一、利用excel做线性回归
1.启动步骤
在excel里数据一栏找到数据分析,然后即可开始进行线性回归,如果没有“数据分析”选项卡,可以在“文件”选项卡里选择“加载项”,选择“转到”,如下:

勾选需要的工具即可
2.数据分析
导入身高体重数据集后,采集前20项进行数据分析,可得如下结果:
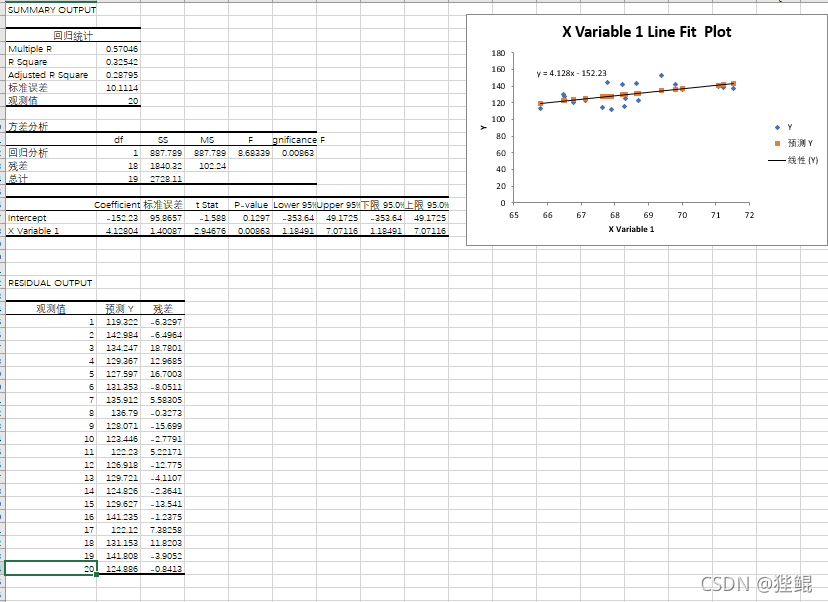
- 相关系数(Multiple):0.570
- P值(P-value):0.01<P<0.005,故回归方程成立。
此时线性回归方程为
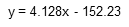
接下来采集前200项再来看一下
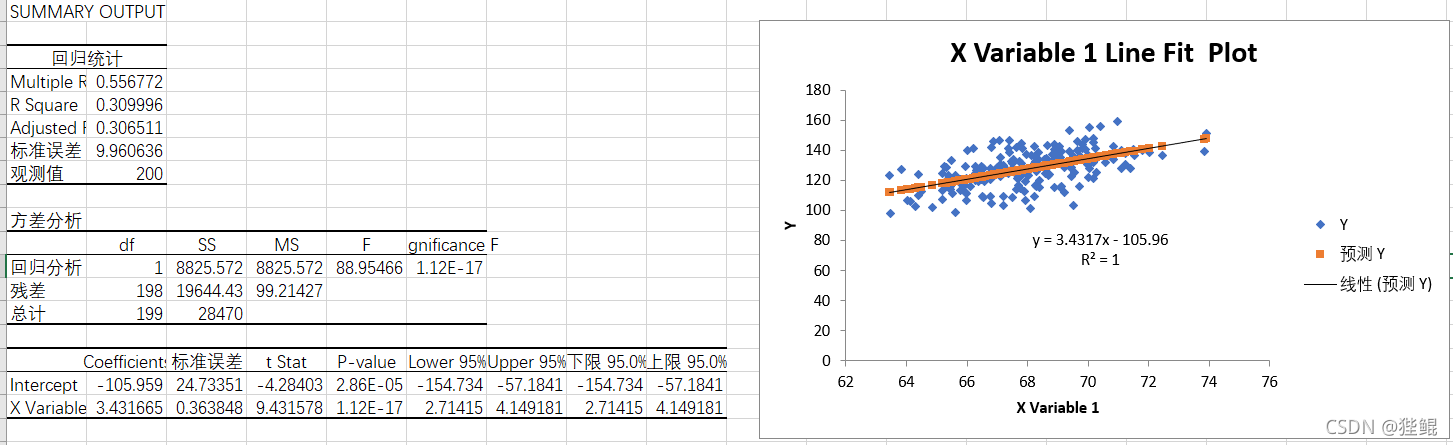
- 相关系数(Multiple):0.556
- P值(P-value):0.01<P<0.005,故回归方程成立。
此时线性回归方程为
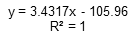
前两千组数据:
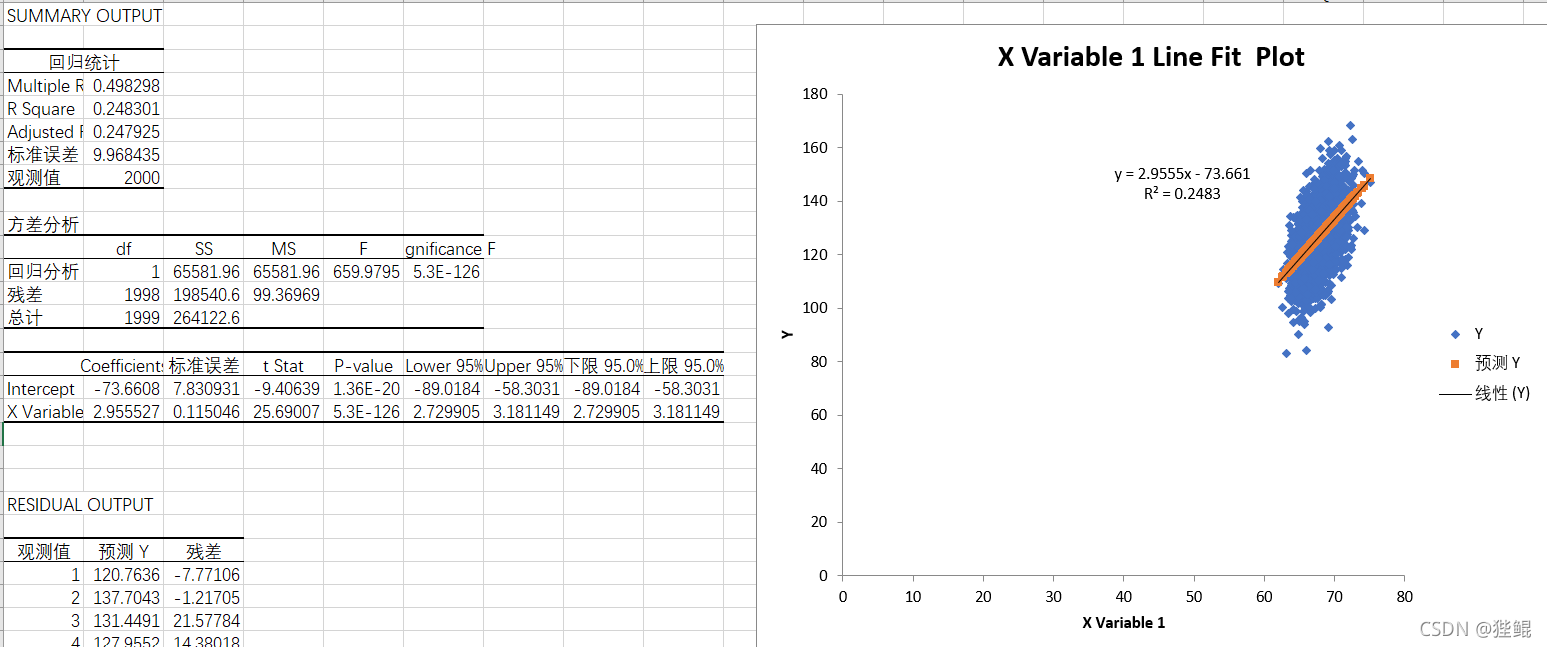
- 相关系数(Multiple):0.498
- P值(P-value):0.01<P<0.005,故回归方程成立。
此时线性回归方程为
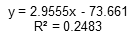
