论文名称:PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction
作者:Hengyi Zheng, Rui Wen, Xi Chen, Yifan Yang, Yunyan Zhang, Ziheng Zhang, Ningyu Zhang, Bin Qin, Ming Xu, Yefeng Zheng
机构:Information Technology Center, Shenzhen University
Tencent Jarvis Lab, Shenzhen, China
Platform and Content Group, Tencent
Zhejiang University
源码实现:https://github.com/hy-struggle/PRGC
实体信息提取技术演进
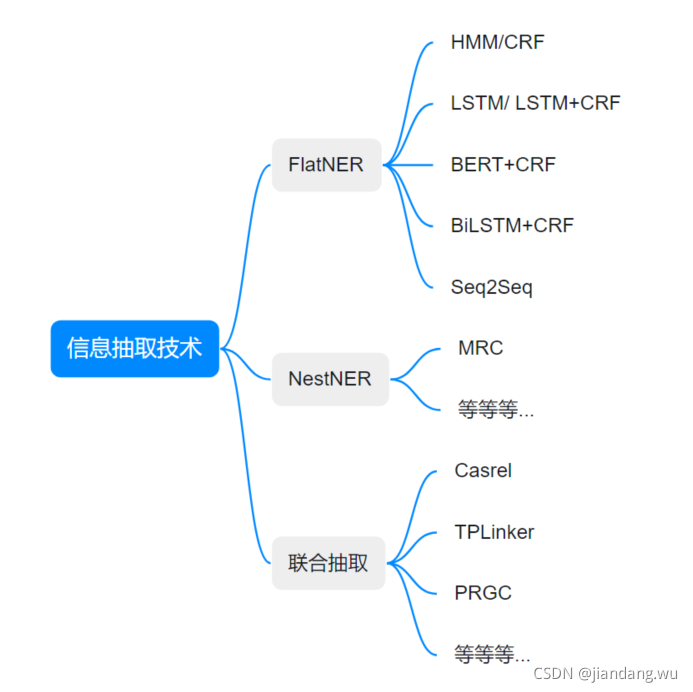
联合抽取背景
从一开始的先识别实体再对每个实体对进行关系分类的流水线式方法,再到基于特征的模型和神经网络模型开始采用联合学习实体和关系的方法,在关系抽取任务上取得越来越好的表现,但是在多三元组实体重叠场景下却都不能有效处理。
问题:主要问题有两个:
- 多三元组重叠问题:同一个实体参与到不同的关系时分类器会混乱,或者不同实体同一关系等等情况。
- 暴露偏差(Exposure Bias)问题:即训练时的输入为ground truth,而预测时的输入为上一个模块
的输出,导致训练与与测试时的输入分布不一致。
下图是一句话中三种不同的重叠三元组情形:
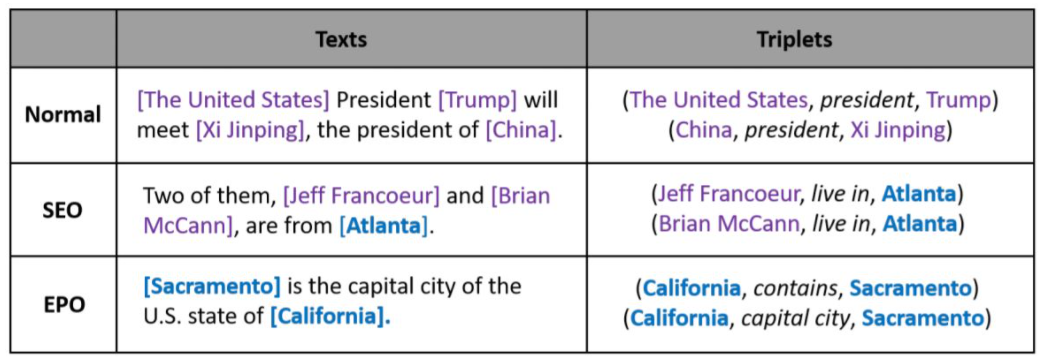
SEO表示一个实体参与到了多个关系中的情形, 即实体 Atlanta 与实体 Jeff Francoeur 有 live in 关系, 也与实体 Brian McCann 存在 live in 关系。
EPO表示两个实体有两个完全不同的关系的情形, 实体 California 和实体 Sacramento 既有 contains 关系,也有 capital 关系;
―――――――――――――――――――――――――――――――――――――――――
关系抽取通常用三元组(subject, relation, object)表示。解决关系抽取的常见思路有两种:
(1)抽取实体,预测实体间可能存在的关系。采用先抽取实体,已知两个实体subject和object后,采用分类模型得到实体间的关系,这种方式称为pipline式抽取;
(2)同时抽取实体和实体间的关系,这种方式称为联合抽取,需要训练时多任务训练抽取实体和关系的模型loss,预测时不同模型模块预测关系和实体边界。
