使用 C++, CUDA 扩展 PyTorch
准备工作
请先确定一下 PyTorch 版本:
>>> torch.__version__
‘1.9.1’
>>> torch.version.cuda
‘11.1’
>>> torch.backends.cudnn.version()
8005
实验环境:

用 C++ 扩展 PyTorch
官网上案例使用的算子大多和 python 的接口差不多,而有的时候我们需要操作 Tensor 的具体元素,这时候就要用到 Using accessors 那一小节介绍的技术
这里我们在人尽皆知的快速排序上进行实验:
首先是我们的源程序:
quickSort.cpp
#include <torch/extension.h>
void quickSort(torch::Tensor& src, int begin, int end) {
auto src_a = src.accessor<int, 1>();
if (begin < end) {
auto key = src_a[begin];
int i = begin;
int j = end;
while (i < j) {
while (i < j && src_a[j] > key)
--j;
if (i < j) {
src_a[i] = src_a[j];
++i;
}
while (i < j && src_a[i] < key)
++i;
if (i < j) {
src_a[j] = src_a[i];
--j;
}
}
src_a[i] = key;
quickSort(src, begin, i-1);
quickSort(src, i+1, end);
}
}
void QuickSort(torch::Tensor& src) {
quickSort(src, 0, src.size(0));
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("quick_sort", &QuickSort, "cpp implementation for quick sort");
}
<torch/extension.h> 头文件是写 cpp 扩展所必须的,它大概包括三部分:
- Aten 库,它是 PyTorch 用于张量计算的主要 API
- pybind11,它是 PyTorch 为 C++ 代码创建 Python 绑定的方式
- 一些头文件,负责管理 ATen 和 pybind11 之间的交互细节
之后重点是我们的 .accessor<int, 1>()
它为我们提供了一种像数组一样操作 torch::Tensor 的方法,这里我们指定 src 为一维 int 数组
然后就可以用我们熟悉的 c++ 代码去书写快速排序的算法了,具体细节这里就不介绍了
最后是 pybind11 的语法,我们用 m.def(…) 在该模块内定义了名为 quick_sort ,实际调用了 QuickSort 的方法
接着在同级目录下还需要一个 setup.py 文件:
setup.py
from setuptools import setup, Extension
from torch.utils import cpp_extension
setup(name='quickSort_cpp',
ext_modules=[cpp_extension.CppExtension('quickSort_cpp', ['quickSort.cpp'])],
cmdclass={'build_ext': cpp_extension.BuildExtension})
这基本上就是套用模板,注意模块名为 quickSort_cpp ,对应的 cpp 源文件就是上面的 quickSort.cpp
这是最后的目录结构:
在这里调用:
python setup.py install
等待片刻,出现:
就可以进行测试了:
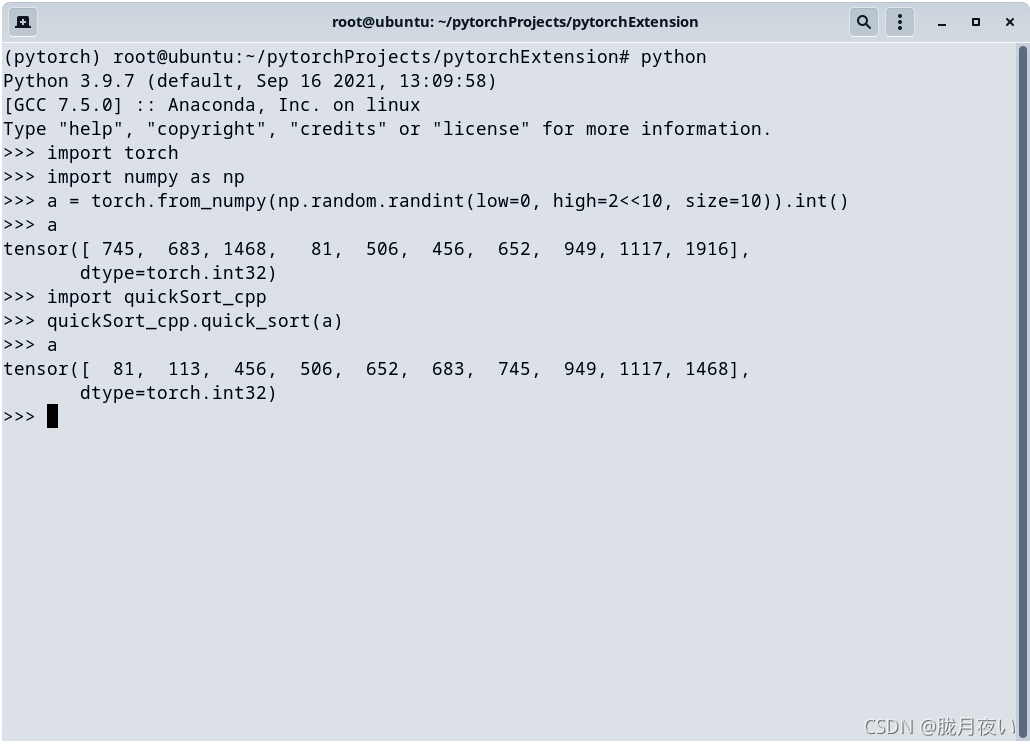
只要注意类型相互对应,基本上不会有什么问题
用 CUDA 扩展 PyTorch
为了利用 GPU 并行计算的优势,更多的时候我们需要为自己的扩展编写 CUDA 版本的代码
下面我们用 Hadamard 乘积来演示用 CUDA 扩展 PyTorch:
其实和 C++ 扩展 PyTorch 的方法差不多,我们只需要让 C++ 程序作为中介,即可联系起 PyTorch 和 CUDA
先用之前提到的 accessors 来写:
hadamard_cuda.cpp
#include <torch/extension.h>
// CUDA declarations
void hadamard_cuda_kernel(torch::Tensor A, torch::Tensor B, torch::Tensor C);
// C++ interface
void hadamard_cuda(torch::Tensor A, torch::Tensor B, torch::Tensor C) {
hadamard_cuda_kernel(A, B, C);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("hadamard_cuda", &hadamard_cuda, "hadamard product (CUDA)");
}
我们用 C++ 程序封装起 CUDA 的调用:
hadamard_cuda_kernel.cu
#include <torch/extension.h>
template <typename scalar_t>
__global__ void _hadamard(
const torch::template PackedTensorAccessor32<scalar_t, 2, torch::RestrictPtrTraits> A,
const torch::template PackedTensorAccessor32<scalar_t, 2, torch::RestrictPtrTraits> B,
torch::template PackedTensorAccessor32<scalar_t, 2, torch::RestrictPtrTraits> C,
int m, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < m && j < n)
C[i][j] = A[i][j] * B[i][j];
}
void hadamard_cuda_kernel(torch::Tensor A, torch::Tensor B, torch::Tensor C) {
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(A.size(0) / threadsPerBlock.x, A.size(1) / threadsPerBlock.y);
AT_DISPATCH_ALL_TYPES(A.scalar_type(), "hadamard_product_cuda", ([&] {
_hadamard<scalar_t><<<numBlocks, threadsPerBlock>>>(
A.packed_accessor32<scalar_t, 2, torch::RestrictPtrTraits>(),
B.packed_accessor32<scalar_t, 2, torch::RestrictPtrTraits>(),
C.packed_accessor32<scalar_t, 2, torch::RestrictPtrTraits>(),
A.size(0), A.size(1));
}));
}
这里我们只是简单地实现一下,还有很多优化方法暂且不管
然后是我们的 setup.py,这个和之前的差不多:
setup.py
