贝叶斯分类
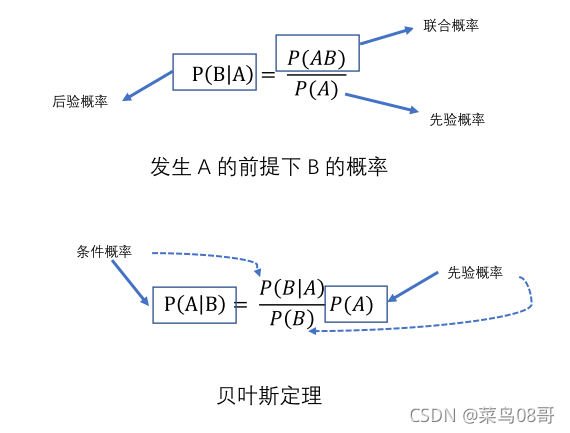
4.1 贝叶斯定理
- 计算条件概率
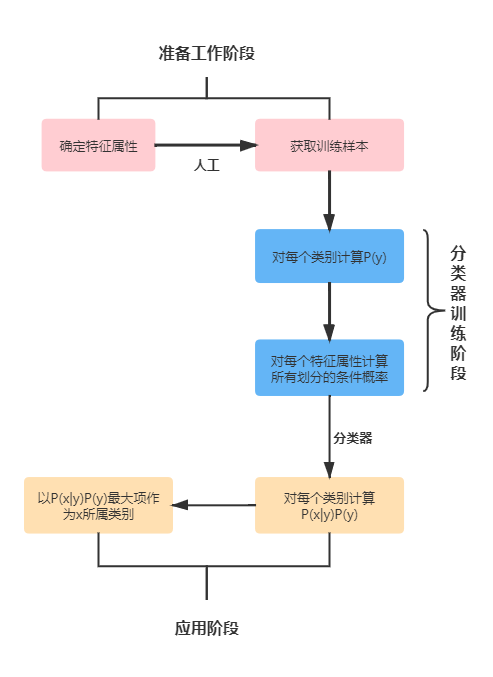
4.2 朴素贝叶斯分类
- 朴素:特征条件独立
- 贝叶斯:基于贝叶斯定理
该方法受限于当特征属性有条件独立或基本独立。
4.3 贝叶斯网络
- 贝叶斯网络也成为信念网络,借助有向无环图来刻画属性之间的依赖关系。
贝叶斯网络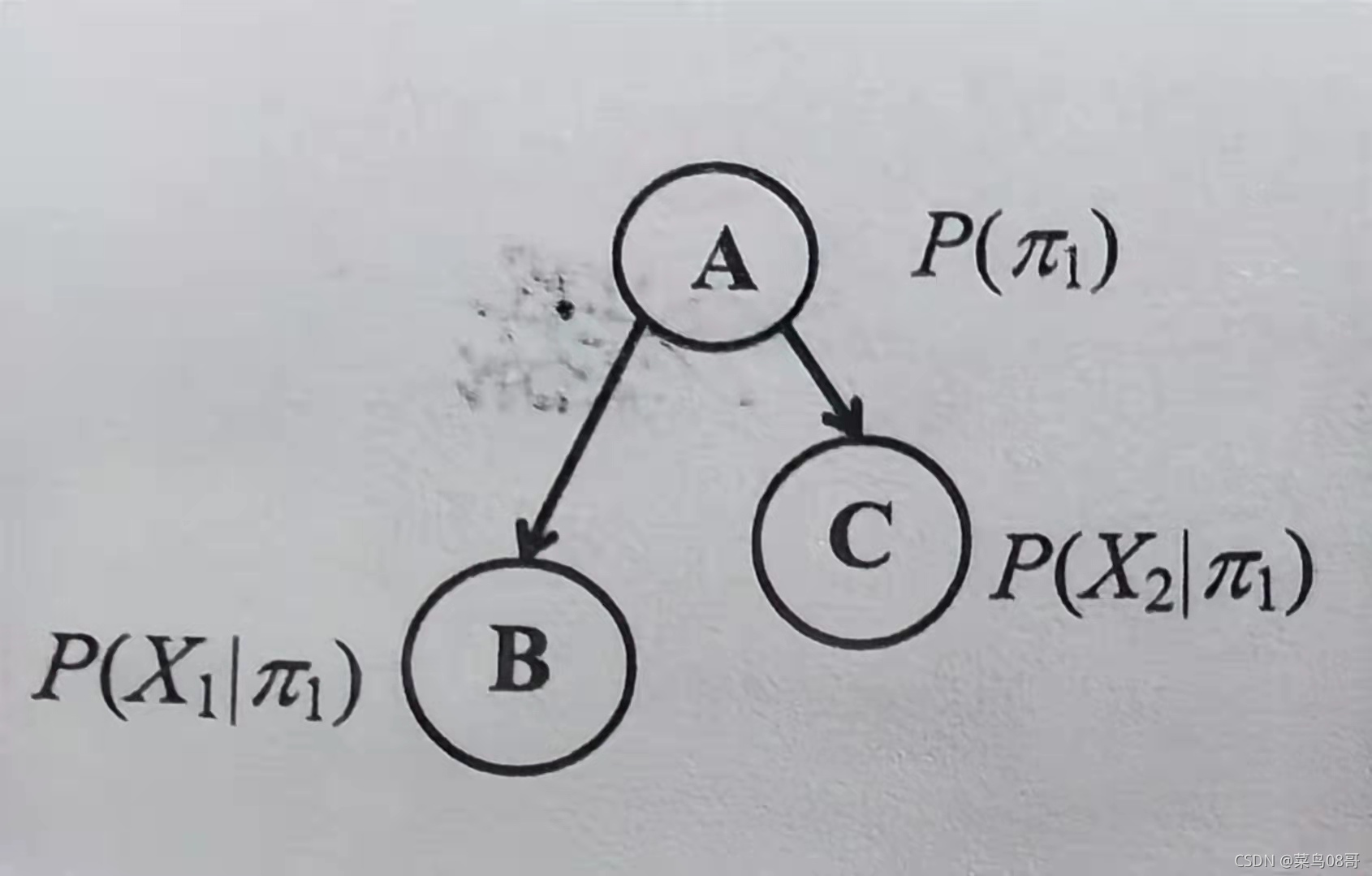
- 贝叶斯网络的三种结构
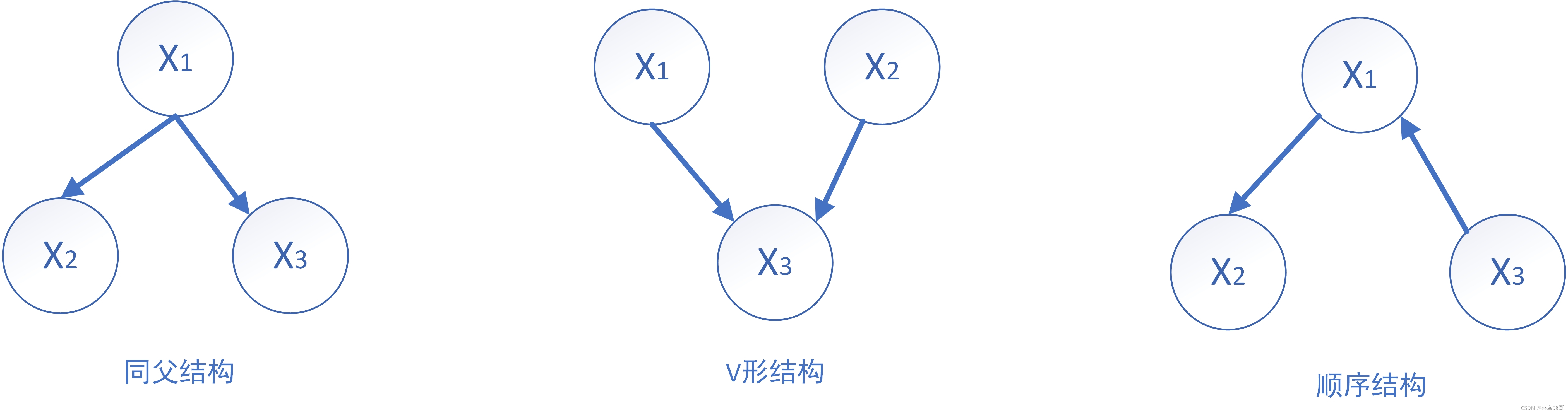
一个节点表示一个状态,状态之间的连线表示因果关系,每一个关系有一个描述因果强度的权重,叫做可信度。两个节点相连,说明两个节点之间有因果关系。
4.4 朴素贝叶斯对email分类――python实现
import re
import random
import numpy as np
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document) # 取并集
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
# 词条存在于词汇表中,则置1
returnVec[vocabList.index(word)] = 1
else:
print("the word: %s is not in my Vocabulary!" % word)
return returnVec
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
# 朴素贝叶斯训练函数
def trainNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory) / float(numTrainDocs) # 文档属于垃圾邮件类的概率
p0Num = np.ones(numWords)
p1Num = np.ones(numWords)
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = np.log(p1Num / p1Denom)
p0Vect = np.log(p0Num / p0Denom) # 取对数防止下溢
return p0Vect, p1Vect, pAbusive
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1)
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def textParse(bigString):
listOfTokens = re.split(r'\W*', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 2]
def spamTest():
docList = []
classList = []
fullText = []
for i in range(1, 26):
wordList = textParse(open('email/spam/%d.txt' % i, 'r').read())
docList.append(wordList)
fullText.append(wordList)
classList.append(1)
wordList = textParse(open('email/ham/%d.txt' % i, 'r').read())
docList.append(wordList)
fullText.append(wordList)
classList.append(0)
vocabList = createVocabList(docList)
trainingSet = list(range(50))
testSet = []
for i in range(10):
randIndex = int(random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex])
del (trainingSet[randIndex])
trainMat = []
trainClasses = []
for docIndex in trainingSet:
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses))
# 训练朴素贝叶斯模型
errorCount = 0
for docIndex in testSet:
wordVector = setOfWords2Vec(vocabList, docList[docIndex])
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
errorCount += 1
print("分类错误的测试集:", docList[docIndex])
print("错误率:%.2f%%" % (float(errorCount) / len(testSet) * 100))
if __name__ == '__main__':
spamTest()
其他方法可参考github