Concept Learners for Few-Shot Learning
? ? ? ? ����2021��˹̹����ѧ��ICLR�Ϸ�����һƪ���ġ�Concept Learners for Few-Shot Learning������������������֪�ĺ������� �ṹ���ġ������õĸ���,��ѧϰ���һ���µĶ���ʱ,�����Ѿ��߱���һЩ�ؼ�����,���Ը�����ǰѧϰ���ĸ��������Ͻ�������ѧϰ�����¶���������,������ѧϰʶ���µ���������ʱ,�����Ѿ��߱��˶�һЩ�ؼ��������ʶ,������ͺ���ë��Ȼ������רע����Щ�ض��ĸ���,���������������ѧϰһ���µ����֡������е�Ԫѧϰ����ȱ�����ֽṹ�������,�������������ֽṹ������֪ʱ,�������Ԫѧϰ�ķ��������� ��������֪�Ľṹ����ʽ������,���������һ��Ԫѧϰ��������COMET,�÷���������������ɽ��͵ĸ���ά��ѧϰ�µı�ʾ�����ģ�ͷ�������,���ܹ�ѧϰ�߲�����ṹ�������ռ��ӳ��,����Ч�ؽ�ϸ���ѧϰ�������
Background ���� Few shot learning
? ? ? ?���ܱ��ĵĹ���֮ǰ,������ϸ�Ľ���һ��ʲô��С����ѧϰ�Լ�ʲô��Ԫѧϰ�����Ⱦٸ�����˵��һ��ʲô��С����ѧϰ��������˷ֱ治�������ʹ�ɽ��,����ֻҪ��һ����ͼ��ߵ�����ͼƬ,�����˶���������ȷ���жϡ���Ȼ�����ܹ�������ȷ�ķ���,�Ǽ�����ܲ���������ȷ�ķ�����?Ҳ����˵������ݼ������ÿ����ֻ��һ��������,�������û�п�����������һ������ȷ������?
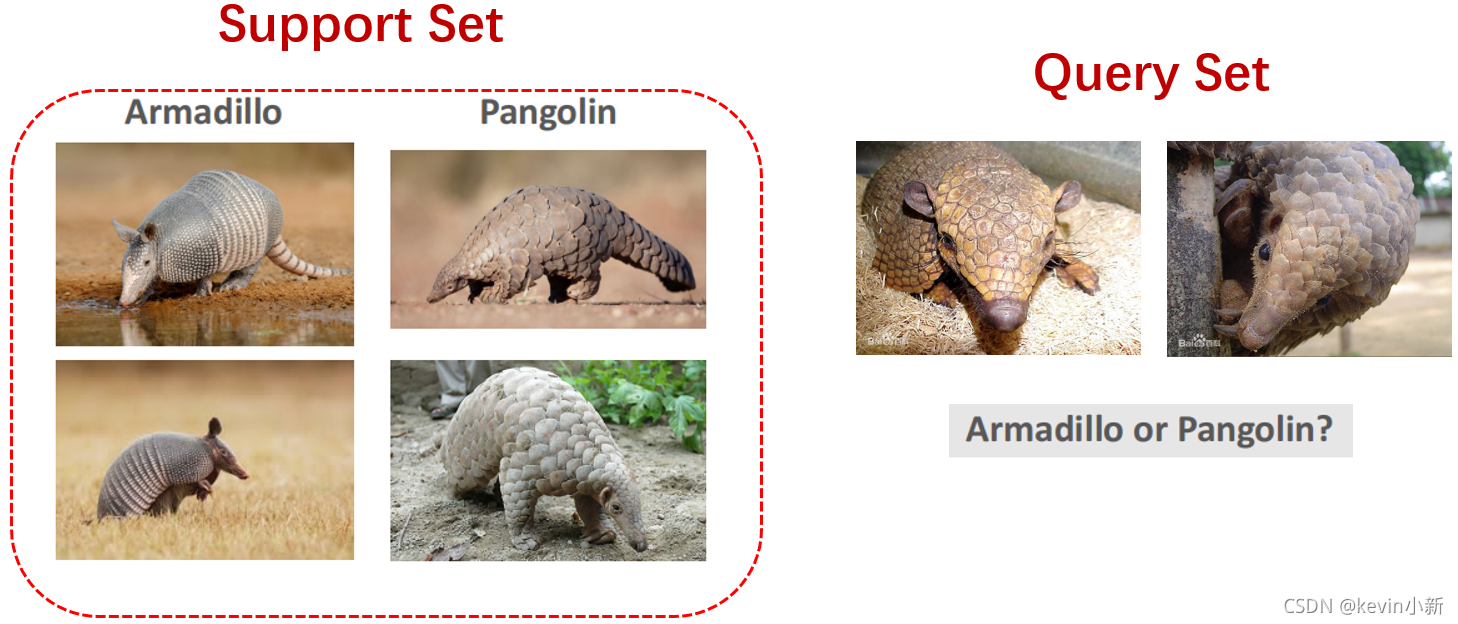
���������������
- few-shot: �Ӻ��ٵ�ͼƬ�г����һ���µĸ���,�������ǿ����ڿ���������è�ͳ���¹ͼƬ֮��(��������֮ǰ��֪�������ֶ��������),���ٷֱ����ͼƬ�е���è�ͳ���¹��
- zero-shot: �������Բ���ͼƬ�Ϳ���ѧϰ��һ���µĸ���,�������������������������
? ? ? ? �������ڵ����������ѧϰ������Ҫ������������ѵ��һ���õ�ģ�͡���ѵ������ÿ������������������ʱ,Ҳ������С���������,ʹ�ô�ͳ�ķ�ʽѵ����ģ�ͺ��������뵽�����������,Ŀǰ���С�������������������Ҫ���ǻ���Ԫѧϰ(meta-learning) �ġ����Խ������ҽ�����һ��ʲô��Ԫѧϰ(meta-learning)��
meta-learning
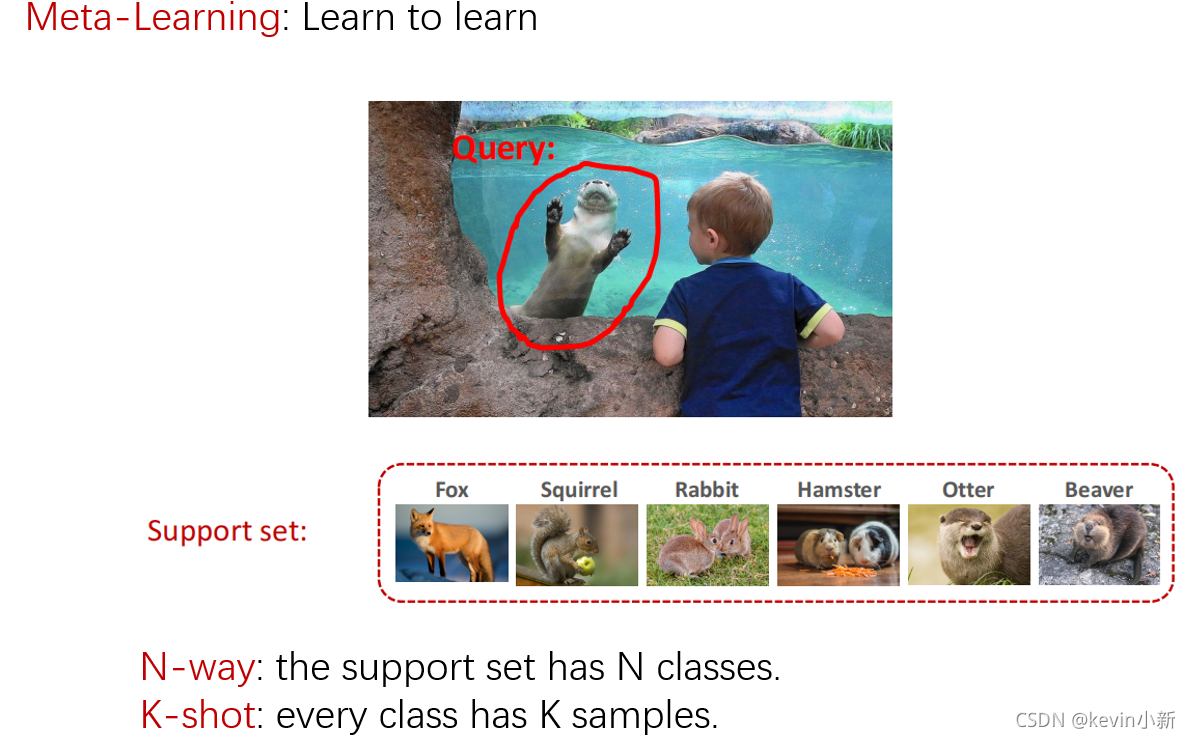
? ? ? ? ԪѧϰҲ��learn to learn,������ģ��ѧ��ѧϰ���ٸ�����,���С����ȥ����,С���ѿ���ˮ���и�ë���Ķ����ϲ��,������û�������ֶ���,��������֪�����ֶ����ʲô����ȻС���Ѵ���û�м������ֶ���,������ѧ����ô��������,��������ѧϰ�����������������һЩ��Ƭ,ÿ�ſ�Ƭ����һ�������ͼƬ�����֡�С���Ѽ�û�м�����Ƭ�ϵĶ���Ҳû�м�����ǰˮ����Ķ���,����С���Ѻܴ���,���ѿ�Ƭ��һ���֪��ˮ����Ķ�����ˮ̡�ˡ��������жϵ���������ǰˮ��Ķ���Ϳ�Ƭ�ϵ�ˮ̡���ú���ȥ����֮ǰС���Ѿ���������ѧϰ������,��֪����ô�ж�����֮�����ͬ������С��������ѧϰ���ֲ�ͬ�Ķ������meta-learning��С������Ȼû�м���ˮ̡,������ֻҪ�ѿ�Ƭ��һ���֪����ǰ�Ķ�����ˮ̡�ˡ���meta-learning��ˮ��δ֪�Ķ������query,��С���ѵĿ�Ƭ��support set�������������,��С����ѧ�����ֲ�ͬ�Ķ������meta-learning���ر�ĵ�֧�ּ�����N�����,ÿ��������K������,���dz����������ΪN-way K-shot����
Few-Shot learning �� ��ͳ�ලѧϰ������
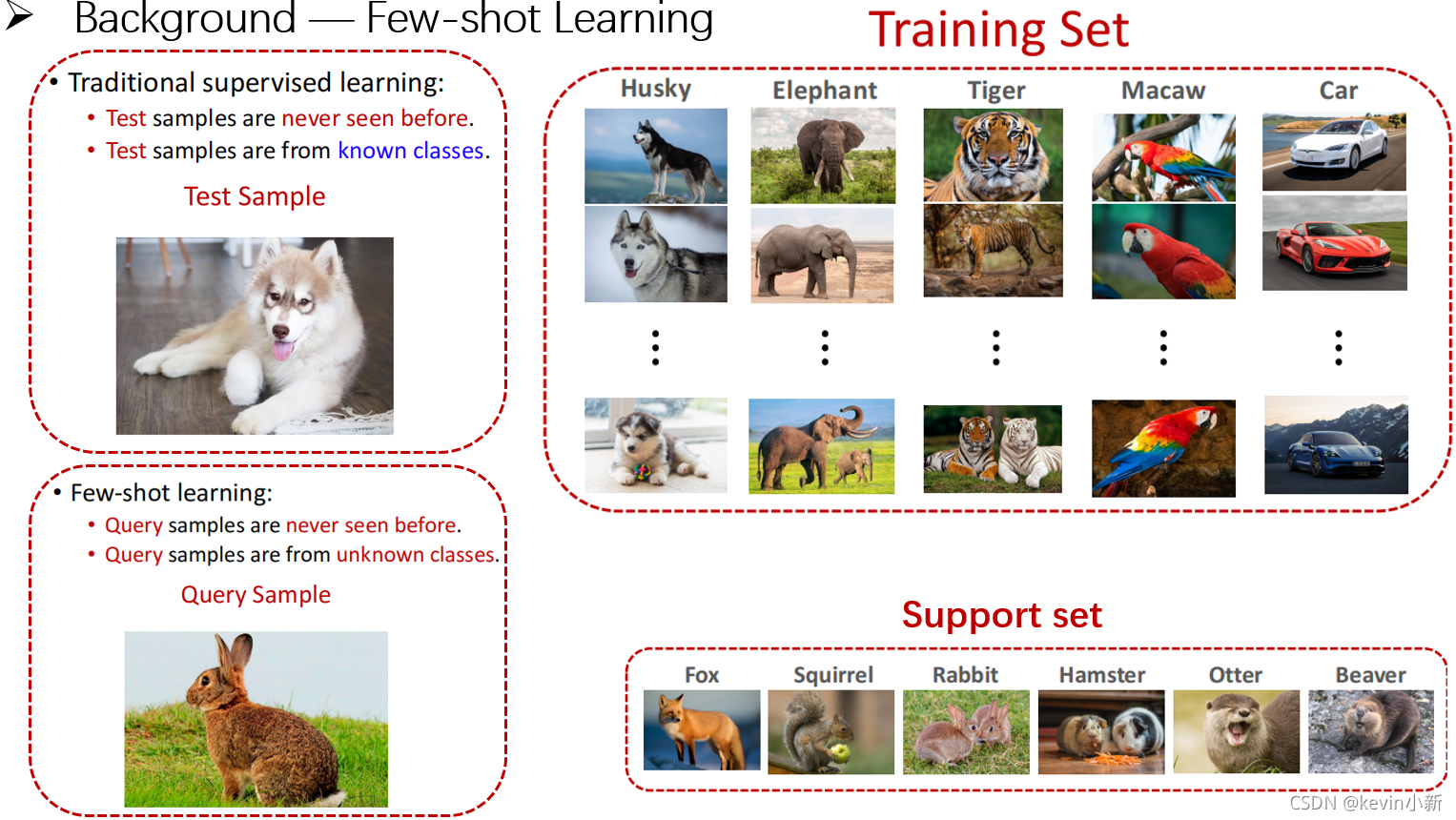
? ? ? ? ����������������ͳ�ලѧϰ��С����ѧϰ�����𡣴�ͳ�ලѧϰ��������,������һ��ѵ������ѧϰһ��ģ��,ģ��ѧϰ��֮�������ģ������Ԥ�⡣��ģ�Ϳ�������Ų���ͼƬ��ģ������Ԥ��,����ͼƬû�г�����ѵ������,ģ��û�м�������ͼƬ,���Dz���ͼƬ����������ѵ�����С�������������ǹ�ʿ��,ѵ���������й�ʿ����һ��,�����ϰ��ֹ�ʿ���ͼƬ����Ȼģ��û�������Ų���ͼƬ,����ģ�ͼ����ϰ��Ź�ʿ���ͼƬ,����ģ�Ϳ��Ժ������жϳ�����ͼƬΪ��ʿ�档
? ? ? ? С����ѧϰ��һ����ͬ������,ģ�Ͳ���û�м�������queryͼƬ,����û�м����κ�����,ѵ������û������������,�����С����ѧϰ�봫ͳ�ලѧϰ��Ҫ������������Ҫ��ģ���ṩ�������Ϣ,Ҳ����support set,ͨ���Ա�query��support set�а���������,ģ�Ϳ��Է���query�������ͼƬ���ƶ����,����ģ�;�֪��queryͼƬΪ�������
? ? ? ? Ҳ����˵���ڸ�����һ�������ݼ�,С����ѧϰ��Ŀ�IJ���Ϊ����ģ��ѧ��֪��ʲô�Ǵ���ʲô���ϻ�,��������ģ��ѧ��ʶ��û�����Ĵ�����ϻ�,С����ѧϰ��Ŀ����Ϊ����ģ��ѧ�������������ͬ,ѧ�����ֲ�ͬ�����Ҳ���Ǹ�����ͼƬ,������ģ��ʶ������ͼƬ��ʲô,������ģ��ʶ֪������ͼƬ����ͬ�����ﻹ�Dz�ͬ�����
? ? ? ? �봫ͳ�ļලѧϰ��ͬ,С����ѧϰ�����ݼ������������Ϊѵ�����Ͳ��Լ�,�ֱ����Ԫѵ����Ԫ���������Ρ�
? ? ? ? С����ѧϰ�����龰ʽ��Ԫѧϰ����,Ҳ������ѭѵ���Ͳ��Խ���ƥ���ԭ�������ڲ���ʱͨ��ʹ��ÿ������ٵ�����,������ѵ��ʱҲ����ÿ������к��ٵ���������ѵ����ѵ��������,ģ�ͻ�����ݼ��в������ܶ��в�ͬ���������ɵ�����,ÿ����������õ���֧ͬ�ּ��Ͳ�ѯ��,ģ�͵�Ŀ�����ͨ��֧�ּ���ѧϰѧ��ֱ��ѯ���е�������֧�ּ�����һ�������ơ�������������,ѵ�������а����˲�ͬ��������,ͨ�����ֻ���ѧϰ,ʹ��ģ��ѧ���˴Ӳ�ͬ���������ɵ���������ȡ���Բ���,���������������ͬ���Ƚ��������Ƶȡ�������Ԫ���Խ�������������ʱ,��ģ��Ҳ�ܽϺõؽ��з��ࡣ
Related Work ���� Prototypical Network
? ? ? ? ��֮ǰд������Prototypical Network���Ķ��ʼ�,���Բο���ƪ����:Prototypical Networks for Few-shot Learning�Ķ��ʼ�
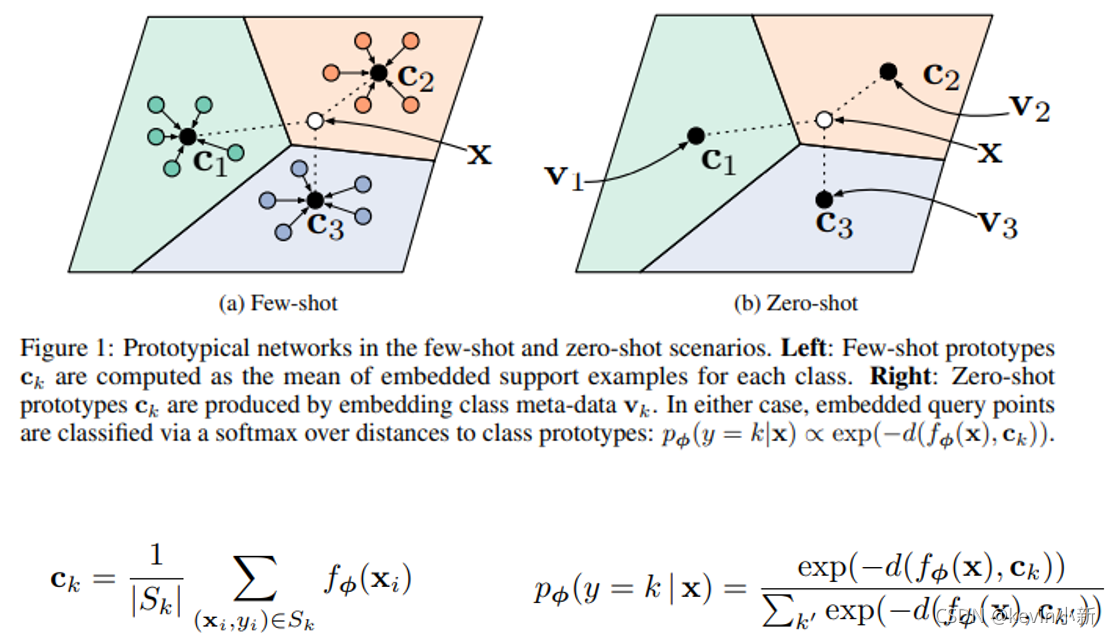
? ? ? ? ���ĵķ���������ÿ������ѧϰ����ѧϰһ��ԭ������ṹ,�����ͨ�����ɽ��з��ࡣ�������������˽�һ��ԭ�������ԭ����
? ? ? ? ԭ��������һ�ֻ��ڶ���ѧϰ��С���������㷨,�佫ÿ������֧�ּ���������ӳ�䵽һ��Ƕ��ռ���,������ȡ���ǵġ���ֵ������ʾÿ�����ԭ��(prototypical),ʹ��ŷ����þ�����Ϊ��������ı�,������ѯ������
x
q
x_q
xq?��ÿ����ԭ��
c
k
c_k
ck?֮��ľ���,�������з��ࡣ��ͼ��ʾ,����֧�ּ��е�ÿ������,ԭ������ͨ�������ض�Ƕ��ռ���֧�ּ������ľ�ֵ����ʾ�����,���ڲ�ѯ������,���Ǽ����������֧�ּ�ÿ�����ԭ�͵ľ���������з��ࡣ
Motivation
? ? ? ? ��������һ�±��ĵ��о�����,�����������Ϊʲô�ܹ�����ѧϰ��,����Ϊ�����������Կ����õĽṹ���������ѧϰ��,��ѧϰ���һ���µĶ���ʱ,�����Ѿ��߱���һЩ�ؼ�����,���Ը�����ǰѧϰ���ĸ��������Ͻ�������ѧϰ�����¶���������,������ѧϰʶ���µ���������ʱ,�����Ѿ��߱��˶�һЩ�ؼ��������ʶ,������ͺ���ë��Ȼ������רע����Щ�ض��ĸ���,���������������ѧϰһ���µ����֡������е�Ԫѧϰ����ȱ�����ֽṹ�������,�������������ֽṹ������֪ʱ,�������Ԫѧϰ�ķ���������
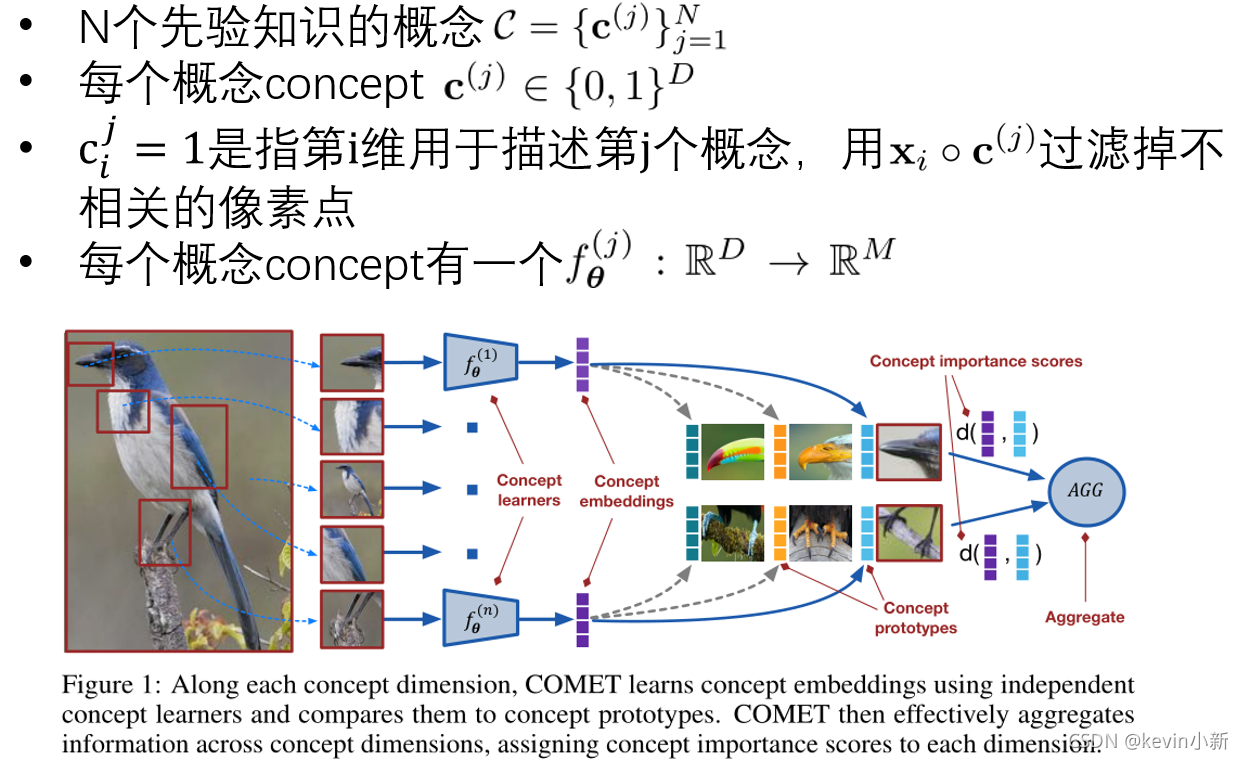
? ? ? ? ��������֪�Ľṹ����ʽ������,���������һ��Ԫѧϰ����,���ܹ���������ɽ��͵�ά�Ƚ���ѧϰ�������ؼ�����ʹ��COMET�������к�ǿ�ķ�������:(1)��ṹ����ʾѧϰ,(2)�ø���ԭ���������ض��ڸ���Ķ����ռ�,�Լ�(3)�Զ��ģ�͵ļ���,����˻���ѧϰ�ĸ�����������Щ�������������ȫ�ල�ķ�ʽ����,����ʹ���ⲿ֪ʶ��������,����������Щ�����������������ģ�Ϳ���ͨ������ֲ���ȫ�ָ�����Ҫ�Է�����ѧϰ��Щ�����е���Щ�Ӽ�����Ҫ�ġ�COMET�ǵ�һ���������صĿɽ���Ԫѧϰ������
? ? ? ? ��ͼ��ʾ,Ҳ����˵����ÿһ��ͼ��,���ǿ��Խ����Ϊ�������,ÿ�����������ѧϰǶ�뺯��,�����ͼƬ��ÿ���������ԭ��֮��ľ���,Ȼ�����и����ϵ���Ϣ�������з��ࡣ

Method
���Ŷ���
? ? ? ? ����˵��һ�·��Ŷ��塣ÿ�������к���N������֪ʶ�ĸ���
C
=
{
c
(
j
)
}
1
N
C=\left \{c^{(j)}\right \}_1^{N}
C={c(j)}1N?,
j
j
j��������ı�š�����ÿ������
c
(
j
)
��
{
0
,
1
}
D
c^{(j)} \in \left \{0, 1\right \}^{D}
c(j)��{0,1}D����һ��0��1��ɵĶ�Ԫ����,ά��DΪ����ͼ���ά��(����
3
��
64
��
64
3\times64\times64
3��64��64),����
c
i
j
=
1
c_i^{j}=1
cij?=1��ʾ��
i
i
iά���ڱ�ʾ��
j
j
