小样本学习和元学习基础知识

人工智能最终依赖于大数据中学习。很难用很少的数据快速概括一个模型。相反,人类可以快速应用他们过去学到的东西来学习新事物。一个重要的方向是缩小人工智能与人类之间的差距。通过有限数据进行学习。
少样本学习(few-shot learning)
深度学习是data hunger的方法, 需要大量的数据,标注或者未标注。少样本学习研究就是如何从少量样本中去学习。拿分类问题来说,每个类只有一张或者几张样本。少样本学习可以分为zero-shot learning(即要识别训练集中没有出现过的类别样本)和one-shot learning/few shot learning(即在训练集中,每一类都有一张或者几张样本)。
人类是有少样本学习的能力。以zero-shot learning来说,比如有一个中文 “放弃”,要你从I, your, she, them, abnegation 五个单词中选择出来对应的英文单词,尽管你不知道“放弃”的英文是什么,但是你会将“放弃”跟每个单词对比,而且在你之前的学习中,你已经知道了I, your, she, them的中文意思,都不是“放弃”,所以你会选择abnegation。
首先明确几个概念
(1)support set :每次训练的样本集合
(2)query set :用于与训练样本比对的样本,一般来说query set就是一个样本
(3)在support set中,如果有n个种类,每个种类有k个样本,那么这个训练过程叫n -way k-shot ,如下图就是5-way 1-shot。

元学习(meta learning)
元学习是要“学会如何学习”,即利用以往的知识经验来指导新任务的学习,具有学会学习的能力,元学习被视为实现通用人工智能(Artificial General Intelligence,AGI)的基础,也必将令人工智能走出深度学习的困境。目前,元学习方法主要分为:度量方法、模型方法、优化方法以及基于数据增强。
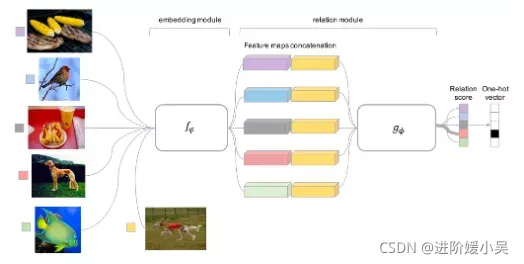
基于度量的元学习的核心思想类似于最近邻算法(k-NN分类、k-means聚类)和核密度估计。该类方法在已知标签的集合上预测出来的概率,是support set中的样本标签的加权和。权重由核函数计算得出,该权重代表着两个数据样本之间的相似性。Convolutional Siamese Neural Network提出了一种用孪生网络做one-shot image classification的方法;Matching Network对support set进行特征提取后,在embedding空间中利用Cosine来度量,通过对测试样本计算匹配程度来实现分类;Relation Network关系网络提出的relation module结构替换了Matching Network和Prototypical Network中的Cosine和欧式距离度量,使其成为一种学习的非线性分类器用于判断关系,实现分类;Prototypical Network利用聚类思想,将support set投影到一个度量空间,在欧式距离度量的基础上获取向量均值,对测试样本计算到每个原型的距离,实现分类。然而,虽然训练模型不需要针对测试任务进行调整,但当测试与训练任务距离远时,效果不好,另外,当任务变得更大时,逐对比较会导致计算成本昂贵。
meta learning 是学习如何学习,few-shot learning 是要达到的目标(用一点点训练资料就可以训练出我们要的结果)。为什么觉得meta learning 和few-shot learning 像呢?就是希望达到few-shot learning,想要一个学习演算法只看到一点点资料就可以学起来。few-shot learning的Algorithm往往是用meta learning 得到的。
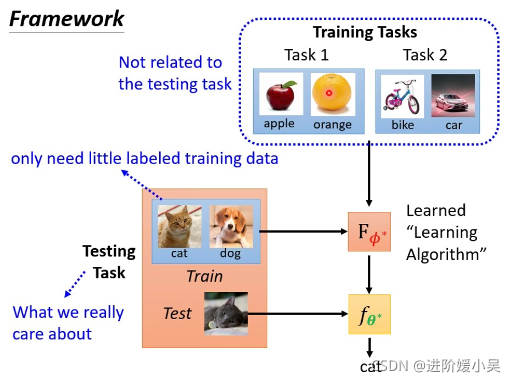

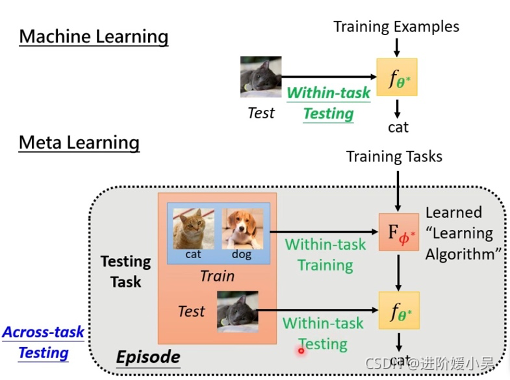
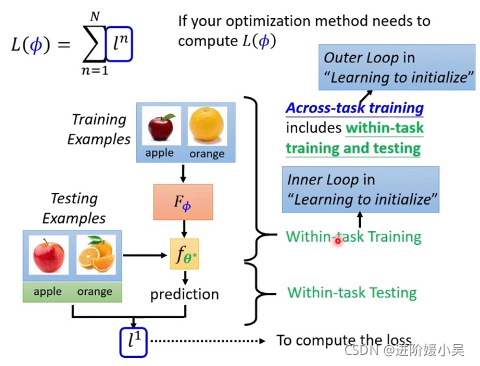
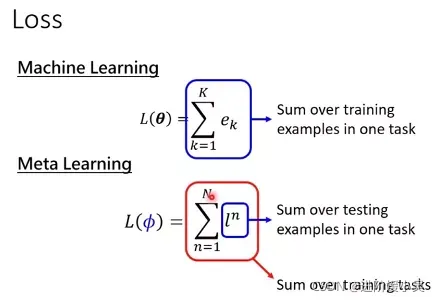

