目录
一、数据处理
1.1数据进行可视化
import numpy as np # 用来做数学运算
import pandas as pd # 用来处理数据表
import seaborn as sns # 用来画高级统计图
import matplotlib.pyplot as plt # 用来画图
from sklearn.model_selection import train_test_split # 做交叉验证,划分训练集和测试集
from sklearn.tree import DecisionTreeClassifier # 用决策树来分类
iris_data = pd.read_csv('iris.csv', na_values=['NA']) # 从名为iris_data的csv文件读数据存成数据表
#第二个参数用来把 csv 里面空白处用 NaN 代替
iris_data.head(5).append(iris_data.tail()) # 展示数据表前5个和后5个数据
#print(iris_data.dropna())
iris_data.describe()
#检查四列数据的个数,平均数,标准差,最小值,最大值和25,50,75的百分位数
sns.pairplot(iris_data.dropna(),hue="class") # 画散点矩阵图
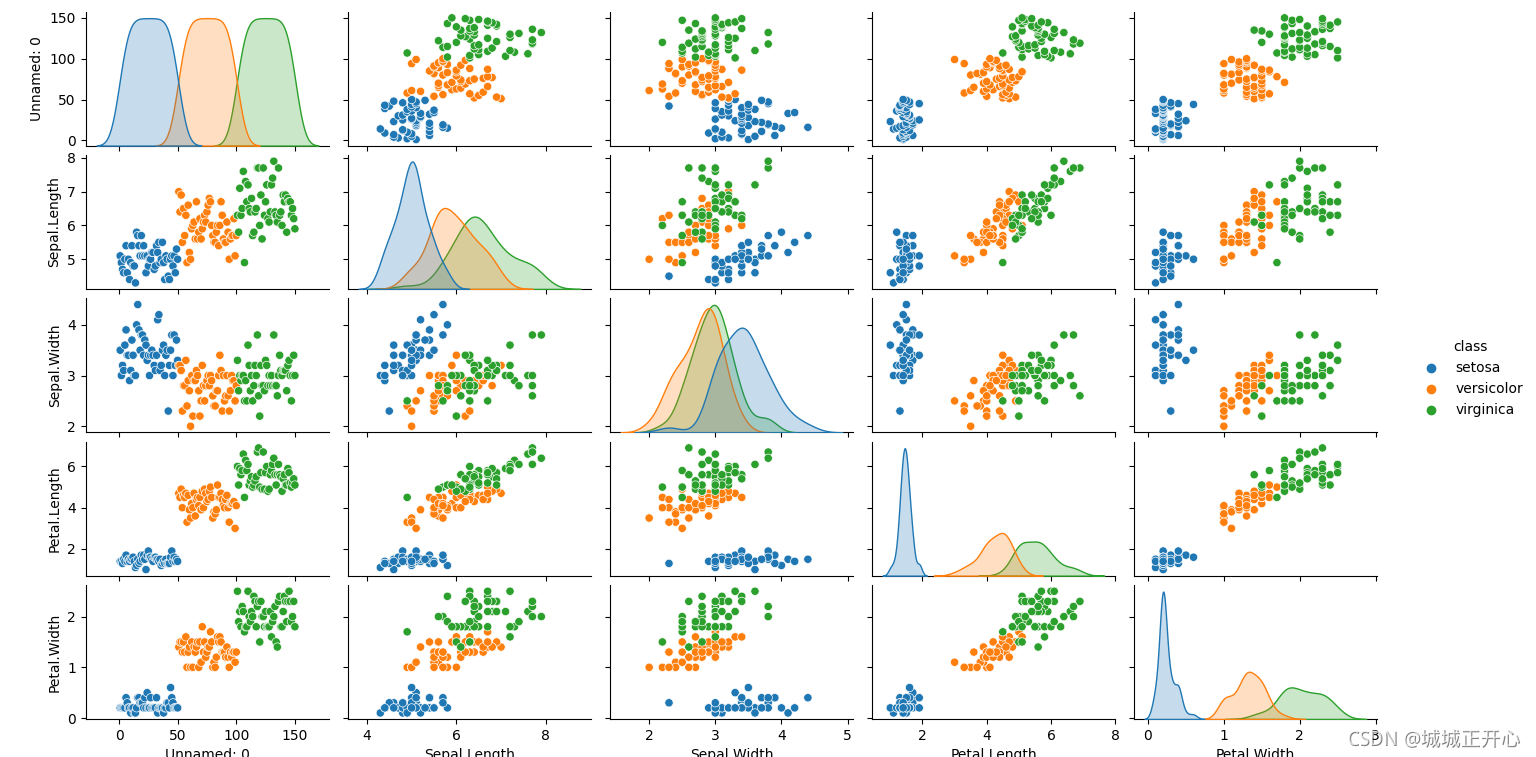
1.2检查,清理数据
处理异常值,观察数据,可以看到有个别数据突出
# 去掉 Iris-setosa 里萼片宽度大于2.5厘米的数据,然后画出其条形图
iris_data = iris_data.loc[(iris_data['class'] != 'setosa') | (iris_data['sepal_width_cm'] >= 2.5)]
