����
ǰ��ʱ��ع˺�ѧϰ�˻���RNN+Attention�����CNN+Attention��seq2seqģ��:��NLP��seq2seq ��dz���������Rnn��Cnn�Ĵ�����ʽ,������������һЩ���������֡�
seq2seq�����ʵ�����Ƿ���,�������ϴ����ʲôӢ�ﵽ����,�������һЩ������˵ʵ��,�ܲ��������ܿ�������?������Ҷ�û�й��������ϰ�,̹����Ҳû��,�������Ǿ�ȥgithub�����ҡ�
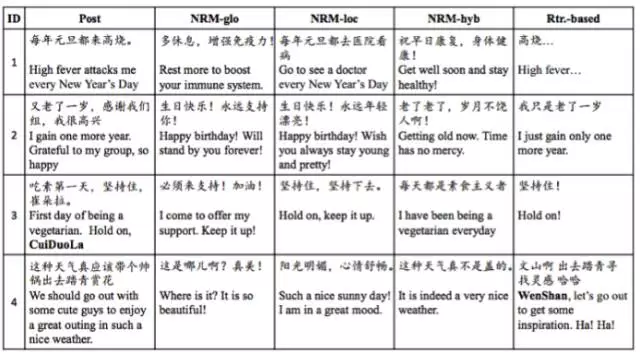
���˻�������,seq2seq������һЩ�Ƚ�����˼����س���������˵,���Ǵ�绰��������Ԥ��,һ������½ӵ绰��Ů��,��ʵ��һ��������������Ԥ��,���������DZȽ����ܵġ�������õ���seq2seq,�����漰��������������һ���ǻ�Ϊ�Ŷ�,ͨ��seq2seqΪ������Ƶ�ģ��ʵ���˼�����������Զ��ظ�,��ͨ��ģ�ͼ�ĶԱȵõ���һϵ������˼�Ľ��������ͼ,postΪ����������,��������Ϊ��ͬģ�ͶԸ����������Ļظ���
�������ѵ���һȺ�п�Ժ��С��д������:Chinese Poetry Generation with Planning based Neural Network����������һ�»���������˼��,��Ȼ��2016�귢������,�����ǽ�����ĵ�һЩ����,�������������һ���ϣ�����һЩ�о����������,��Ҫ�������ŷ�������һЩӢ������ȥ��һЩ�о�,��������������Ϣ�������ǻ��Ӣ����һ����ԭ�����ص�ַ:Chinese Poetry Generation with Planning based Neural Network��
����͵���Ϊ�����Ķ��ʼ�,������ԭ�ĵķ���ɡ��ֿ�ʼ�����Լ�ѧӢ����,��Ȼ���й���д��Ӣ��,�����ܱ��Լ�д��Ҫ��,ֵ��ѧϰ,�¸�!!!
ժҪ
���ĵ�ʫ����������Ȼ���Դ�������һ���Ƚϴ����ս����ƪ���������һ���Ƚ����������ʽ����ʫ�ķ���,��һ���Ǹ�����д�˵���д�������ɼ���������,�ڶ���ʹ���ĵĻ���RNN��encoder-decoder��ܰ���������ɶ�Ӧ�е�ʫ�䡣������ڼƻ��Է�����������Ա�֤���ɵ�ʫ�������Ϻ���д�ű���һ�¡������ۺϵ��ж����۱���,���ַ����������Ƚ���ʫ�����ɷ���,Ҳ���Ǵﵽsota��ˮƽ,����ʫ��������ij�̶ֳ��Ͽ�������ʫ����������
����
�й��ŵ�ʫ�����й��Ļ�������Ҫ���Ļ��Ų�������ǧ��������ʷ��,��������������ʫ������Ӣ����������ķ羰�����顢����ȡ��й��ŵ�ʫ���в�ͬ������,���ƴ�����ʫ��ÿһ�����͵�ʫ�趼������ѭһЩ�ض��Ľṹ�����������ģʽ���±�չʾ����Ϊ�й����ܻ�ӭ��ʫ������֮һ������ʫ(���)��һ�����ӡ�

����ʫ��ԭ�����:ʫ���������,ÿ����������߸���;ÿ���ֶ���һ���ض�������,ƽ(ˮƽ��)����(������);����ʫ�еڶ��к����һ�е����һ���ַ���������ͬһѺ�����������ϸ������,д�õ�����ʫ�ͳ������н���֮����
������,ʫ���Զ����ɵ��о��ܵ��˹㷺�Ĺ�ע�������������ʹ�ù����ģ��,�Ŵ��㷨,�ܽ�ķ����Լ�ͳ�ƻ�������ķ�������ʫ�衣���,���ѧϰ�����Ѿ���Ϊһ�ź���ǰ;��ѧ��,����Ϊʫ��������һ�����е����е��������⡣��Щ����ͨ���Ǹ����û���д����ͼ(ͨ����һ��ؼ���)��ʫ�����ݼ���ѡ��һ�������ɵ�һ��,���������Ǹ��ݵ�һ�к������ɵ����ɡ��û���д����ͼֻ��Ӱ���һ��,�������п�����ʫ������û�й���,����ܻᵼ������ʫʱ�����岻һ�¡�����,ʫ�������ͨ����ѵ�����Ͽ��е�ʫ������ʾ��������������֪,��ʫ����ʹ�õĵ���,�ر����ڹŴ�д��ʫ��,�Dz�ͬ���ִ����Եġ����,����û���Ϊһ���ִ�����(������ˡ��°���)дʫ,���еķ��������������������ʫ�衣
��ƪ���������һ����ӱ��ʫ�����ɷ���,���������εĹ�������ʫ��:ʫ�������(����˵ʲô��)���ȱ���ȷ�ؼƻ���,Ȼ����б���ʵ��(�����˵��)�������û���д����ͼ,��������һ��ؼ���,һ������,��ʹ������Ȼ�����������ĵ�,��һ��Ҳ��ʹ��ʫ��滮ģ����ȷ��ʫ�������������,ÿһ�ж���һ���������ʾ��ʫ��滮ģ�ͽ��û���д����ͼ�ֽ�Ϊһϵ�е�������,ÿ�������ⶼ�����������,������д����ͼ��һ�����档Ȼ����������ʫ,ʹ�û��ڵݹ�������ı�����-������ģ��(RNNenc-dec),��������ʫ,��������Ӧ���������ǰ�����ɵ�������ÿһ�С���������RNN��enc-dec���,��֧�ֶ��������ǰ�����еı��롣���ڹ滮�Ļ�������������ķ����������ŵ㡣����,���ɵ�ʫ��ÿһ�ж����û���д����ͼ�и����ܵ���ϵ�����,ʫ��滮ģ�Ϳ��Դ�ʫ������֮��,�Ӷ����֪ʶ��Դѧϰ,����ģ�������ݻ�Ӱٿ�ȫ������ȡ��֪ʶ�����,�����������ִ�����Ŵ�ʫ�������ǵ����ּ��ϡ��ԡ������ˡ��°�����Ϊ��:���ðٿ�ȫ���֪ʶ,ʫ��滮ģ�Ϳ��Խ��û��IJ�ѯ�����ˡ��°�����չ��һϵ��������,�����㡢Ȩ����,�Ӷ�ȷ������ʫ�������һ���ԡ�
���ĵĹ����������档����,�����һ�����ڹ滮��ʫ�����ɿ��,����ȷ�ع滮��ÿһ�е������⡣���,ʹ��һ���ĵ�RNN������������,��֧�ֱ����������ǰ�����,һ��һ�е�����ʫ��
��ع���
ʫ��������NLP�е�һ�������ս�Ե�����Oliveira���������һ�ֻ���������ģ���ʫ�����ɷ�����Netzer���˲�����һ�ֻ��ڵ��ʹ��������ķ�����Tosa����ʹ����һ�ֶ��������ķ����������ձ�ʫ������ɡ�Greene����Ӧ��ͳ��ѧ�ķ��������������ɺͷ����н����ʫ�衣Colton����������һ���������Ͽ��ʫ������ϵͳ,��ϵͳʹ��ģ����ݸ�����Լ��������ʫ�衣Yan������Ϊʫ��������һ�������м���Լ�����ܽ��ܵ��Ż����⡣Manurungʹ���Ŵ��㷨������ʫ�衣����ͳ�ƻ�������(SMT)��һ����Ҫ������Jiang �� Zhouʹ�û���SMT��ģ���������ĶԾ�,���Կ�����ֻ�����еļ���ʫ�䡣��һ�б���Ϊ��Դ����,��������ɵڶ��С�He������չ���������,ͨ����ǰһ������ת��Ϊ��һ������������ʫ��
������,���ѧϰ������ʫ�����ɷ���ȡ���˾�ijɹ���Zhang��Lapata�����һ�ֻ��ڵݹ�������(RNN)������ʫ����ģ�͡��÷���ʹ�õݹ�����������ģ��(RNNLM)�Ӹ����Ĺؼ��������ɵ�һ��,Ȼ��,ͨ���ۻ�����Ϊֹ�����ɵ��е�״̬,�������ɺ������С�Wang����ʹ�ö˵�����������ģ���������δʡ��δ���ͨ�����ѳɵ��з���Ϊ���������С��������������SMT,������֮�����������Ը��á�Wang����û�п��ǵ���һ�е�����,���,��һ�������û��ṩ��,������ʫ��д�úܺõľ��ӡ�Yi��չ���ַ��������й�����ʫ�����ɵ�һ�е��������ͨ��һ����������������(NMT)ģ�������,��ģ����һ���ؼ�����Ϊ����,������ת��Ϊ��һ�С�Marjan ���������һ��ʫ�������㷨,��������������ؼ�����ص�Ѻ����,Ȼ��ʹ�ñ�����-������ģ����Ѻ������������ʫ��
���еĹ�����ͬ����ǰ�ķ������¡�����,�������û������롣��������һЩ�ؼ��ʡ��������,�������ĵ�����ǰ�ķ���ֻ��֧��һЩ�ؼ��ֻ�����ṩ��һ�С����,ʹ�û��ڹ滮�ķ���,�����û���������ȷ��ʫ������,ÿһ�ж���һ���ض���������,��֤���ɵ�ʫ��������֯����,�Ӷ�������ǰһ�ַ���������,����ֻ֤�е�һ�����û�����ͼ���,����һ���������˥�������������ͼ�ء�����,�ڽ�������������ɹ�������Ľṹ���Ƶ�,������ģ�Ϳ����Զ���ѵ�����Ͽ���ѧϰԼ�������,��ʫ������ģ�͵Ľṹ����
����
1.����
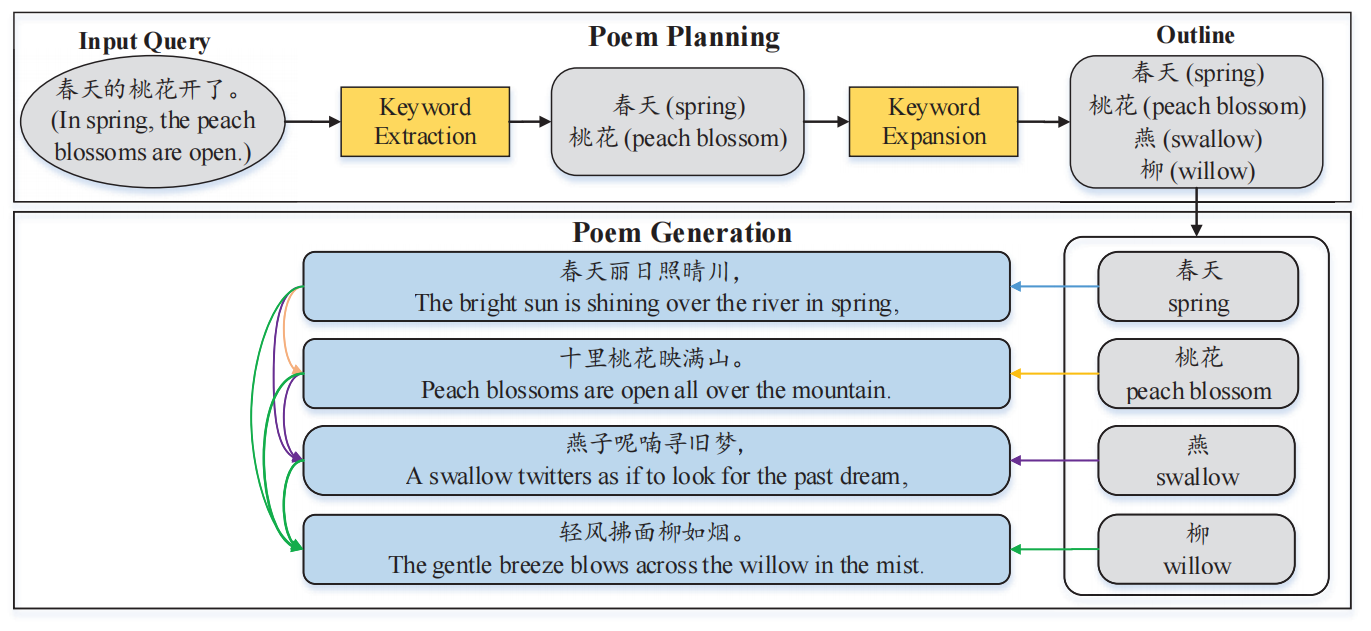
�ܹ۲쵽ʫ����дʫǰӦ�����ƶ���ٵ�����,���������һ�ֻ��ڼƻ���ʫ�����ɷ���(PPG),���ȸ����û���д����ͼ���ɴ��,Ȼ������ʫ�����PPGϵͳ���û���д����ͼ��Ϊ����,������һ�����ʡ�һ�����ӻ�һ���ĵ�,Ȼ�������������һ��ʫ:ʫ��滮��ʫ�����ɡ�PPG�����γ����˵������ͼ:
��������дһ����
N
N
N�����,
l
i
l_i
li?��ʾʫ�ĵ�
i
i
i�С���ʫ��滮��,�����ѯ��ת��Ϊ
N
N
N���ؼ���(
k
1
,
k
2
,
?
?
,
k
N
k_1,k_2,\cdots,k_N
k1?,k2?,?,kN?),
k
i
k_i
ki?������
i
i
i��ʫ�������⡣��ʫ�����ɽ�,
l
i
l_i
li?��������ͨ��
k
i
k_i
ki?��
l
1
l_1
l1?��
l
i
?
1
l_{i-1}
li?1?��ʫ��Ϊ�����,
l
1
l_1
l1?��
l
i
?