j������,Ҳ����˵����һ��ͼ��,����
c
i
j
=
1
c_i^{j}=1
cij?=1�IJ��ִ����ø��������λ��,Ҳ�����൱��һ��ɸ��,���˵�����ص����ص㡣ÿ������
j
j
j����һ��������Ƕ�뺯��
f
��
(
j
)
f_\theta ^{(j)}
f��(j)?�Ը������������ȡ��
? ? ? ? ��ͼ�������COMET�ܹ�ͼ����ÿ������ά����,COMET��ʹ�ö����ĸ���ѧϰ����ѧϰ����Ƕ��,�����������ԭ�ͽ��бȽϡ�����Ƕ�뺯��
f
��
(
j
)
f_\theta ^{(j)}
f��(j)?��Ӧͼ1�е�concept learners,�������������������ķ����Ժ���������һ�����ݵ�
x
q
x_q
xq?,�������ĸ���Ƕ��,����������ÿ����ĸ���ԭ�͵ľ��롣Ȼ��,ͨ���Ը���Ƕ�����ԭ��֮��ľ���������ۺ����и����ϵ���Ϣ��
��ʽԭ��
? ? ? ? �����DZ��ĵļ��㹫ʽ,����ͨ����ʽ�����֧�ּ���ÿ�����
k
k
k�ĵ�
j
j
j������ԭ��
P
k
(
j
)
P_k^{(j)}
Pk(j)?����ԭ���������һ��ֻ����������Ǹ���,ԭ����������������ͼ��
x
i
��
c
(
j
)
x_i \odot c^{(j)}
xi?��c(j)��ʾ��λ���,Ҳ����ͨ��ɸ��
c
(
j
)
c^{(j)}
c(j)�õ�ÿ�����Ȼ�����ÿ����ѯ������
x
q
x_q
xq?,����ͨ���Բ�ѯ��ÿ������ԭ��j��֧�ּ����
k
k
k�ĸ���ԭ��
j
j
j֮��ľ���������,Ҳ���Ƿ��ӱ�ʾ����
x
q
x_q
xq?��֧�ּ����k�ľ���;Ȼ����ͨ��softmax����,���䵽֧�ּ���ÿ�����
k
k
k֮��ľ���ת��Ϊ���ʵ���ʽ,Ҳ���Ƕ��ڲ�ѯ������
x
q
x_q
xq?,
P
��
(
y
=
k
�O
x
q
)
P_\theta(y=k|x_q)
P��?(y=k�Oxq?)��ʾģ��Ԥ��
x
q
x_q
xq?Ϊ
k
k
k���һ������,Ȼ����ͨ����������ʧ����
L
��
=
?
