学习pandas这一篇文章就够了!
? pandas的强大相信用过的都觉得很强,对于数据处理而言可以说是必不可缺的。废话少说,开始肝了!
文章目录
一、创建Series和DataFrame
pandas有一维数据,二维和多维,一般我们就只使用一二维
1. 创建Series
? Series是一维,如下所示:
? 直接利用列表创建
list_name = ['Alice','Bob','Cindy','Eric','Halen','Grace']
series = pd.Series(list_name)
print(series)

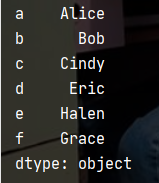
? 可以指定索引,如果不指定就会像上面的例子一样
list_name = ['Alice','Bob','Cindy','Eric','Halen','Grace']
series = pd.Series(list_name,index=['a','b','c','d','e','f'])
print(series)
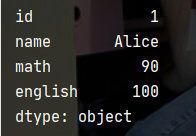
? 利用字典创建
dict = {"id":1,"name": "Alice", "math": 90, "english": 100}
series1 = pd.Series(dict)
print(series1)
2. 创建DataFrame
? DataFrame是二维数据,以下给出了创建的三种方法,结果都是一样的。
# 第一种
test_dict = {'id':[1,2,3,4,5,6],
'name':['Alice','Bob','Cindy','Eric','Halen','Grace'],
'math':[90,99,78,98,97,81],
'english':[100,100,95,78,45,75]}
data = pd.DataFrame(test_dict,index=list('abcdef'))
print(data)
# 第二种
list_test = [[1,2,3,4,5,6],
['Alice','Bob','Cindy','Eric','Halen','Grace'],
[90,99,78,98,97,81],
[100,100,95,78,45,75]]
list_test_new = np.array(list_test).T # 将4行6列转换为6行4列
data2 = pd.DataFrame(list_test_new,index=list('abcdef'),columns=['id','name','math','english'])
print(data2)
# 第三种
list_test = [[1,'Alice',90,100],
[2,'Bob',99,100],
[3,'Cindy',78,98],
[4,'Eric',98,78],
[5,'Halen',97,45],
[6,'Grace',81,75]]
data3 = pd.DataFrame(list_test,index=list('abcdef'),columns=['id','name','math','english'])
print(data3)

二、获取元素
? 这里的例子就取以上的data为例。
? 我将用loc和iloc为大家举例,
? loc就是根据行索引和列名定位,iloc就是根据行列的索引定位。
1. 查找一列或者几列元素(或行)
# 取所有的name和english
print(data.loc[:,['name','english']])
print(data.iloc[:,[1,3]])
这里的引号指的是所有,逗号前表示行,逗号后表示列(在这里是指定的列)

# 取Alice到Eric所有的id、name和english
print(data.loc['a':'d',['id','name','english']])
print(data.iloc[0:4,[0,1,3]])
? 注意,loc中的由于“ : ”不是根据索引定位的,所以取Alice到Eric直接写成 ‘a’:‘d’ 就可以,但是iloc 是根据索引定位的,取Alice到Eric就是(Alice的索引)到(Eric的索引 + 1)才行

print(data['name'])
print(data['name']['b'])

这里补充另外一种方法,就是直接在dataframe后面加上列名和行名,就和loc是一样的,注意只能是名字,而不是索引。
2. 查找符合条件的元素
# 取math大于90的id、name和math
print(data.iloc[:,2]>90) # 对每一元素和90比较,返回布尔值
# 以下这两种方法是一样的
print(data.iloc[list(data.iloc[:,2]>90),0:3]) # iloc定位必须要将series转换为列表才行
print(data.loc[data.iloc[:,2]>90,'id':'math']) # 无需转换(可转可不转)
在这里使用了series的面具用法,意思是找到元素对应的布尔值,然后输出布尔值为True的,如下:

# 取名字长度大于4的所有信息
info_bool1 = data.loc[:,'name'].map(lambda x:True if len(x)>4 else False)
info_bool2 = data.iloc[:,1].map(lambda x:True if len(x)>4 else False)
# info_bool1和info_bool2效果一样
print(info_bool2)
print(data.loc[list(info_bool2),:])
print(data.iloc[list(info_bool2),:])
这里的map是series专门的函数,它的作用就是遍历series中的每一个元素,然后在使用lambda匿名函数对值进行处理。

以下这种方法(函数)效果也是一样的
def len_name(x):
if len(x)>4:
return True
else :
return False
info_bool3 = data.iloc[:,1].map(len_name)
print(data.iloc[list(info_bool3),:])
# 取名字长度大于4并且math大于90
info_bool4 = data.iloc[:,1].map(lambda x:True if len(x)>4 else False) # 名字长度大于4
data_info5 = data.iloc[list(info_bool4),:] # 一个所有名字长度大于4的新的dataframe
print(data_info5.iloc[list(data_info5.iloc[:,2]>90),:])

3. 获取列名和索引以及修改
? (1)获取索引、列名和所有元素值
print(list(data.index)) # 索引
print(list(data.columns)) # 列名
print(data.values) # 输出所有值,是一个向量
print(data.values.tolist()) # 可将其转换为列表

? (2)修改列名
data1 = data.rename(columns={'id':'ID','name':'NAME'}) # 重新命名
print(data1)

? (3)重置索引
df1=data1.reset_index() # 重置索引默认为0,1,2,
print(df1)
df2 = data1.reset_index(drop=True) # 删除index列
print(df2)

? (4)将dataframe中的某一列设置为索引
df3 = data.set_index('name') # 将name列设置为设置索引
print(df3)
print(df3.loc['Bob':'Halen',:]) # 定位
df4 = df3.set_index('id')
print(df4)
? 将data中的name列设置为索引,代替了原来的索引,df4在df3的基础上将id设置为索引,代替了原来的name列。

三、基本操作
1. 删除指定行列
print(data.drop(['a','f'],axis=0)) # 删除索引名为a和f的行
print(data.drop(['id','name'],axis=1)) # 删除列名为id和name的列
print(data.drop(labels='c',axis='index')) # 删除指定单行
print(data.drop(labels=['a','f'],axis=0)) # 删除指定多行
print(data.drop(labels='id',axis='columns')) # 删除指定列
? 重点就是要指定行或列名
? 在这里**axis=0或者axis=‘index’**表示行,**axis=1或者axis=‘columns’**表示列
? 注意有时候不必专门去记忆axis=0和axis=1,因为有些时候axis=0反而表示列,1表示行。
2. 连接操作
? (1)准备数据
df1 = data.iloc[:,0:2]
df2 = data.iloc[:,2:]
df3 = pd.DataFrame({'math':[89,75,36,59],'english':[94,89,16,47]})

? (2)横向连接
print(df1,'\n',df2)
new_data = pd.concat([df2,df1],axis='columns') # 或者用axis=1
print(new_data)
? 注意,**[df2,df1]**有表示先后顺序

? (3)纵向连接
new_data2 = pd.concat([df2,df1],axis=0) # 或者axis=index
print(new_data2)

? 可以看到这里的索引不是一样的,所以可以重置索引
new_data3 = new_data2.reset_index(drop=True) # 重置索引
print(new_data3)

3. one-hot编码(独热编码)
? 在统计一些人的性别的时候,我们需要将其转换为数值,就可以用0和1来代替。同时也带来了问题,是男为1,还是女为1呢,因为有些人认为这会影响男权主义和女权主义,所以就有了one-hot编码,那么它是什么样的呢?

