这个与上个教程的区别就是两层神经网络
一、数据集
import tensorflow as tf
tf.__version__
'2.6.0'
# 导入数据集
mnist = tf.keras.datasets.mnist
(train_images,train_labels),(test_images,test_labels) = mnist.load_data()
train_images.shape,test_images.shape,train_labels.shape
((60000, 28, 28), (10000, 28, 28), (60000,))
# 展示图片
import matplotlib.pyplot as plt
def plot_image(image):
plt.imshow(image,cmap='binary')
plt.show()
plot_image(train_images[0])
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N7WP1qfL-1632926073867)(output_4_0.png)]](https://img-blog.csdnimg.cn/225775e1f31745c596cd77347e79257d.png)
# 划分数据集
total_num = len(train_images)
split_valid = 0.2
train_num = int((1 - split_valid) * total_num)
# 训练集
train_x = train_images[:train_num]
train_y = train_labels[:train_num]
# 验证集
valid_x = train_images[train_num:]
valid_y = train_labels[train_num:]
# 测试集
test_x = test_images
test_y = test_labels
# 数据塑形+归一化
train_x = tf.cast(train_x.reshape(-1,784)/255.0,dtype=tf.float32)
valid_x = tf.cast(valid_x.reshape(-1,784)/255.0,dtype=tf.float32)
test_x = tf.cast(test_x.reshape(-1,784)/255.0,dtype=tf.float32)
# 标签进行独热编码
train_y = tf.one_hot(train_y,10)
valid_y = tf.one_hot(valid_y,10)
test_y = tf.one_hot(test_y,10)
二、模型
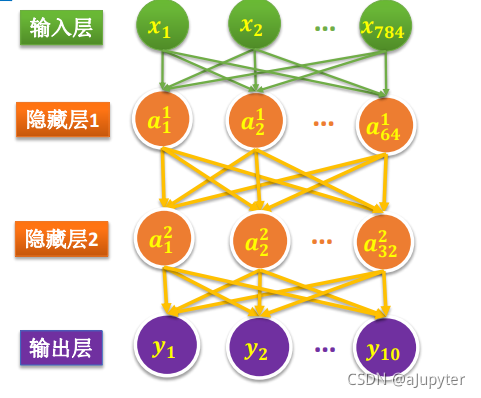
# 构建模型
# 定义第一层隐藏层权重和偏执项变量
Input_Dim = 784
H1_NN = 64
W1 = tf.Variable(tf.random.normal(shape=(Input_Dim,H1_NN)),dtype=tf.float32)
B1 = tf.Variable(tf.zeros(H1_NN),dtype=tf.float32)
# 定义第二层隐藏层权重和偏执项变量
H2_NN = 32
W2 = tf.Variable(tf.random.normal(shape=(H1_NN,H2_NN)),dtype=tf.float32)
B2 = tf.Variable(tf.zeros(shape=(H2_NN)),dtype=tf.float32)
# 定义输出层权重和偏执项变量
Output_Dim = 10
W3 = tf.Variable(tf.random.normal(shape=(H2_NN,Output_Dim)),dtype=tf.float32)
B3 = tf.Variable(tf.zeros(Output_Dim),dtype=tf.float32)
# 待优化列表
W = [W1,W2,W3]
B = [B1,B2,B3]
# 定义模型的前向计算
def model(w,x,b):
x = tf.matmul(x,w[0]) + b[0]
x = tf.nn.relu(x)
x = tf.matmul(x,w[1]) + b[1]
x = tf.nn.relu(x)
x = tf.matmul(x,w[2]) + b[2]
return tf.nn.softmax(x)
# 损失函数
def loss(w,x,y,b):
pred = model(w,x,b)
loss_ = tf.keras.losses.categorical_crossentropy(y_true=y,y_pred=pred)
return tf.reduce_mean(loss_)
# 准确率
def accuracy(w,x,y,b):
pred = model(w,x,b)
acc = tf.equal(tf.argmax(pred,axis=1),tf.argmax(y,axis=1))
return tf.reduce_mean(tf.cast(acc,dtype=tf.float32))
# 计算梯度
def grad(w,x,y,b):
with tf.GradientTape() as tape:
loss_ = loss(w,x,y,b)
return tape.gradient(loss_,[w[0],b[0],w[1],b[1],w[2],b[2]])
# return tape.gradient(loss_,w+b)
三、训练
# 定义超参数
train_epochs = 30
learning_rate = 0.003
batch_size = 10
total_steps = train_num // batch_size
train_loss_list = []
valid_loss_list = []
trian_acc_list = []
valide_acc_list = []
# 优化器
optimizer = tf.optimizers.Adam(learning_rate=learning_rate)
for epoch in range(train_epochs):
for step in range(total_steps):
xs = train_x[step*batch_size:(step+1)*batch_size]
