又在网络上搜罗了半天,凑了几个决策树的例子。原理的部分呢,大致就是有几种算法:首先是ID3算法,基于信息熵的原理,根据某个属性如果能够最为迅速的将所有的样本进行分类,那么这个属性将成为决策树的首选节点,然后仍然根据熵值继续向下选择其他属性作为分类节点。但ID3算法有个很明显的弊端,就是如果一个属性的值有很多个,则这个属性被选出来的概率则最高(即偏好有更多值的属性),这个属性在某些情况下就是一个鸡肋属性,比如生日,身份证号等,很显然不同的人有不同的出生日期,根据生日确实可以很快将样本进行划分类别,但这个生日对于我们进行判断分类其实并没有什么意义。为了避免出现这样的尴尬,于是C4.5就应运而生了,不再是根据熵值来进行选择,而是根据信息增益率,也就是比率来进行选择。CART树则是使用Gini系数来进行计算判断,同时能避免ID3,C4.5处理不了连续值的尴尬。为了提升分类准确率,又整出一个随机森林的算法,说白了就是如果一棵树分的不准确的话(样本在进行抽样时总是有可能出现抽偏的可能),那我们就多搞它几棵树,多抽几次样,弄个森林来进行进行处理。当然啊,这只是我自己小小的理解,不对的话,可以留言探讨。
这篇文章的目的并不是搞那么高深的理论,只是让大家能上手决策树的实现,所以就不罗嗦了,直接上案例开始动手。第一个案例我会说得很详细,后面两个我就不罗嗦了,过程都是一样的,贴个结果图算了。
案例1:挑瓜
大家都会挑西瓜吧(尽管我还是不太会,跟着数据瞎咧咧了),西瓜有如下一些特征:色泽、根蒂、敲声、纹理、脐部、触感,根据这些特征可以对瓜进行一定的判断是否是一个好瓜(熟了)。数据链接在此(3个案例数据)
首先导入数据,查看一下:
dt=pd.read_excel(r'决策树数据.xlsx',sheet_name='挑瓜')
dt.head(2)
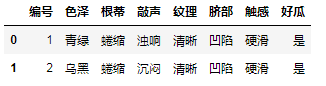
显然,编号这个属性是我们进行判断时不需要的,色泽、根蒂……触感这些都是所谓的特征数据,而好瓜则是类别数据,我们需要把这两部分分开,同时还需要解决另一个问题,就是这些数据都是中文的,不能直接拿去进行计算,所以还需要进行一些转换。
#去掉编号列,同时将好瓜这一列名改为是否,这样生成的图里更容易看明白
dt.rename(columns={'好瓜':'是否'},inplace=True)
dt1=dt.iloc[:,1:]
#定义一个数据转换的函数,将中文数据转换为数值
def convert(dt):
if dt in ['青绿','蜷缩','浊响','清晰','凹陷','硬滑','是']:
return 1
elif dt in ['乌黑','稍蜷', '沉闷', '稍糊', '稍凹', '软粘','否']:
return 2
elif dt in ['浅白', '硬挺', '清脆', '模糊', '平坦']:
return 3
dt1=dt1.applymap(convert)
dt1
整理后得到的数据如下:
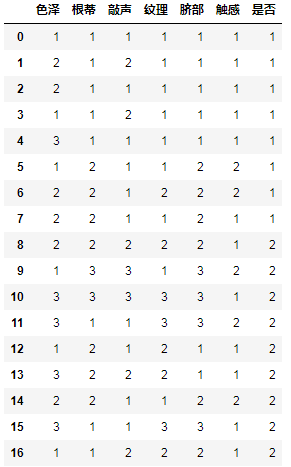
