一文带你了解《知识图谱》新技术

自然语言处理
自然语言处理发展历程(1)
50-60年代:自然语言处理研究领域是作为人工智能的应用发展起来的
- 最早的自然语言理解方面的研究工作是机器翻译,20世纪 60年代,国外对机器翻译曾有大规模的研究
- 普遍采用基于规则的方法,或者基于知识库的方法,在限定领域取得成功
- 人们低估了自然语言的复杂性,在开放领域遇到很大的困难
- 1966年,美国科学院语言自动处理咨询委员会公布了《语言与机器》,否定了机译的可行性
自然语言处理发展历程(2)
90年代开始:随着大规模词典和真实语料库的研制,给自然语言处理领域的研究带来了巨大变化
- 基于语料库的统计自然语言学习成为一种重要的方法
- 自然语言处理系统面向大规模真实文本的处理,研制的系统开始面向实用
- 机器翻译:统计机器翻译
- 信息抽取:系统并不要求能对自然语言文本进行深层理解,而是从中抽取一些有用信息,作为自然语言部分理解的一种形式
- 统计自然语言学习方法受限于训练集的规模,过拟合问题严重,推广能力不足
自然语言处理发展历程(3)
近几年
- 深度学习方法基于分布学习词语的语义,在自然语言处理的很多任务中取得了很好的效果。
- 基于深度学习的自然语言处理方法
- 神经机器翻译
随着Web2.0的普及,网络上积累规模巨大的User Generated Content,为建立大规模知识库奠定基础
- 基于知识的方法在开放域自然语言处理处理任务中的应用成为可能
基于知识的方法和基于统计的方法的融合受到关注
知识图谱
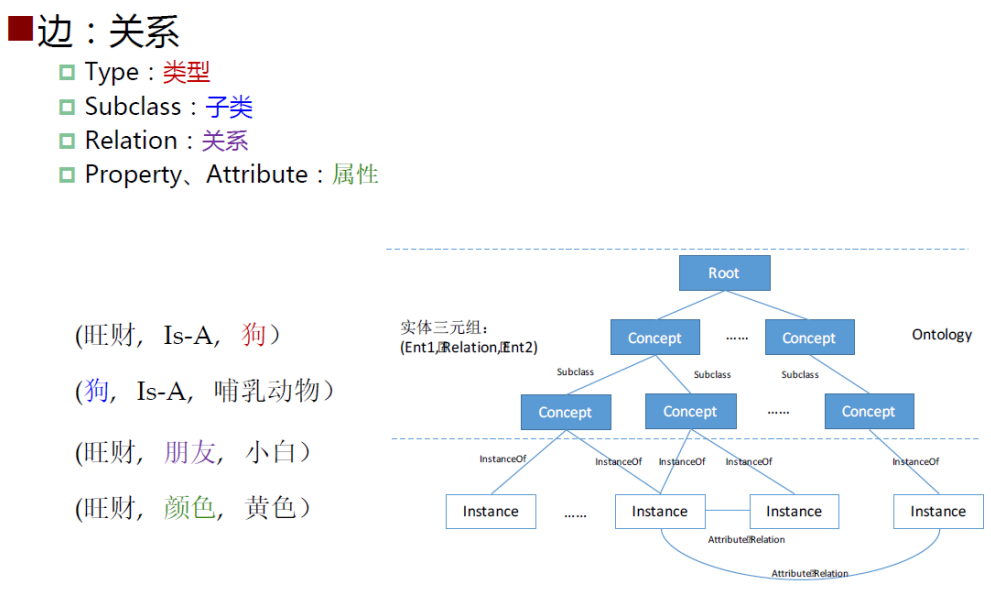
知识图谱是一种基于图的数据结构,由节点(node)和边(Edge)组成,每个节点表示一个“实体”,每条边为实体与实体之间的“关系”,知识图谱本质上是语义网络。
知识图谱描述现实世界中存在的实体以及实体之间的关 系,已被广泛应用于智能搜索、智能问答、个性化推荐、内容分发等领域。
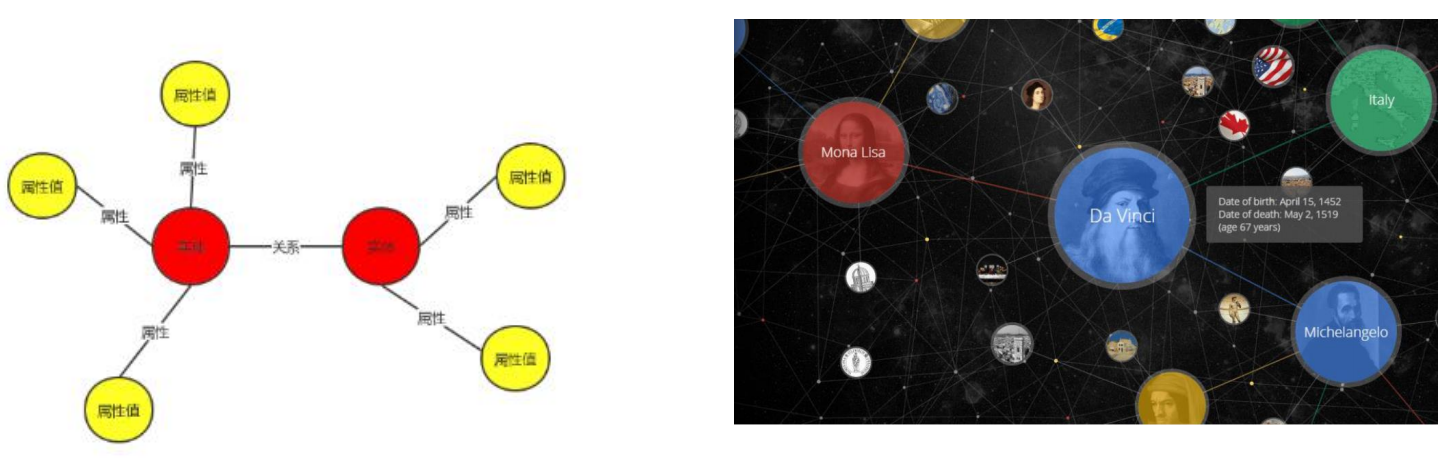
基本形式为(实体1-关系-实体2)、(实体-属性-属性值)。
- 实体:有区别性且独立存在的事物。如某个国家:中国、英国等;某个城市:北京、伦敦等。
- 属性值:实体指向的属性的值。例如中国(实体)面积(属性)960万平方公里(属性值)。
- 关系:把图节点(实体、语义类、属性值)映射到布尔值的函数。
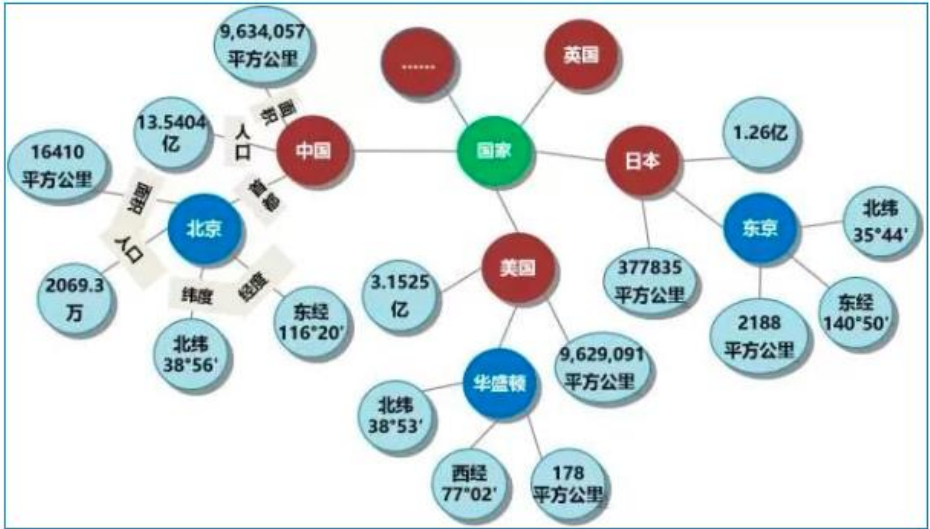
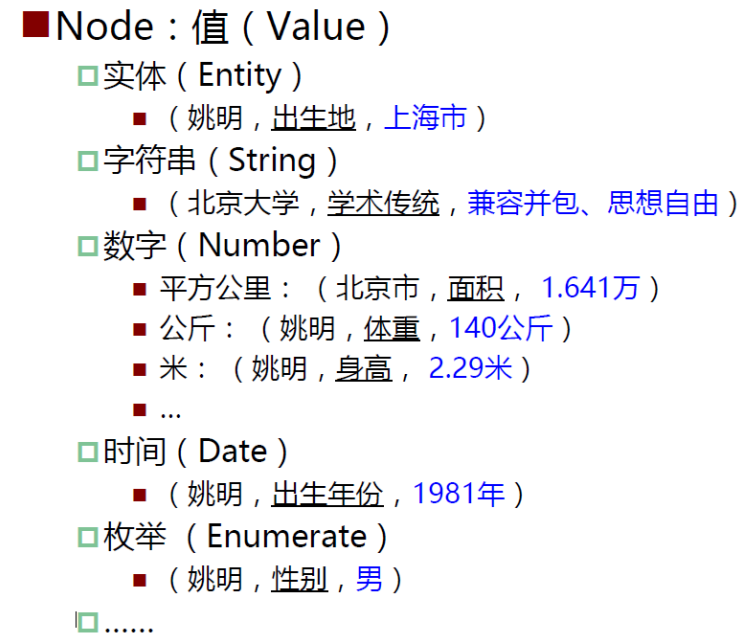