可以看到当数据变多以后,R^2的值变化极大
二、jupyter编程
1.数据导入
下载好软件之后,打开

会出现以下界面

这个界面用于连接web和你的本地机器,在使用过程中是不可以关闭的。
软件会自动打开,导入我们的数据集(注意:导入之后要点击上传)

2.不使用第三方库,最小二乘法编码
在新建的python文件内输入以下代码:
import pandas as pd
import numpy as np
import math
#准备数据
p=pd.read_excel('weights_heights(身高-体重数据集).xls','weights_heights')
#根据自己的需要添加,这里选择前20行数据
p1=p.head(20)
x=p1["Height"]
y=p1["Weight"]
# 平均值
x_mean = np.mean(x)
y_mean = np.mean(y)
#x(或y)列的总数(即n)
xsize = x.size
zi=((x-x_mean)*(y-y_mean)).sum()
mu=((x-x_mean)*(x-x_mean)).sum()
n=((y-y_mean)*(y-y_mean)).sum()
# 参数a b
a = zi / mu
b = y_mean - a * x_mean
#相关系数R的平方
m=((zi/math.sqrt(mu*n))**2)
# 这里对参数保留4位有效数字
a = np.around(a,decimals=4)
b = np.around(b,decimals=4)
m = np.around(m,decimals=4)
print(f'回归线方程:y = {a}x +({b})')
print(f'相关回归系数为{m}')
#借助第三方库skleran画出拟合曲线
y1 = a*x + b
plt.scatter(x,y)
plt.plot(x,y1,c='r')
以下为测试结果
前20项数据结果
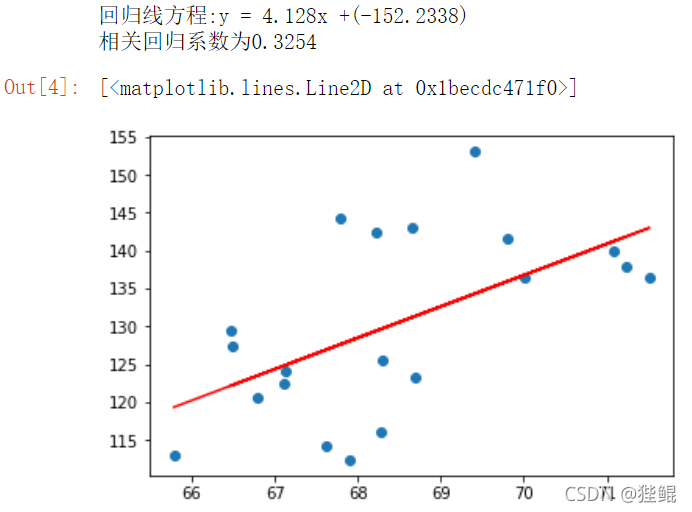
前200项数据结果
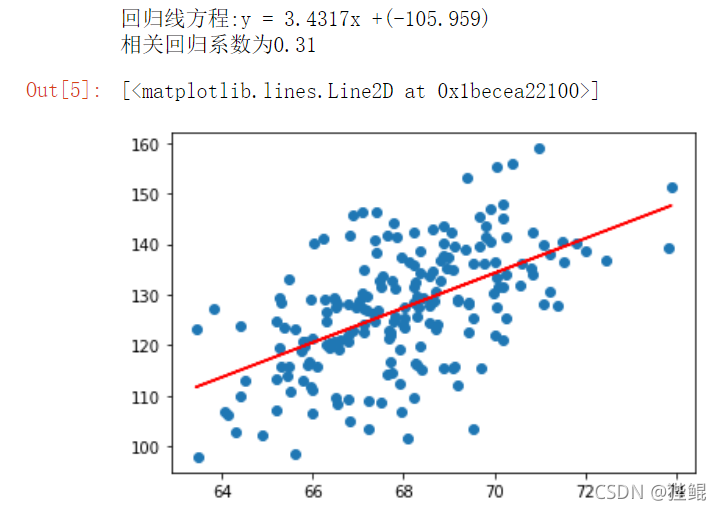
前2000项数据结果

3.使用skleran编码
代码如下:
# 导入所需的模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
p=pd.read_excel('weights_heights(身高-体重数据集).xls','weights_heights')
#读取数据行数
p1=p.head(20)
x=p1["Height"]
y=p1["Weight"]
# 数据处理
# sklearn 拟合输入输出一般都是二维数组,这里将一维转换为二维。
y = np.array(y).reshape(-1, 1)
x = np.array(x).reshape(-1, 1)
