目录
项目来源
https://www.kaggle.com/janiobachmann/bank-marketing-dataset
项目简介
利用最近一次的营销活动的信息,分析什么对推销结果的影响最大,如何确定银行定期产品推销中最具价值的客户。
PS: 这是最初上传到UCI机器学习库的经典营销银行数据集,该数据集提供了有关金融机构营销活动的信息,但在本篇博客当中我们仅会用到EXCEL进行数据分析,使用机器学习进行分析我们留到之后再介绍。
1 数据理解
| 字段名 | 理解 |
|---|---|
| age | 年龄(数值) |
| job | 职业(分类:admin, bluecollar, entrepreneur, housemaid, management, retired, self-employed, services,student, technician, unemployed, unknown) |
| marital | 婚姻状况(分类:divorced, married, single, unknown) |
| education | 学历(分类:primary, secondary, tertiary and unknown) |
| default | 失信状况(分类:yes, no) |
| balance | 资产余额(数值) |
| housing | 房屋贷款(分类:yes, no, unknown) |
| loan | 个人贷款(分类:yes, no, unknown) |
| contact | 联系方式(分类:cellular, telephone) |
| day | 最后一次电话营销的日期(数值:月份中的哪一天) |
| month | 最后一次电话营销的月份(分类:jan, feb, mar, apr,…,nov, dev) |
| duration | 通话时长(数值:以秒为单位,0的话最终输出结果必然是0) |
| campaign | 联系次数(数值:此活动中联系该客户的次数) |
| pdays | 距上次联系完客户后的天数(数值:999代表未联系过该客户) |
| previous | 这次活动前与这位客户联系的次数(数值) |
| poutcome | 上次营销的结果(分类:yes, no, unknown) |
| deposit | 定期存款(分类:yes, no)客户是否已购买定期存款 |
2 数据清洗
此次数据除了部分未知数据(unknown),其它暂不需要清洗。
3 确定思路
首先这个balance,我不太确定具体指什么,目前推测应该是客户存放在银行的资金(负数应该代表欠了银行钱吧哈哈),总不可能是代表这个人的个人全部资产吧(银行得不到这方面的信息),所以暂时留着。
然后这个day和month,如果说有年份的话还能将其分为周一周二等,但是没有,数据集出处也没有明确标注是哪一年,所以如果用来分析的话可能也只能按月来分析,但按以往的经验和数据量的大小来看,应该用处不大。
至于duration的话,因为当duration为0时结果必然是失败的,说明这个数据的记录应该是银行人员在营销完记录下的,而现实中你无法在营销前就得到该数据,所以这个数据没有用。
那么接下来我们如何下手呢?
首先我们可以将数据分为两种类型:
1、客户的个人信息
2、营销人员与客户的联系信息
那么接下来我们可以按照这两种数据提出几个问题:
1、用户的个人信息是否对结果有着明显的影响(哪些属性影响大)?
2、营销人员的行为是否对结果有着明显的影响(哪些属性影响大)?
