��������SSA
�������¸�����ʦ����Ŀ,�Ӵ���һ��ʱ�����з�����Ԥ�������,��Ҫ�ǻ��ھ���ֽ����������(Singular Spectrum Analysis,SSA),�ù���ż�,����һ�������ʼǡ�
SSA (Singular Spectrum Analysis)
��������(SSA)��һ�ִ���������ʱ���������ݵķ���,���Զ�ʱ�����н��з�����Ԥ�⡣�����ڹ�����ʱ�������ϵ��ض����������ֵ�ֽ�(SVD),���Դ�һ��ʱ�������зֽ�����ơ�������������SSA���зdz��㷺��������,����ʱ������,�Ȳ���Ҫ�������ģ��,Ҳ����Ҫ����ƽ����������
SSA�㷨�Ļ�������
����һ������ΪN��ʱ������
X
?
=
X
N
?
=
(
x
1
,
��
,
x
N
)
X^��=X^��_N=(x_1,��,x_N)
X?=XN??=(x1?,��,xN?)��
N
>
2
N> 2
N>2,��
X
X
X��һ����������,��,���ٴ���һ��
i
i
iʹ��
x
i
��
0
x_i \neq0
xi?��?=0��������
L
(
1
<
L
<
N
)
L(1<L<N)
L(1<L<N)Ϊ���ڳ���,��
K
=
N
L
+
1
K=N_L+1
K=NL?+1
SSA�㷨�Ĺ����ɷֽ���ع����������Ľ���ɡ�
�ֽ�
- ��һ����Ƕ��
���ǽ�ԭʼʱ������ӳ���һ������Ϊ L L L����������,�γ� K = N ? L + 1 K =N?L+1 K=N?L+1������Ϊ L L L������:
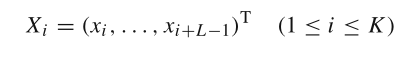
��Щ������ɹ켣����:

- �ڶ���:����ֵ�ֽ�
����һ��,�Թ켣���� X X X��������ֵ�ֽ�(SVD)���� S = X X T S=XX^T S=XXT, �� 1 , . . . , �� L ��_1,...,��_L ��1?,...,��L?Ϊ S S S������ֵ,�� �� 1 �� . . . �� �� L �� 0 ��_1��...�ݦ�_L��0 ��1?��...����L?��0;�� U 1 , . . . , U L U_1,...,U_L U1?,...,UL?�Ǿ��� S S S��Ӧ����Щ����ֵ�ı�����������
�� d = r a n k ( X ) = m a x { i , �� i > 0 } d=rank(X)=max\{i,��_i>0\} d=rank(X)=max{i,��i?>0}(ע��,��ʵ��������,����ͨ���� d = L ? , L ? = m i n { L , K } d=L^?,L^?=min\{L,K\} d=L?,L?=min{L,K})�� V i = X T U i / �� i ( i = 1 , �� , d ) V_i =X^TU_i/\sqrt{ ��_i}(i=1,��,d) Vi?=XTUi?/��i??(i=1,��,d)
���������,�켣���� X X X��SVD����д��:
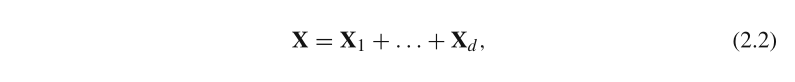
����, X i = �� i U i V i T X_i =\sqrt{ ��_i}U_iV_i^T Xi?=��i??Ui?ViT?
�ع�
-
������ ����(grouping)
�Ƚ��±꼯�� { 1 , . . . , d } \{1,...,d\} {1,...,d}���ֳ� m m m�������ཻ���Ӽ� I 1 , . . . I m I_1,...I_m I1?,...Im?,�� I = { i 1 , . . . , i p } I=\{i_1,...,i_p\} I={i1?,...,ip?},���Ӧ�� I I I�ĺϳɾ��� X I = X i 1 + . . . + X i p X_I=X_{i_1}+...+X_{i_p} XI?=Xi1??+...+Xip??������:
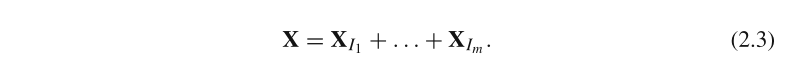
-
���IJ�:�Խ���ƽ��
����һ����,���ǽ�(2.3)�е�ÿ������ X I j X_{I_j} XIj??�任Ϊһ������ΪN��������,���õ��ֽ������С��� Y Y YΪһ�� L ? K L*K L?K�ľ���,Ԫ��Ϊ y i j , 1 �� i �� L , 1 �� j �� K . y_{ij},1��i��L, 1��j��K. yij?,1��i��L,1��j��K.�� L ? = m i n ( L , K ) , K ? = m a x ( L , K ) , N = L + K ? 1 L^?=min(L,K),K^?=max(L,K),N=L+K?1 L?=min(L,K),K?=max(L,K),N=L+K?1.��� L < K L< K L<K, y i j ? = y i j y^?_{ij} = y_{ij} yij??=yij?,����, y i j ? = y j i y^*_{ij} = y_{ji} yij??=yji?
������������Ĺ�ʽ2.4���жԽ�����ƽ��,������ Y Y Yת��Ϊ���� y 1 , �� , y N y_1,��, y_N y1?,��,yN?