接着将数据划分为特征数据和类别数据两个部分:
import numpy as np
labels=np.array(dt1['是否'])#特征数据
data=np.array(dt1.iloc[:,:-1])#类别数据
开始构建决策树:
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion = 'entropy')#参数criterion = 'entropy'为基于信息熵,‘gini’为基于基尼指数
clf.fit(data, labels)#训练模型
用第1种方式来绘制决策树(不建议用这种)
with open("tree.dot", 'w') as f:#将构建好的决策树保存到tree.dot文件中
f = tree.export_graphviz(clf,feature_names = np.array(dt1.columns[:-1]), out_file = f)
然后在prompt窗口下输入命令
dot -Tpng tree.dot -o tree.png
确实得到了一棵树,不过样子奇难看,也根本看不清属性是啥
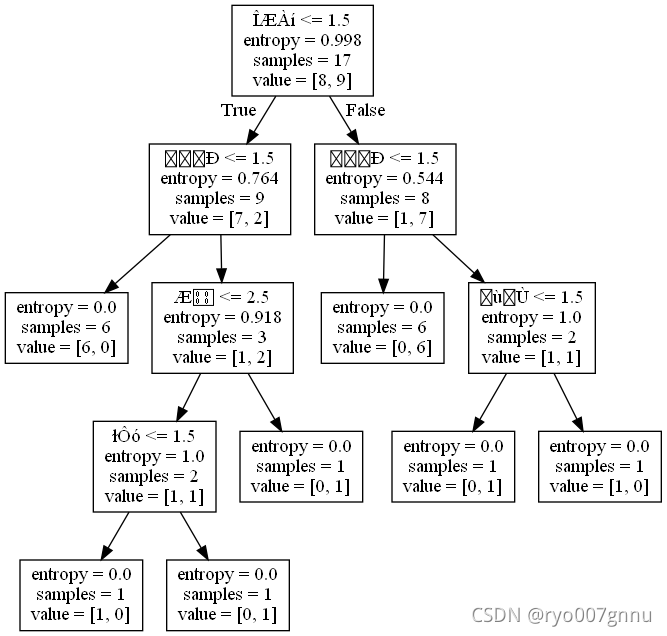
于是换第2种方式:(需要先安装graphviz)
import graphviz
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=dt1.columns[:-1].values,
class_names=dt1.columns[-1],
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph
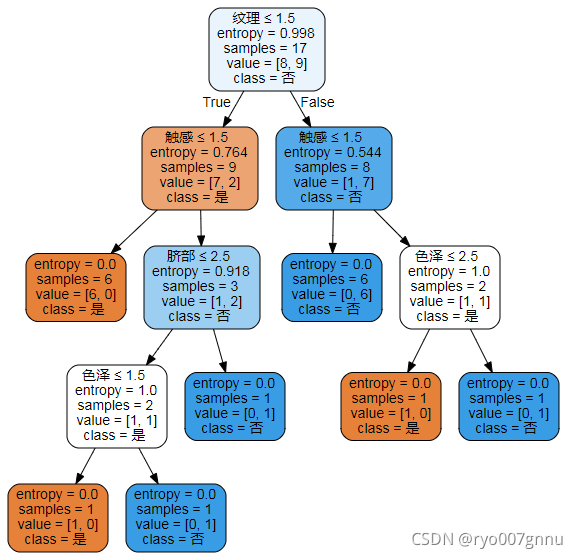
这回这个就好看多了。
听说还有个更牛X的包叫dtreeviz(也需要先安装),本着试试不花钱的态度,也做了一遍,可貌似总解决不了中文无法显示的问题(其实是我懒得去折腾,不是传统的那种显示不了中文的问题,英文则一点问题没有),代码先放在这里,有兴趣的可以试试:
from dtreeviz.trees import dtreeviz
viz = dtreeviz(clf,x_data=data,y_data=labels,
target_name='class',feature_names=dt1.columns[:-1].values,
class_names=list(dt1.columns[-1]),
title="Decision Tree-挑瓜")
viz
决策树的用途就是用于进行分类,既然有了决策树,我们随便构建一个样本,预测一下看看它会被分到哪个类别里去吧?
t=['乌黑','蜷缩','清脆','模糊','平坦','硬滑']
t=pd.DataFrame(t).T.applymap(convert)
clf.predict(t)
结果为:
array([2], dtype=int64),按我这里的话,就是否的这一类了。
如果把纹理改为清晰呢?
