基础模型
如果想输入一段法语句子,翻译成一段英语句子如下。

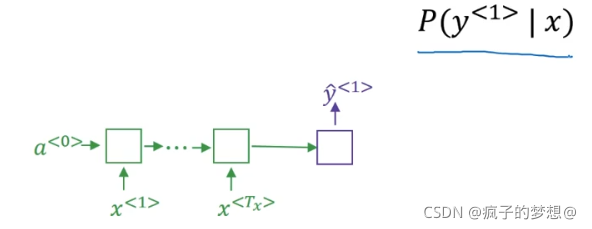
机器翻译模型如下,绿色表示编码网络,紫色表示解码网络。

我们看到解码网络和基本的语言模型相似。语言模型如下
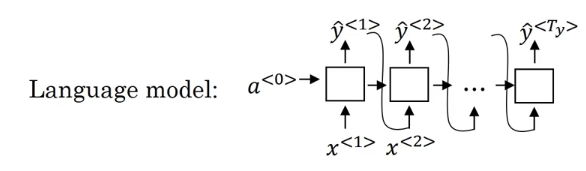
不同的是,机器翻译会计算输入句子的向量,而语言模型通常是以零向量开始。当使用翻译模型时,要找到输出中,概率最高的那个句子。比如预测输出会出现以下多种情况,所以我们并不是在输出结果中随机取一个y值,而是取概率最大化的。

贪心搜索
贪心搜索是对机器翻译的输出,每一个时间步输出一个预测单词时,取最大概率的那个,直到所有单词预测完毕。最后连成的句子或许就是最大概率贴近原始句子的翻译。即调出单个单词的最大概率,使得整体句子的概率最大化。但并不是最优的一个解决方法。
集束搜索算法
不仅仅是机器翻译,语音识别,我们也需要使得输出中找到一个最大概率贴近原意的。集束搜索算法是一个解决方案。
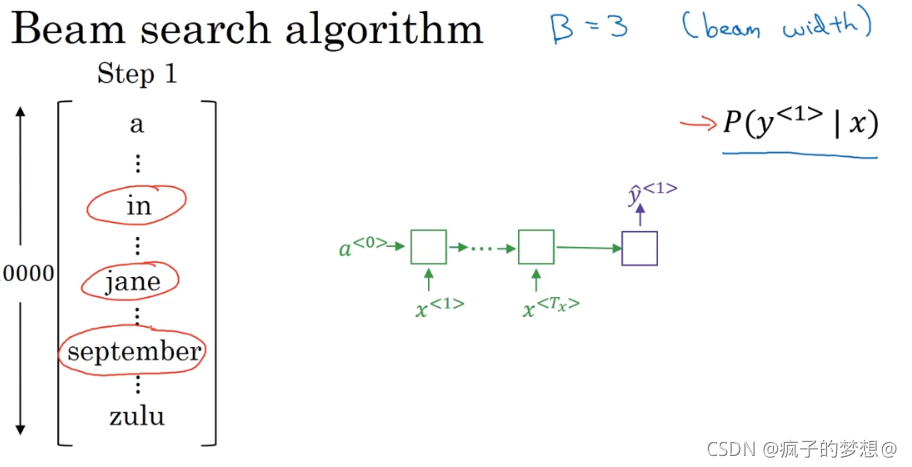
集束搜索算法首先要做的是挑选要输出的英语翻译中的第一个单词,这里列出了10000词的词汇表。