4 分析过程
4.1 年龄
此时我们探究年龄与结果是否有明显的影响。
首先我们可以查看以下数据集中的年龄统计分布情况:

可以发现共有11162名最小值为18,最大值为95,最小值为18。我们可以按照我们的认知,将客户分为几个不同年龄阶段。

分组的话主要是用到了VLOOKUP函数进行分组。

此时得到分组后,我们可以生成数据透视表来查看情况。
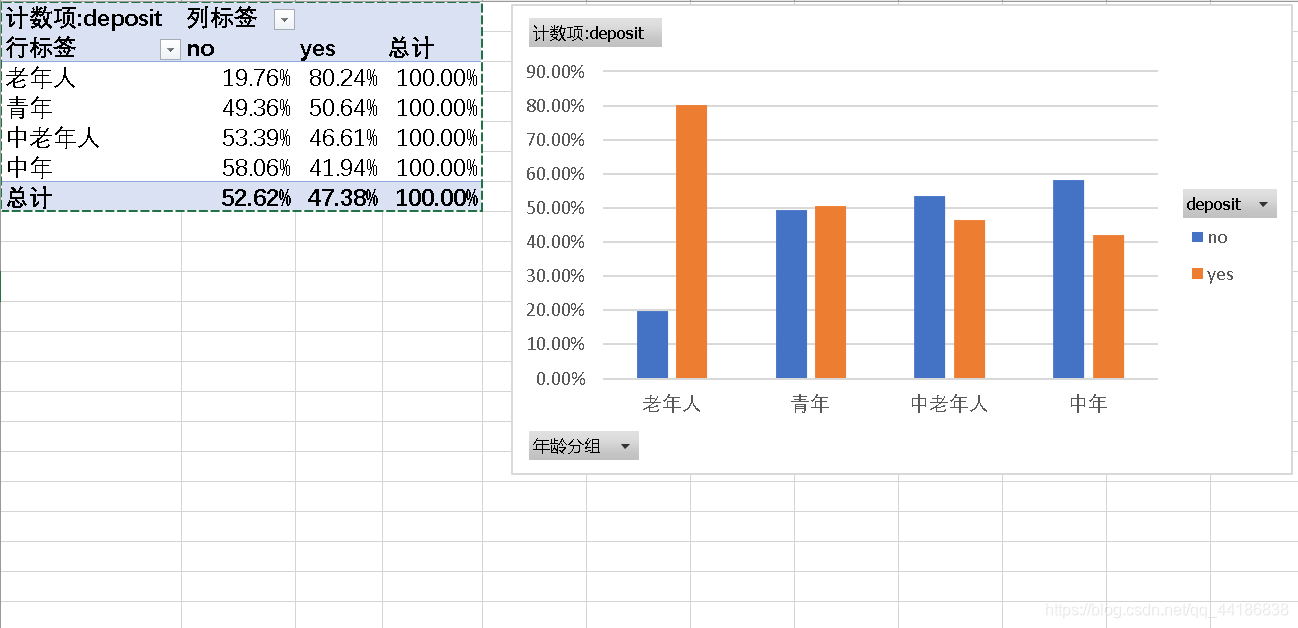
从图当中我们可以明显的看到在老年人群体中最终购买了定期存款的比例最大,为80.2%,而其他群体最终的结果并没有明显的差距。
4.2 失信状况default
