本文总结深度学习方法在流量识别方面的应用,也是对前四篇文章的总结。
主要包括数据集,特征提取方法,深度学习网络,性能比较等几方面的介绍。
目录
一、概述
1. 异常检测的定义和方法
异常检测基于这样一个事实,即异常活动与正常系统活动明显不同,因此可以通过检查不同的统计信息来检测。网络入侵检测系统(N-IDS)是根据网络流量类型及其行为,对网络流量数据分类,判断它是恶意的还是良性的,以及进一步判断它属于哪种攻击类型的流量。
不同的异常以不同的方式出现在网络中,因此设计一个有效的异常检测系统需要从大量嘈杂,高维数据中提取相关信息,区分正常和异常的网络行为的一般模型是比较困难的。且基于模型的算法在应用程序中不可移植,网络流量的性质发生细微变化,模型也会不合适。因此,基于机器学习原理的非参数学习算法是可取的,因此它们可以学习正常测量的性质,并且能够自主的适应正常结构的变化。
2. 异常检测的意义
异常数据检测非常重要。因为数据中的异常转化为各种应用领域中重要(且通常至关重要)可操作的信息。例如,计算机网络中的异常流量模式可能意味着被黑客攻击的计算机正在向未经授权的目的地发送敏感数据。异常 MRI 图像可能表示存在恶性肿瘤。信用卡交易数据中的异常可能表明信用卡或身份盗窃或航天器传感器的异常读数可能表示航天器某些部件存在故障。
3. 网络流量数据分类方法
网络流量数据分类的主要方法有(1)误用检测;(2)异常检测;(3)状态完整协议分析。
误用检测也称为签名检测,根据预先定义的签名和过滤器,以有效的确定已知的入侵,但对于匿名入侵却无法检测,过度依赖于人为更新语料库。异常检测不是未知入侵的可靠检测方法,误报率高。市场上的大多数商业工具都是误用检测和异常检测的结合体。常用的强有力方法是状态完整协议分析,其使用软件供应商专有设计的功能来确定特定约定和应用程序的差异。
二、基于机器学习的网络流量数据分类
机器学习方法是目前用于IDS的突出方法。基于机器学习的网络流量数据分类大概可分为三种:聚类、传统机器学习分类方法和深度学习。
(1)聚类:无监督学习,如K-Means,FCM等;
(2)传统机器学习分类方法:半监督学习,如SVM,RF,GBT等;
(3)深度学习:监督学习,如DNN,CNN,RNN等;
1. 聚类
聚类的原理:聚类是一种不受监督的机器学习技术。聚类通过数据相似性对数据进行分类,这些相似性和通过距离函数(如欧几里得函数,切比雪夫函数)等来测量,好的集群应该有内部相似性和相互差异性。
聚类用于异常数据检测的技术,基于这样的假设:正数据实例属于大型且密集的聚类,异常数据不属于任何聚类或者属于小而独特的聚类。当某些聚类体大且密集,而另一些群集较小或稀疏时,可用于网络流量异常检测。小集群、稀疏区域和隔离点可能表示异常。
传统的聚类方法,例如K-means,每个数据只能属于一个簇。模糊聚类比硬聚类方法更加灵活,其允许一个数据项属于多个聚类,属于聚类的数量表示为一个模糊集。且它对于离群值检测非常实用,因为它考虑到了数据的性质,可以量化元素对簇的隶属度。
但聚类仅能识别基本攻击,无法识别复杂攻击和未知攻击。
研究意义在于,结合一些有效的特征提取和简化方法,并对FCM进行一些优化,如改变目标函数和距离函数,利用改进过的FCM进行聚类,达成对网络流量的识别。
2. 深度学习
传统的ML方法应用于IDS的有很多,如随机森林(RF),支持向量机(SVM),梯度下降树(GBT),贝叶斯网络(BN),Logistic回归等方法。
这些基于ML的传统的实时IDS解决方法并不是很有效,因为模型的输出呈高误报率,且在识别新入侵方法无效。主要原因是机器学习模型只学习TCP/IP包中简单特征的攻击模式。然而,新出现的深度学习取得了显著成果。
深度学习方法有两个基本特征:(1)能够全方位的学习TCP/IP数据包的复杂层次特征表示(CNN);(2)能够在大量TCP/IP数据包中记住过去的信息(RNN)。