l
o
g
P
��
(
y
=
k
�O
x
q
)
L_\theta=-log P_\theta (y=k|x_q)
L��?=?logP��?(y=k�Oxq?)���в������ݶȸ��¡�
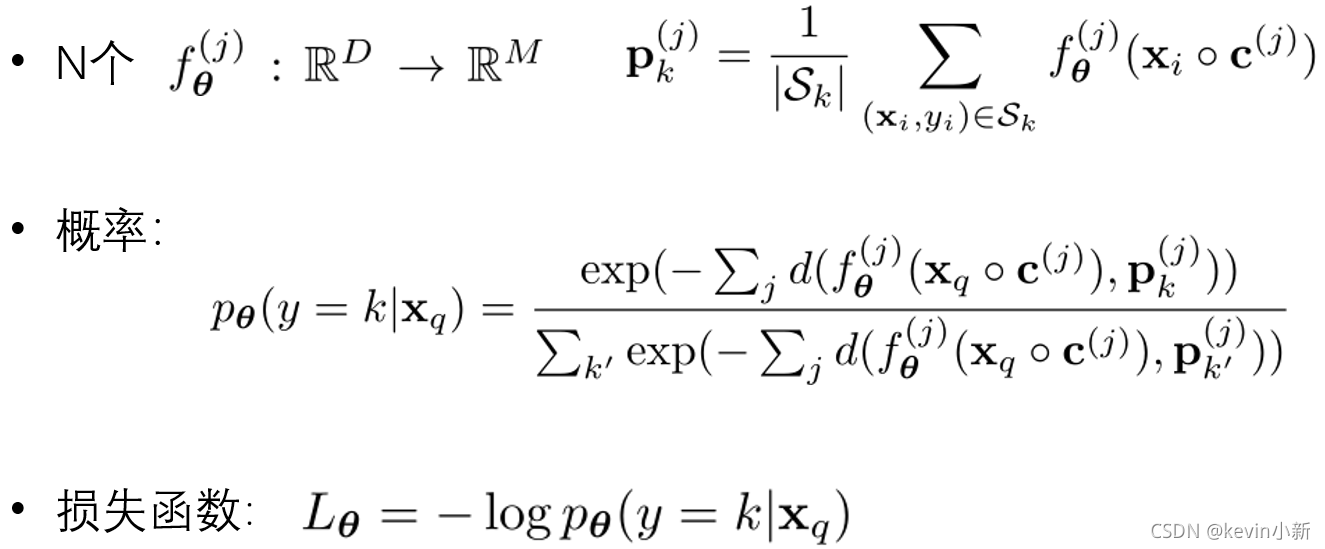
Experimental Results
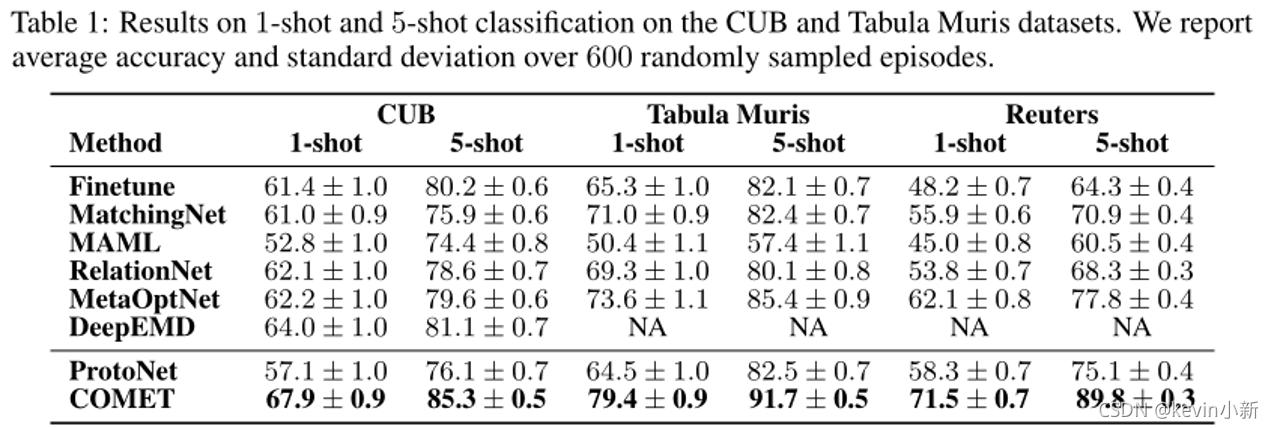
? ? ? ? ������������ȫ��ͬ������:������Ӿ�����Ȼ���Դ���������ѧ,������COMETģ�͵����ܡ�
? ? ? ? �ڼ�����Ӿ�����,����ʹ�õ���CUB���ݼ�,����ϸ���ȵ��������ݼ���
? ? ? ? ��NLP����,���߽�COMETӦ����������������ɵĻ��ı��������ݼ�Reuters��? ? ? ? ������ѧ����,����ʹ����һ��������ϸ�����ͷ�����������ݼ�Tabula Muris��
? ? ? ? ����CUB���ݼ�,���߸��ݻ��ڲ�����ע�Ͷ������,��������졢���β�͵ȡ�����Reuters���ݼ�,���߶�ÿ�����ʸ���wordNet��νṹ�е���λ�ʽ��и���Ķ��塣����Tabula Muris���ݼ�,����ʹ�û����嶨�����,����һ���ڲ�νṹ�ʻ�������������ܽ�ɫ����Դ��
? ? ? ? ��ʾ�˱��ķ����Ľ��,���Կ������ķ�������Խ�ԡ�
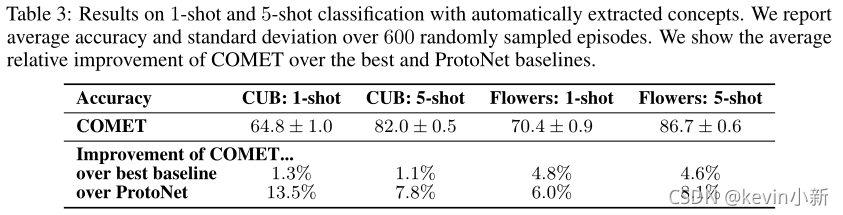
? ? ? ? Ϊ��֤��COMET������ȷʵ���Ը���ѧϰ�߶����Ƕ����Ȩ��,���߽�COMET��ԭ������ļ��ɽ��бȽ�,����һ������COMET�����и����й���Ȩ�ص����ܱ�2��������ÿ������ԭ��֮�乲������,ProtoNetEns��ʾʹ�ö��ԭ��������м���ѧϰ��

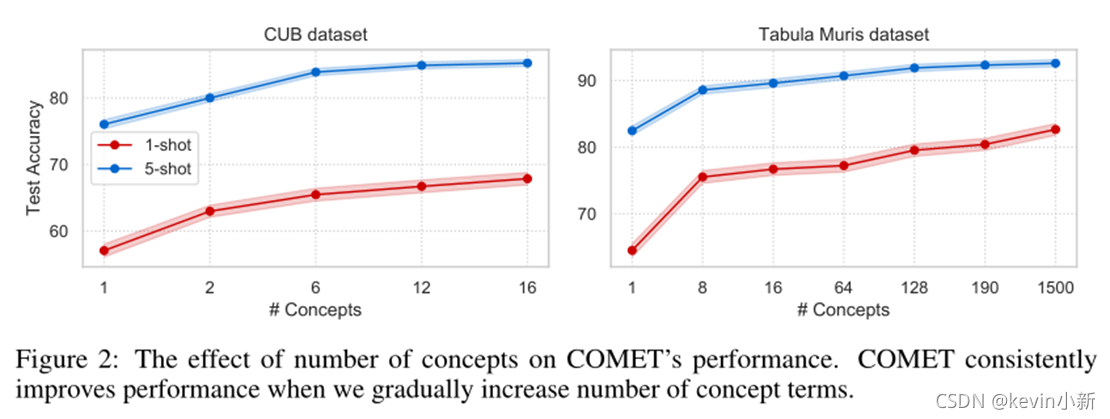
? ? ? ? ��ͼ��ʾ�˸�����������ģ��Ԥ��ȷ�ʵ�Ӱ��,����CUB���ݼ�,���߸�����ɼ���Ƶ�����Ӹ���,����Tabula Muris��,���ѡ��һЩ����������ӡ����Ÿ�������������,ģ�͵�ȷ��Ҳ�����ӡ�
? ? ? ? Ϊ��֤�����ĵķ����Դ����ص������³����,����ͨ��������������չ��1500��,�Ӷ��������������ϵ����ʹ�����������,COMET��ӵ��������õ�190���������,Ҳ�������˽������Щ�������,��ʹ�ڸ����������١��������Լ����������ص����������������,COMET������Ҳ������������
? ? ? ? Ϊ��֤�����ķ���COMET�ܹ���ȷʶ����Ҫ���༶����,������CUB���ݼ��Ͻ�����ʵ�顣Ҳ���Ǹ���һ��������,��������������ͬһ�������Ӧԭ����֮���ƽ������,ѡ��������������������ÿ������,COMET �����ҵ�����صĸ������,���족��ѡΪ����βС���ġ�����صĸ���,��βС�����������Բ�ε��������;���������������С�������ݺ��,�����ϻ����ƶ�����;��������ȷʵ������صġ�ǰ�,�����ɵ����λ��ͷ������֤ʵ��COMET��ȷʶ������Ҫ���༶���

? ? ? ? ��ͼ��ʹ�þֲ������ȫ�ָ���Ը�����ͼ����о��������һ��ʵ��,����һ���̶��ĸ���,Ӧ��COMET����ͼ��������ԭ�͵ľ����ͼ������������ǿ��Կ���,ʹ�þֲ�������Ժܺõر������ԭ��ͼ��,��ȷ�ķ�ӳ����صĸ����ʹ������ͼ����Ϊ�����������������ӳ����������,�����ṩֱ�۵Ľ��͡�

? ? ? ? COMET�ڽ�������֤�ĸ�����Ϊ�ⲿ֪ʶ�ṩ����ȡ���������ijɹ�,����Ҳ�о���COMET���Զ��ƶϸ�������������ʹ���Զ����ɸ���ķ����������顣��ͼ��ģ����CUB���ݼ������ɵ�30�����ʹ���Զ����ɵĸ����������,�����Ȼ�ȶԱȷ����Ľ����,��Ҳ��һ��֤���˱��ķ�������Ч�ԡ�

References
ԭ������
����github����
COMET | ����ѧϰʹ���������˵�˼ά��ʽ
����ѧ�߶���ƪ���ĵ���Ƶ���
few-shot learning��������
Prototypical Networks for Few-shot Learning�Ķ��ʼ