<--------感谢评论、答疑、指正!--------->
2021.10.5
LeeML-Notes:P22
洋洋洒洒老师讲了一大章,主要内容很简单,讲了俩事
1. 同样数量的参数,哪种模型好?
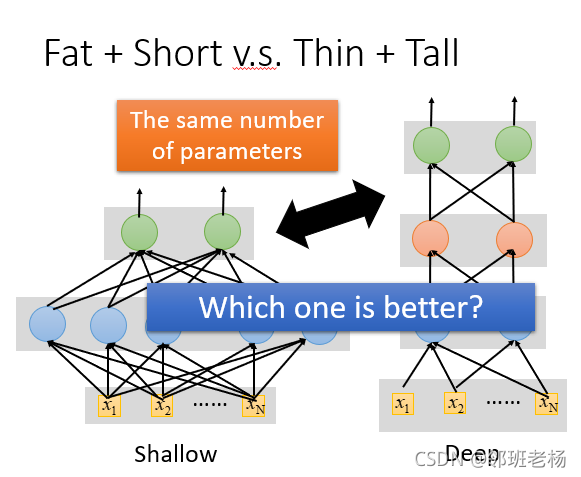
前提就是调整shallow和Deep让他们的参数是一样多,shallow model较好还是deep model较好?

【相同参数量的时候】
- 我们用5层hidden layer,每层2000个neural,得到的error rate是17.2%
- 相对应的一层的模型,得到的错误率是22.5%,
【结论】
- 是单纯的增加parameters,是让network变宽不是变高的话,其实对performance的帮助是比较小的。
- 也就是,层数深的模型(瘦的)比层胖的效果好。
2. 原因
2.1 问题1:为什么变高比变宽好呢?
-