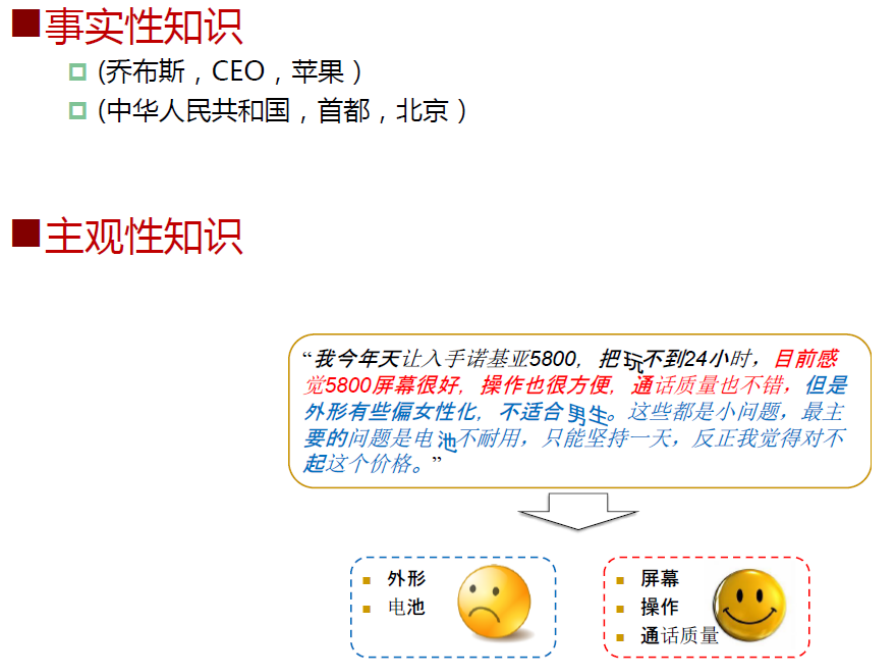
知识图谱中的知识

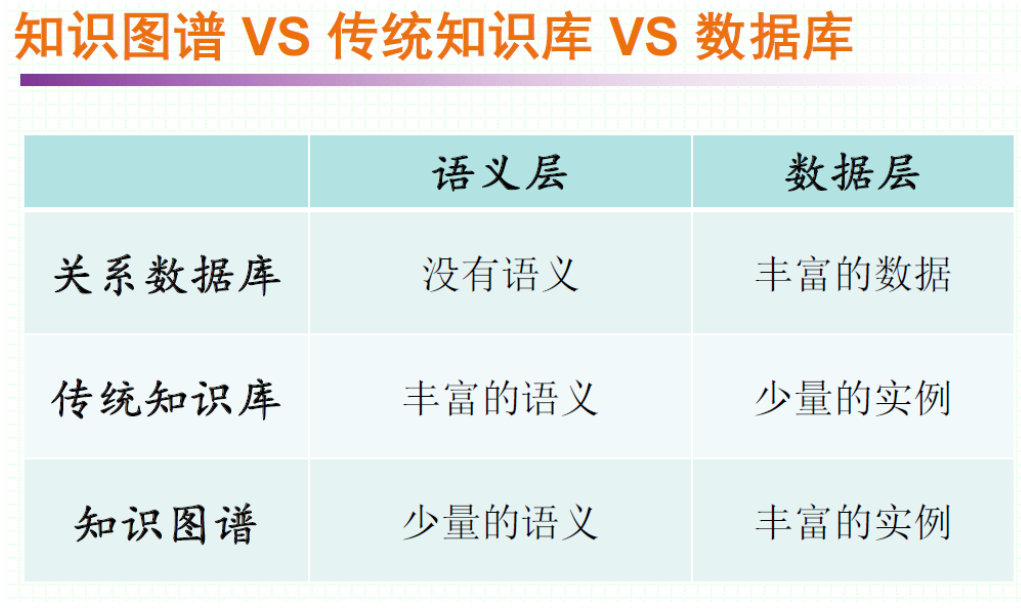

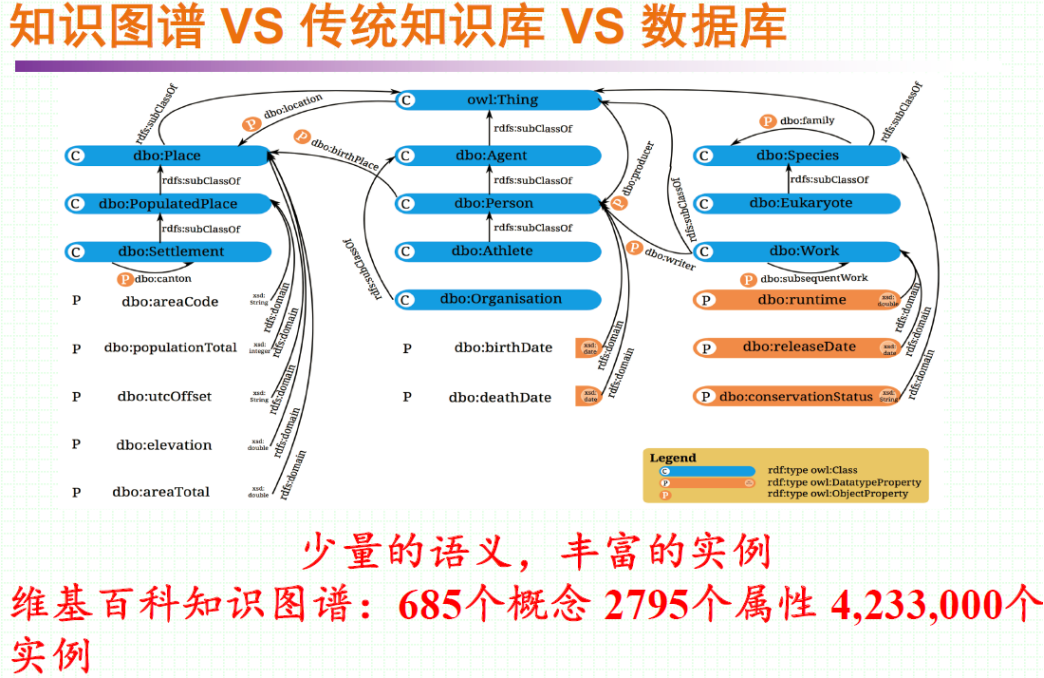

典型的知识图谱
WordNet




Cyc

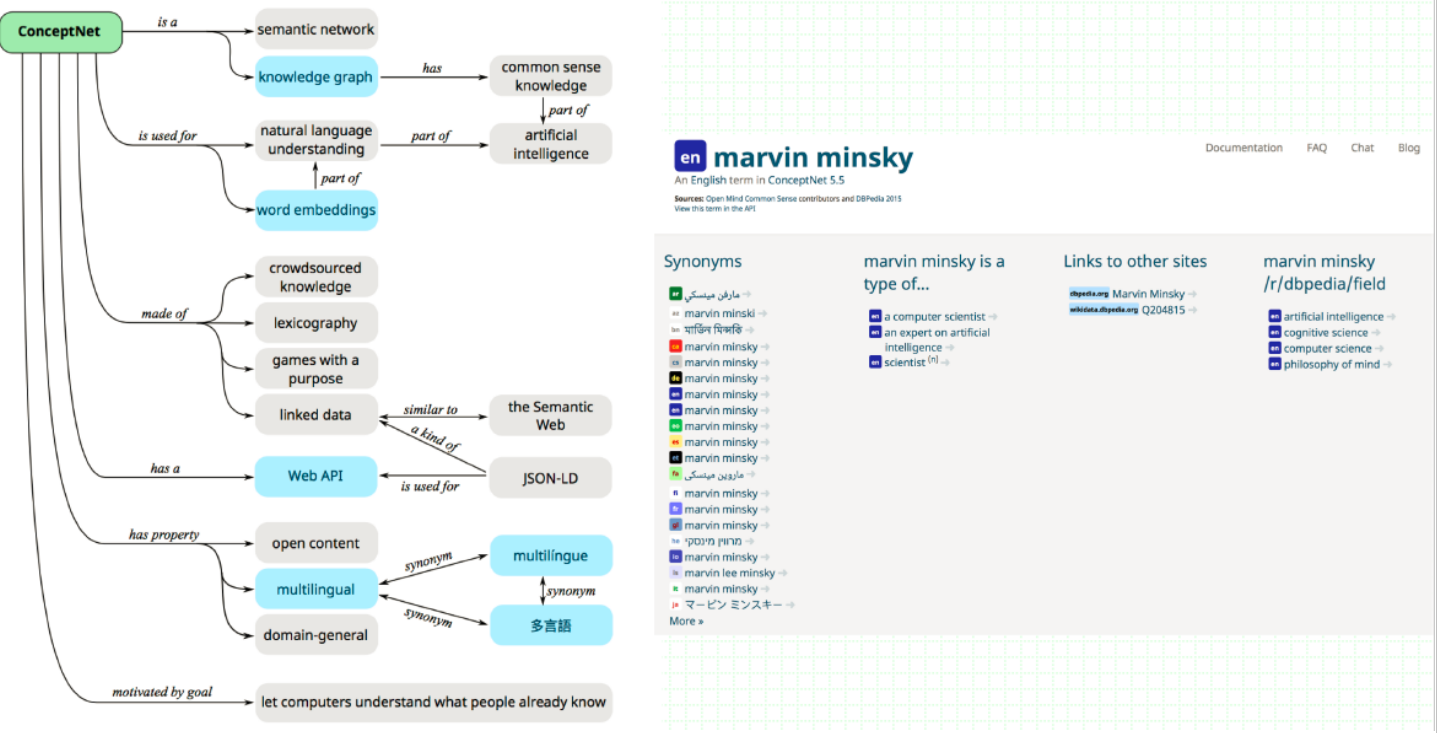
ConceptNet

FreeBase

https://developers.google.com/freebase
Wikipedia

Wikidata

https://www.wikidata.org/wiki/Wikidata:Main_Page
DBPedia

YAGO

https://www.mpi-inf.mpg.de/departments/databases-and-information-systems/research/yago-naga/yago/#c10444
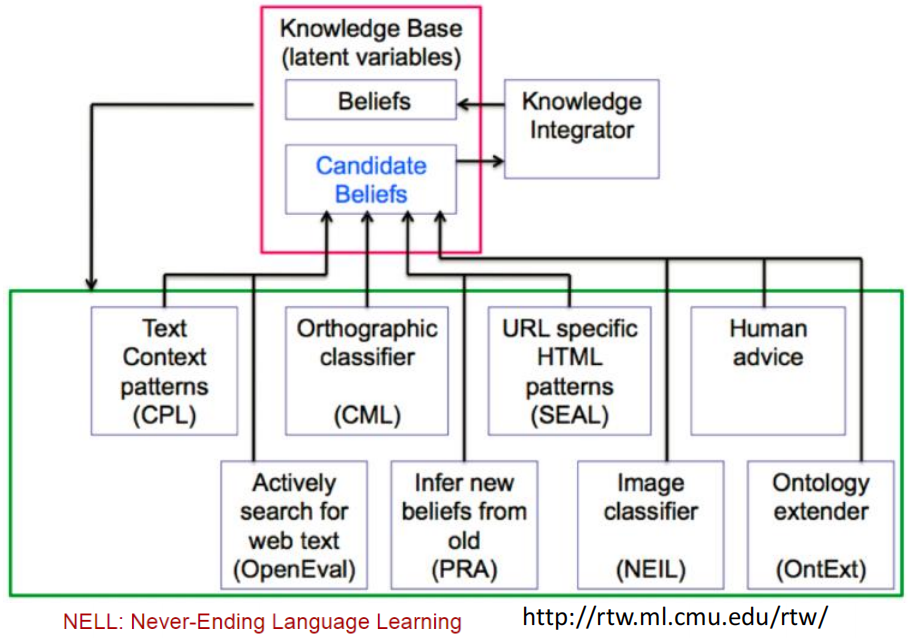
NELL

OpenIE
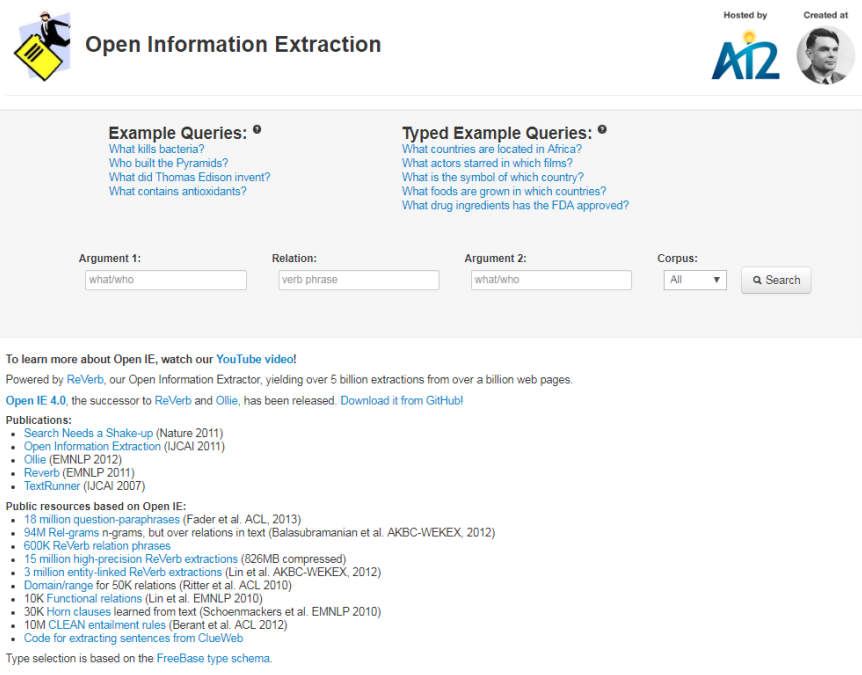
https://openie.allenai.org/
ZhiShi.me