1
l_{i-1}
li?1?��ʫ������������һ�����С�Ȼ��ʫ������������,ÿһ�ж�����һ���������ǰ��������������ɡ�
2. �滮��ʫ
2.1 �ؼ�����ȡ
�û�������д����ͼ������һϵ�е�������ʾ����ʫ��滮����һ������,�������ѯ Q Q Q����ȡ�Ĺؼ��������������ʫ�е� N N N����,�����ȷ��ÿһ��ֻȡһ���ؼ�����Ϊ�����⡣����û��������ѯ Q Q Q̫��,������Ҫ��ȡ����Ҫ�� N N N������,������ԭʼ˳����Ϊ�ؼ�������,����������
����ʹ�õ���TextRank�㷨ȥ������Ҫ�Ĵ������һ�ֻ���PageRank�Ļ���ͼ�������㷨��ÿ����ѡ����ͼ�е�һ�������ʾ,�����������ʵĹ�����������֮�����ӱ�;�ߵ�Ȩ���Ǹ��������ʵĹ���ǿ�ȵ����������õġ�
TextRank����
S
(
V
i
)
S(V_i)
S(Vi?)����ʼ��ΪĬ��ֵ(����1.0),���������¹�ʽ���е�������,ֱ������:
S ( V i ) = ( 1 ? d ) + d �� V j �� E ( V i ) w j i �� V k �� E ( V j ) w j k S ( V j ) S\left(V_{i}\right)=(1-d)+d \sum_{V_{j} \in E\left(V_{i}\right)} \frac{w_{j i}}{\sum_{V_{k} \in E\left(V_{j}\right)} w_{j k}} S\left(V_{j}\right) S(Vi?)=(1?d)+dVj?��E(Vi?)��?��Vk?��E(Vj?)?wjk?wji??S(Vj?)
����, w i j w_{ij} wij?�ǽڵ� V j V_j Vj?�� V i V_i Vi?֮��ıߵ�Ȩ��, E ( V i ) E(V_i) E(Vi?)���� V i V_i Vi?���ӵĶ��㼯, d d d��һ����������,ͨ������Ϊ0.85, S ( V i ) S(V_i) S(Vi?)�ij�ʼ��������Ϊ1.0��
2.2 �ؼ�������
����û��������ѯ Q Q Q̫��,����ȡ���㹻�Ĺؼ���,������Ҫ��չһЩ�µĹؼ���,ֱ������ؼ��ֺŵ�Ҫ������ʹ�����ֲ�ͬ�ķ�������չ�ؼ��֡�
RNNLM-based method: ����ʹ��һ���ݹ�����������ģ��(RNNLM)����ǰ��Ĺؼ���˳��Ԥ������ؼ���: k i = arg ? max ? k P ( k �O k 1 : i ? 1 ) k_i= \arg \max_k P(k|k_{1:{i-1}}) ki?=argmaxk?P(k�Ok1:i?1?), k i k_i ki?��ʾ�� k k k���ؼ���, k 1 : i ? 1 k_{1:i-1} k1:i?1?���Ѿ��еĹؼ������С�
RNNLM��ѵ����Ҫһ���ɴ�ʫ������ȡ�Ĺؼ���������ɵ�ѵ����,����һ���ؼ��ִ���һ�е������⡣���Ǵ��ռ�����ʫ�����Զ�����ѵ�����Ͽ⡣������˵,����һ���� N N N����ɵ�ʫ,�������ȸ�����ʫ���Ͽ��ϼ������TextRank������ÿ���еĵ��ʽ�������Ȼ��ѡ���ı������÷���ߵĴ�����Ϊ���еĹؼ��ʡ�����,����Ϊÿ��ʫ��ȡһ���ؼ�������,��Ϊ����RNNLM�Ĺؼ���Ԥ��ģ������һ��ѵ�����Ͽ⡣
Knowledge-based method: ��������RNNLM�ķ�����������Ϊ���ռ���ʫ�������ǵ��������������⡣���û��IJ�ѯ��������ؼ���ʱ,����,ѵ�����Ͽⲻ���ǵ�����ʵ��ʱ,�˷������������ˡ�
Ϊ�˽���������,���������һ�ֻ���֪ʶ�ķ���,��ʹ�ö����֪ʶ��Դ�����������⡣�����֪ʶ��Դ����ʹ��,�����ٿ�ȫ�顢��������Ľ��顢�ʻ����ݿ�(��:WordNet)�ȡ�����һ���ؼ��� k i k_i ki?,�÷����Ĺؼ�˼�����ҵ�һЩ�ܹ���õ���������� k i k_i ki?�ĵ��ʡ�������,ʹ�ðٿ�ȫ�����Ŀ��Ϊ֪ʶ����Դ,�� k i k_i ki?����չ�µĹؼ��ʡ����Ǽ�����Щ������������������������Ϊ��ѡ�ؼ���:
- ������� k i k_i ki?��Χ [ ? 5 , 5 ] [-5,5] [?5,5]�Ĵ�����
- ������ʵĴ��������ݴʻ�����;
- ����ʱ�ʫ�����Ͽ�Ĵʻ�������
Ȼ��ѡ���ı������÷���ߵĺ�ѡ����Ϊ�ؼ��ʡ�
3.ʫ������
��ʫ�����ɽ�,ʫ���������ɵġ�ÿһ�ж���ͨ����ʫ��滮ģ��ָ���Ĺؼ��ֺ�ǰ��������ı���Ϊ���������ɵġ�������̿��Կ�����һ�����е����е�ӳ������,�����������ֲ�ͬ���͵��������:��ʫ��滮ģ��ָ���Ĺؼ��ֺ�֮ǰ���ɵ�ʫ���ı�����������һ������ע������RNN������-������(RNNRNN-dec)�Ŀ����֧�ֶ��������Ϊ���롣
����һ����
T
k
T_k
Tk?�ַ��Ĺؼ���
k
k
k,����:
k
=
{
a
1
,
a
2
,
?