―――――――――――――――――――――――――――――――――――――――――
联合抽取related work
MRC的提出,是解决的nest NER和flat NER合并的问题。建议感兴趣的同学看一下这篇论文,实现很简单,但是算是一种任务的解决方案转移到另一种任务上的成功案例。
https://arxiv.org/pdf/1910.11476.pdf
question的构建方式非常重要,因为question会将label的先验知识编码进去,并对最终的模型效果有显著的影响。论文使用标注指南作为question(标注指南是构造NER数据集时提供给标注者的简短的标注说明,如下图所示)

MRC4ERE,包含了大量的多样问题模板生成问题,query人工设置。
CasRel
学习关系特定的尾实体标注器,即对于每一个头实体s,我们将它进行所有关系特定标注器的映射,找出正确的尾实体o。当然若对于指定头实体s,在某个关系的特定标注器映射下,找不到正确的尾实体,则认为s在该关系下映射到了“null”型尾实体。(s表示头实体,o表示尾实体,r表示关系),这个模型存在严重的信息曝光误差问题。
TPLinker
本文主要的贡献在于提出了一个新颖的标注方式,称为handshaking tagging scheme。使用这种方式,可以在避免暴露偏差的情况下识别重叠关系。但是,为了避免曝光偏差,它利用了相当复杂的解码器,导致了稀疏的标签,关系冗余,导致span的提取能力差
本文提出了基于实体链接的实体-关系联合抽取方法,能够在识别重叠关系的同时避免引入暴露偏差。
PRGC
设计三个任务联合训练
- 关系判断
- 基于候选关系列表做实体抽取(头实体、尾实体)
- Subject-object对齐
模型介绍
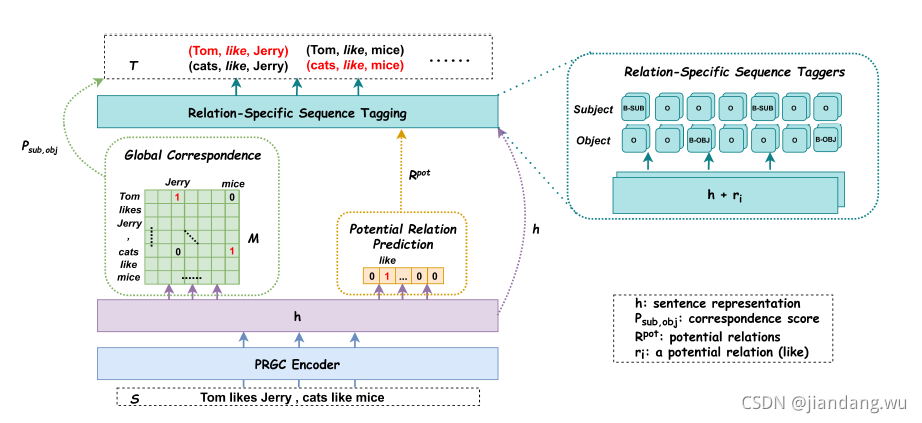
算法流程:
-
Relation Judgement
首先预测潜在关系的子集,只需要从这些潜在实体里提取子集。
给定embedding h,潜在关系预测模块如下:
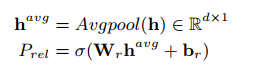
问题建模为多标签二分类任务,比如有56种关系,那就有56个sigmoid。
如果概率超过阈值就认为存在关系,否则标记为0。
接下来只需要应用抽取的子集对应的embedding,而不是所有embedding -
Entity Extraction
依次解码主体和客体,是因为解决实体重叠问题。
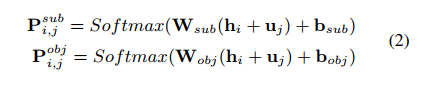