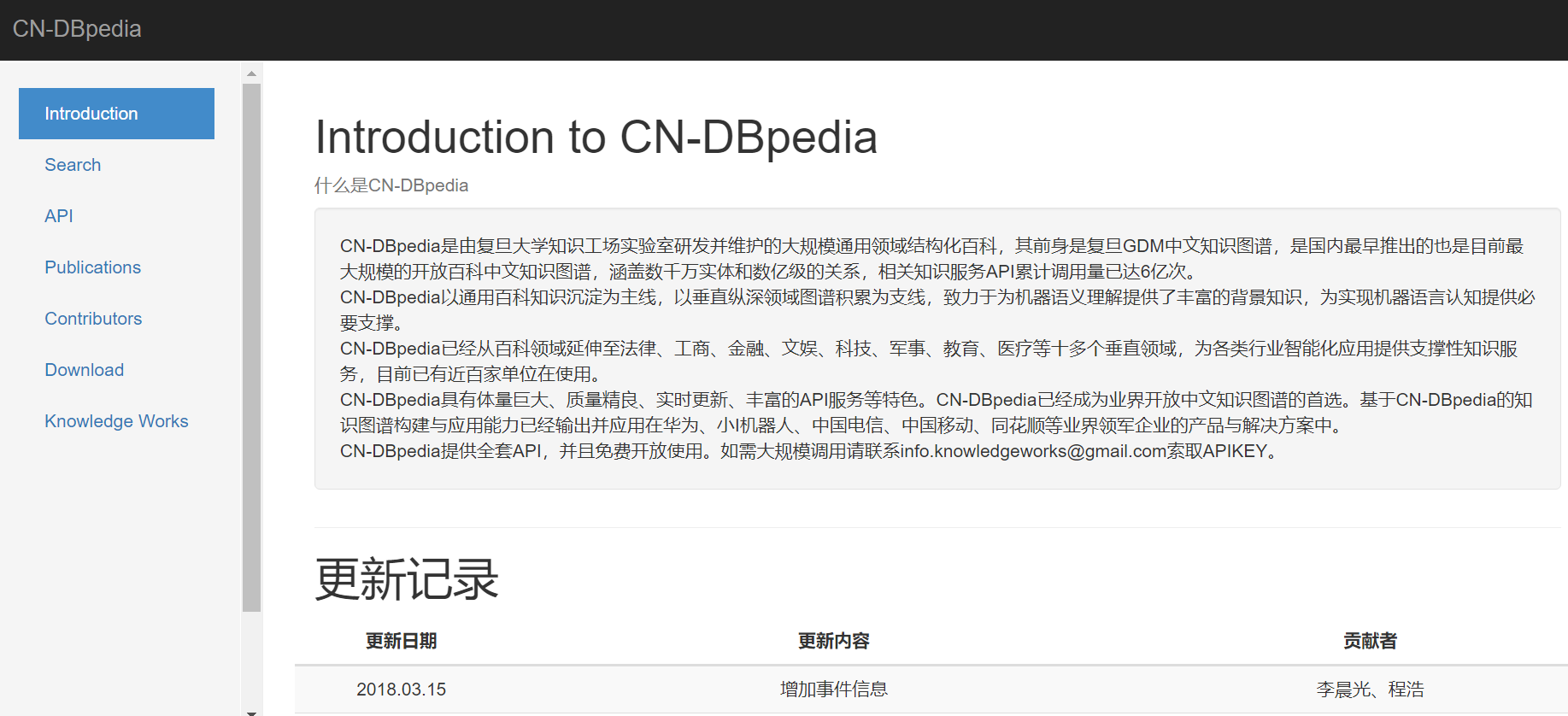
CN-DBPedia

http://kw.fudan.edu.cn/cndbpedia
BabelNet https://babelnet.org/

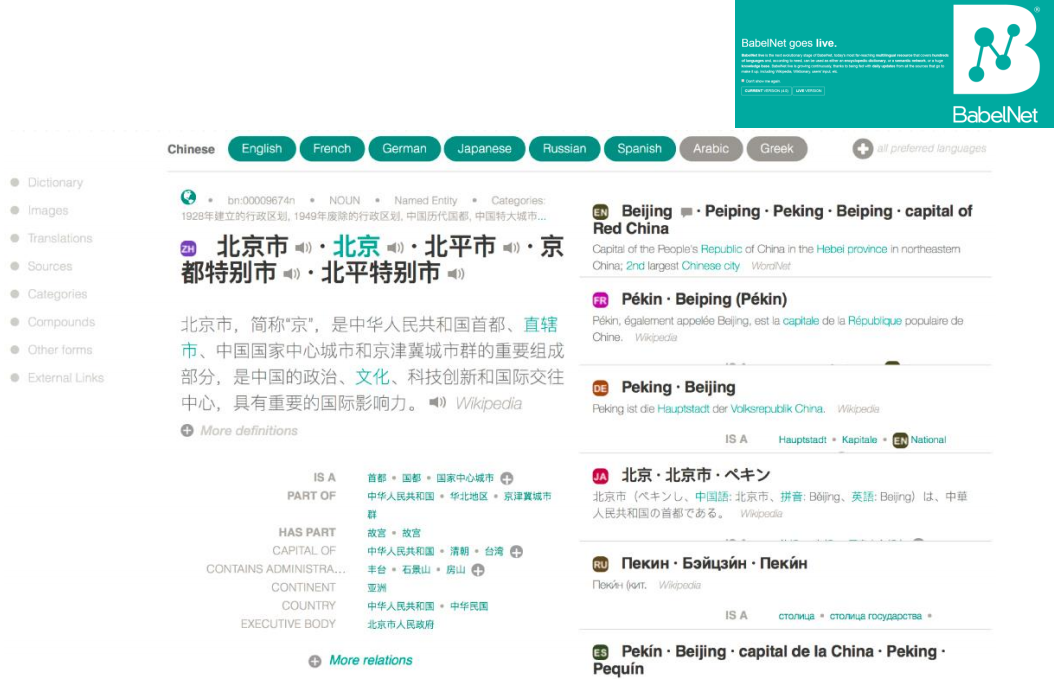

Google知识图谱
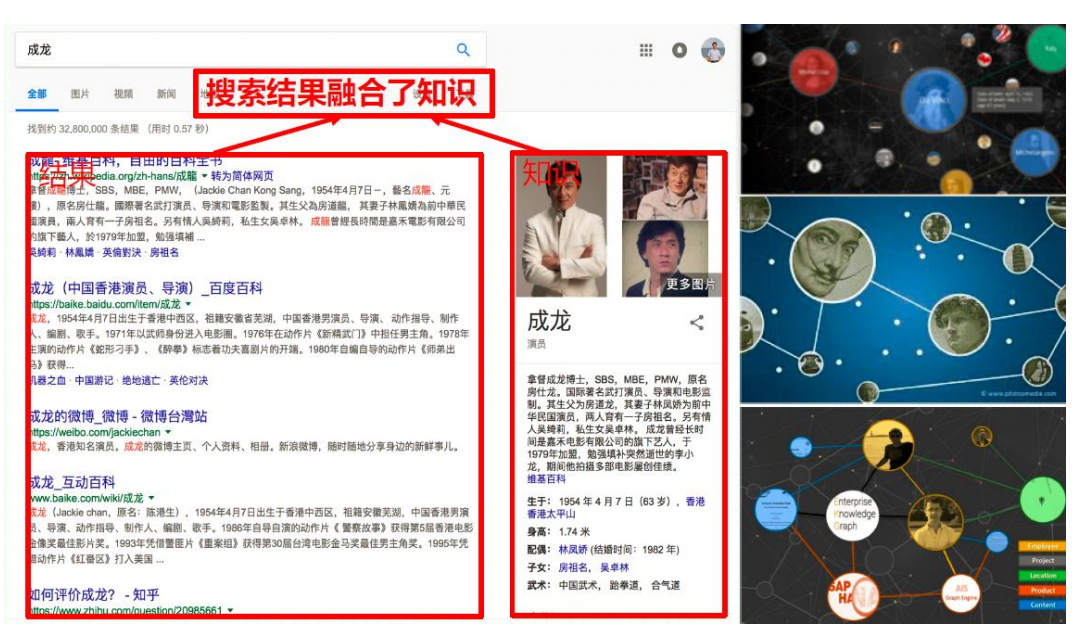

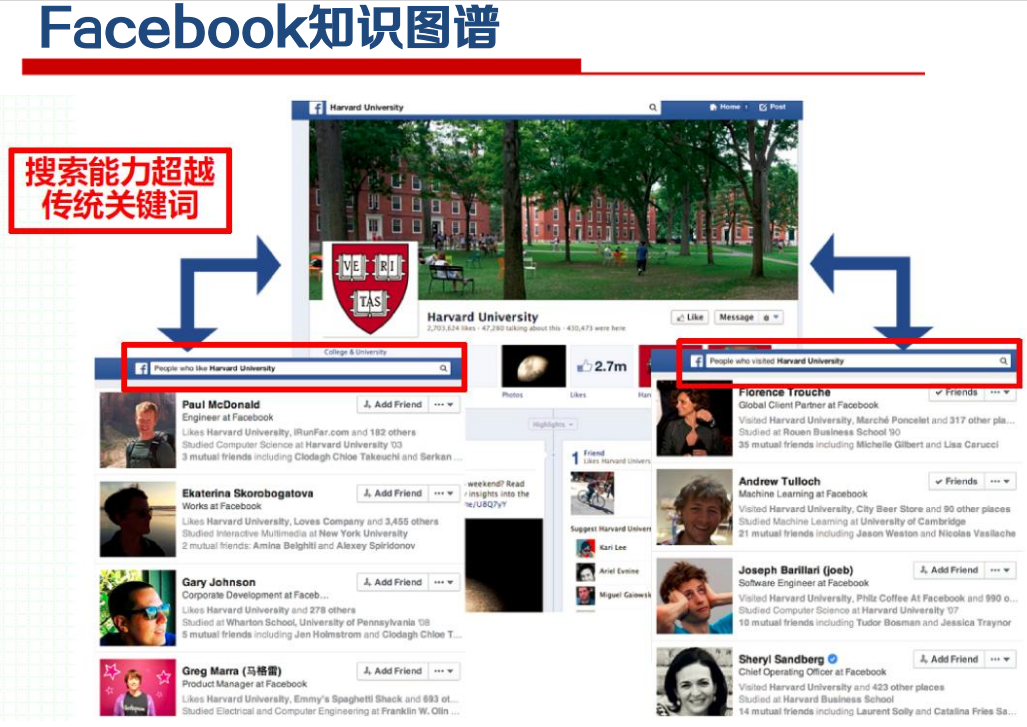
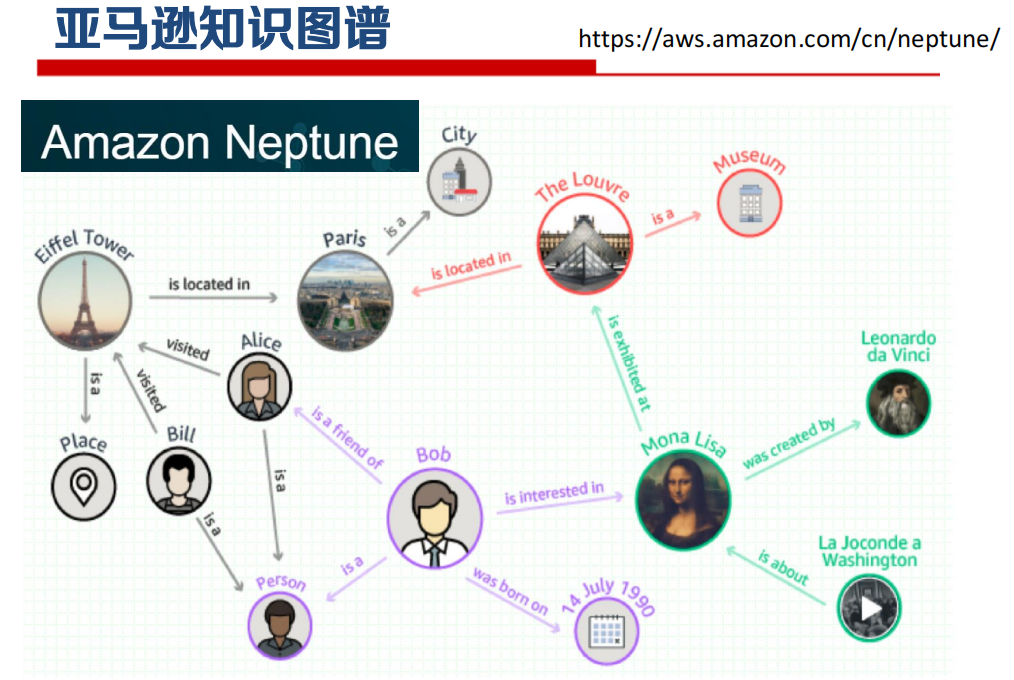
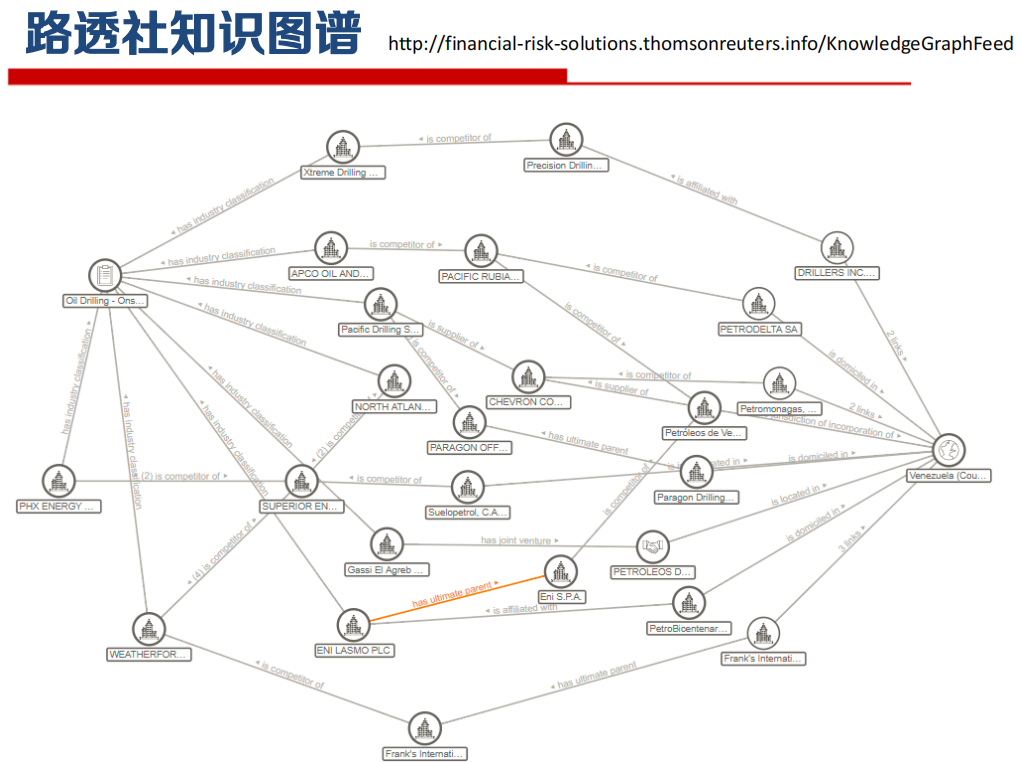