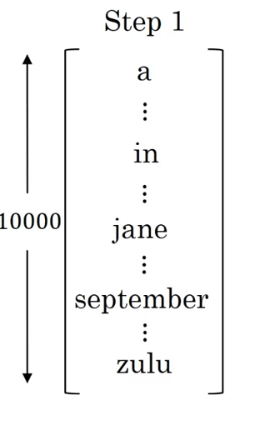
给定一个法语输入,第一个预测输出y的概率值是多少,贪婪算法只会挑出最可能的那一个词,然后继续,集束搜索则会考虑多个选择,会有一个参数叫B(集束宽),B=3意味着集束搜索会一次考虑三个单词。
比如B=3时,第一个预测输出,in、jane、september有较大概率,那么便会存储到计算机内存里,便于后续尝试用这三个词。
那么接下来第二步,集束搜索会针对每一个单词,找到第二个单词应该选什么。比如针对第一个单词为in时,进行第二个单词的预测输出,第二个预测输出是根据给定的输入x和第一个单词是in的概率下进行输出。最后用第一个预测输出为in的概率,乘以第二个预测输出的概率作为输出1和输出2形成单词对的概率。
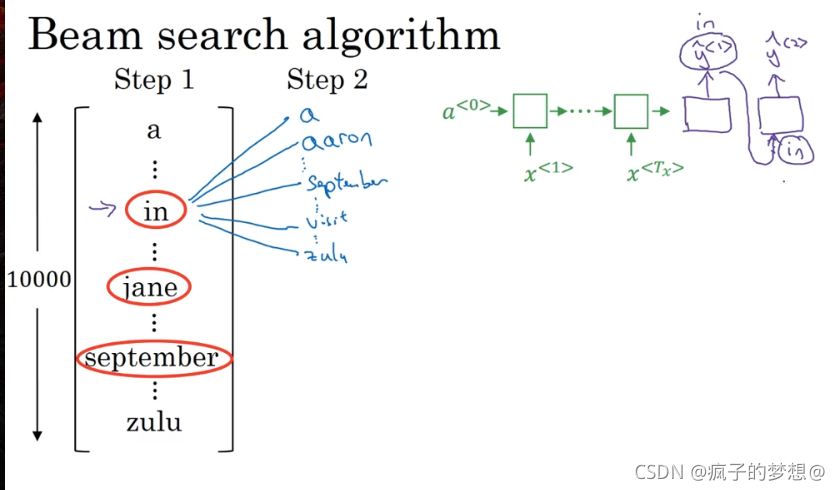
随后在对jane进行同样的操作。
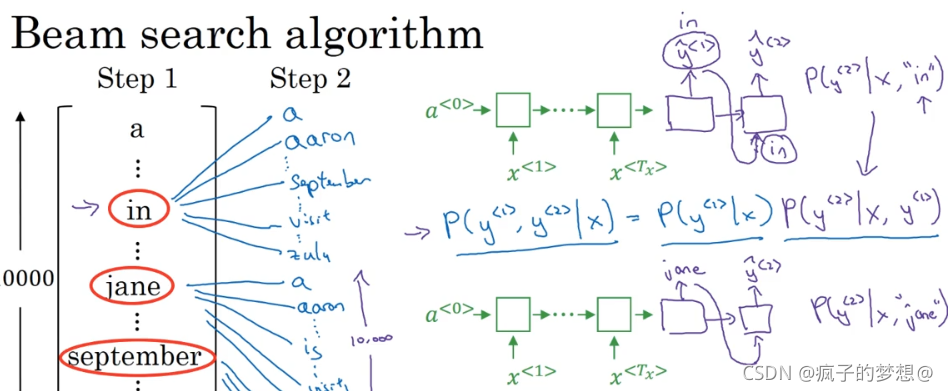
因为B设置为3,词汇表设置为10000,那么最终对这三个词汇,会产生30000个不同概率的输出,集束搜索的第二步就是从这里边找出3个最可能的存入计算机内容。随后继续进行第三个单词的预测输出,不断循环往复,最后输出结束。如果B=1,实际就变成了贪婪算法。