t=['乌黑','蜷缩','清脆','清晰','平坦','硬滑']
t=pd.DataFrame(t).T.applymap(convert)
clf.predict(t)
结果成了:array([1], dtype=int64),就是个好瓜了。
案例2:网上写烂了的打网球的案例。
这个案例主要是根据天气、温度、湿度等因素判断是否该去打网球,过程基本和前面的一样,我就不再赘述了,直接给个结果图吧,主要是前面的第2、3种方法画的。
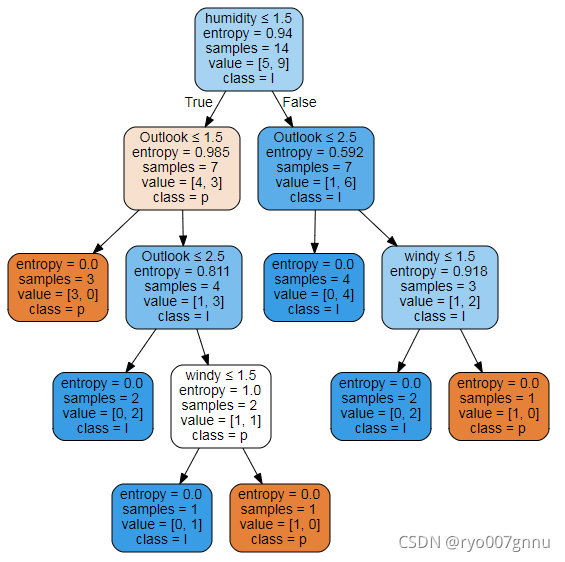
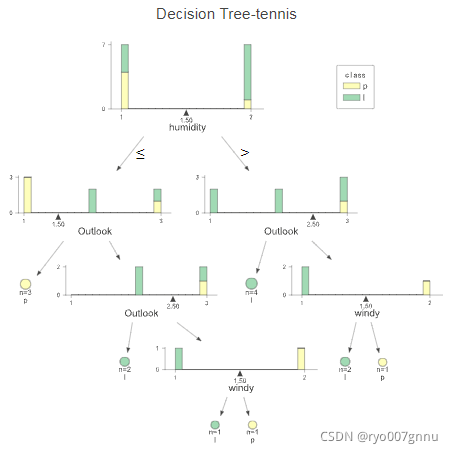
其实看看这俩图,可能本人审美不足,也没感觉出后面这个图帅在哪里。
案例3:销售决策
这个例子呢,我就不知道具体是什么产品了,反正先当成衣服吧,主要有性别、类型和尺码三个特征属性,然后是一个产品类型的类别属性。主要是判断当给定特征属性时的某个用户,应该给他(她)推荐哪类产品。
过程也不赘述了,直接上棵树,看看能不能做出和我一样的效果?
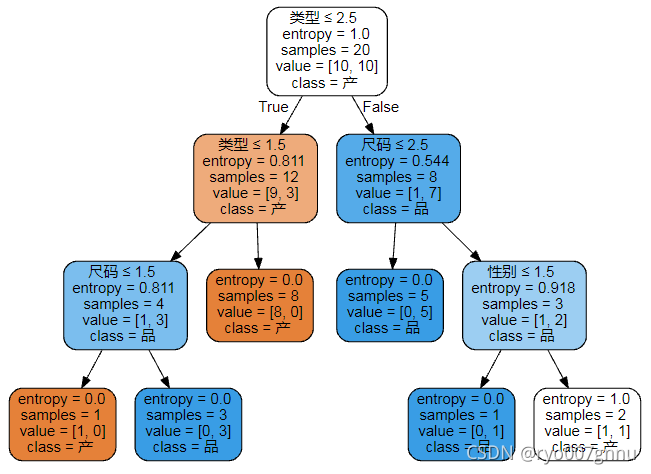
这个地方偷了个懒,没有将类别属性的名称修改一下,所以如果是‘产’,就认为是C0,如果是‘品’就认为是C1吧。