机器学习sklearn的学习与运用――数据预处理 ― 标准化(来自Educoder)
相关知识
原始数据存在的几个问题:不一致、重复、含噪声、维度高。数据挖掘中,数据预处理包含数据清洗、数据集成、数据变换和数据归约几种方法,在这里不过多叙述预处理方法细节。接下来将简单介绍,如何通过调用 sklearn 中的模块进行数据预处理。
sklearn.preprocessing 模块提供很多公共的方法,将原始不规整的数据转化为更适合分类器的具有代表性的数据。一般说来,使用标准化后的数据集训练学习模型具有更好的效果。
数据标准化的方法有很多种,常用的有“最小―最大标准化”、“Z-score标准化”等等。经过上述标准化处理,各属性值都处于同一个数量级别上,可以进行综合数据分析。
Z-score 标准化
这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将 A 的原始值 x 使用 Z-score 标准化到 x’。
Z-score 标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况,其公式为:
新数据=(原数据-均值)/标准差
sklearn.preprocessing.scale函数,可以直接将给定数据进行标准化。

标准化处理后,数据的均值和方差:

sklearn.preprocessing.StandardScaler类实现了 Transformer 接口,可以保存训练数据中的参数(均值 mean_、缩放比例 scale_),并能将其应用到测试数据的标准化转换中。
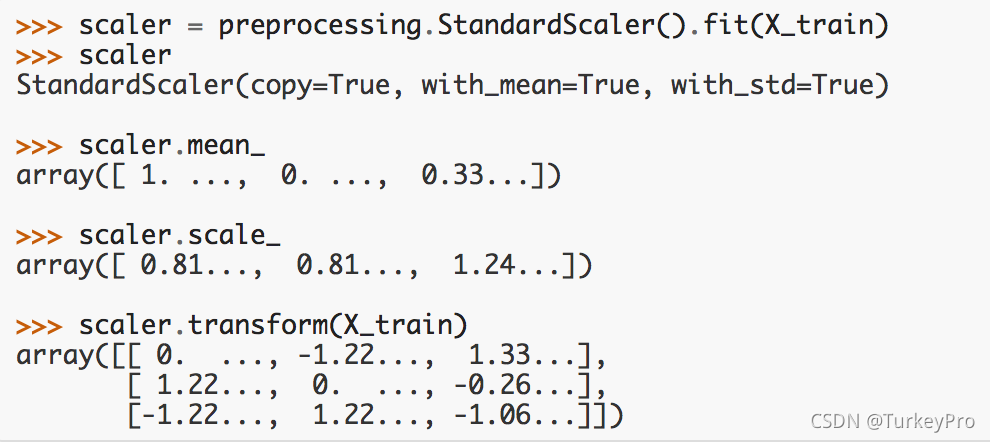
将标准化转换器应用到新的测试数据:

min-max 标准化
min-max 标准化方法是对原始数据进行线性变换。设 minA 和 maxA 分别为属性 A 的最小值和最大值,将 A 的一个原始值 x 通过 min-max 标准化,映射成在区间[0,1]中的值 x’,其公式为:
新数据=(原数据-极小值)/(极大值-极小值)
sklearn.preprocessing.MinMaxScaler将属性缩放到一个指定的最大和最小值(通常是1-0)之间。
MinMaxScaler 中可以通过设置参数feature_range=(min, max)指定最大最小区间。其具体的计算公式为:
- X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
- X_scaled = X_std * (max - min) + min

将标准化缩放,应用到新的测试数据:

代码实现:
from sklearn.datasets import fetch_california_housing
from sklearn import preprocessing
dataset = fetch_california_housing("./step4/")
X_full, y = dataset.data, dataset.target
#抽取其中两个特征数据
X = X_full[:, [0, 5]]
def getMinMaxScalerValue():
'''
对特征数据X进行MinMaxScaler标准化转换,并返回转换后的数据前5条
返回值:
X_first5 - 数据列表
'''
X_first5 = []
# 请在此添加实现代码 #
# ********** Begin *********#
min_max_scaler = preprocessing.MinMaxScaler()
X_first5 = min_max_scaler.fit_transform(X)
# ********** End **********#
return X_first5[:5] #取前五条数据
def getScaleValue():
'''
对目标数据y进行简单scale标准化转换,并返回转换后的数据前5条
返回值:
y_first5 - 数据列表
'''
y_first5 = []
# 请在此添加实现代码 #
# ********** Begin *********#
y_first5 = preprocessing.scale(y)
# ********** End **********#
return y_first5[:5] #取前五条数据
def getStandardScalerValue():
'''
对特征数据X进行StandardScaler标准化转换,并返回转换后的数据均值和缩放比例
返回值:
X_mean - 均值
X_scale - 缩放比例值
'''
# 请在此添加实现代码 #
#********** Begin *********#
scaler = preprocessing.StandardScaler().fit(X)
#********** End **********#
return scaler.mean_,scaler.scale_
以上实验来自Educoder平台Python机器学习软件包Scikit-Learn的学习与运用第二关实例“数据预处理 ― 标准化”
直接放在自己电脑上运行会报错,写这篇文章的目的主要是记录标准化处理的方法以及对应的步骤。谢谢!