?
,
a
T
k
}
k=\{ a_1, a_2, \cdots, a_{T_k}\}
k={a1?,a2?,?,aTk??},��ǰ����ı�
x
\mathbf{x}
x,������
T
x
T_x
Tx?���ַ�,����:
x
=
{
x
1
,
x
2
,
?
?
,
x
T
x
}
\mathbf{x}=\{x_1, x_2, \cdots,x_{T_x}\}
x={x1?,x2?,?,xTx??}�����Ƚ�
x
\mathbf{x}
x�����һ������״̬������
[
r
1
:
r
T
k
]
[r_1:r_{T_k}]
[r1?:rTk??],
x
\mathbf{x}
x�����
[
h
1
:
h
T
x
]
[h_1:h_{T_x}]
[h1?:hTx??], ���߶�ʹ�õ���Bi-GRUģ�͡�Ȼ��,ͨ������
[
r
1
:
r
T
k
]
[r_1:r_{T_k}]
[r1?:rTk??]�����һ��ǰ��״̬�͵�һ��ǰ��״̬,��
[
r
1
:
r
T
k
]
[r_1:r_{T_k}]
[r1?:rTk??]���ɵ�һ������
r
c
r_c
rc?��,����:
r
c
=
[
r
T
k
��
r
1
��
]
r_{c}=\left[\begin{array}{c} \overrightarrow{r_{T_{k}}} \\ \overleftarrow{r_{1}} \end{array}\right]
rc?=[rTk???r1???]
Ȼ��
h
0
=
r
c
h_0=r_c
h0?=rc?,Ȼ��������е�����
h
=
[
h
0
:
h
T
x
]
\mathbf{h}=[h_0:h_{T_x}]
h=[h0?:hTx??]�Ϳ��Ա�ʾ
k
\mathbf{k}
k��
x
\mathbf{x}
x������,����ͼ:
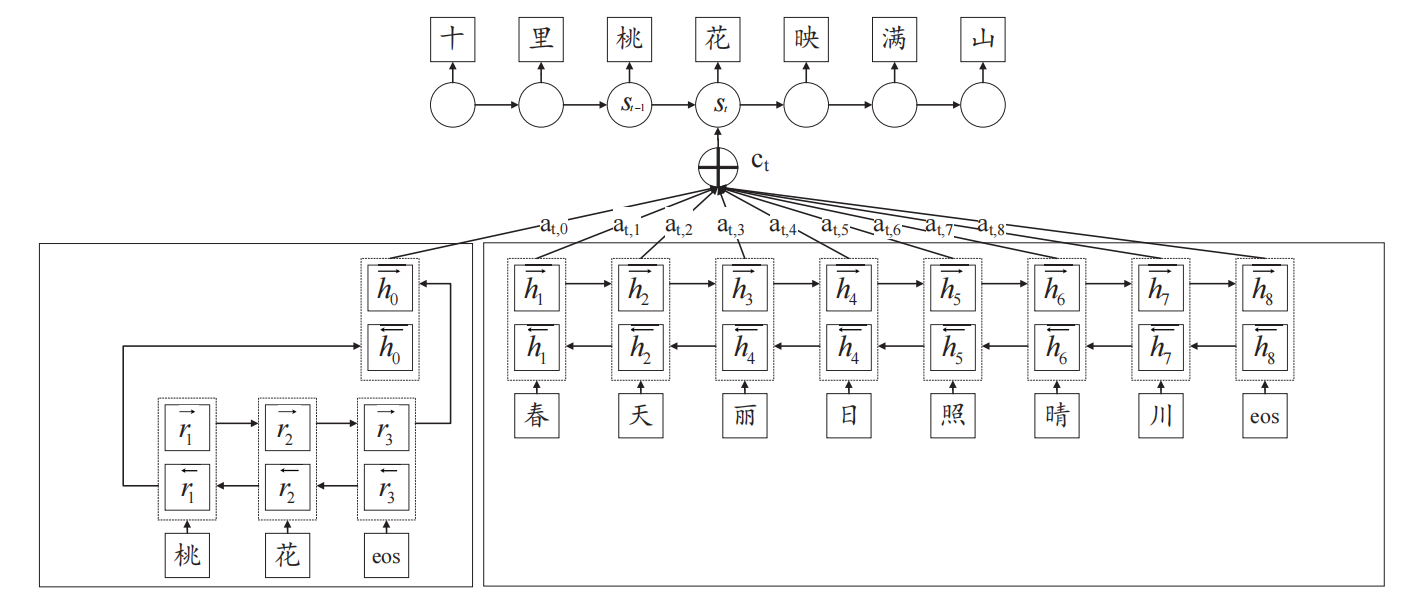
ע��,���������ɵ�һ��ʱ,ǰ����ı��ij���Ϊ��,��
T
x
=
0
T_x=0
Tx?=0,��������
h
\mathbf{h}
hֻ����һ������,��
h
=
[
h
0
]
h=[h_0]
h=[h0?],���,��һ��ʵ�������ɵ�һ���ؼ������ɵġ�
���ڽ�����,����ʹ����һ��GRU,��ά��һ���ڲ�״̬���� s t s_t st?,����ÿ�����ɲ��� t t t,����ܵ���� y t y_t yt?�ǻ��� s t s_t st?������������ c t c_t ct?��֮ǰ���ɵ���� y t ? 1 y_{t?1} yt?1?���ɵġ�����ʹ�����¹�ʽ��ʾ:
y t = arg ? max ? y P ( y �O s t , c t , y t ? 1 ) y_{t}=\arg \max _{y} P\left(y \mid s_{t}, c_{t}, y_{t-1}\right) yt?=argymax?P(y�Ost?,ct?,yt?1?)