k-way是support set 里有多少个类别;n-shot是每个类别有多少个例子。
如果做few-shot 分类,预测的准确率会受support set 的类别数量和样本数量影响。随着分类类别数量增加,准确率会降低;随着number of shot的增加预测值会增加。
学一个函数来判断相似度。
其他
Omniglot数据集
常用的数据集:Omniglot是meta learning最常用的数据集。这个数据集不大,只有几兆,很适合学术界使用。Omniglot有点类似MNIST。MNIST有10个类每个勒有6000个样本;Omniglot的类别很多,每个类的样本却很少,有1600多个类,每个类只有20个样本。

另一个数据集是Mini-ImageNet。一共有100类,每个类有600个样本,样本是84*84的小图片。
https://deepai.org/dataset/imagenet
分类问题:
(1)Siamese Neural Network
(2)Matching Network
(3)Prototypical Network
(4)Relation Network
介绍两种训练方法。第一种是每次取两个样本,比较它们的相似度,需要用大的数据集,每类有标注,每类下面有很多个样本。用训练集构造正样本和负样本,正样本告诉神经网络什么东西同一类,负样本可以告诉神经网络它们的区别。正样本是通过每次抽取一张图片,然后从同一类中随机抽取另一张图片,标签设置为1。负样本是随机抽取一张图片,然后排出这类,在其余类中随机抽取一张,两张图片类别不同,标签设置为0。
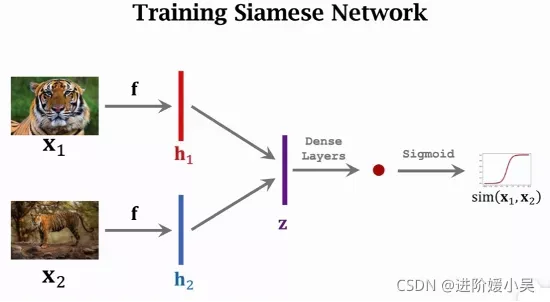
希望神经网络的输出接近标签,把标签和预测的差别记为损失函数,可以是cross entropy。有了损失函数就可以用反向传播来计算梯度,然后用梯度下降来更新模型参数。
Siamese Network是计算两两之间的相似度。另一种方法是triplet Loss。每次需要三张图做一轮训练,首先从训练集中随机选一张图片作为anchor(锚点),记录下这个锚点,然后从该类别中随机抽取一张图片作为正样本,然后排出这个类别,做随机抽样,得到一个负样本。

Prototypical Networks是基于这样一种思想,对于每个类别,都存在一个嵌入空间中的点,称为类的原型,每个样本的嵌入空间表示都会围绕这个点进行聚类。为了做到这一点,即利用神经网络的非线性映射将输入映射到嵌入空间,并将嵌入空间中支持集的平均值作为类的原型。预测分类的时候,就只需要比较跟支持集类别的哪个类的原型更近了。
基于度量的元学习的核心思想类似于最近邻算法(k-NN分类、k-means聚类)和核密度估计。该类方法在已知标签的集合上预测出来的概率,是support set中的样本标签的加权和。权重由核函数计算得出,该权重代表着两个数据样本之间的相似性。因此,学到一个好的核函数对于基于度量的元学习模型至关重要。度量元学习正是针对该问题提出的方法,它的目标就是学到一个不同样本之间的度量或者说是距离函数。任务不同,好的度量的定义也不同,但它一定在任务空间上表示了输入之间的联系,并且能够帮助我们解决问题。
Siamese Neural Network孪生网络做one-shot image classification的方法;Matching Network对support set进行特征提取后,在embedding空间中利用Cosine来度量,通过对测试样本计算匹配程度来实现分类;Relation Network关系网络提出的relation module结构替换了MatchingNet和Prototypical Net中的Cosine和欧式距离度量,使其成为一种学习的非线性分类器用于判断关系,实现分类;Prototypical Network利用聚类思想,将support set投影到一个度量空间,在欧式距离度量的基础上获取向量均值,对测试样本计算到每个原型的距离,实现分类。
然而,虽然训练模型不需要针对测试任务进行调整,但当测试与训练任务距离远时,效果不好,另外,当任务变得更大时,逐对比较会导致计算成本昂贵。基于度量的元学习方向倾向于最大程度上抽取任务样本内含的特征,使用特征比对的方式判定样本的种类,因此如何提取最能代表样本特点的特征便成为了该方向研究重点。相比于普通学习得到的特征表示,元学习得到的特征表示(Meta-learned Representations)是有区别的,更有助于少样本学习。
使用元学习的特征表示能够提升少样本学习的效果,作者归为两种不同的机制:
(1)固定特征提取模块的参数,只更新(微调)最后的分类层(Classification Layer)参数。在这种机制下,类别数据点在特征空间中会更加聚集,那么在微调时,分类边界对于提供的样本会没那么敏感。
(2)在模型参数空间寻找最优点作为基础模型,该最优点接近大部分特定任务(Task-specific)模型参数的最优点,那么在面对新的特定任务时,能够通过几步的梯度计算,将基础模型更新为适用于新任务的特定模型。
后续会持续更新关于小样本学习的文章。
每天按时吃饭绝不敷衍,致力于不断寻找更多的人类美食,然后…然后我就胖了。
大家也要按时吃饭哟??
祝大家国庆节快乐哇!😁