# 拟合
reg = LinearRegression()
reg.fit(x,y)
a = reg.coef_[0][0] # 系数
b = reg.intercept_[0] # 截距
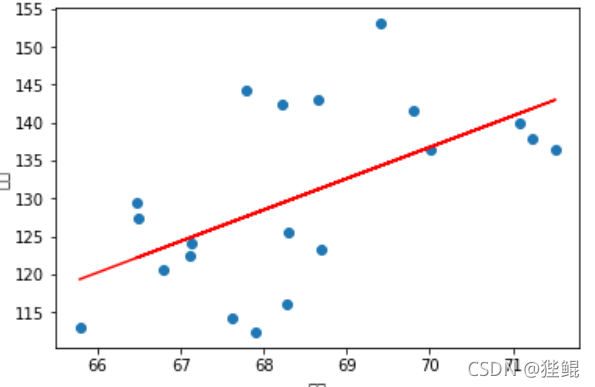
print('拟合的方程为:Y = %.4fX + (%.4f)' % (a, b))
c=reg.score(x,y) # 相关系数
print(f'相关回归系数为%.4f'%c)
# 可视化
prediction = reg.predict(y)
plt.xlabel('身高')
plt.ylabel('体重')
plt.scatter(x,y)
y1 = a*x + b
plt.plot(x,y1,c='r')
前20组数据
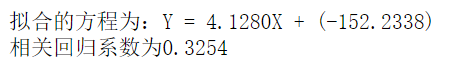
前200组数据
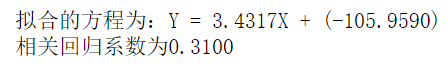
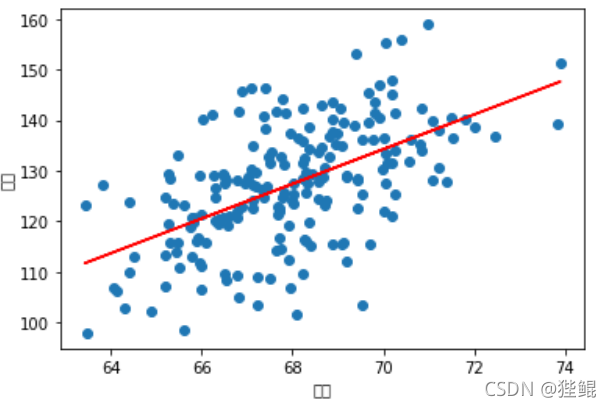
前2000组数据
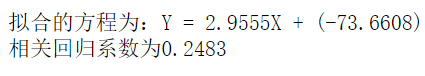
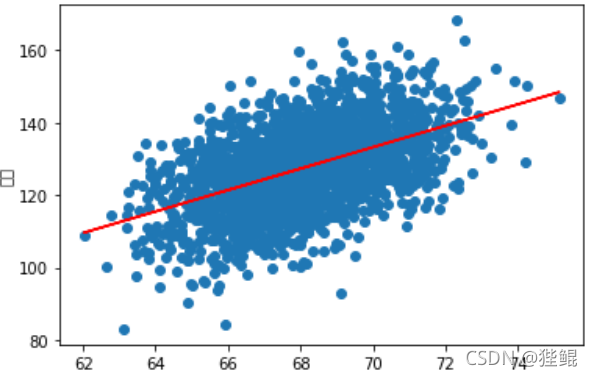
三、总结
三种方式做出的结果大同小异,excel虽然方便且轻松,但是使用jupyter更有助于我们了解机器学习的内在算法与线性回归的相关知识。