一,K-近邻算法的简介
????????K-近邻算法(K-Nearest Neighbor, KNN),属于监督学习,是一中基本分类与回归方法。k?近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类,?k?近邻法假设给定一个训练数据集,其中的实例类别已定,分类时,对新的实例,根据其?k?个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,?k?近邻法不具有显式的学习过程,?k?近邻法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”k?近邻法1968年由?Cover?和?Hart?提出.
?
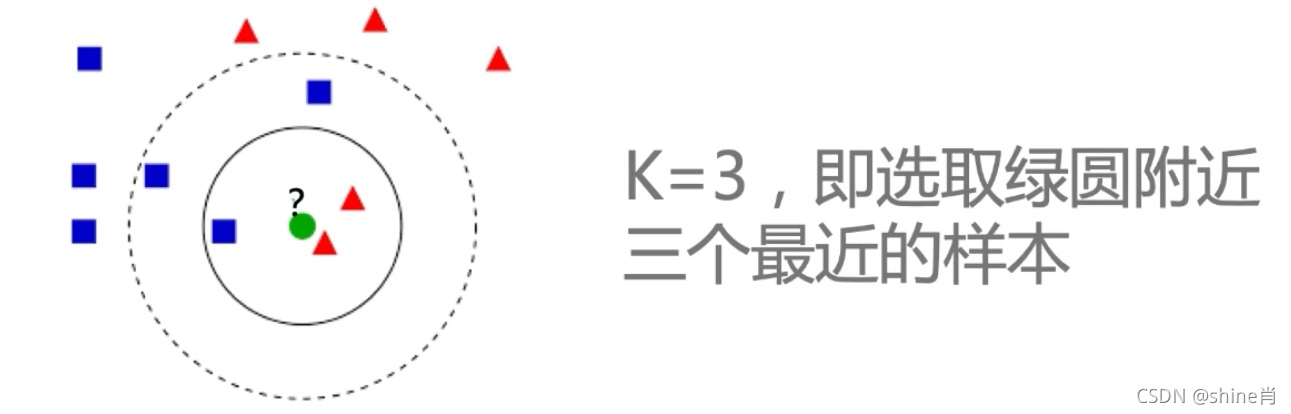
- 定义:已知一个未分类的测试样本,附近有K个最相近的,已分类的样本,若这个样本在特征空间中的K个最相近的样本中的大多数属于某个类别,则该样本也属于这个类别。(就是通过你的“邻居”来判断你属于哪个类别)
?
?
?二,三个基本要素
- ?K值的选择
????????????????K值的选择不同,归类结果会收到影响
- ?K值通常为奇数,避免产生相等占比的情况。
- 当K值过小时,例如k=1,预测结果会对近邻的实例点非常敏感,容易受噪声的影响,发生过拟合。
- 当K值过大时,其优点是可以减少学习的估计误差,但是会受到样本均衡的问题,现有的训练集的近似误差会变大,输入不相似的训练实例也会起作用,导致预测错误。
- 往往需要通过“交叉验证(Cross Validation)”等方法评估模型在不同取值下的性能,进而确定具体问题的K值。
- ?距离度量
? ? ?1,欧式距离
????????????????![]()
例子:

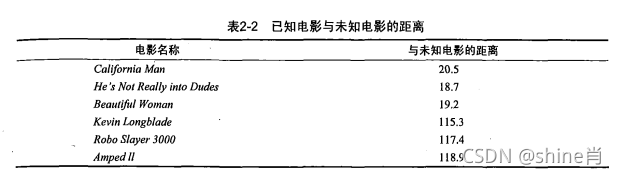
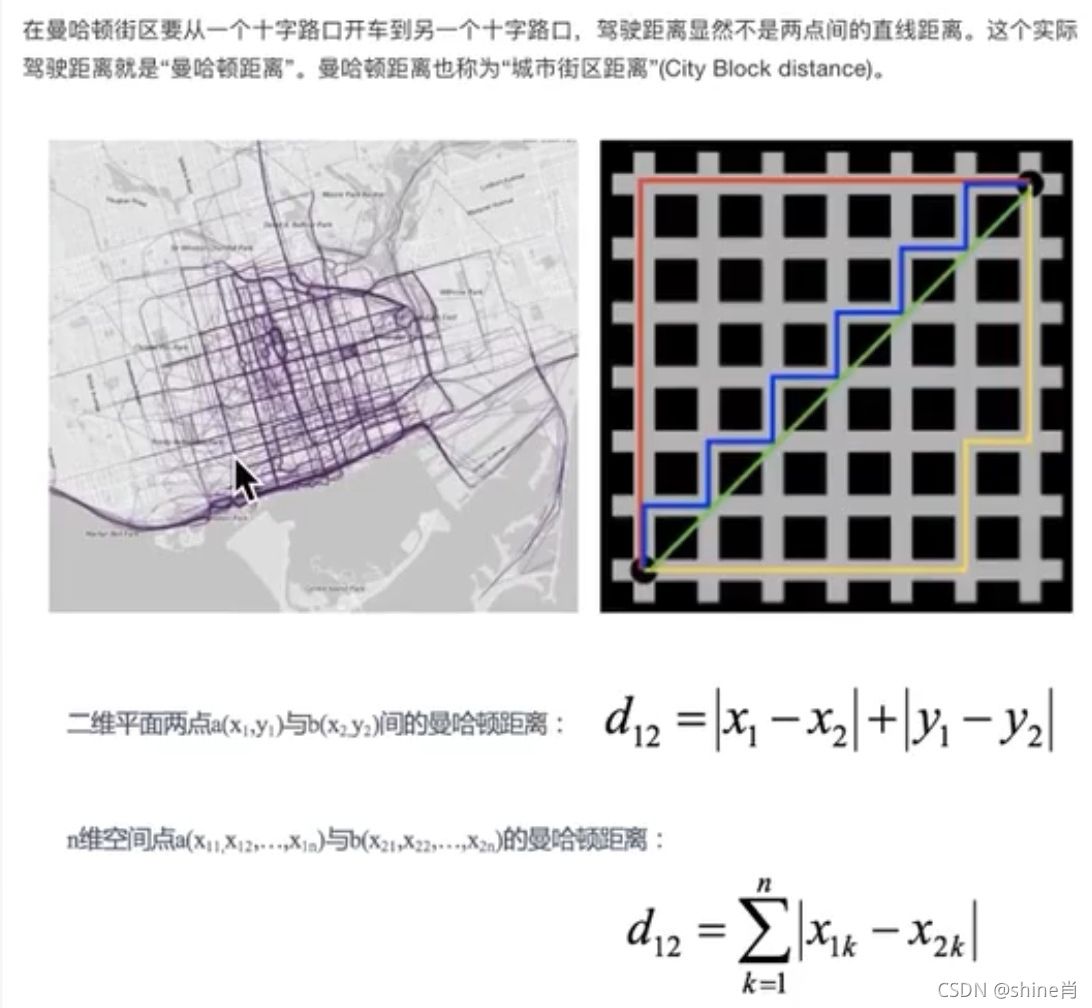
2,曼哈顿距离
? ? ? ? ? ? ?
- ?分类决策规则
???????????????? ? ? ? ?
? ? ? ?