ys = train_y[step*batch_size:(step+1)*batch_size]
grads = grad(W,xs,ys,B)
optimizer.apply_gradients(zip(grads,[W[0],B[0],W[1],B[1],W[2],B[2]]))
# optimizer.apply_gradients(zip(grads,W+B))
trian_loss = loss(W,train_x,train_y,B).numpy()
valid_loss = loss(W,valid_x,valid_y,B).numpy()
train_accuracy = accuracy(W,train_x,train_y,B).numpy()
valid_accuracy = accuracy(W,valid_x,valid_y,B).numpy()
trian_acc_list.append(train_accuracy)
valide_acc_list.append(valid_accuracy)
train_loss_list.append(trian_loss)
valid_loss_list.append(valid_loss)
print(f'{epoch+1}:trian_loss:{trian_loss}valid_loss:{valid_loss}train_accuracy:{train_accuracy}valid_accuracy:{valid_accuracy}')
1:trian_loss:6.580987453460693valid_loss:6.479250431060791train_accuracy:0.5860000252723694valid_accuracy:0.5925833582878113
2:trian_loss:6.424005031585693valid_loss:6.360451698303223train_accuracy:0.5971875190734863valid_accuracy:0.6018333435058594
3:trian_loss:6.097455024719238valid_loss:6.033313274383545train_accuracy:0.6189166903495789valid_accuracy:0.6230000257492065
4:trian_loss:5.8688645362854valid_loss:5.803295612335205train_accuracy:0.6339583396911621valid_accuracy:0.637499988079071
5:trian_loss:5.9221625328063965valid_loss:5.803203105926514train_accuracy:0.6303750276565552valid_accuracy:0.6372500061988831
6:trian_loss:5.896974563598633valid_loss:5.842071533203125train_accuracy:0.6324166655540466valid_accuracy:0.6362500190734863
7:trian_loss:5.031162261962891valid_loss:4.914495468139648train_accuracy:0.6853333115577698valid_accuracy:0.6925833225250244
8:trian_loss:5.0237603187561035valid_loss:4.93804407119751train_accuracy:0.6856458187103271valid_accuracy:0.6910833120346069
9:trian_loss:4.672614574432373valid_loss:4.5313215255737305train_accuracy:0.7083125114440918valid_accuracy:0.7173333168029785
10:trian_loss:4.590989589691162valid_loss:4.537859916687012train_accuracy:0.7135208249092102valid_accuracy:0.7169166803359985
11:trian_loss:4.445350170135498valid_loss:4.330698013305664train_accuracy:0.7228749990463257valid_accuracy:0.7298333048820496
12:trian_loss:4.395635604858398valid_loss:4.309895992279053train_accuracy:0.726187527179718valid_accuracy:0.731333315372467
13:trian_loss:4.7202019691467285valid_loss:4.669859409332275train_accuracy:0.7056666612625122valid_accuracy:0.7092499732971191
14:trian_loss:4.354457855224609valid_loss:4.261003017425537train_accuracy:0.7288749814033508valid_accuracy:0.7350833415985107
15:trian_loss:4.494258403778076valid_loss:4.385723114013672train_accuracy:0.7201041579246521valid_accuracy:0.7266666889190674
16:trian_loss:4.434334754943848valid_loss:4.348935127258301train_accuracy:0.7239791750907898valid_accuracy:0.7291666865348816
17:trian_loss:4.3910346031188965valid_loss:4.281760215759277train_accuracy:0.7265833616256714valid_accuracy:0.7334166765213013