这里的男和女这两列就是独热编码。
有几类就有几列,比如说这里只有男和女,那么就有两列。
data = pd.DataFrame(np.arange(16).reshape(4,-1),columns=list('abcd'))
print(data)

data_one_hot = pd.get_dummies(data.iloc[:,0],prefix='a') # 设置前缀
print(data_one_hot)
这里对a进行独热编码,a中有4类那么就有4列。

当然如果对有排名先后的就不能用独热编码。
四、数据预处理(实战)
1. 导入数据以及清洗数据
? 导入导出数据就是利用read_excel和read_csv来导入,这里主要就是说明在导入时应该注意参数设置以及修改数据。
? 这是原始数据:


(1)导入数据
data2 = pd.read_excel(r'C:\Users\86178\Desktop\成绩信息表.xlsx',header=1)
print(data2)
? 在这里可以看到我们需要将第二行的数据作为表头就用header=1来指定。

(2)修改列名
输出列名就可以看到此时的列名十分复杂,而且有的没有是unnamed,所以需要将其修改。
print(data2.columns)

? 修改方法(详细可见上获取列名和索引以及修改):
new_data2 = data2.rename(columns={'学年学期\n(如:2018-2019-2)':'学年学期','Unnamed: 5':'平时成绩1','实验成绩':'平时成绩2','Unnamed: 7':'平时成绩3'})
print(list(new_data2.columns))

这样就修改成功了。
(3)删除冗余行
可以看到


开头和末尾存在冗余行,需要将其删除:
new_data3 = new_data2.drop(labels=[0,44],axis=0) # 删除指定行
new_data3 = new_data3.reset_index(drop=True) # 重置索引
print(new_data3)

2. 类型转换
print(new_data3.dtypes) # 查看每一列的类型

其中的期中成绩,平时成绩1,平时成绩2,平时成绩3,期末成绩,必须是float或者int型,因为这样才统计计算。同时学生学生学号也不能为float型的,因为不方便读。
list_columns = ['期中成绩', '平时成绩1', '平时成绩2', '平时成绩3', '期末成绩']
for i in list_columns:
new_data3[i] = new_data3[i].astype(np.float16)
new_data3['学生学号'] = new_data3['学生学号'].astype('string')
new_data3['学生学号'] = new_data3['学生学号'].map(lambda x:x[0:10]) # 将数据清洗
print(new_data3.dtypes)
print(new_data3['学生学号'])

? 这样不仅仅把学号的格式规范了,同时也把成绩这几列转换为float型了,也方便计算了。
3. 空值处理
(1)查看全局是否存在空值
print(new_data3.isnull())
print(new_data3.isna()) # 这两种方法是等价的,判别每一个元素是否为空

当为True时表示为空,反之不为空。但是一般都不这样使用,除非数据少时,这样能直接看出。
print(new_data3.isnull().values.any()) # any表示任何的,所以就是判断全局是否有空值

这是判断全局是否存在空值,如果为True,表示全局存在空值,否则就没有。
(2)查看每列或每行是否存在空值及数量
print(new_data3.apply(lambda x:x.isnull().values.any())) # 每列是否出现空值
print(new_data3.apply(lambda x:x.isnull().sum())) # 每列空值的个数