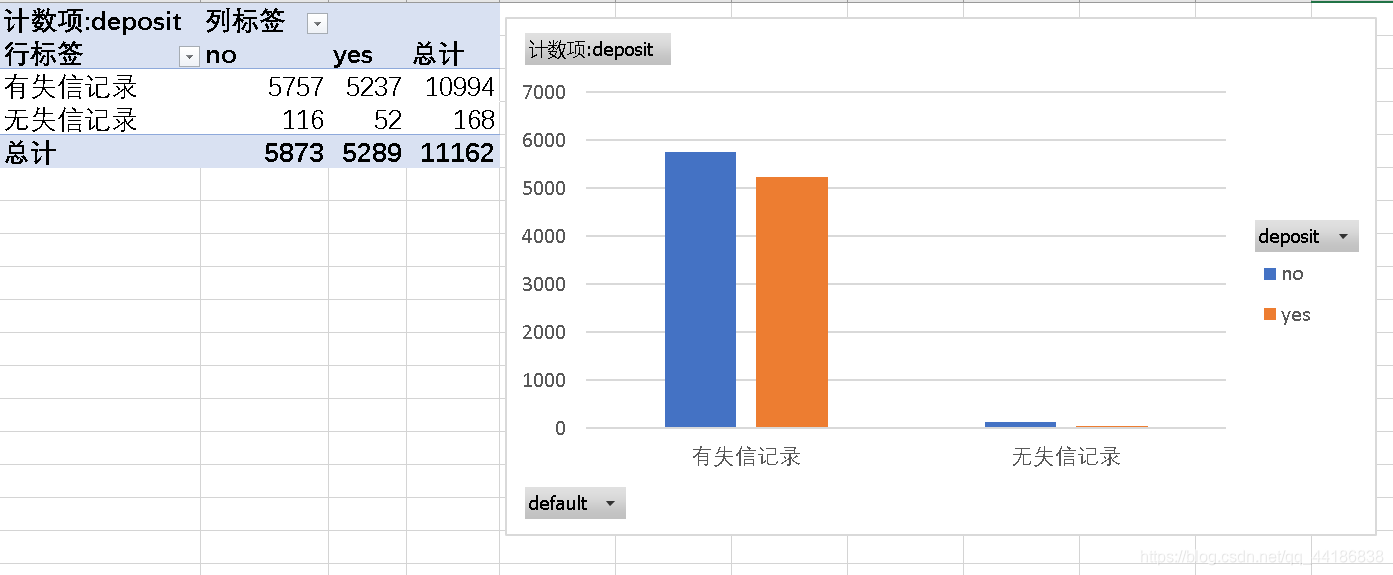
有失信记录的在结果上没有什么差别,无失信记录的最终购买的比例低于没有购买的,但是数据量较小,不能作为参考。
4.3 个人资产balance
同年龄一样,balance是数值型,因而最好先将其分组。
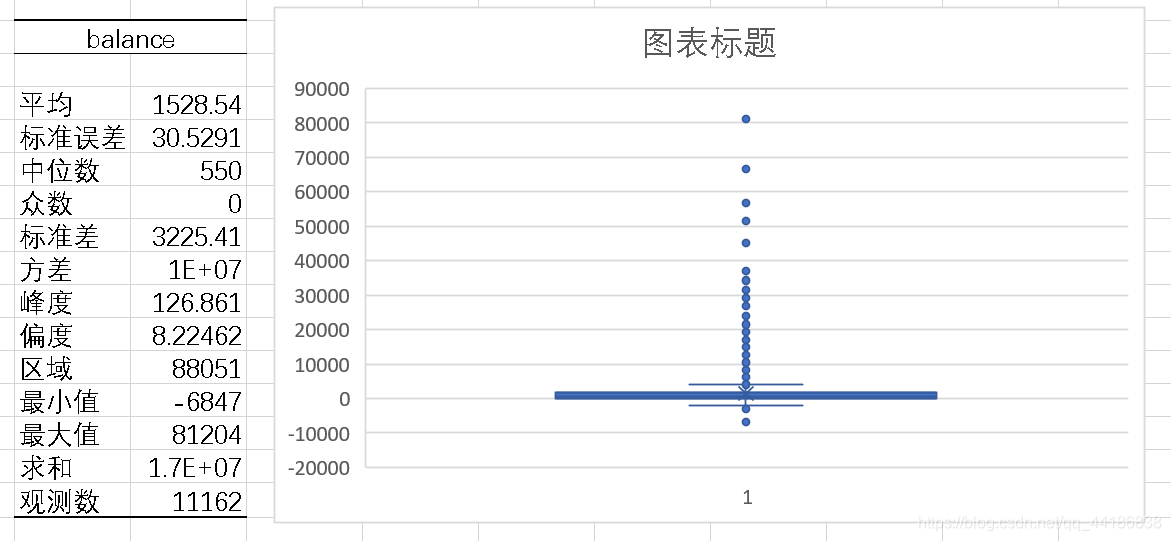
这里我主要采用箱型图来查看balance数据的分布,以便后续进行分组。
可以看到的是数据主要是集中在0-2000之间,有少部分低于该区间,然后有部分大于该区间。
按下图进行分组:

结果如下:
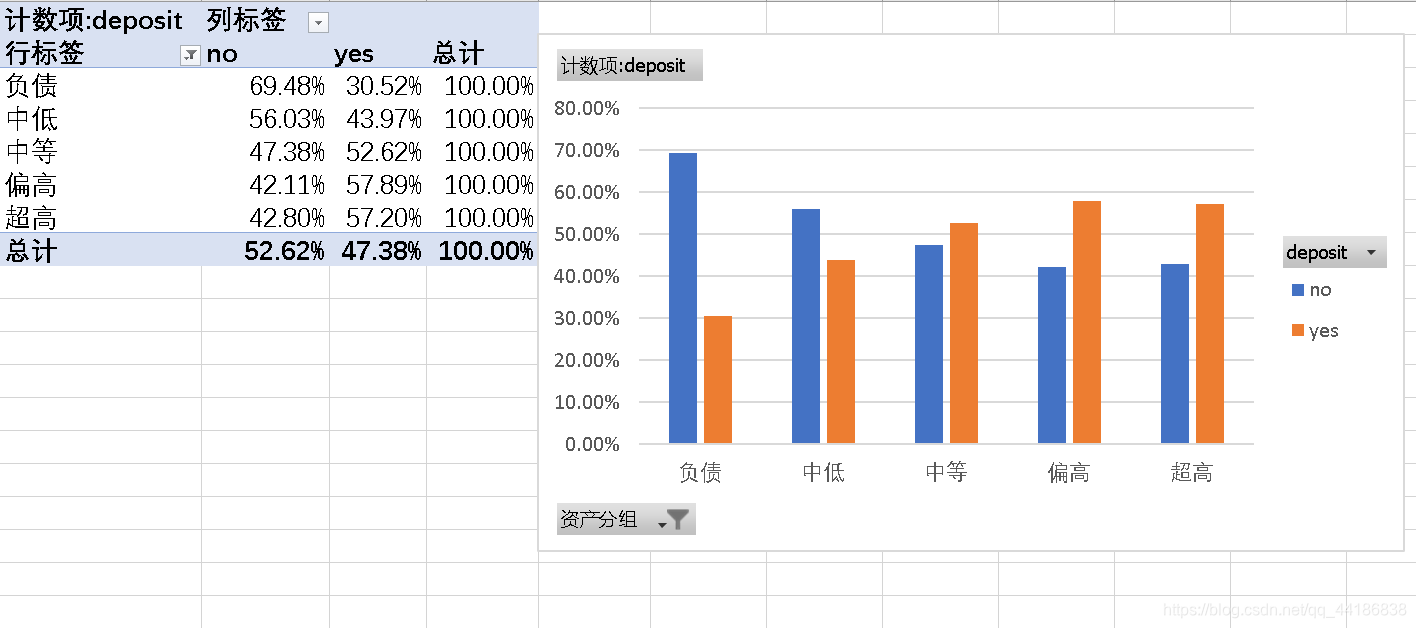