例如CNN使用卷积核逐层提取复杂特征,所以它能自动学习高维网络流量的特征;RNN通过对序列数据建模,学习可变长度输入序列的隐藏的序列特征。
目前使用的方法有
(1)CNN+RNN:此处CNN使用一维卷积法Conv1D;
(2)直接使用ANN或者DNN或者RNN进行分类:输入层神经元个数即为特征个数;
研究意义在于,结合一些有效的特征提取和简化方法,对CNN和RNN的组合,以及一些新型的方法,例如DBN,搭建良好性能的网络结构,提高对网络流量识别的准确率。
三、数据集
首先,对数据集进行预处理,即将字符串属性转换为数字属性。
主要有KDDCup-99数据集、NSL-KDD数据集,以及最近推出的数据集,即UNSW-NB15。
1. KDDCup-99数据集
数据集由4GB压缩TCP转储数据组成,包括在网络流量收集的500万条连接记录。每个记录都包含从TCP连接数据中提取的41个特征。这些功能包括三个类别:单个TCP 连接的基本功能、连接中的内容功能以及使用两秒时间窗口的误差率功能。每个记录还包括一个标志,指示它是正常的还是入侵的。异常连接标记为模拟攻击类型。
KDD数据集异常类型被分为四大类39种攻击类型,其中22种攻击类型出现在训练集中,另有17种未知攻击类型出现在测试集中,以测试检测以前未知或变异的攻击模式的能力。
四种异常类型分别是:
(1)DOS, 拒绝服务攻击,例如ping-of-death, syn flood, smurf等;
(2)R2L, 来自远程主机的未授权访问,例如guessing password;
(3)U2R,未授权的本地超级用户特权访问,例如buffer overflow attacks;
(4)PROBING,端口监视或扫描,例如port-scan, ping-sweep等。

KDDCup-99 数据集已提供,其数据集以两种形式(1) 完整数据集;(2)10% 的完整数据集
| Attack Catefory | Data Instance--10% Data | |
| Train | Test | |
| Normal | 97,278 | 60,593 |
| Dos | 391,458 | 229,853 |
| Probe | 4,107 | 4,166 |
| R2L | 1,126 | 16,189 |
| U2R | 52 | 228 |
| Total | 494,021 | 311,029 |
对其数据特征进行一定的描述:
(1)TCP连接的基本特征(共9种,1-9):基本连接特征包含了一些连接的基本属性,如连续时间,协议类型,传送的字节数等;
(2)TCP连接的内容特征(共13种,10-22):对于U2R和R2L之类的攻击,由于它们不像DoS攻击那样在数据记录中具有频繁序列模式,而一般都是嵌入在数据包的数据负载里面,单一的数据包和正常连接没有什么区别。为了检测这类攻击,Wenke Lee等从数据内容里面抽取了部分可能反映入侵行为的内容特征,如登录失败的次数等;
(3)基于时间的网络流量统计特征(共9种,23-31):由于网络攻击事件在时间上有很强的关联性,因此统计出当前连接记录与之前一段时间内的连接记录之间存在的某些联系,可以更好的反映连接之间的关系。
(4)基于主机的网络流量统计特征(共10种,32-41)。
详细介绍:(61条消息) KDD CUP 99 数据集解析、挖掘与下载_Whitesad的博客-CSDN博客
2. NSL-KDD数据集
NSL-KDD数据集解决了KDD99数据集中存在的固有问题。NSL-KDD数据集由于缺少基于入侵检测网络的公共数据集,所以NSL-KDD数据集仍然存在一些问题,同时也不是现有真实网络的完美代表。但它仍然可以用作有效的基准数据集,以帮助研究人员比较不同的入侵检测方法。NSL-KDD训练集和测试集的设置是合理的,不同研究工作的评估结果将是一致的和可比的。
其改进是:
(1)NSL-KDD数据集的训练集中不包含冗余记录,所以分类器不会偏向更频繁的记录;
(2)NSL-KDD数据集的测试集中没有重复的记录,使得检测率更为准确。
(3)来自每个难度级别组的所选记录的数量与原始KDD数据集中的记录的百分比成反比。结果,不同机器学习方法的分类率在更宽的范围内变化,这使得对不同学习技术的准确评估更有效。
(4)训练和测试中的记录数量设置是合理的,这使得在整套实验上运行实验成本低廉而无需随机选择一小部分。因此,不同研究工作的评估结果将是一致的和可比较的。
| Attack Catefory | Data Instance--10% Data | |
| Train | Test | |
| Normal | 67,343 | 9,710 |
| Dos | 45,927 | 7,458 |
| Probe | 11,656 | 2,422 |
| R2L | 995 | 2,887 |
| U2R | 52 | 67 |
| Total | 125,973 | 22,544 |
| Data Instance--10% Data | ||||
| Attack Catefory | KDDCup-99 | NSL-KDD | ||
| Train | Test | Train | Test | |
| Normal | 97,278 | 60,593 | 67,343 | 9,710 |
| Dos | 391,458 | 229,853 | 45,927 | 7,458 |
| Probe | 4,107 | 4,166 | 11,656 | 2,422 |
| R2L | 1,126 | 16,189 | 995 | 2,887 |
| U2R | 52 | 228 | 52 | 67 |
| Total | 494,021 | 311,029 | 125,973 | 22,544 |
详细介绍:(61条消息) NSL-KDD数据集介绍与下载_Asia-Lee-CSDN博客_nsl-kdd
在文章:KDD99数据集与NSL-KDD数据集介绍 | 文艺数学君 (mathpretty.com)
中,提到作者提取了如下11个特征:
- 1. duration
- 2. protocol_type
- 3. service
- 5. src_bytes
- 6. dst_bytes
- 8. wrong_fragment
- 25. serror_rate
- 33. dst_host_srv_count
- 35. dst_host_diff_srv_rate
- 36. dst_host_same_src_port_rate
- 40. dst_host_rerror_rate
3. UNSW-NB15数据集
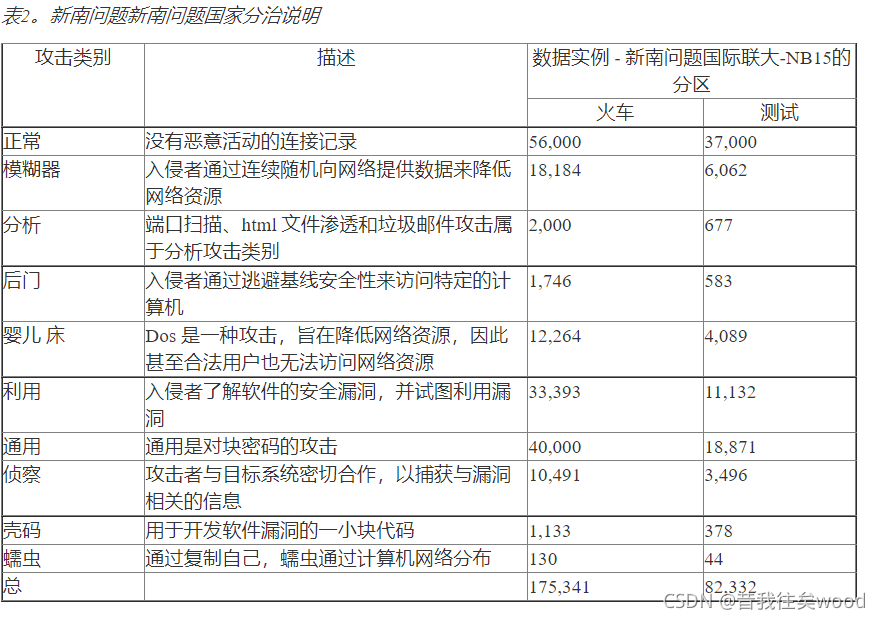
UNSW-NB15数据集被认为是评价现有和新型IDS方法的可靠数据集。该数据集有254w条记录,49个特征,其中有9种常见攻击。正常信息占数据集大小88%,攻击信息12%。
数据集以两种形式公开提供(1) 完整数据集;(2) 完整数据集的一小部分。一小组数据集有 175,341 条train记录和 82,332 条test记录。
| ID | Type | Count | Train(drop_duplicates) | Test(drop_duplicates) |
|---|---|---|---|---|
| 0 | Normal | 93000 | 56000(51890) | 37000(34206) |
| 1 | Generic | 58871 | 40000(4181) | 18871(3657) |
| 2 | Exploits | 44525 | 33393(19844) | 11132(7609) |