我们在做deep learning的时候,其实我们是在模块化这件事。
-
如果直接分类,分为四类,这样因为第二类数量少训练效果很差

-
如果模块化,先分男女,长短 再训练,即使那组数量少 也会有较好的效果
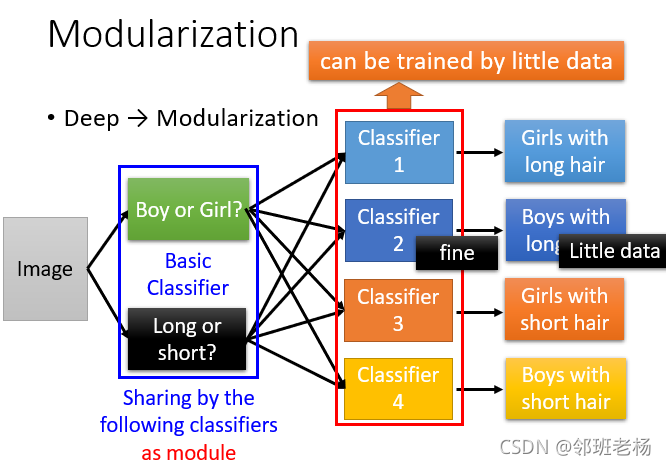
2.2 问题2:深度学习和模组化有什么关系?
老师可能举例四五个例子 说明了一件事:实验证明,确实深度和模块化有关。 下面是几个简单例子:
【例1】
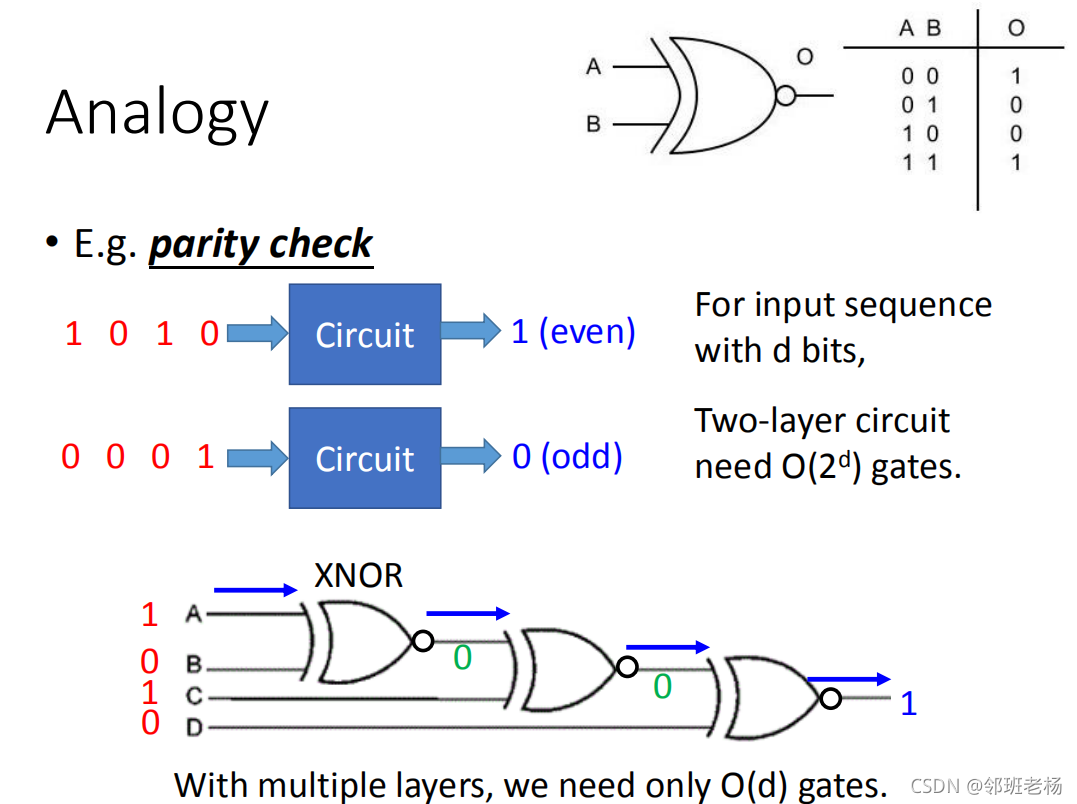
- 一层的话 O ( 2 d ) O(2^d) O(2d)
- 多层的话 O ( d ) O(d) O(d)
- 套娃(多层)比一层效率高
【例2】
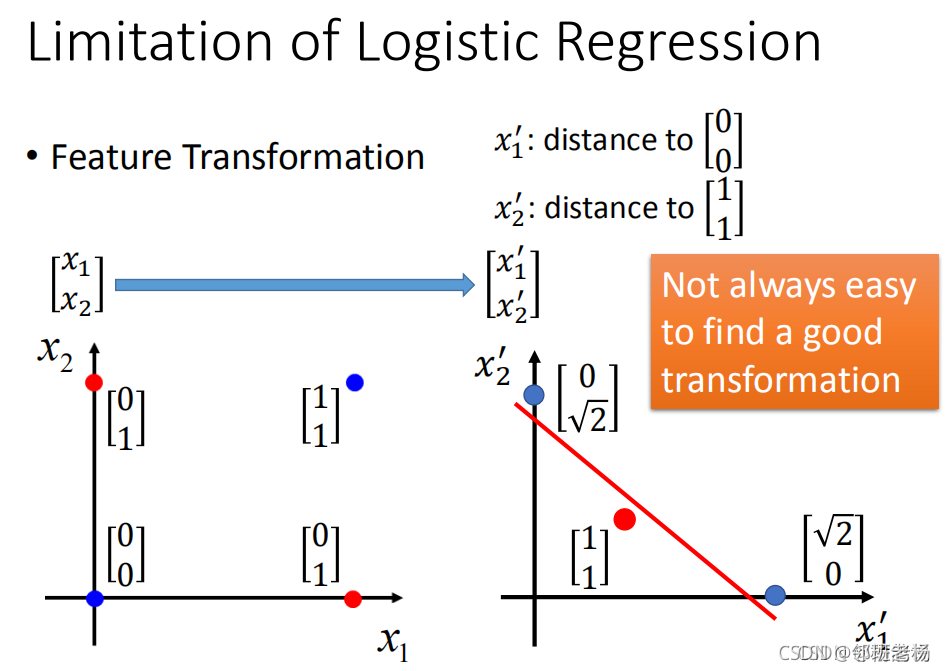
- 类似与折花,一张纸上的时候 无法将红蓝两点分类
