Ŀ¼
1.Yolov4��������ܹ�
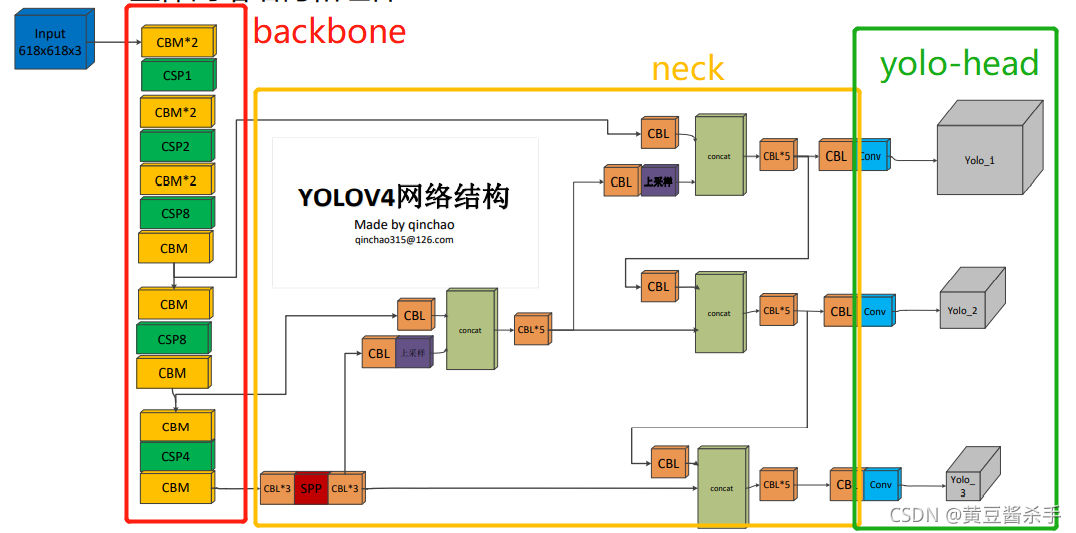
�������������������backbone��neck��head����,ע����ɫ����������head����(��������ʵ��ʱ������neckһ����,������)��
1.1backboneģ��
backbone���ְ���CBM��CSP������ģ�顣CBM��ʾConv+Normalization+Mish�ṹ,CSP��ʾCBM+ResUnit+concat���,����(608,608,3),���(76,76,256)��(38,38,512)��(19,19,1024),��������:
1.1.1CBM��ģ��
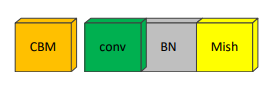
CBM��backbone�еĻ���ģ��,�ɻ����ĵ��������conv������BatchNormalization��һ��Mish���������ɡ�Mish�������ʽ����:
f
(
x
)
=
x
tanh
?
(
log
?
(
1
+
e
x
)
)
(1)
\bm{f(x)=x\tanh(\log(1+e^{x}))\tag{1}}
f(x)=xtanh(log(1+ex))(1)
ע��: pytorch��δʵ��Mish�������API����,�����Ҫ�Լ�����ʹ��,��������:
class Mish(nn.Module):
def __init__(self):
super(Mish, self).__init__()
def forward(self, x):
return x * torch.tanh(F.softplus(x))
1.1.2CSPX��ģ��
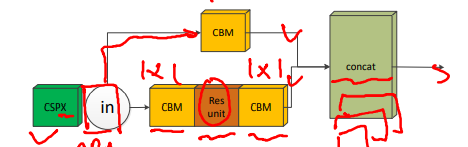
ע��:CSPX���е�X��ʾ�·�·����CBM�м�вԪ(Res unit)�ĸ���
in : ��ʾ��һ��������ģ������,���������������·:
- �·�·ΪCBM��Res unit��CBM
- �Ϸ�·Ϊһ��CBM��ģ��
- ���·�·�������concat
concat: ���·�·����concat�ѵ���һ��,������·���
(
152
,
152
,
282
)
(152,152,282)
(152,152,282)����·���
(
152
,
152
,
318
)
(152,152,318)
(152,152,318),concat���Ϊ
(
152
,
152
,
600
)
(152,152,600)
(152,152,600)��
CBM: ͬ��1.1.1
Res unit:
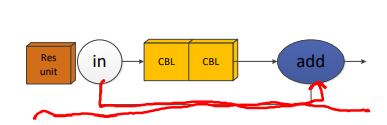
Res unit������CBL��ɵ��Ϸ�·����Ϊ�·�·��ԭ�������add����,������·���
(
152
,
152
,
282
)
(152,152,282)
(152,152,282)����·���
(
152
,
152
,
318
)
(152,152,318)
(152,152,318),��ͨ����Ӧλ��Ԫ��ֱ�����(add),ά�Ȼ���
(
152
,
152