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CUDAExtension
setup(
name='hadamard_cuda',
ext_modules=[
CUDAExtension('hadamard_cuda', [
'hadamard_cuda.cpp',
'hadamard_cuda_kernel.cu',
])
],
cmdclass={
'build_ext': BuildExtension
})
为了方便之后的测试,我们再写一个:
test.py
import torch
import hadamard_cuda
print("cuda:", torch.cuda.is_available())
device = torch.device('cuda')
A = torch.randint(low=0, high=10, size=(16, 16), device=device)
B = torch.randint(low=0, high=10, size=(16, 16), device=device)
print(A[0:5, 0:5])
print(B[0:5, 0:5])
C = torch.randint(low=0, high=10, size=(16, 16), device=device)
hadamard_cuda.hadamard_cuda(A, B, C)
print("After hadamard (CUDA)")
print(C[0:5, 0:5])
下面是最后的目录结构:
在当前目录下运行:
python setup.py install
等待片刻,直至出现:
接着我们就可以进行测试了:
python test.py
结果:
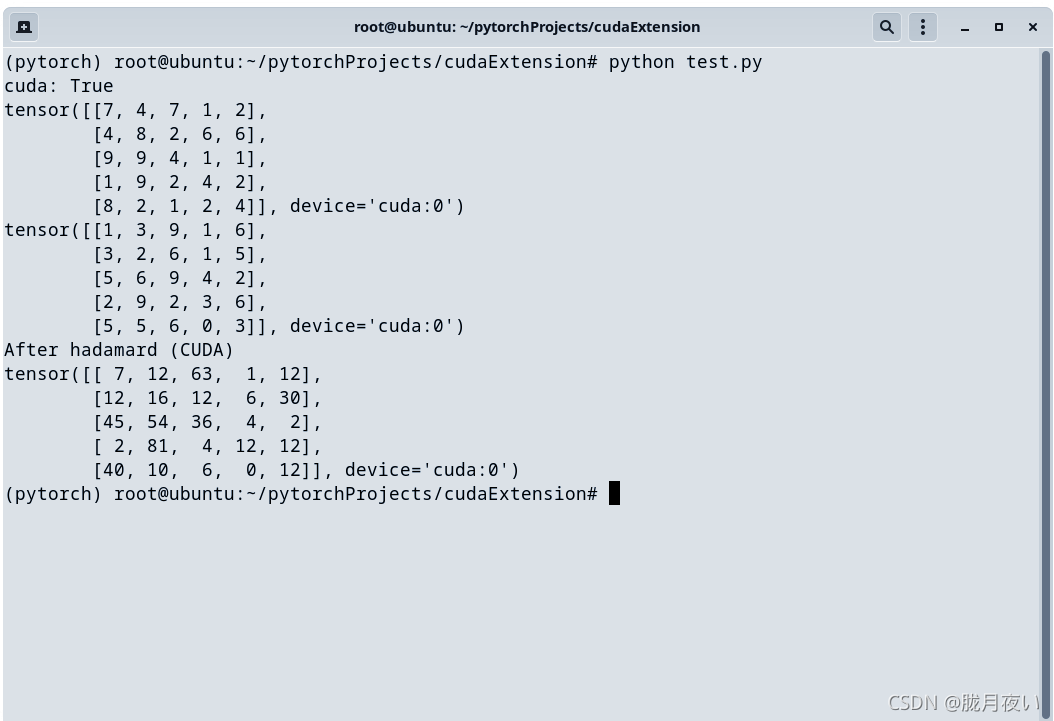
注意类型的统一
这是在较新版本的 PyTorch 上使用的方法,然而,很多时候我们还会看到不少 c 风格的 CUDA 程序,下面介绍和这些程序交互的方法:
假如,我们遇到下面这样的 CUDA 程序:
foo_cuda_kernel.cu
#include <cuda.h>
#include <cuda_runtime.h>
__global__ void _foo(int* A, int* B, int* C, int m, int n) {
/* do something */
}
void foo_cuda_kernel(int* A, int* B, int* C, int m, int n) {
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(m / threadsPerBlock.x, n / threadsPerBlock.y);
_foo<<<numBlocks, threadsPerBlock>>>(A, B, C, m, n);
}
我们可以将封装所用的 C++ 程序重新改写成下面的样子:
foo_cuda.cpp
#include <torch/extension.h>
// CUDA declarations
void foo_cuda_kernel(int* A, int* B, int* C, int m, int n);
// C++ interface
void foo_cuda(torch::Tensor A, torch::Tensor B, torch::Tensor C) {
foo_cuda_kernel((int *) A.data_ptr<int>(),
(int *) B.data_ptr<int>(),
(int *) C.data_ptr<int>(),
A.size(0), A.size(1));
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("foo_cuda", &foo_cuda, "(CUDA)");
}