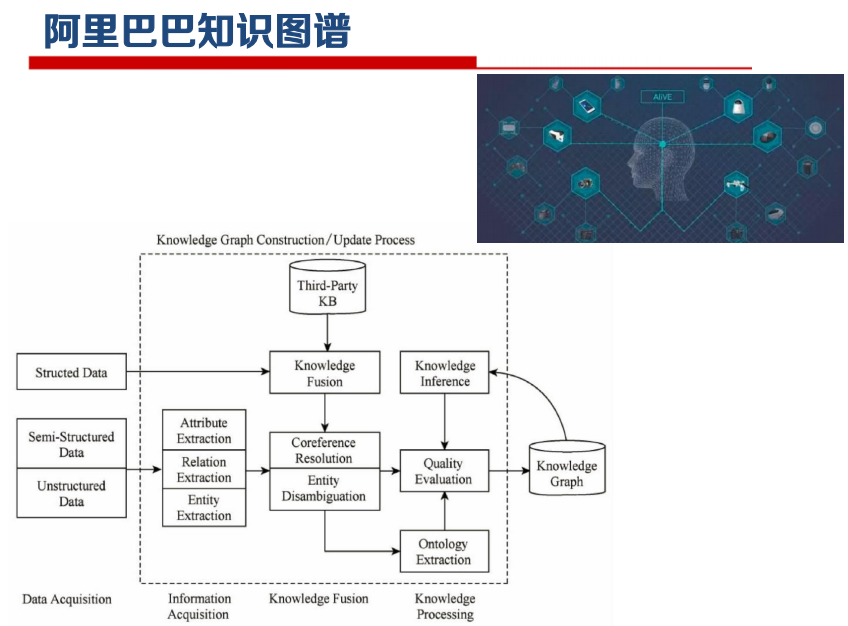
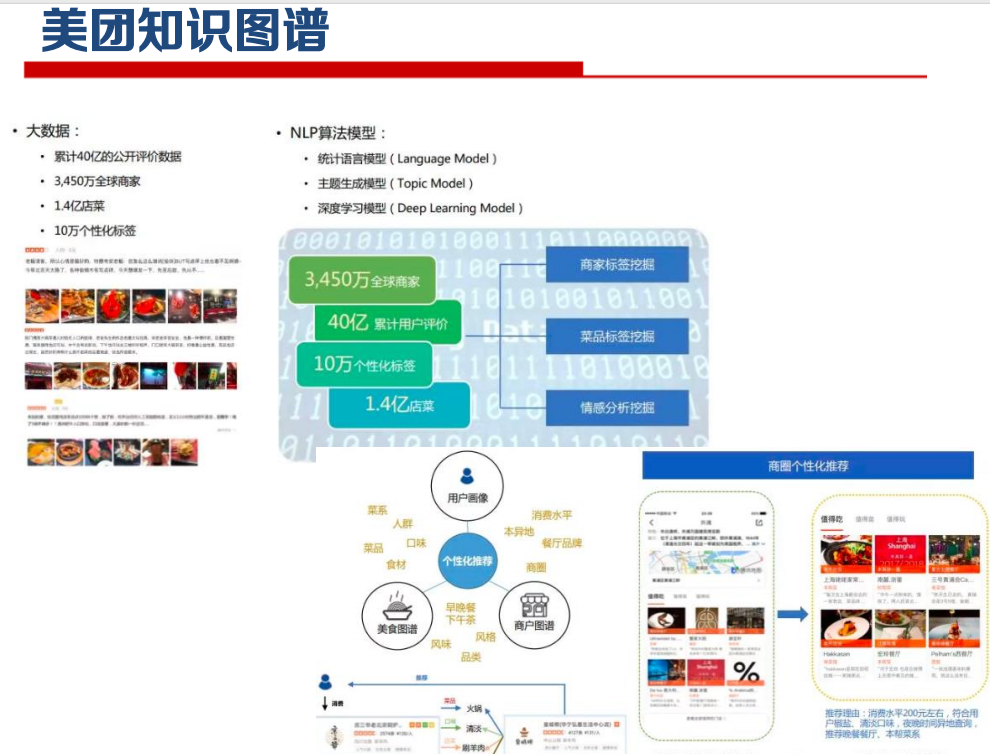
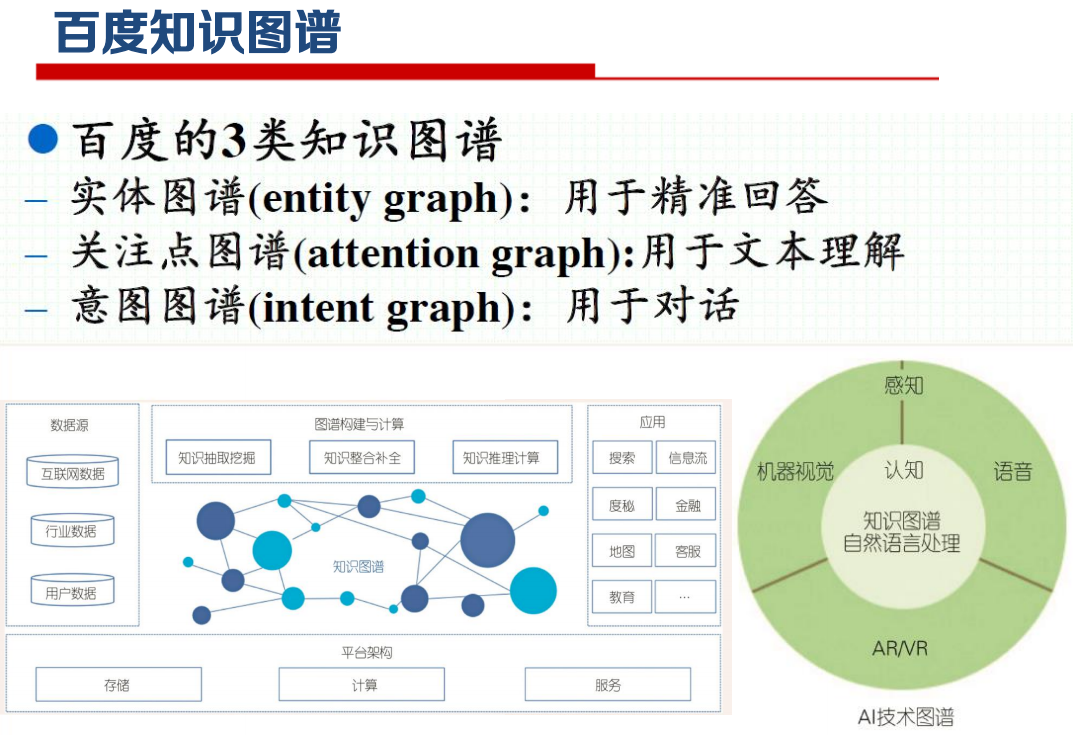
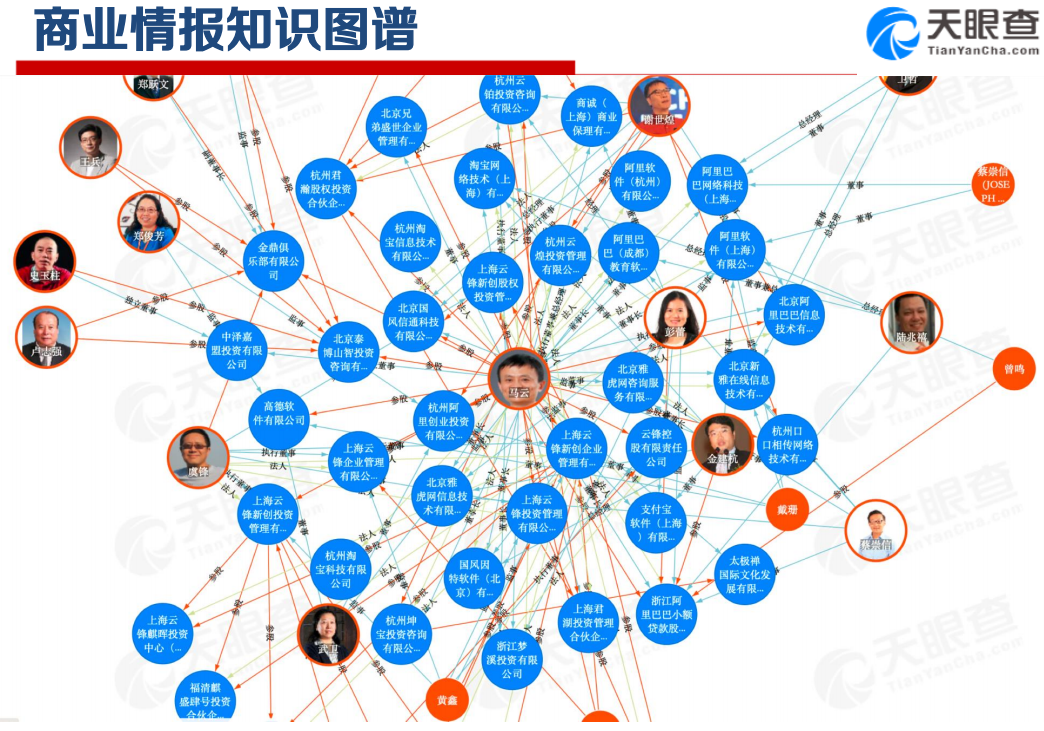