��������ͼ��ʾ�Խ�����ƽ��,����ά����ת��Ϊһά����:

SSAԤ��
SSA��Ԥ��,���Լ�����Ϊһ�����Եݹ����,��:
y N + 1 = a 1 y N + a 2 y N ? 1 + . . . + a L ? 1 y N ? L + 1 y_{N+1}=a_1y_{N}+a_2y_{N-1}+...+a_{L-1}y_{N-L+1} yN+1?=a1?yN?+a2?yN?1?+...+aL?1?yN?L+1?
����,ϵ�� a 1 , . . . a L ? 1 a_1,...a_{L-1} a1?,...aL?1?����SVD��õ�����ֵ����õ���
SSA��Ԥ�ⷽ���еݹ�(recurrent)�;���(vector)���֡�
Recurrent Forecast
ʱ������
Y
N
+
M
=
(
y
1
,
.
.
.
,
y
N
+
M
)
Y_{N+M}=(y_1,...,y_{N+M})
YN+M?=(y1?,...,yN+M?)�ĵݹ�Ԥ�ʽ����:
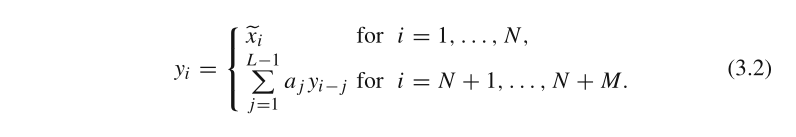
����,
x
i
~
Ϊ
��
��
��
ʽ
2.4
��
��
��
��
��
ʱ
��
��
��
ֵ
��
\tilde{x_i}Ϊ���ݹ�ʽ2.4�ع�������ʱ������ֵ��
xi?~?Ϊ������ʽ2.4����������ʱ������ֵ��
y
N
+
1
,
.
.
.
,
y
N
+
M
y_{N+1},...,y_{N+M}
yN+1?,...,yN+M?ΪM��Ԥ��ֵ��
��,����ֻ��Ҫ���ϵ��
a
1
,
.
.
.
a
L
?
1
a_1,...a_{L-1}
a1?,...aL?1?���ɡ����㷽������:
������
R
=
(
a
L
?
1
,
.
.
.
,
a
1
)
T
R=(a_{L?1},...,a_1)^T
R=(aL?1?,...,a1?)T,����
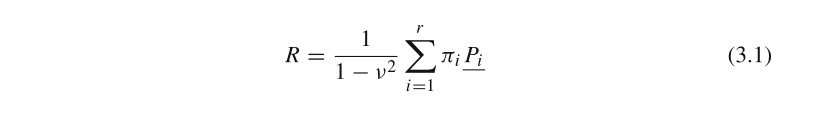
ʽ3.1��,
��
2
=
��
1
2
+
.
.
.
+
��
r
2
\nu^2=\pi_1^2+...+\pi_r^2
��2=��12?+...+��r2?;
��
i
\pi_i
��i?������
P
i
(
i
=
1
,
.
.
.
,
r
)
P_i(i=1,...,r)
Pi?(i=1,...,r)�����һ������,
P
i
P_i
Pi?������SVD�ֽ�����еõ��ı�����������
Vector Forecast
SSAԤ�����һ�ַ���������Ԥ�ⷨ���ܵ���˵,����Ԥ��ȵݹ�Ԥ����ȶ�,�ر��ǵ��������쳣ֵ�϶��ʱ��������ľ���:
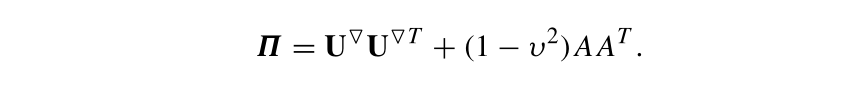
����������������:

����,
Y
��
Y_\Delta
Y��?��
Y
Y
Y�ĺ�
L
?
1
L-1
L?1��Ԫ�ع��ɵ���������������
Z
j
Z_j
Zj?����:
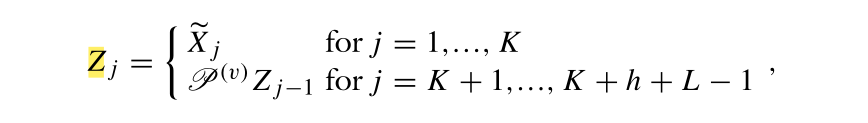
����,
X
j
~
\tilde{X_j}
Xj?~?Ϊ�켣�������鲢�������������ع��ĵ�
j
j
j�С�����,ͨ���������
Z
=
[
Z
1
,
.
.
.
,
Z
K
+
h
+
L
?
1
]
Z=[Z_1,...,Z_{K+h+L-1}]
Z=[Z1?,...,ZK+h+L?1?],�����жԽ���ƽ��,���Եõ�һ���µ�����
y
^
1
,
.
.
.
,
y
^
K
+
h
+
L
?
1
\hat{y}_1,...,\hat{y}_{K+h+L-1}
y^?1?,...,y^?K+h+L?1?,����,
y
^
N
+
1
,
.
.
.
,
y
^
N
+
h
\hat{y}_{N+1},...,\hat{y}_{N+h}
y^?N+1?,...,y^?N+h?����ͨ��Vector�������Ԥ��ֵ��
Vector����Ԥ���������ͼ��ʾ:

pythonʵ��
SSA�Ĵ���ʵ��,���DZȽ϶��,�����϶���ʵ���˷ֽ���ع�,Ԥ��һ��Ҳ����recurrent����,��
pyts�е�SSA
GitHub��Ҳ�бȽ϶�:
pssa
ssa-py
�һ���GitHub�����pssa,����һ��,����ʵ����vectorԤ�ⷽ��,�пյ�ʱ������������GitHub�ɡ