因为crf无法解决实体重叠问题,所以没有使用传统的lstm-crf做命名实体识别,而是直接上全连接。 -
Subject-object Alignment
对于主客体对齐,设计了一个关系无关的全局对应矩阵,用于确定特定的主客体。
给定一个句子,模型先预测一个可能存在关系的子集,以及得到一个全局矩阵。
执行序列标注,标注存在的主体客体。最后枚举所有实体对,由全局矩阵裁剪。
尽管它引入了通常提到的曝光偏差,但是仍有优越性。
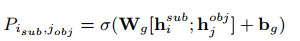
模型训练策略
三个任务联合训练,损失函数是:

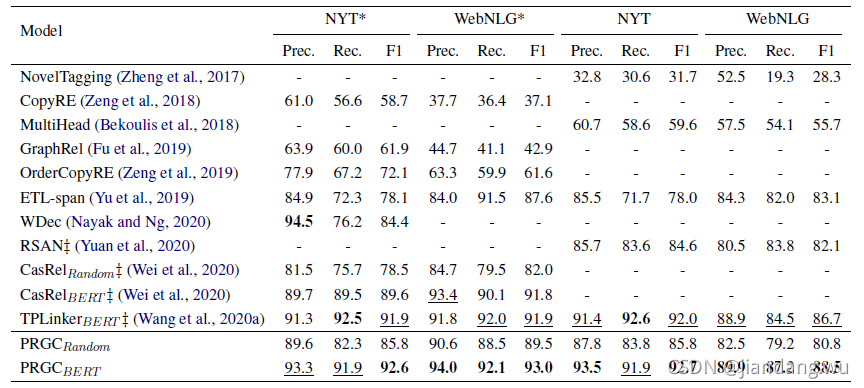
模型效果
关系抽取:
实体抽取效果:
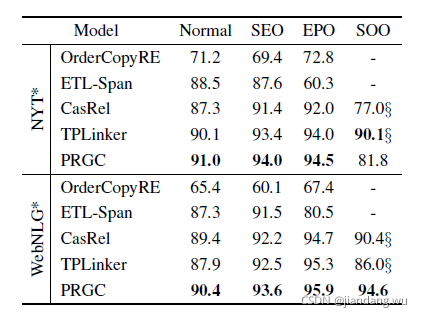
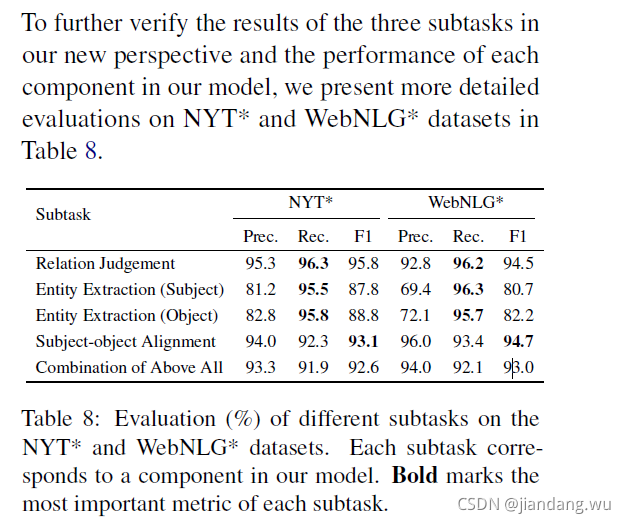
各个子任务上的效果
优点:1. 不用自己设置问题,全部参数和配置由模型训练获得
2. 多个loss合并训练,增加模型训练难度,提供模型的学习能力和泛化能力
缺点:依然存在信息曝光问题,预测关系,加入关系,预测实体对
联想番外篇
预训练语言模型的演变,Mask策略的演变:
- bert
随机15%掩码一个字,其中,80%的时候是[MASK],10%的时候是随机的其他token,10%的时候是原来的token。 - ernie
ERNIE在掩码时额外使用了短语级别和实体级别的掩码,藉此向语言模型中引入了知识。 - roberta
RoBERTa采用动态masking,它没有在预处理的时候执行 masking,而是在把序列输入模型时动态生成 mask,并且遮挡词不是固定的,有利于模型学习各种掩码策略下语料表现出来的特征。掩码实体,取消NSP,加入NOP - spanbert
掩码一个片段:片段掩码、实体掩码、段落掩码、词掩码,span boundary objective
为什么预训练模型的效果越来越好?
- 充分训练
- 足够的数据
- 设计越来越困难的训练任务:多loss联合
那三元组联合抽取模型的效果较前面几种模型好,也就能理解了
使用场景思考与讨论:
三元组抽取,(实体,关系,实体)
- 修饰词+品类词,修饰关系的三元组抽取,构造场景词、五级品类词、标题压缩等等
- 等等吧,大家可以根据自己的业务场景构建相应的应用
参考论文
MRC:https://arxiv.org/abs/1910.11476
Casrel:https://arxiv.org/pdf/1909.03227.pdf
TPLinker:https://arxiv.org/pdf/2010.13415.pdf