- 🎉粉丝福利送书:《Hadoop+spark+Python大数据处理从算法到实战》
- 🎉点赞 👍 收藏 ?留言 📝 即可参与抽奖送书
- 🎉下周三(10月7日)晚上20:00将会在【点赞区和评论区】抽一位粉丝送这本书~🙉
- 🎉详情请看第四点的介绍嗷~?

目录
1. ①
1.1 题目
用
urllib和re库方法定向爬取给定网址的数据

1.2 思路
1.2.1 发送请求
- 引入库并且编写请求头
请求头是为了把爬虫包装成浏览器的正常访问。
import urllib.request
import re
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
}
urllib和requests不同
urllib构造请求头和发送请求是分开的,而requests是封装在一起的。
url = "https://www.shanghairanking.cn/rankings/bcsr/2020/0812"
request = urllib.request.Request(url, headers=header) # 构造请求头
r = urllib.request.urlopen(request) # 发送请求
1.2.2 解析网页
- decode() 是为了解码成
中文 - replace(’\n’,’’) 是为了把回车去掉,方便后续的正则匹配。
html = r.read().decode().replace('\n','')
1.2.3 获取结点
- 分析网页
我们很容易找到结点信息,然后观察节点信息的结构。
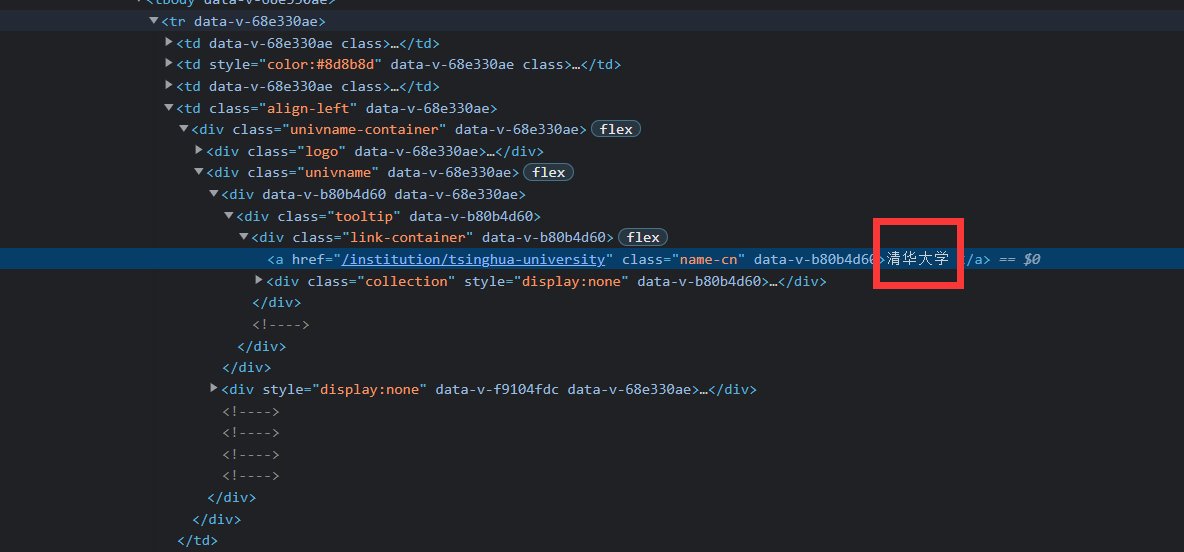
- 使用正则表达式获取总体的节点信息
ranking = re.findall("<td data-v-68e330ae>(.*?)</td></tr>",html)
- 构造字典来存储数据
uList =[]
for k in ranking:
u = {
"rank":"",
"percent":"",
"name":"",
"socre":"",
}
name = re.findall("img alt=(.*?) onerror",k)