18:trian_loss:4.349645614624023valid_loss:4.264510631561279train_accuracy:0.7292708158493042valid_accuracy:0.7349166870117188
19:trian_loss:4.429117202758789valid_loss:4.2584147453308105train_accuracy:0.7242083549499512valid_accuracy:0.734333336353302
20:trian_loss:3.2191579341888428valid_loss:3.0694947242736816train_accuracy:0.7988749742507935valid_accuracy:0.8080833554267883
21:trian_loss:3.0707924365997314valid_loss:3.0029022693634033train_accuracy:0.8083750009536743valid_accuracy:0.812333345413208
22:trian_loss:2.9579107761383057valid_loss:2.883277654647827train_accuracy:0.815541684627533valid_accuracy:0.8199999928474426
23:trian_loss:2.8853251934051514valid_loss:2.7707910537719727train_accuracy:0.820145845413208valid_accuracy:0.8271666765213013
24:trian_loss:3.1851065158843994valid_loss:3.10489821434021train_accuracy:0.8012083172798157valid_accuracy:0.8060833215713501
25:trian_loss:2.7804036140441895valid_loss:2.683088541030884train_accuracy:0.8267083168029785valid_accuracy:0.8327500224113464
26:trian_loss:3.095480442047119valid_loss:3.00217604637146train_accuracy:0.8071458339691162valid_accuracy:0.812749981880188
27:trian_loss:2.906459331512451valid_loss:2.8469276428222656train_accuracy:0.8190416693687439valid_accuracy:0.8225833177566528
28:trian_loss:2.9077982902526855valid_loss:2.7894530296325684train_accuracy:0.8187708258628845valid_accuracy:0.8262500166893005
29:trian_loss:2.8220016956329346valid_loss:2.72312068939209train_accuracy:0.8242708444595337valid_accuracy:0.8303333520889282
30:trian_loss:3.002092123031616valid_loss:2.8451685905456543train_accuracy:0.8130208253860474valid_accuracy:0.8225833177566528
accuracy(W,test_x,test_y,B).numpy()
0.8081
# 损失图像
plt.plot(train_loss_list,'r')
plt.plot(valid_loss_list,'b')
[<matplotlib.lines.Line2D at 0x7f8e83ce4a10>]
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aLuAQ28U-1632926073869)(output_22_1.png)]](https://img-blog.csdnimg.cn/60aa9db6843a4eed8cea64553d059d35.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAYUp1cHl0ZXI=,size_12,color_FFFFFF,t_70,g_se,x_16)
# 准确率图像
plt.plot(trian_acc_list,'r')
plt.plot(valide_acc_list,'b')
[<matplotlib.lines.Line2D at 0x7f8e83c5b7d0>]
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1WEoLkwM-1632926073870)(output_23_1.png)]](https://img-blog.csdnimg.cn/96d6c37ccf0442188380c37fa49894b6.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAYUp1cHl0ZXI=,size_12,color_FFFFFF,t_70,g_se,x_16)
四、预测
def predict(x,w,b):
pred = model(w,x,b)
pred_ = tf.argmax(pred,axis=1)
return pred_
import numpy as np
id = np.random.randint(0,len(test_x)) # 随机生成一个验证id
# 预测值
pred = predict(test_x,W,B)[id]
# 真实值
true = test_labels[id]
print(true,pred.numpy())
0 0
import sklearn.metrics as sm
print(f'r2:{sm.r2_score(test_y,model(W,test_x,B))}')
r2:0.5868031351043385
这还不如单层神经网络呢…