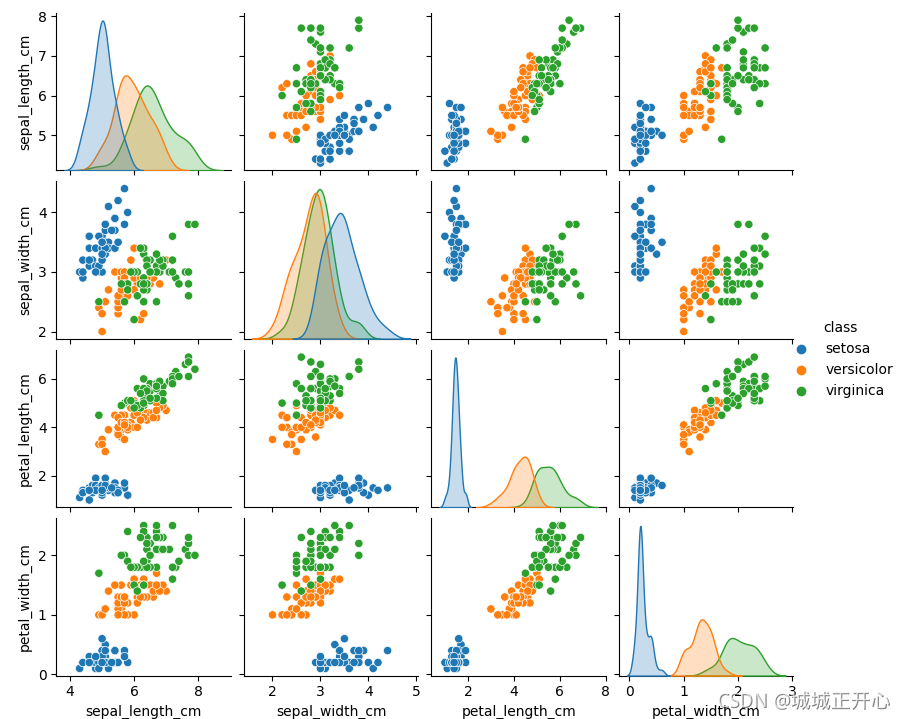
二、用scikit-learn来预测数据
2.1选出特征(输入变量)和标记(输出变量)
# 读数据
iris_data_clean = pd.read_csv('iris-data-clean.csv')
# 选出特征
all_inputs = iris_data_clean[['sepal_length_cm', 'sepal_width_cm',
'petal_length_cm', 'petal_width_cm']].values
# 选出标记
all_classes = iris_data_clean['class'].values
2.2划分训练集和数据集
#划分数据集和测试集
(training_inputs, test_inputs, training_classes, test_classes) = train_test_split(all_inputs, all_classes, train_size=0.75, random_state=1)
2.3利用决策树模型进行学习
# 创建决策树分类器
decision_tree_classifier = DecisionTreeClassifier()
# 训练数据
decision_tree_classifier.fit(training_inputs, training_classes)
# 分类精度
print(decision_tree_classifier.score(test_inputs, test_classes))
plt.show()
2.4结果