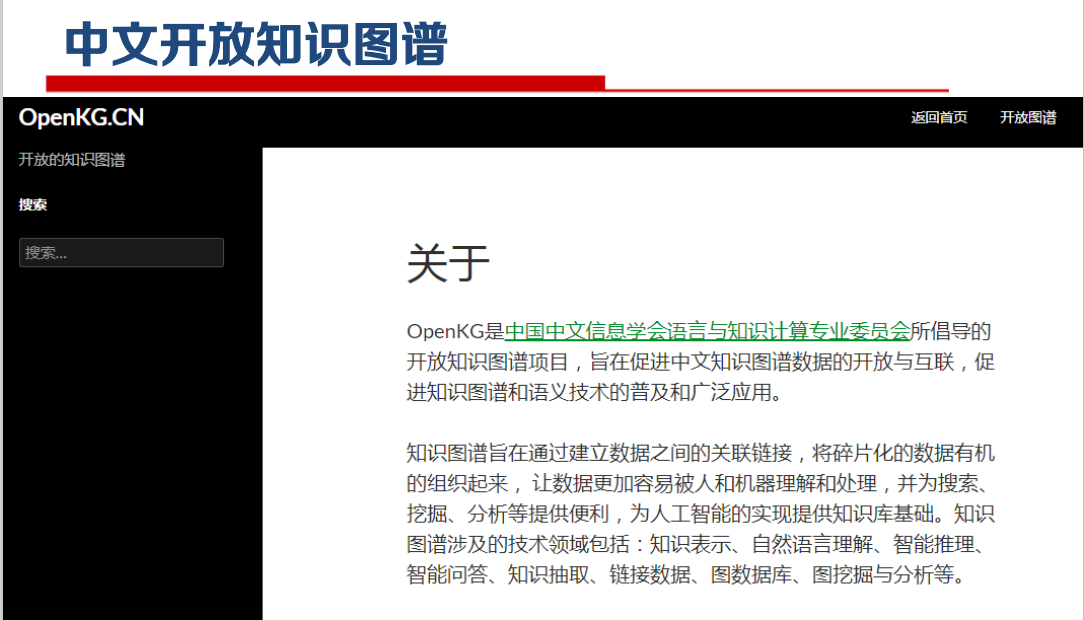

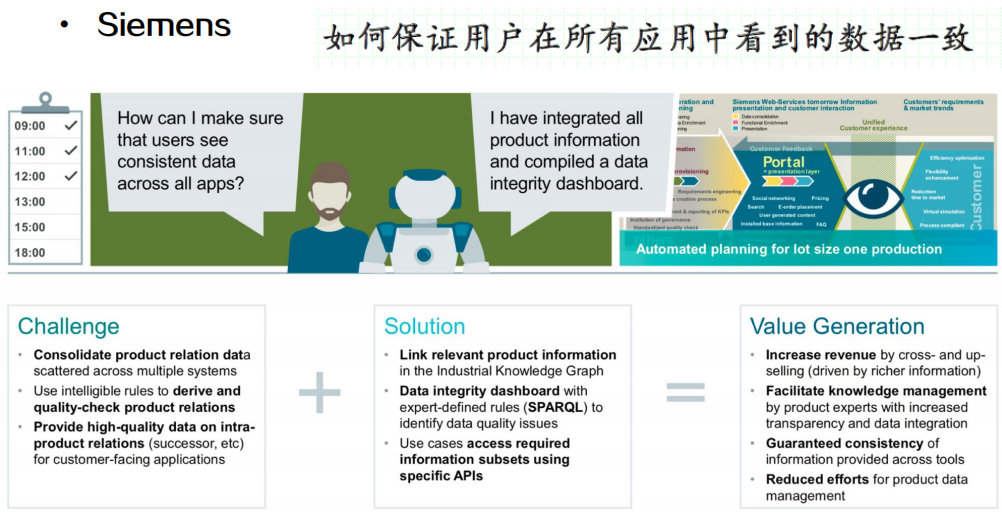
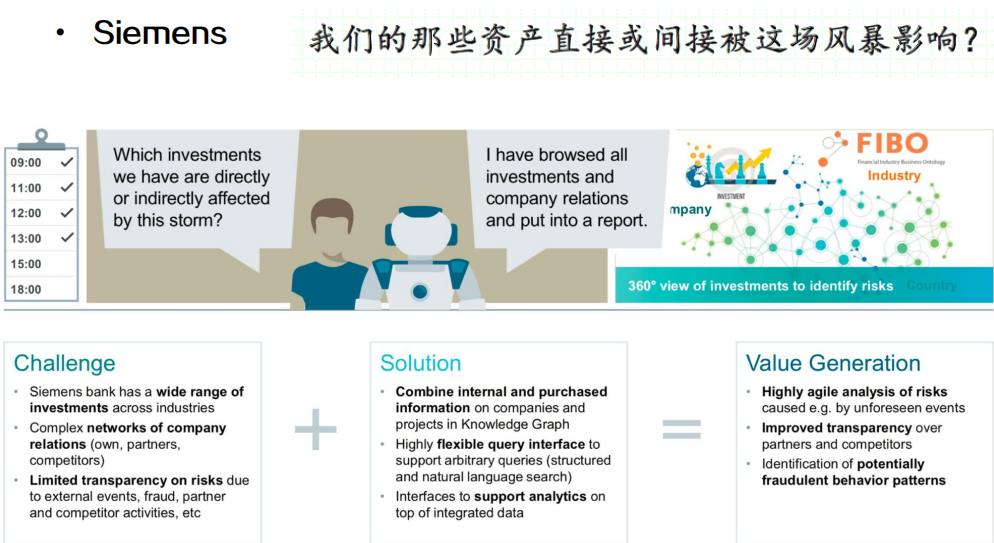
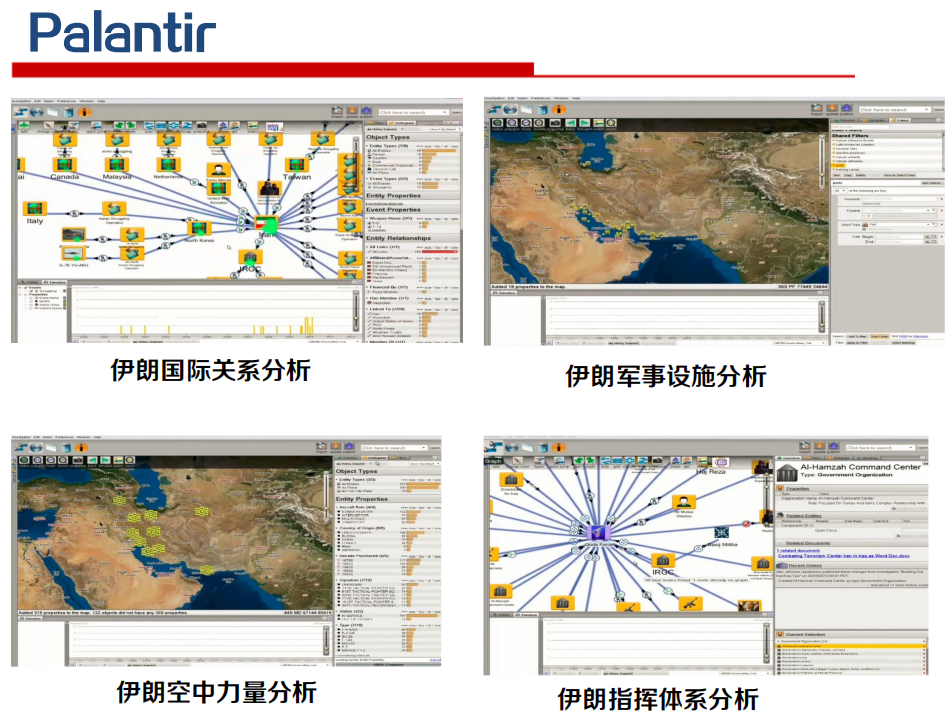