����ÿһ��Ԥ��,
s
t
s_t
st?�ᱻ���¹�ʽ����:
s
t
=
f
(
s
t
?
1
,
c
t
?
1
,
y
t
?
1
)
s_{t}=f\left(s_{t-1}, c_{t-1}, y_{t-1}\right)
st?=f(st?1?,ct?1?,yt?1?)
f ( ? ) f(\cdot) f(?)��GRU��һ�������,ͨ������������ģ����ÿһ�����¼��� c t c_t ct?(�������attention�ļ���):
c t = �� j = 0 T h ? 1 a t j h j c_{t}=\sum_{j=0}^{T_{h}-1} a_{t j} h_{j} ct?=j=0��Th??1?atj?hj?
h
j
h_j
hj?�DZ���������еĵ�
j
j
j������״̬��Ȩ��
a
t
j
a_{tj}
atj?�������¹�ʽ�����:
a
t
j
=
exp
?
(
e
t
j
)
��
k
=
0
T
h
?
1
exp
?
(
e
t
k
)
a_{t j}=\frac{\exp \left(e_{t j}\right)}{\sum_{k=0}^{T_{h}-1} \exp \left(e_{t k}\right)}
atj?=��k=0Th??1?exp(etk?)exp(etj?)?
����:
e t j = v a T tanh ? ( W a s t ? 1 + U a h j ) e_{t j}=v_{a}^{T} \tanh \left(W_{a} s_{t-1}+U_{a} h_{j}\right) etj?=vaT?tanh(Wa?st?1?+Ua?hj?)
e
t
j
e_{tj}
etj?����ʱ�䲽��
t
t
tʱ��
h
j
h_j
hj?�ϵ�ע�����÷֡���һ������
y
t
y_t
yt?�ĸ��ʿ��Զ���Ϊ:
P
(
y
t
�O
y
1
,
��
,
y
t
?
1
,
x
,
k
)
=
g
(
s
t
,
y
t
?
1
,
c
t
)
P\left(y_{t} \mid y_{1}, \ldots, y_{t-1}, \mathbf{x}, \mathbf{k}\right)=g\left(s_{t}, y_{t-1}, c_{t}\right)
P(yt?�Oy1?,��,yt?1?,x,k)=g(st?,yt?1?,ct?)
���� g ( ? ) g(\cdot) g(?) ��һ����� y t y_t yt?�ĸ��ʵķ����Ժ�����
ʫ������ģ�͵IJ�����ѵ��,������ȵ����ѵ�����Ͽ�Ķ�����Ȼ:
arg
?
max
?
��
n
=
1
N
log
?
P
(
y
n
�O
x
n
,
k
n
)
\arg \max \sum_{n=1}^{N} \log P\left(\mathbf{y}_{\mathbf{n}} \mid \mathbf{x}_{\mathbf{n}}, \mathbf{k}_{\mathbf{n}}\right)
argmaxn=1��N?logP(yn?�Oxn?,kn?)