# 匹配出名字
ranking = re.findall(" (\d+) ",k)
# 匹配出排名
socre = re.findall("<td data-v-68e330ae> (.*?) ",k)
# 匹配出分数
u["rank"]=ranking[0]
u["percent"]=socre[0]
u["name"]=eval(name[0])
u["socre"]=socre[1]
uList.append(u)
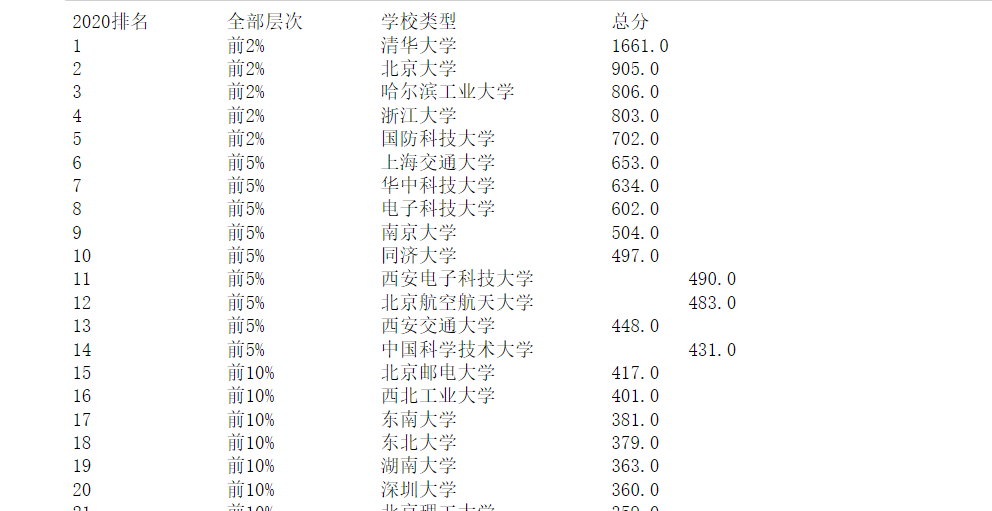
1.2.4 数据输出
print("2020排名\t全部层次\t学校类型\t\t总分")
for u in uList:
print("{}\t\t{}\t\t{}\t\t{}\t\t".format(u["rank"],u["percent"],u["name"],u["socre"]))
2. ②
2.1 题目
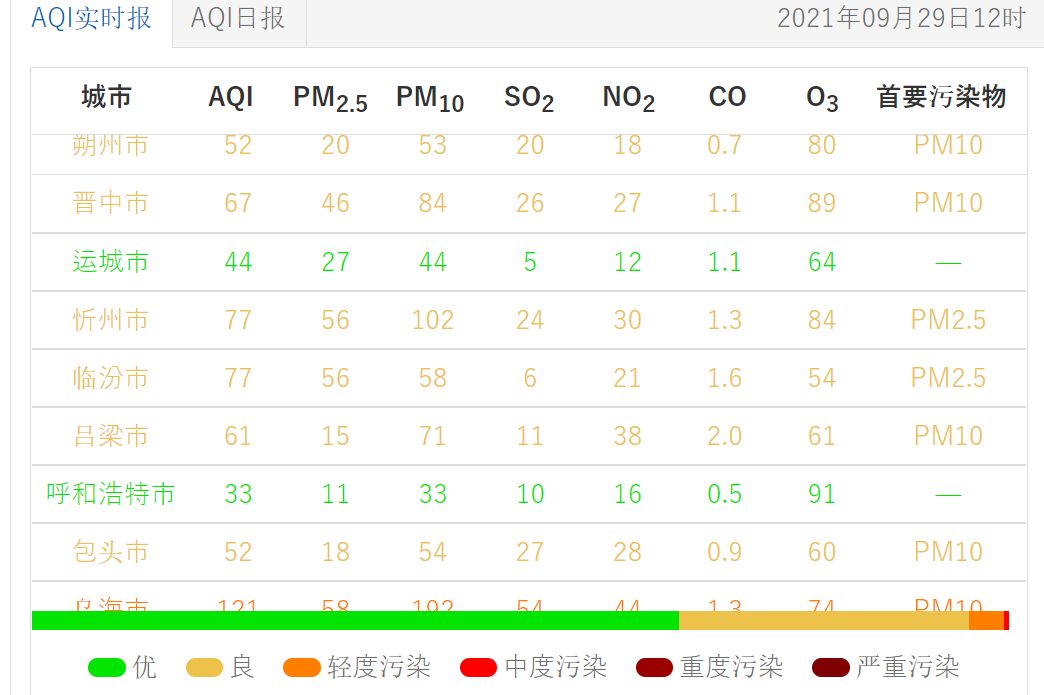
用
requests和Beautiful Soup库方法设计爬取网址的AQI实时报
2.2 思路
2.2.1 发送请求
- 导入库
import requests
from bs4 import BeautifulSoup
- 构造请求头
headers = {
'Connection': 'keep-alive',
'sec-ch-ua': '"Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
- 发送请求
response = requests.get('https://datacenter.mee.gov.cn/aqiweb2/', headers=headers)
2.2.2 解析网页
- 使用
BeautifulSoup解析器进行解析,解析成lxml格式
soup = BeautifulSoup(response.content,"lxml")
解析器的作用是为了把请求到的字符串重新解析成lxml前端树的格式,方便获取器进行节点的Find等操作。
2.2.3 获取结点
- 分析网页