,
318
)
(152,152,318)
(152,152,318)��
CBL:�ɻ����ĵ��������conv������BatchNormalization��һ��Leakyrelu���������ɡ�Leakyrelu�������ʽ����:
f
(
x
)
=
{
z
,
i
f
(
z
>
0
)
a
z
,
i
f
(
z
�Q
0
)
(2)
\bm{f(x)=\left\{\begin{aligned}&z, &if(z>0)\\ &az, &if(z\leqq0)\end{aligned}\right.\tag{2}}
f(x)={?z,az,?if(z>0)if(z�Q0)?(2)
1.2neckģ��
neck���ְ���CBL��SPP�Լ��ϲ���������ģ�顣CBL��ʾConv+BatchNormalization+LeakyRelu�ṹ
SPP��ʾһ������ͼ����3�����ػ�+һ��ֱ��,���ͨ��ƴ�ӵõ������
�ϲ���������(608,608,3),���(76,76,256)��(38,38,512)��(19,19,1024),��������:
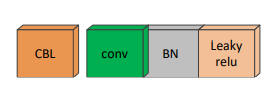
1.2.1CBL��
CBL���ɻ����ĵ��������conv������BatchNormalization��һ��Leakyrelu���������ɡ�Leakyrelu�������ʽ����:
f
(
x
)
=
{
z
,
i
f
(
z
>
0
)
a
z
,
i
f
(
z
�Q
0
)
(2)
\bm{f(x)=\left\{\begin{aligned}&z, &if(z>0)\\ &az, &if(z\leqq0)\end{aligned}\right.\tag{2}}
f(x)={?z,az,?if(z>0)if(z�Q0)?(2)
1.2.2SPP��
SPP������ֱ��������maxpooling,����������ͼά�Ȳ���,������ͬ����(ֱ��)��ͬƴ����һ��(concat),����ͼ��ʾ:
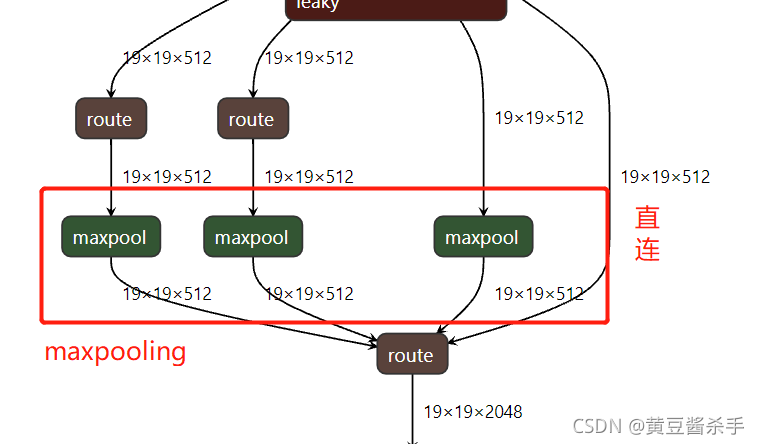
concat�������Ϊ(19,19,512),������һ��(19,19,2048)������ͼ��
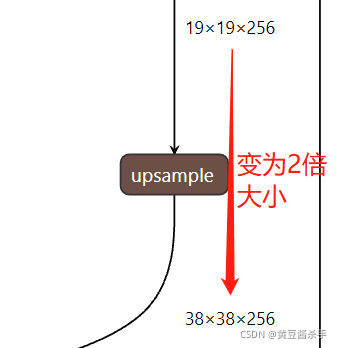
1.2.3�ϲ�����
�ϲ���(upsample)����������ͼ��С(YOLOV4���ϲ���Ϊԭ����2��),���ı�ͨ����,����:
1.3headģ��
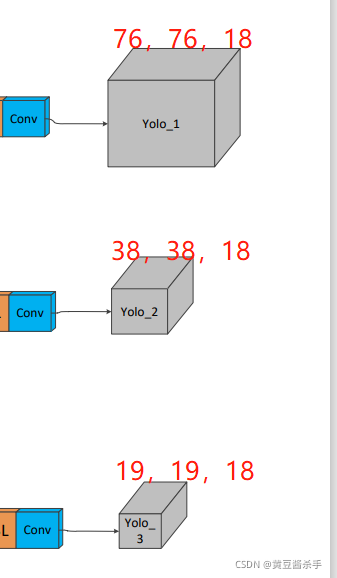
head����yoloģ�����һ���conv��,�Լ�yolo-decode(ģ��������н������)��
yolo-head��������ͷ��,��С�ֱ�Ϊ
(
76
,
76
)
(76,76)
(76,76)��
(
38
,
38
)
(38,38)
(38,38)��
(
19
,
19
)
(19,19)
(19,19)��
1.3.1conv��
conv�����ڽ����ѹ������Ӧ���ά��,��Ӧά��Ϊ: ( 76 , 76 , 3 ? ( 4 + 1 + c l a s s ) ) (76,76,3*(4+1+class)) (76,76,3?(4+1+class))�� ( 38 , 38 , 3 ? ( 4 + 1 + c l a s s ) ) (38,38,3*(4+1+class)) (38,38,3?(4+1+class))�� ( 19 , 19 , 3 ? ( 4 + 1 + c l a s s ) ) (19,19,3*(4+1+class)) (19,19,3?(4+1+class))
- class��ʾ��Ҫ�ķ���ά��,���������˺ͳ���class��������Ϊ2�������anchor�����������ĸ���
- 3��ʾÿ������������������ѡ��(anchor1��anchor2��anchor3)
- 4��Ԥ������ĵ�Ϳ��ߵ�λ����Ϣ(tx,ty,tw,th)
- 1��ʾ��������ĸ���(conf)
ע��:�����������(19,19)��yolo-head����˵��,����ά�ȵ�decode������
��conv����������reshape��ͱ��
(
3
,
19
,
19
,
4
+
1
+
c
l
a
s
s
)
(3,19,19,4+1+class)
(3,19,19,4+1+class)
1.3.2yolo-decode
tx��ty����sigmoid��ֱ��ʾ��Ӧ�����ϵ����ֵ,��Ը�����߽��λ��,����:

��
(
t
x
)
\bm{\sigma(t_x)}
��(tx?)��Ϊtx����sigmoid������Ľ��,����Ϊ0.3,���ʾ��Ԥ���(ģ��Ԥ����������)�����ĵ�λ��19*19����ͼ��ij������(����Ϊ�����С�������)�е����λ��,��������߽���Ϊ0,�ұ߽���Ϊ1
ͬ��
��
(
t
y
)
\bm{\sigma(t_y)}
��(ty?)��
tw��th��ʾ����Ԥ��anchor�����ű���,����Ԥ��anchorΪ[142.0,65.0],tw��th����
e
t
w
e^{tw}
etw��
e
t
h
e^{th}
eth�������ʾԤ���ΪԤ�������ű���,����1.3��ʾԤ������Ϊ:
i
n
t
(
142.0
?
1.3
)
=
i
n
t
(
184.6
)
=
184
int(142.0*1.3)=int(184.6)=184
int(142.0?1.3)=int(184.6)=184
ͬ��
t
h
\bm{th}
th��
tx��ty:
t
x
,
t
y
=
o
u
t
p
u
t
[
��
,
0
]
,
o
u
t
p
u
t
[
��
,
1
]
(3)
tx,ty=output[��,0],output[��,1]\tag{3}
tx,ty=output[��,0],output[��,1](3)
g
r
i
d
_
x
=
[
1
2
?
19
?
?
1
2
?
19
]
(4)
grid\_x=\begin{bmatrix} 1&2&\cdots&19\\ &\cdots&\cdots\\ 1&2&\cdots&19\\ \end{bmatrix}\tag{4}
grid_x=???11?2?2?????1919????(4)
g
r
i
d
_
y
=
[
0
0
?
0
?
?
19
19
?