这里主要可以发现的是负资产的客户最终购买的可能性较低,而资产较高的客户购买的可能性稍微大些。
4.4 housing&loan
接下来的房屋贷款和个人贷款,这个我打算放在一起进行分析。
具体如下:
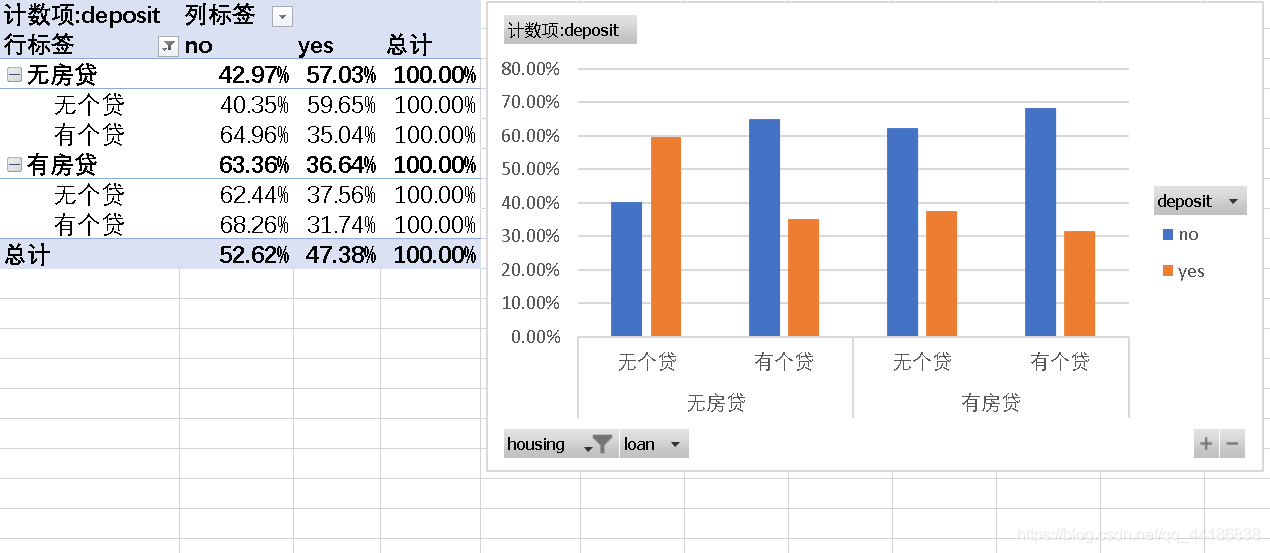
可以看到无房贷和无个人贷款的客户最终购买的可能性最大,为59.65%。其余的只要有任何一个贷款购买的可能性就比较低。
4.5 上次营销结果poutcome
同理,生成透视图查看一下:
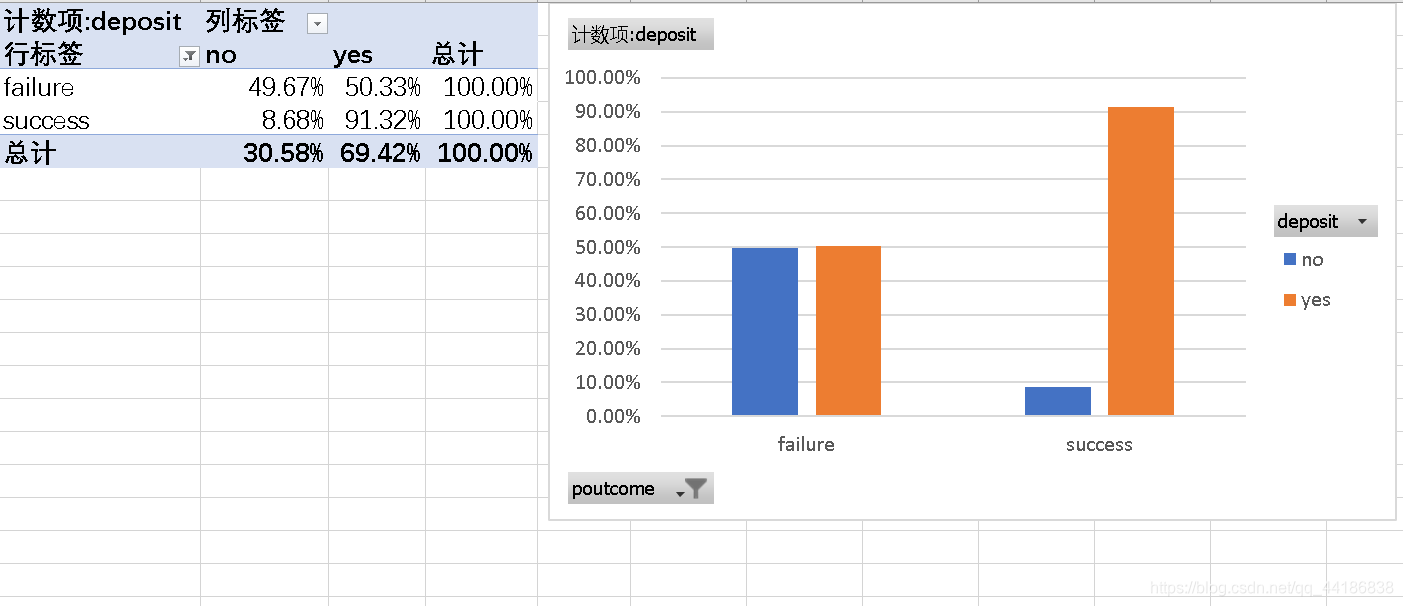
(包括这次在内,当生成透视图时发现有部分数据(如unknown、other)是我们不想要的,记得筛选掉)
从图中我们可以明显发现,上次营销成功的客户这次购买的可能性也极大。
5 总结
结论:从上述结果我们可以发现,老年人且上次营销成功的群体最有可能购买产品,而有贷款且低资产的用户购买的可能性会很小。
PS: 这次没有其他过多的因素考量,如产品实际的业务情况、数据具体来源等,而我主要也是利用自己以往的经验来选取数据进行分析,没有做过多的分析比较。
推荐关注的专栏
👨?👩?👦?👦 机器学习:分享机器学习实战项目和常用模型讲解
👨?👩?👦?👦 数据分析:分享数据分析实战项目和常用技能整理
CSDN@报告,今天也有好好学习