我们可以看到我们所想要的节点信息都是在这个在td标签下的,所以我们只需要找到所有的td标签即可。
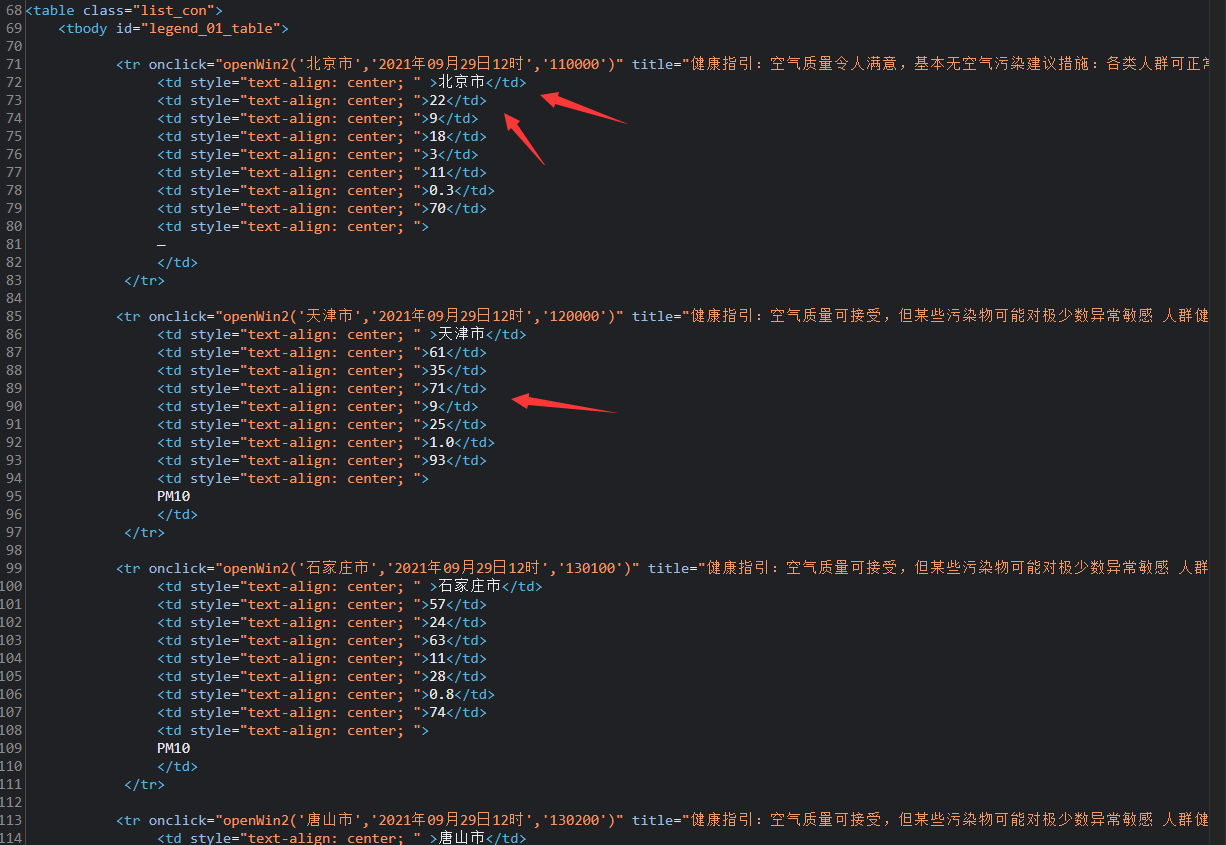
- 找到所有的
td
tdTmp = soup.find_all('td')
结果我们打印结果,我们发现,数据除了text格式之后,还可能存在\t\n\r这些空格,所以要进行一个清洗替换
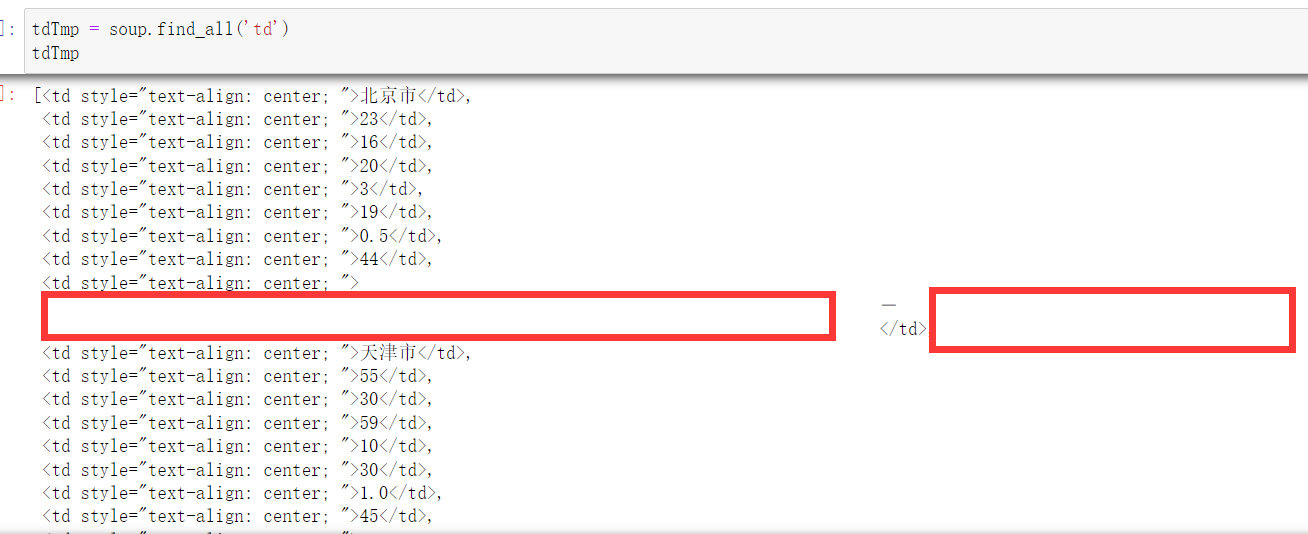
- 数据清洗
把\r\t\n这些空格回车字符进行清洗替换
for i in range(len(tdTmp)):
info=tdTmp[i].text
if len(info)>10:
info = info.replace('\r', '')
info = info.replace('\n', '')
info = info.replace('\t', '')
somethingList.append(info)
if count < 8:
count += 1
td.append(info)
else:
tds.append(td)
count=0
td = []
2.2.4 数据输出
一样采用字典键值对去存储数据。
num=0
for td in tds:
cityWeather={
"num":"",
"city":"",
"AQI":"",
"PM2.5":"",
"So2":"",
"No2":"",
"Co":"",
"something":"",
}
cityWeather["num"]=num+1
cityWeather["city"]=td[0]
cityWeather["AQI"]=td[1]
cityWeather["PM2.5"]=td[2]
cityWeather["So2"]=td[4]
cityWeather["No2"]=td[5]
cityWeather["Co"]=td[6]
cityWeather["something"]=somethingList[num]
num+=1
infoList.append(cityWeather)
print(cityWeather)
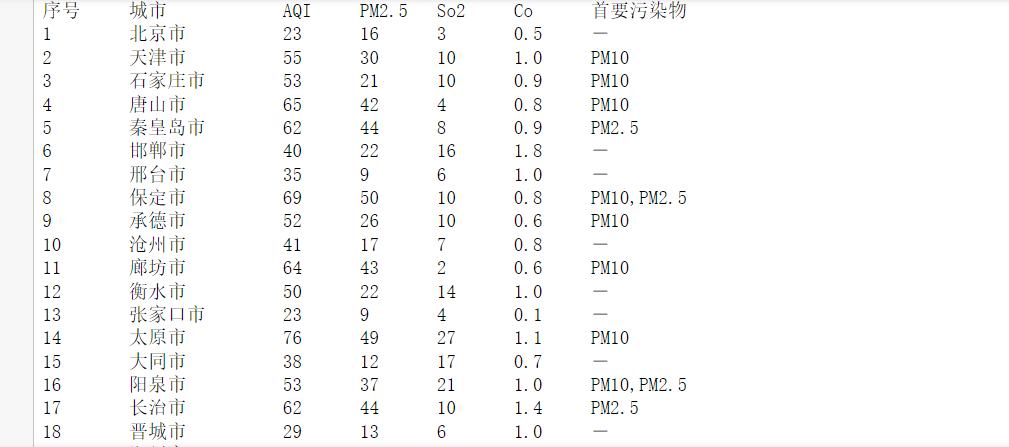