ʵ��
1.���ݼ�
���������о������С�����߸��ַ�������ͬ���й�����ʫ�����Ǵӻ��������ռ���76,859������ʫ,���ѡ��2000��ʫ������֤,2000��ʫ���в���,�����ʫ����ѵ����
ѵ���������е�ʫ������ʹ�û���CRF�ĵ��ʷָ�ϵͳ���ָ�ɴ��Ȼ�����ÿ�����ʵ��ı������������ı������÷���ߵĴ��ﱻѡ����Ϊ���еĹؼ��֡�����,�Ϳ���Ϊÿ������ʫ��ȡһ������4���ؼ��ʵ����С���ʫ���ѵ�����Ͽ���,��ȡ��72,859���ؼ�������,����ѵ��RNN����ģ�ͽ��йؼ�����չ�����ڻ���֪ʶ����չ,����ʹ�ðٶȰٿƺ�ά���ٿ���Ϊ�����֪ʶ��Դ��
������ʫ����ȡ�ĸ��ؼ��ֺ�,����Ϊÿ��ʫ�����ĸ�������ɵ���Ԫ��(�ؼ��֡�ǰ����ı�����ǰ��)����ͼ:

2.ѵ��
��������Ļ���ע������RNN����ģ��,����ѡ����6000����õ��ַ���ΪԴ�ߺ�Ŀ��ߵĴʻ��������Ƕ��ά��Ϊ512,���ɵ���2vec��ʼ������������������������ѭ�����ز����512�����ص�Ԫ��ģ�͵IJ����ھ��ȷֲ��������ʼ��,��Χ��[-0.08,0.08]����ģ�Ͳ���AdaDelta�㷨����ѵ��,����minibatch������Ϊ128��������֤���ϵ���ʧ���,ѡ�����յ�ģ�͡�
3.����
3.1 ����ָ��
������֪,ȷ�����ı�����ϵͳ�����ѵ�,��ʫ�����ɺͶԻ���Ӧ���ɡ�����һ���ض�������,�г�ǧ����ķ�����������һ���ʵ��ĺ���ص�ʫ���Ի�����Ӧ,���IJο����ײ����ܺ���������ȷ�Ľ����Liu �������,�����ص����Զ�����������Ӧ�ڶԻ���Ӧ,BLEU��METEOR��������������Բ������,���ǽ�����һ�������о�������ʫ������ģ�͡����Ƕ�����������ʹ���������۱�������ʫ��:��ʫ�⡱���������ԡ���������ԡ��������塱����ϸ��˵���������±�:

������ĵ÷ִ�1��5��,�÷�Խ��Խ�á�ÿ��ϵͳ����20��5�ֵ�����ʫ��20��7�ֵ�����ʫ���������ɵ�ʫ�趼��5λר�ҽ�������,��ƽ�����ַ�����Ϊ���շ�����
3.2 ����
����ʵ���˼���ʫ�����ɷ�����Ϊ����,�������з�����������ͬ��Ԥ����������
SMT.: һ�ֻ���ͳ�ƻ���������й�ʫ�����ɷ�����һ��ʫ��ͨ�������롱����һ�е������ɵġ�
RNNLM:һ�������ı����еķ�����һ��ʫ�ļ��б���Ϊһ����ɫ����������һ��,����ѵ��RNNLM��
RNNPG:�ڻ���RNN��ʫ���������ķ�����,��һ���ɱ�RNNLM����,Ȼ�����ǰһ�б�������������������������������С�
ANMT:����ע�������������뷽����������������Ϊһ��������������,�������ڴ�ͳ��SMT��������Ҫ��������ANMT��,��������ϵͳ��һ�����Ļ���ע������RNN enc-dec���.
3.3 ���
������ר�����۵Ľ������:
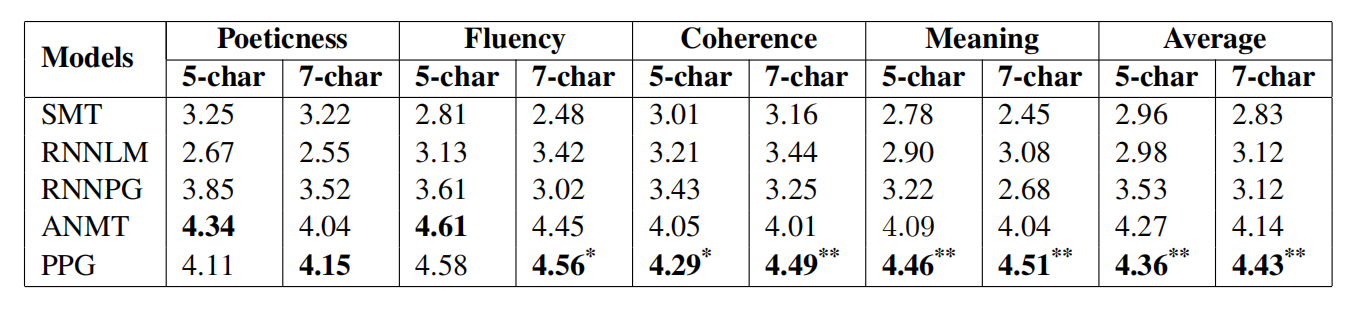 ���ǿ��Կ���,��������ķ���,���ڹ滮��ʫ������(PPG),��ƽ�������������еĻ���ģ�͡������5���ֺ�7����ʫ������һ�¡�
���ǿ��Կ���,��������ķ���,���ڹ滮��ʫ������(PPG),��ƽ�������������еĻ���ģ�͡������5���ֺ�7����ʫ������һ�¡�
SMT���ɵ�ʫ���ʫ������RNNLM,˵�����ڷ���ķ������Ը��õز�����������֮���ӳ���ϵ��ANMT��һ����ǿ�Ļ���,���������SMT��RNNLM��RNNPG,���������ǵķ�����ANMT��PPG��ʹ�û���ע������endec��ܡ���Ҫ��������,���ǵķ���������ʫ֮ǰΪÿһ�ж����������⡣ANMT����ֻ�ǽ�ǰ����ı�ת��Ϊ��һ�С����û���������ָ��,��ϵͳ�����������һ�㵫����ô������Ľ�������֮��,���ǵķ�����ȷ�ؿ����˹ؼ���,��ÿһ�е������ⶼ�и��õĿ��ơ����˹����۽�����Կ���,��ANMT���,�÷�����ʫ��������ȷ���ȡ���˷dz��ӽ�������,������Ժͺ���÷�Ҫ�ߵö�,��֤��������Ԥ��ģ�͵���Ч�ԡ�
4.�Զ�����vs��������ʫ
���ǽ�����һ����Ȥ������,ֱ�ӽ����ǵ��Զ�ʫ������ϵͳ������ʫ�˽����˱Ƚ�,��������ͼ����ԡ����ǴӲ��Լ��������ȡ��20�����й��Ŵ�ʫ��д��ʫ����������Щʫ�ı�����Ϊ����,��ͨ�����ǵ��Զ�����ϵͳ������20��ʫ�����,�������ɵ�ʫ�������ഴ����ʫ������ͬһ���⡣Ȼ������Ҫ��һЩ����������������������д��ʫ��ͻ������ɵ�ʫ�衣�����ܹ���40�������ߡ����Ƕ��ܹ����ý���,ӵ��ѧʿ�����ѧ��������4��Ϊ�й���ѧרҵ��ʿ,�������䵽ר���顣����36�������߱����䵽�����顣��ä����,����ÿ����������չʾһ��ʫ�������,�����߱�Ҫ�������ѡ����ѡ��:(1)ʫA������д��;(2)ʫB������д��;(3)������������������д�ġ�
���۽����ʾ����ͼ:

���ǿ��Կ���,49.9%�Ļ������ɵ�ʫ�豻�����ʶ��Ϊ������д��ʫ��,���߲��ܱ������������������֡����ǿ��Կ���,49.9%�Ļ������ɵ�ʫ�豻�����ʶ��Ϊ������д��ʫ��,���߲��ܱ������������������֡����ǿ��Դӽ���еó���������:(1)�������û��ı���,���ǵĻ�������ʫ��������dz��ӽ�����ʫ��;(2)����רҵר�ҵĽǶ�����,�������ɵ�ʫ��������д��ʫ�������Ȼ��һЩ���ԵIJ��㡣��ͼ����һ����ä����ѡ�������ʫ�����ӡ�

5.����ʾ��
�����ϱ��еĹŴ�ʫ����,���ǵķ������������ɻ����κ��ִ������ʫ�衣�±�չʾ��һЩʾ����ʫ�ı�����ơ��,���ǵ�ʫ��滮ģ�����Ĺؼ�����ơ��,�㴼,��ˬ�������ұߵı�����һ�����������ұ��ĵ�ʵ��������,ʫ��滮ϵͳ���˱���֮��,�������������ؼ���:��ˮ�����Ǻ�����,��Щ�������ߵ���Ʒ�йء�

�����������
�ڱ�����,���������һ���µ�����ʫ�����ɷ���,��������ȷ�ؽ��û���д����ͼ�ֽ�Ϊһϵ��������,Ȼ��ʹ�øĽ��Ļ���ע������RNN������-��������ܵ�������һ��ʫ�衣�ĺ��RNN enc-decģ��������������,����ͬʱ�����������ǰ����ı�������ר�ҵ���������,���ǵķ����������еĻ���ģ��,ʫ��������ij�̶ֳ��Ͽ���������ʫ�������������ǻ�֤����ʹ�ðٿ�ȫ����Ϊ�����֪ʶ��Դ,���ǵķ������Խ��û���������չ���ʵ�����������,�Ա�����ʫ�衣��δ��,���ǽ��о����������滮����,��PLSA��LDA��word2vec������Ҳ�������ǵķ���Ӧ����������ʽ����ѧ����,��ʫ�衢Ԫ����,���������Ե�ʫ�衣
�ҵ��ܽ�
������˵,�������̲����Ǻܸ���,˼·�Ƚ�����,���۷�ʽҲ�Ƚ��ر�,����Ҳ�ܹ����ա�����֮��,��֪��������û�г��Խ�ʫ���е�ƽ�������ӽ�ȥ,�ӽ�ȥ��������Dz��Ǹ���������?�����л�����Գ��Ը���һ�¡���Ȼ,�����Ҫ�Լ�ȥ��ȡ����,Ҫȥ���ֵĻ�,Ҫ���Ļ������ϡ������漰��һЩ�㷨��TextRankҲ��һ���Ƚ�����˼���㷨,�¸�,��ʱ��Ҳ������һƪ���¡�fighting!!!