- 加了个隐藏层,我们如图,分别将到 [ 0 , 0 ] T 距 离 作 为 x 1 ′ , [ 1 , 1 ] T 距 离 作 为 x 2 ′ , [0,0]^T距离作为x'_1,[1,1]^T距离作为x'_2, [0,0]T距离作为x1′?,[1,1]T距离作为x2′?,原本红蓝点就可分类了。
- 深层可以解决浅层解决不了的问题
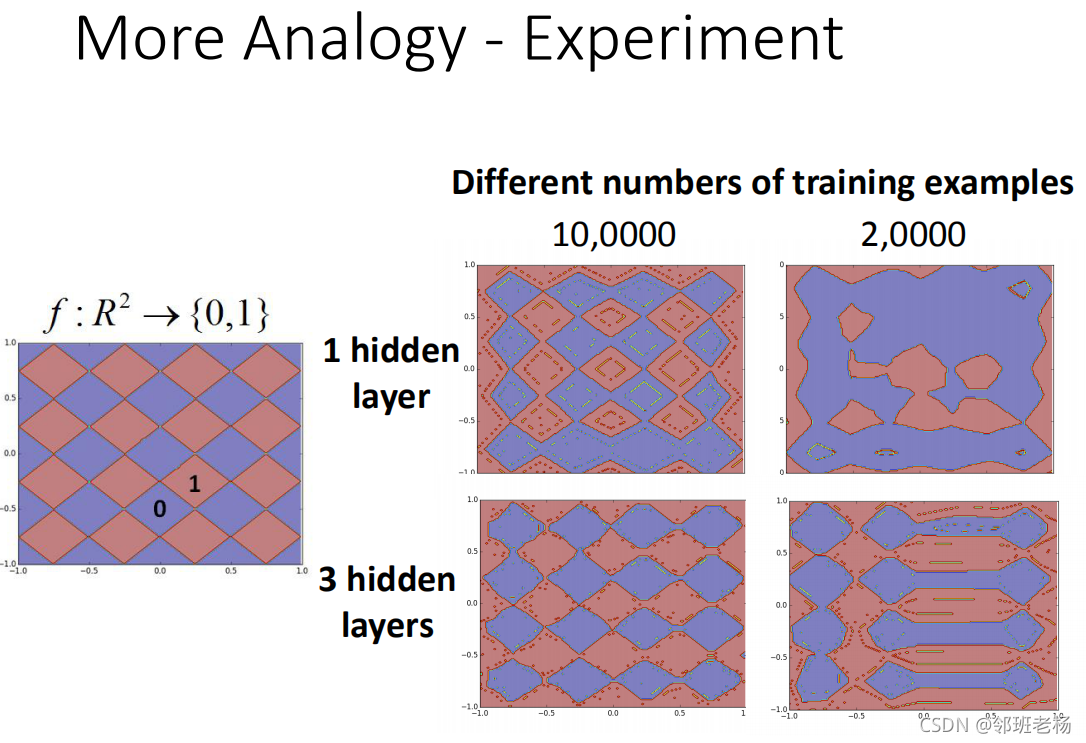
【例子3:使用二位坐标举例】
-
我们有一个function,它的input是二维 R 2 R^2 R2,它的output是{0,1}
-
1隐藏层和3隐藏层在10万笔data的时候,这两个neural表现类似,在20000笔数据时候,三层表现很好
-
说明数据少的时候,层数多分类效果更好
【例子4:图像识别】
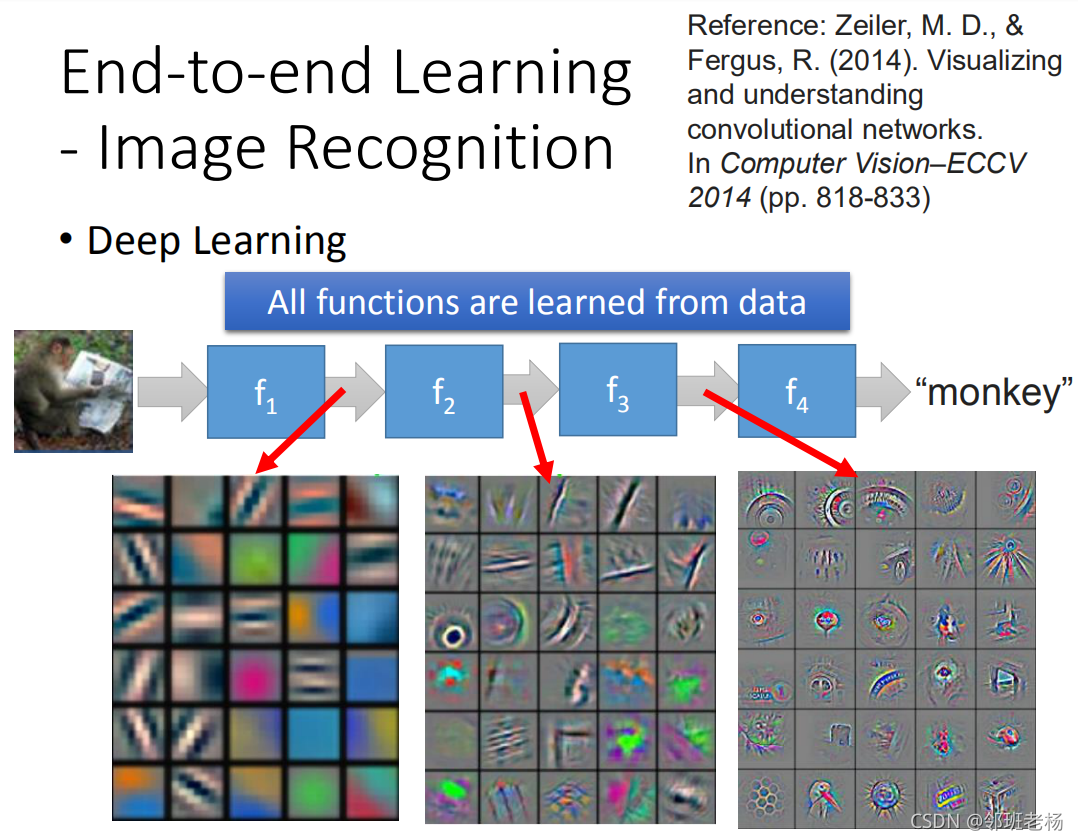
- 每一层取的特征不一样,有的颜色 有的形状,证明是深度学习是个个模块化过程