结果输出
print("序号 \t 城市 \t\t AQI \t PM2.5 \t So2 \t Co \t 首要污染物")
for k in infoList:
print("{} \t {} \t {} \t {} \t {} \t {} \t {}".format(k["num"],k["city"],k["AQI"],k["PM2.5"],k["So2"],k["Co"],k["something"]))
3. ③
3.1 题目
要求:使用urllib和requests和re爬取一个给定网页
爬取该网站下的所有图片
输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
3.2 思路
3.2.1 发送请求
- 引入库
import requests,re
import urllib
- 构造请求头
headers = {
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
url = 'http://news.fzu.edu.cn/'
- 发送请求
urllib:
request = urllib.request.Request(url, headers=headers)
r = urllib.request.urlopen(request)
requests:
response = requests.get(url, headers=headers, verify=False)
3.2.2 解析网页
urllib:
html = r.read().decode().replace('\n','')
requests:
html = response.content().replace('\n','')
3.2.3 获取结点
- 注意一点
img和src之间也可能会有匹配的,所以不能直接使用<img src="(.*?)这种形式的正则。
- 正则匹配出所有的图片信息
imgList = re.findall(r'<img.*?src="(.*?)"', html, re.S)
3.2.4 数据输出
- 创建一个文件夹image进行保存