知识图谱应用
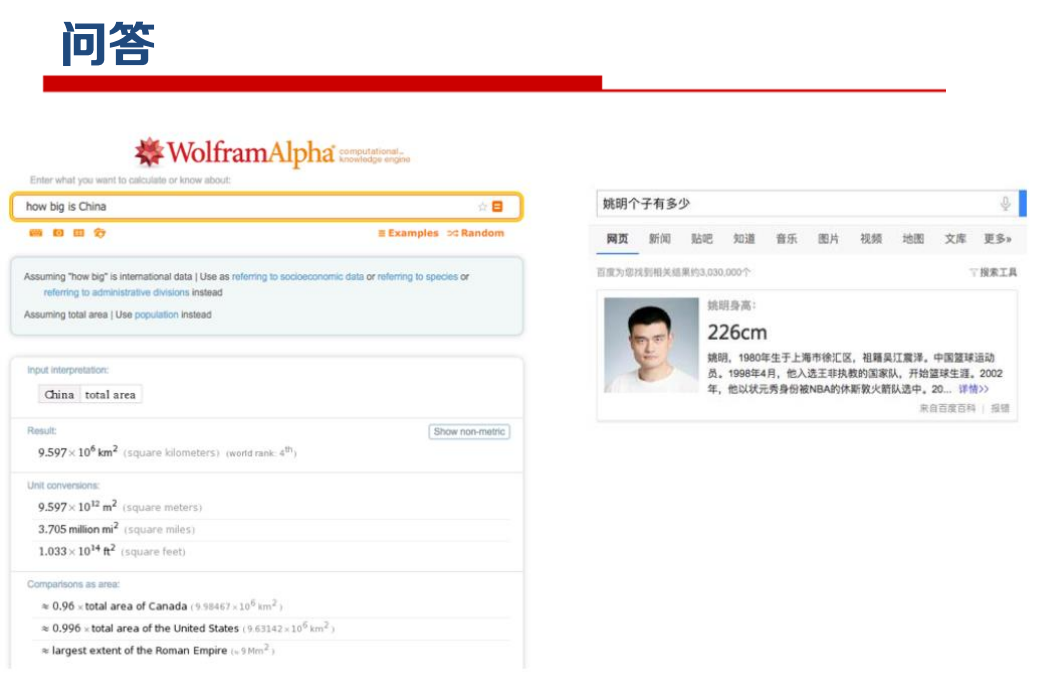
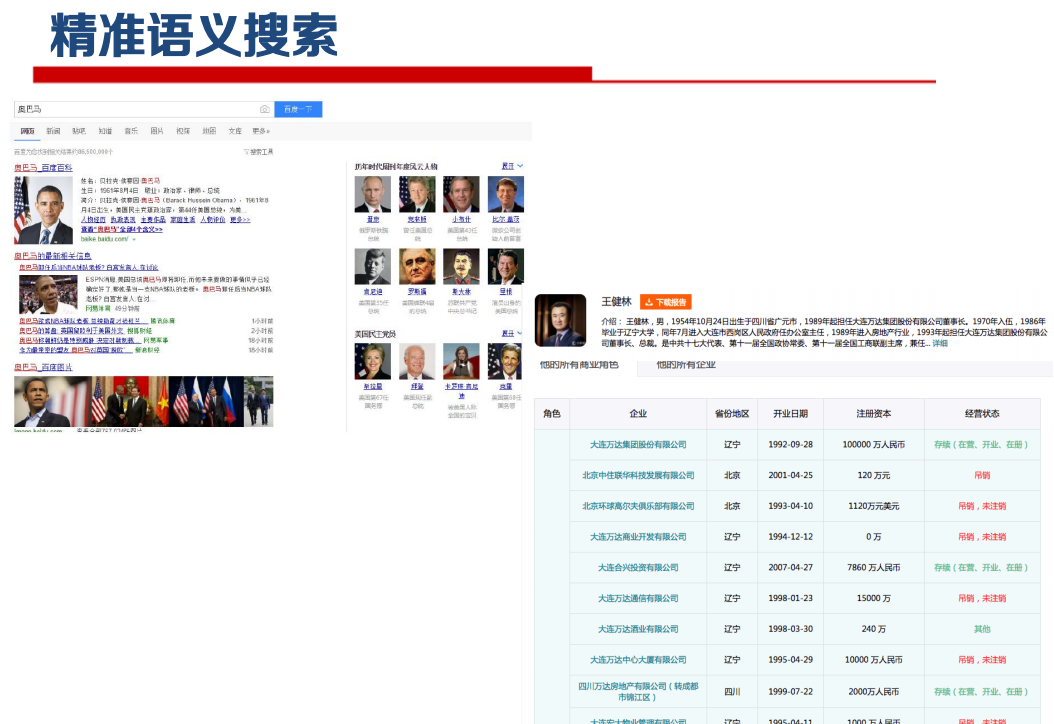
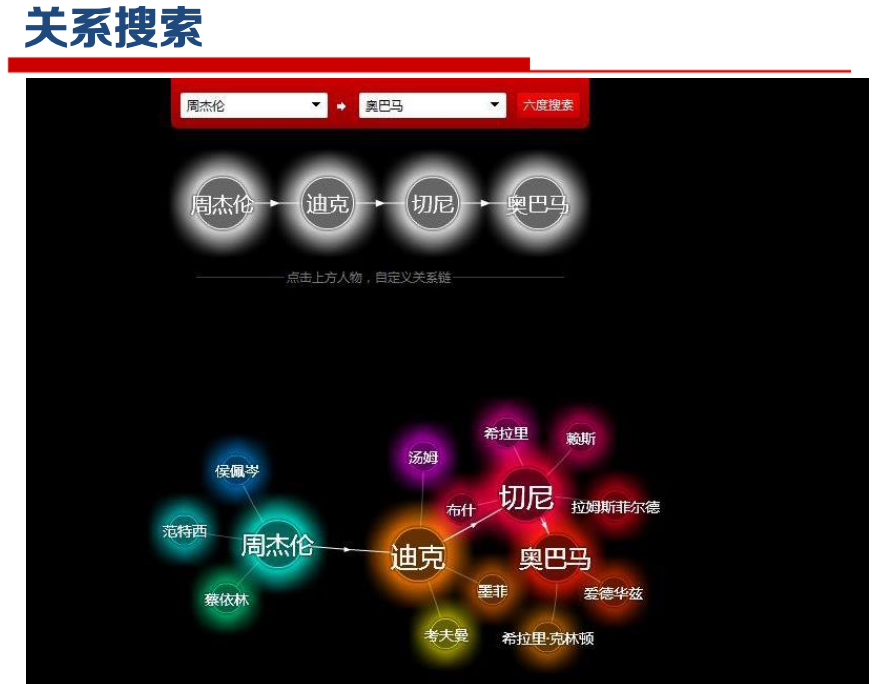
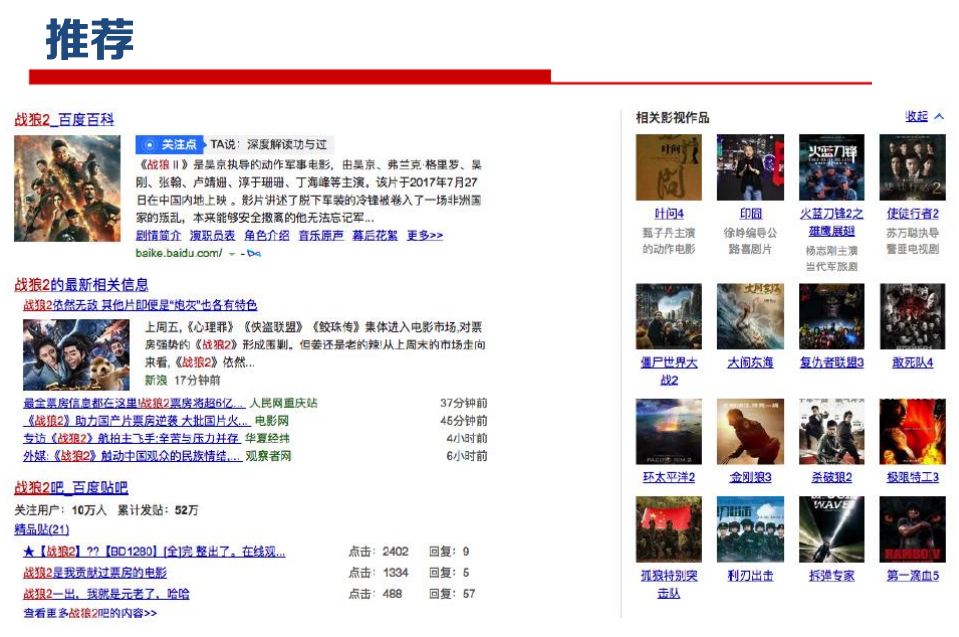