这里的apply是dataframe里面专用的遍历每行每列的,和series中的map一样。
(3)删除空值
DataFrame.dropna(axis=0, , how='any' ,there=None, subset=None, inplace=False)
函数作用:删除含有空值的行或列
axis:维度.axis=0表示index行,axis=1表示colums列,默认为0
how:"all"表示这一行或列中的元素全部缺失(为nan)才删除这一行或列,"any"表示这一行或列中只要有元素缺失,就删除这一行或列
thresh:行或列中至少保留n个数据。
当一行中10个数据,当thresh=5,允许有5个空值,大于5的行则删除。
当thresh=6,允许有4个空值,大于4的行则删除。
当thresh=8,允许有2个空值,大于2的行则删除。
当thresh=9,允许有1个空值,大于1的行则删除。
当thresh=10,允许有0个空值,存在空值的行就删除。
总结:当thresh的值越大,删除的行就越多。(thresh)+(允许为空值的数)= 行中元素个数
subset:在某列的子集中选择出现了缺失值的列删除,不在子集中的含有缺失值得列或行不会删除(有axis决定是行还是列)。换句话说,指定删除某一列。eg:subset=['name','id']指定这两列。如果存在空值则删除这行。
inplace:新数据是存为副本还是直接在原数据上进行修改
这里是drop的使用方法,重点掌握thresh和subset,这两个在特定的情况下能更好清理数据。
list_columns = ['期中成绩', '平时成绩1', '平时成绩2', '平时成绩3', '期末成绩']
new_data4 = new_data3.dropna(axis=0,subset=list_columns,thresh=4)
print(new_data4)
针对这里,设定的是,指定成绩这几列,将设置为,thresh=4。表示在成绩这五列中,如果存在空值数大于等于3的删除该行,允许在成绩这5列中可以有1个空值,大于1则删除(总数为5,即thresh最高也就是5)。
那么大家有没有想过为什么要怎样设计呢?
如果数据每行中的缺少量过大,则填充起来的可用性也就不大了,所以设计thresh=4,允许有一个空值存在,超过一的行就删除。
当时候数据量缺失不是很大时,还可以才用填充的方式,也就是下面讲的方法
(4)填充空值
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
函数作用:填充缺失值
value:需要用什么值去填充缺失值
axis:确定填充维度,从行开始或是从列开始
method:ffill:用缺失值前面的一个值代替缺失值,如果axis =1. 那么就是横向的前面的值替换后面的缺失值,如果axis=0,那么则是上面的值替换下面的缺失值。backfill/bfill.缺失值后面的一个值
limit:确定填充的个数,如果limit=2, 则只填充两个缺失值
? 填充方式一般有:
-
指定值填充。
print(new_data4.fillna(0)) print(new_data4.fillna(axis=1,method='ffill')) # 前面一个值代替 print(new_data4.fillna(axis=1,method='bfill')) -
均值填充。
注意,这里的均值填充是值计算出除去空值外的平均值,并用它去填充空值,而不是加上空值计算出的平均值。
print(new_data4.iloc[:,4:9].apply(lambda x:x.fillna(x.mean())))
指定成绩这五列,计算均值,然后填充。
这里的**x.mean()**是计算这一列的均值,类似的还有,**x.std()**计算方差,x.sum()
4. 数据归一化
在我的另一篇文章中有讲到归一化――波士顿房价预测(深度学习)与找到影响房价的决定性因素(最速下降法) 归一化的作用就是消除量纲的影响
在这里还是讲一下,归一化一般有两种方法:
-
最大最小归一化

有两种方法可以实现:
第一种,直接利用公式计算,
new_data6_1 = new_data5.apply(lambda x:(x - x.min())/(x.max() - x.min())) print(new_data6_1)
第二种,调用库计算,这种方法我觉得是很好的,主要是能还原数据。
from sklearn.preprocessing import MinMaxScaler sc = MinMaxScaler(feature_range=(0,1)) new_data6_2 = sc.fit_transform(new_data5) print(new_data6_2)
print(sc.inverse_transform(new_data6_2)) # 还原数据
还原数据主要是还原结果,这样很方便,在这里直接举例还原原数据。

值得提一下的是,这两种方法不管是哪一种都是对每列归一化(在每列中找到最大最小值计算),而不是全局的,如果对全局归一化那就相当于没有归一化了。
-
正态分布标准化
对成正态分布的数据,进行标准归一化

new_data7 = new_data5.apply(lambda x:(x-x.mean())/x.std())
print(new_data7)

? 到了这里pandas数据预处理基本上已经结束了,接下来可以去预测,去得出结论等等,这些后面我会继续出文章的。
五、总结
? pandas的用法有很多,但是这里差不多已经涵盖了大多数,不过总有一些漏网之鱼,哈哈哈。写了好多天终于写完了,希望这篇文章能够帮到你。文章中出现错误的,或者没有写完整的欢迎评轮,我会继续更新的。
? 你的点赞收藏就是对我最大的鼓励了。