| 3 | Fuzzers | 24246 | 18184(16150) | 6062(4838) |
| 4 | DoS | 16353 | 12264(3806) | 4089(1718) |
| 5 | Reconnaissance | 13987 | 10491(7522) | 3496(2703) |
| 6 | Analysis | 2677 | 2000(1594) | 677(446) |
| 7 | Backdoor | 2329 | 1746(1535) | 583(346) |
| 8 | Shellcode | 1511 | 1133(1091) | 378(378) |
| 9 | Worms | 174 | 130(127) | 44(44) |
| Total | 257673 | 175341 | 82332 |
详见1:UNSW-NB15数据集介绍 | 文艺数学君 (mathpretty.com)
详见2:UNSW-NB15数据集分析 | Ashin Wang's Blog
4. CICIDS2017数据集
对自1998年以来现有的11个数据集的评估表明,大多数数据集(比如经典的KDDCUP99,NSLKDD等)已经过时且不可靠。其中一些数据集缺乏流量多样性和容量,一些数据集没有涵盖各种已知的攻击,而另一些数据集将数据包有效载荷数据匿名化,这不能反映当前的趋势。有些还缺少特征集和元数据。
CIC-IDS-2017 数据集包含良性和最新的常见攻击,类似真实世界数据(PCAPs)。
CICIDS2017数据集提取了八十多个特征,包含14种类型的攻击。包含227w条正常信息(占80%)和55w条攻击信息记录(占20%)。
详见:CIC-IDS2017数据集特征介绍 | 蓝亚之舟 (lanyazhizhou.com)
四、特征选择和简化方法
通常来说,数据集中许多维度(特征)在生成模型时没用,为了减少算法复杂性,缩小尺寸很重要。当特征的原始单位和意义很重要且,建模目标时识别有影响的子集时,特征选择优于特征转换。当存在绝对特征,且特征转换不恰当时,特征选择称为减少尺寸的重要手段。
1. 信息增益IG
信息增益来源于信息熵,信息增益可以认为这个特性带给整个系统的信息量,反应这个特征的重要程度。IG(X,Z)=H(X)?H(X|Z),观察到事件X对于我们预知Z提供了多少信息。
在使用ANN和RNN分类时,从NSL-KDD数据集41个特征中提取了14个,使用简化特征的数据集进行对ANN和RNN的训练;
2. 非负矩阵分解(NMF)
基本思想:给定一个非负矩阵V,NMF能够找到一个非负矩阵W和一个非负矩阵H,使得矩阵W和H的乘积近似等于矩阵V中的值。其中W为基础矩阵,相当于从原矩阵V中抽取出来的特征。H为系数矩阵。优化目标为二者之间的差距,如距离函数等。
在基于NSL-KDD的GMM模型中,该网络具有基于NMF的15个特征(原为41个)特征。
3. 主成分分析(PCA)
主成分分析使用正交变换将一组可能相关变量的观测值转换为一组称为主成分的线性不相关变量值。每个主成分都是原始变量的线性组合。所有主成分相互正交,因此没有冗余信息。主成分的数量小于或等于原始变量的数量。
Shisrut等人使用NSL-KDD数据集比较经典ML方法与集成无监督特征学习和深度神经网络的性能,建立了一个深度神经网络(DNN)的模型。该网络具有基于主成分分析(PCA)的15个特征;
4. 遗传算法(GA)维度降低技术
采用遗传算法“适者生存”的思想。将每个特征视为染色体,经过交叉,变异,选出最优的特征。
基于KDDCup1999数据集,利用GA算法将41个特征减少到了8个,结合改进的FCM方法,对KDD数据集的数据进行5和26分类。
5. 信息增益(IG)、晶粒比(GR)和相关属性(CA)
特征简化方法,同样是在在使用ANN和RNN分类时,消除了NSL-KDD数据集12个特征,最后剩下29个特征,输入层29个神经元,