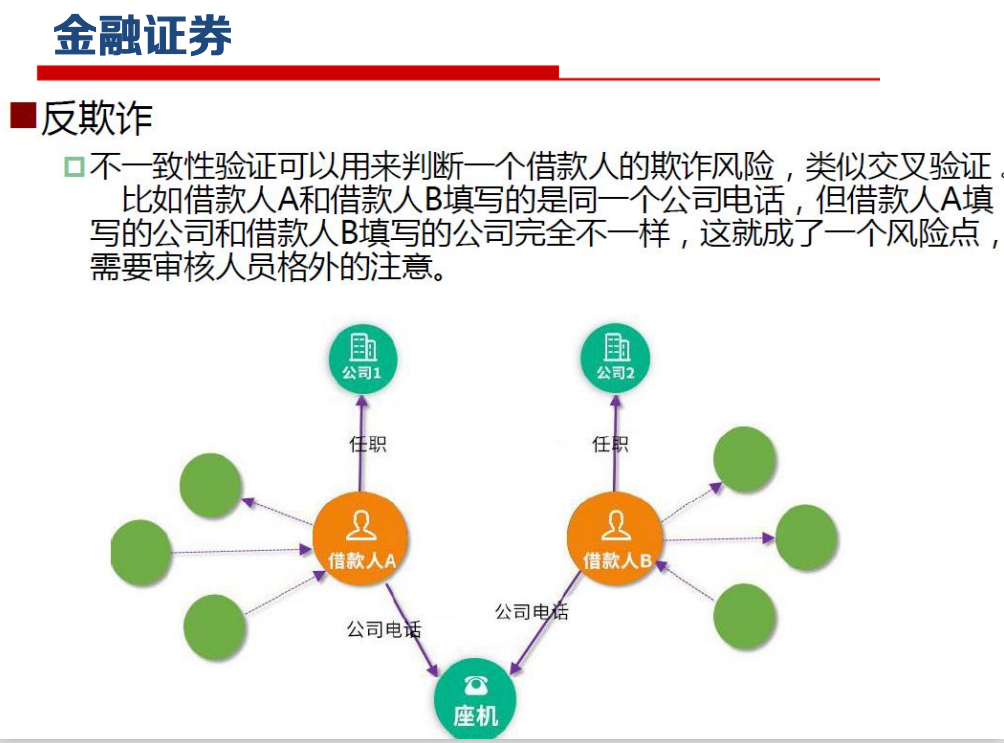
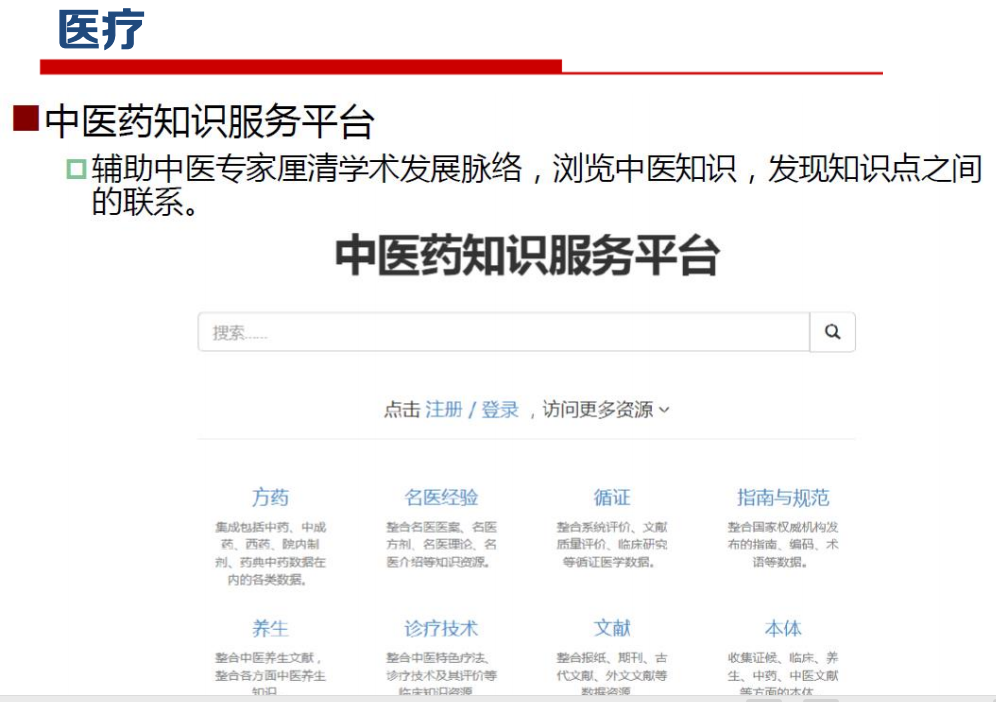