19
]
(5)
grid\_y=\begin{bmatrix} 0&0&\cdots&0\\ &\cdots&\cdots\\ 19&19&\cdots&19\\ \end{bmatrix}\tag{5}
grid_y=???019?0?19?????019????(5)
b
x
=
s
i
g
m
o
i
d
(
t
x
)
,
b
y
=
s
i
g
m
o
i
d
(
t
y
)
(6)
bx=sigmoid(tx),by=sigmoid(ty)\tag{6}
bx=sigmoid(tx),by=sigmoid(ty)(6)
b
x
+
=
g
r
i
d
_
x
,
b
y
+
=
g
r
i
d
_
y
(7)
bx+=grid\_x,by+=grid\_y\tag{7}
bx+=grid_x,by+=grid_y(7)
b
x
=
b
x
/
W
,
b
y
=
b
y
/
W
(8)
bx=bx/W,by=by/W\tag{8}
bx=bx/W,by=by/W(8)
��ʱ��bx��by��ʾԤ������ĵ�λ��ԭͼ�����λ��,����:ԭͼ(608,608),bx=0.3���ʾ��Ԥ�������ĵ��x����Ϊ:
i
n
t
(
608
?
0.3
)
=
i
n
t
(
182.4
)
=
182
(9)
int(608*0.3)=int(182.4)=182\tag{9}
int(608?0.3)=int(182.4)=182(9)
tw��th:
����tw�ļ�����Ҫ���ڽ�tw����
e
t
w
e^{tw}
etw���ʾ����Ԥ��anhor�Ŀ�������,��anchor��С��ʾԤ�����ԭͼ�ϵĿ�,�ٳ���608,��ʾ��Դ�С,����:Ԥ����СΪ��������182,����Դ�СΪ182/608=0.2993,�Ӷ���tw�õ���bwͳһ��tx��tyһ������С֮�С�
ͬ��th��
ֻ�����Ǻ���������Щ��ʽ�ȽϷ���
b
w
=
s
c
a
l
e
_
x
_
y
?
e
t
w
?
0.5
?
(
s
c
a
l
e
_
x
_
y
?
1
)
(10)
bw=scale\_x\_y*e^{tw}-0.5*(scale\_x\_y-1)\tag{10}
bw=scale_x_y?etw?0.5?(scale_x_y?1)(10)
b
h
=
s
c
a
l
e
_
x
_
y
?
e
t
h
?
0.5
?
(
s
c
a
l
e
_
x
_
y
?
1
)
(11)
bh=scale\_x\_y*e^{th}-0.5*(scale\_x\_y-1)\tag{11}
bh=scale_x_y?eth?0.5?(scale_x_y?1)(11)
b
w
?
=
a
n
c
h
o
r
/
32
,
b
h
?
=
a
n
c
h
o
r
/
32
(12)
bw*=anchor/32,bh*=anchor/32\tag{12}
bw?=anchor/32,bh?=anchor/32(12)
�����32��608/19,��19��yolo_head��Ӧ��ԭͼ��С�ı�����
b
w
/
=
19
,
b
h
/
=
19
(13)
bw/=19,bh/=19\tag{13}
bw/=19,bh/=19(13)
��ʱ��bw��bh��Ϊ���ԭͼ608��Ԥ���Ŀ��Ⱥ߶ȡ�
����Ԥ������Ϻ���������λ��:
b
x
1
=
b
x
?
b
w
/
2
(14)
bx1=bx-bw/2\tag{14}
bx1=bx?bw/2(14)
b
y
1
=
b
y
?
b
h
/
2
(15)
by1=by-bh/2\tag{15}
by1=by?bh/2(15)
b
x
2
=
b
x
+
b
w
/
2
(16)
bx2=bx+bw/2\tag{16}
bx2=bx+bw/2(16)
b
y
2
=
b
x
+
b
h
/
2
(17)
by2=bx+bh/2\tag{17}
by2=bx+bh/2(17)
b
x
1
=
b
x
1
?
608
(
w
)
(18)
bx1=bx1*608(w)\tag{18}
bx1=bx1?608(w)(18)
b
y
1
=
b
y
1
?
608
(
h
)
(19)
by1=by1*608(h)\tag{19}
by1=by1?608(h)(19)
b
x
2
=
b
x
1
?
608
(
w
)
(20)
bx2=bx1*608(w)\tag{20}
bx2=bx1?608(w)(20)
b
y
2
=
b
y
1
?
608
(
h
)
(21)
by2=by1*608(h)\tag{21}
by2=by1?608(h)(21)
��ʱ��(bx1,by1),(bx2,by2)��ΪԤ�����ԭͼ�е�����λ��,�����������,��Ը��������Ԥ���ΪĿ��Ԥ������