注意:实践中,我们不会直接使用每个预测输出相乘后的概率存入计算机,这会造成数值下溢,我们使用一个log对数计算和,然后的进行存储,而不是概率的乘积。
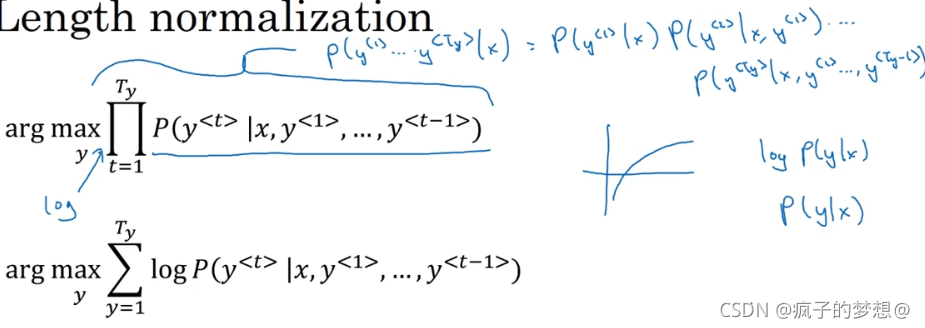
注意力模型
举下边一个例子,我们输入是一段法语,绿色部分表示读取,并记忆这段法语,随后紫色解码部分进行预测输出。
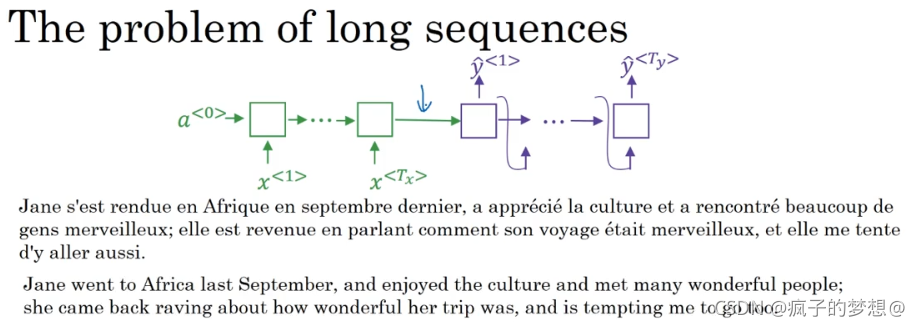
注意力模型会像人工翻译一样,一次只翻译一部分,即对每个单词的预测会分配一定的权重来决定什么时候翻译这一个单词。
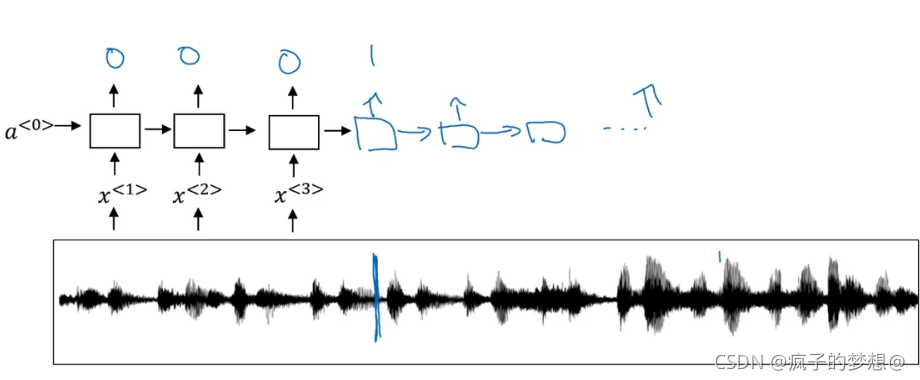
触发字检测系统
语音识别系统可以根据一个特定的名字来被唤醒,比如。你好,小度,这就叫做触发字检测系统。比如我们有下图所示音频片段,和一个RNN网络,需要计算出他的声谱特征x1、x2、x3等等放到RNN中,最后要做的就是定义标签y
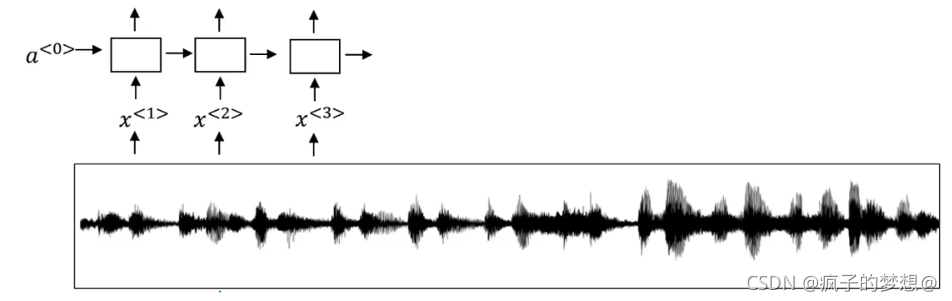
运行时,比如某人在蓝色竖线处说了小度你好,那么在RNN中,那个点的预测输出就变为1,前边一直都是0.