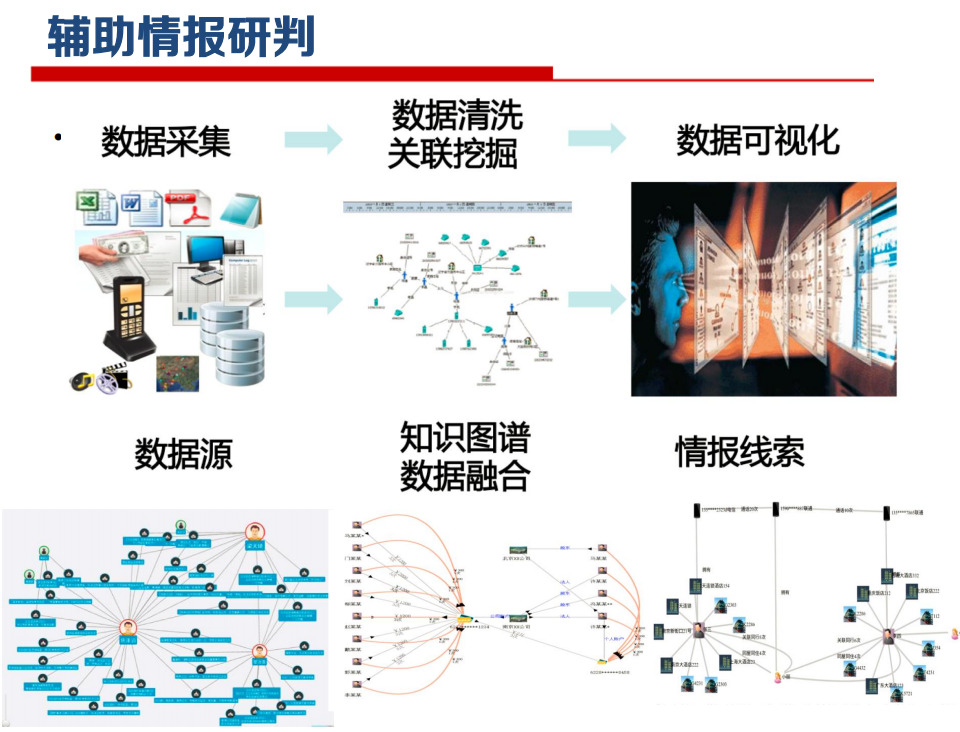

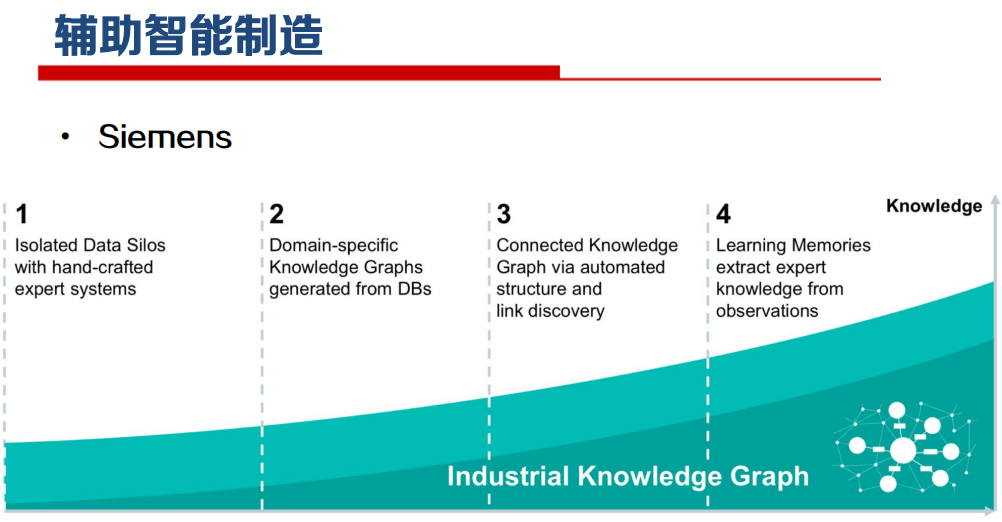
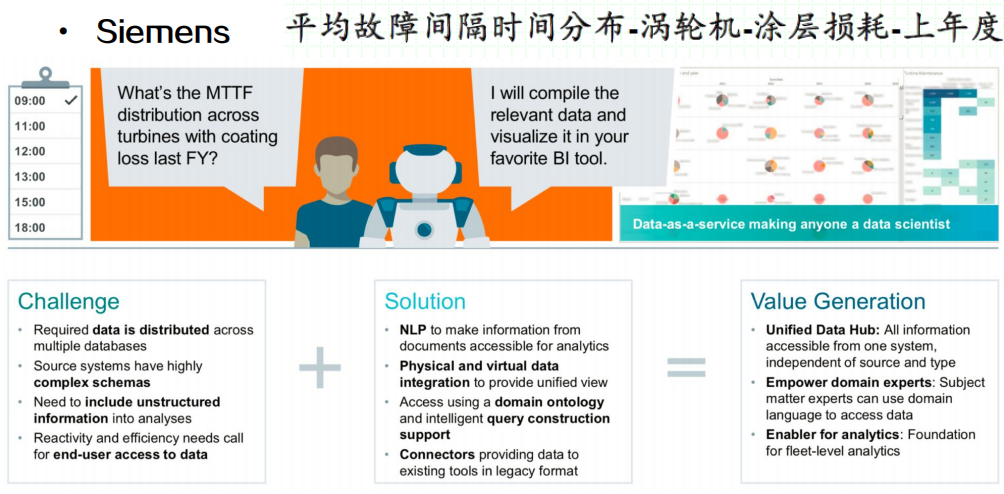
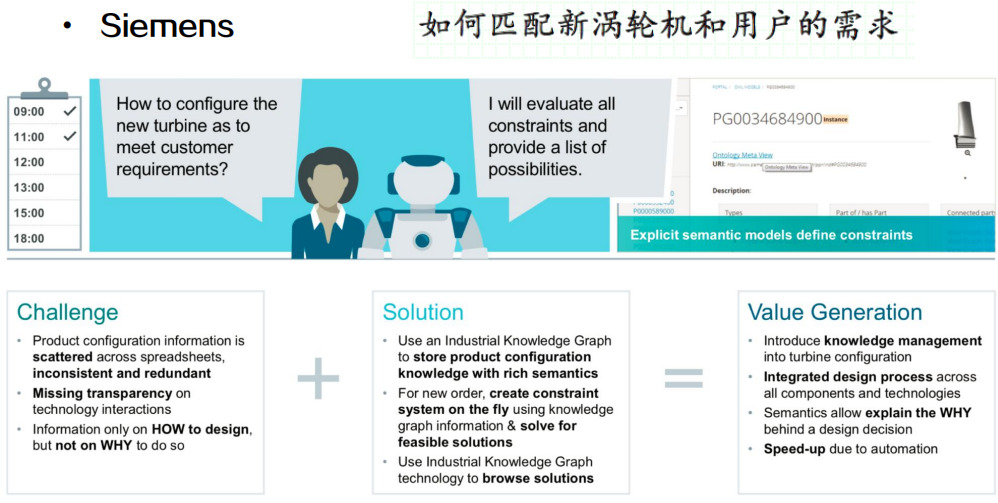


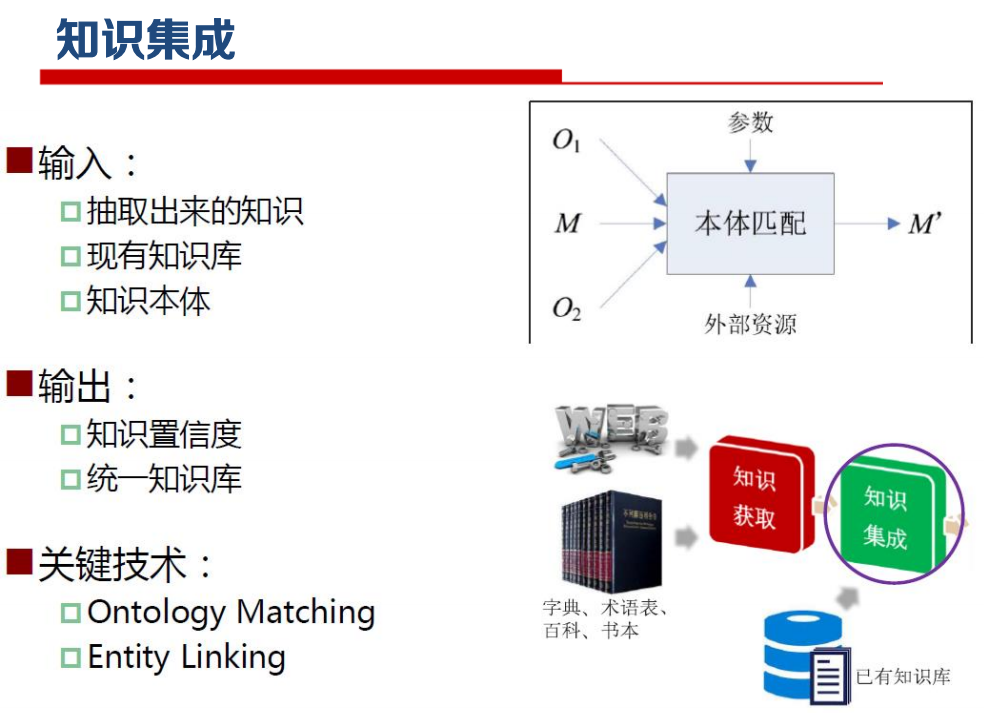
知识图谱生命周期

领域知识建模



加油!
感谢!
努力!