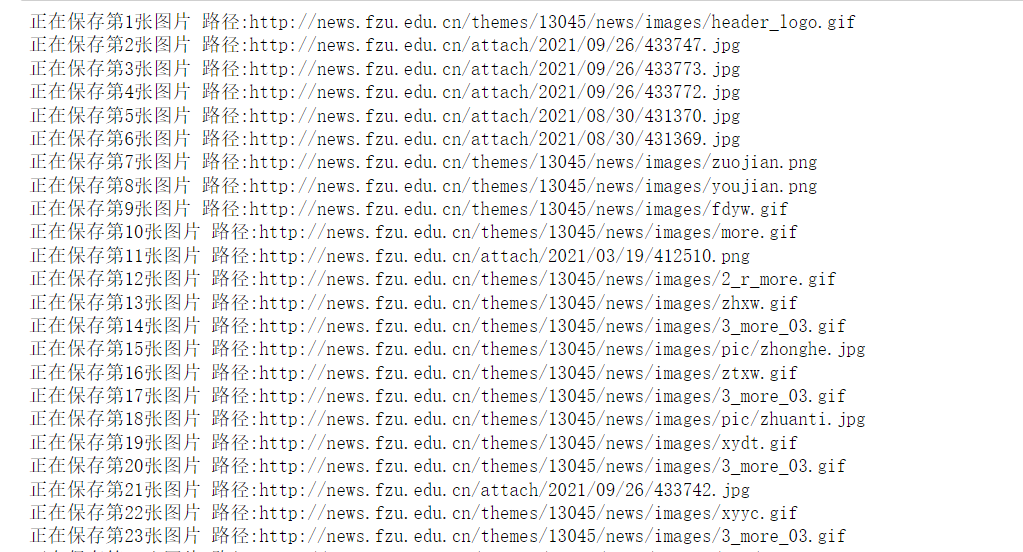
for i, img in enumerate(imgList):
img_url = "http://news.fzu.edu.cn" + img
print(f"正在保存第{i + 1}张图片 路径:{img_url}")
resp = requests.get(img_url)
with open(f'./image/{img.split("/")[-1]}', 'wb') as f:
f.write(resp.content)
4. 福利送书
点赞,评论这篇博文即可参与送书。
【参考文案】
学习人工智能,为什么要从基础的算法开始入门?学习大数据分析,为什么最后却讲解起了云计算?在“大数据”“云计算”“人工智能”被频繁提起的今天,你是否知道这三个名词间有什么关系?
如果你也有类似疑问,那一定要好好看看北京大学出版社倾力打造的新书――《Hadoop+spark+Python大数据处理从算法到实战》!本书围绕大数据处理的三大核心要素(算力+数据+算法),剖析大数据处理全过程,没有高冷的代码,也没有繁杂的公式,用“简单的方法”搞定大数据,带你用愉快的心情玩转AI!

【内容简介】
本书围绕新基建的云计算、大数据及人工智能进行介绍,分为以下五个部分。
第一部分,介绍大数据的概念与特点,以及典型的产业应用场景;
第二部分,介绍目前云计算中的一个重要的研究与应用领域――容器云,包含应用容器引擎Docker与容器编排工具Kubernetes;
第三部分,是大数据分析的基础,也是大数据分析技术的重点,包含Hadoop、HBase、Hive、Spark的环境搭建及开发流程;
第四部分,是机器学习相关算法的应用,包含scikit-learn、SparkML、TensorFlow工具的使用;
第五部分,以实例介绍如何使用Spark机器学习库中的协同过滤算法,来实现一个基于Web的推荐系,以及介绍如何使用OpenCV与TensorFlow构建卷积神经网络来实现基于Web的人脸识别。
本书轻理论,重实践,适合有一定编程基础,且对云计算、大数据、机器学习、人工智能感兴趣,希望投身到新基建这一伟大事业的读者学习。同时,本书还可作为广大院校相关专业的教材和培训参考用书。