2021SC@SDUSC
目录
一、Paddle OCR的介绍
1.1 OCR的发展与面临的困难?
? ? ? ?OCR (Optical Character Recognition)
是一种以自动识别图像中的文本为目标的技术,其研究历史悠久,应用范围广泛,如文件电子化、身份认证、数字金融系统、车牌识别等。此外,在工厂中,通过自动提取产品的文本信息,可以更方便地管理产品。学生的线下作业或试卷可以通OCR
系统电子化,使师生之间的交流更加高效。OCR
还可以用于标记街景图像的兴趣点
(POI),提高 地图制作效率。丰富的应用场景赋予了 OCR
技术巨大的 商业价值,同时也带来了很多挑战。
? ? ? 图像中的文本大致可分为两类:场景文本和文档文本。
场景文本是指如图所示的自然场景中的文本,它通常会因为一
些因素而发生巨大的变化,如视角缩放、弯曲、混乱、字体、多语言、模糊、光照等。文档文本在实际应用中更常见。它也有高密度、长文本等问题需要解决。同时,文档图像文本识别往往需要 对结果进行结构化,这就带来了一个新的困难任务。
? ? ? 在实际应用中,需要处理的图像通常是大量的,这使得高计算效率成为设计 OCR
系统的重要标准。
优先选择
CPU
而不是 GPU。
? ? 在成本方面,特别是OCR
系统需要在许多场景下的嵌入式设备上运行,比如手机,这就需要考虑模型的大小,而权衡模型大小和性能是困难的。
1.2 PaddleOCR的推出?
? ? ? Paddle Paddle提出一种实用的超轻量级 OCR
系统,命名为
PP- OCR,该系统由文本检测、检测框校正和文本识别三部分组成。
? ? ??
PP-OCR算法被开发者广泛应用,短短半年时间,
累计Star数量已超过15k
,频频登上Github Trending和Paperswithcode 日榜月榜第一,
称它为
OCR方向目前最火的repo
绝对不为过。
? ? ??
其具有多方面的优势:
- 在 PaddleOCR 识别中,会依次完成三种任务:检测、方向分类及文本识别;
- 关于预训练权重,PaddleOCR 官网根据提供权重文件大小分为两类:轻量型和服务器部署;
- 支持多语言识别,目前能够支持 80 多种语言;
- 提供有丰富的 OCR 领域相关工具供我们使用,方便我们制作自己的数据集、用于训练;
二、PP-OCR的框架
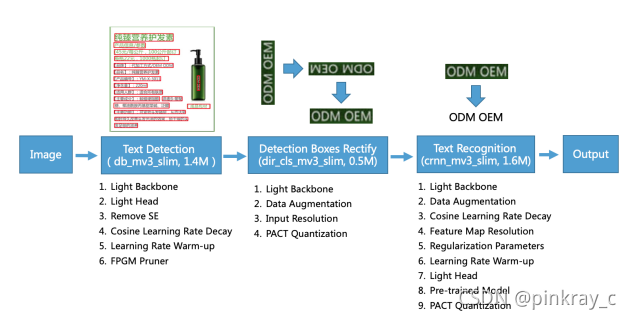
2.1 文字检测器
? ? ? 文本检测的目的是定位图像中的文本区域。
? ? ??
在
PP- OCR 中,我们使用可微分二值化
(DB) (Liao et al. 2020)
作为基于简单分割网络的文本检测器。DB
的简单后处理使得它非常高效。为了进一步提高其有效性和效率,采用了以下六种策略:
轻主干、轻头部、去除
SE
模块、余弦学习率衰 减、学习率预热和 FPGM
剪枝。最后,将文本检测器的模型尺寸减小到 1.4M
。
2.2 方向分类器
? ? ? 检测框修复识别检测到的文本前,需要将文本框转换为水平矩形框进行后续的文本识别。
? ? ? 由于检测帧由四个点组成,因此易于通过几何变换实现。
然而,矫正后的盒子可能会被反转。因此,需要一个分类器来确定文本的方向。如果确定一个方框是反向的,则需要进一步翻转。训练文本方向分类器是一项简单的图像分 类任务。我们采用以下四种策略来增强模型能力和缩小模型尺寸:
轻骨干网、数据增强、输入分辨率和
PACT
量化。最后,文本方向分类器模型大小为 500KB。
2.3 文字识别器
? ? ? ?在
PP-OCR 中,我们使用
CRNN (Shi, Bai, and Yao 2016)
作 为文本识别器,它在文本识别中被广泛应用和实用。
? ? ? ?CRNN融合了特征提取和序列建模。它采用了连接时态分类(CTC)的损失,避免了预测与标注不一致的问题。为了增强文本识别器的模型能力和缩小模型大小,采用了以下 9
种策略
:轻主干、数据增强、余弦学习速率衰减、特征图解析、
正则化参数、学习率预热、轻头部、预训练模型和 PACT
量化。文本识别器中、英文识别器模型尺寸仅为 1.6M
,字母、数字、符号识别器模型尺寸仅为 900KB
。
三、PP-OCR各模型的策略具体实现
3.1 文本检测器模型
? ? ? ?介绍增强文本检测器的模型能力或减少模型大小的 7 种策略。
- 轻骨架,选用采用 MobileNetV3 large x0.5 来权衡精度和效率;
- 轻头部,FPN (Lin et al.2017)架构;
- 去SE,去除?SE 块后,模型尺寸从 4.1M 减小到 2.5M,但精度不受影响;
- 余弦学习率衰减,学习率学习速度的超参数,学习率越低,损失值变化越慢;
- 学习率预热,有助于提高图像分类的准确率;
- FPGM,使用 FPGM (He etal. 2019b)在原始模型中寻找不重要的子网络;
3.2 方向分类器模型
? ? ? ?介绍增强方向分类器的模型能力或减少模型大小的 7 种策略。
- 轻骨架,选用采用 MobileNetV3 large x0.5 来权衡精度和效率;
- 数据增强,加 入 了 BDA 和RandAugment;
- 加入分辨率,当一幅归一化图像的输入分辨率增加时,精度也会提高;
- PACT量化,使神经网络模型具有更低的延迟、更小的体积和更低的计算功耗;
3.3 文字识别器模型?(主要介绍本人负责部分)
? ? ? ?介绍增强文字识别器的模型能力或减少模型大小的 7 种策略。
- 轻主干,选用采用 MobileNetV3 large x0.5 来权衡精度和效率;
- 数据增强,BDA (Base Dataaugmented)和TIA (Luo et al. 2020);
- 余弦学习率衰减,有效提高模型的文本识别能力;
- 特征图辨析,适应多语言识别,进行向下采样 feature map的步幅修改;
- 正则化参数,权值衰减避免过拟合;
- 学习率预热,同样有效;
- 轻头部,采用全连接层将序列特征编码为预测字符,减小模型大小;
- 预训练模型,是在 ImageNet 这样的大数据集上训练的,可以达到更快的收敛和更好的精度;
- PACT量化,略过 LSTM 层;
学习率模型: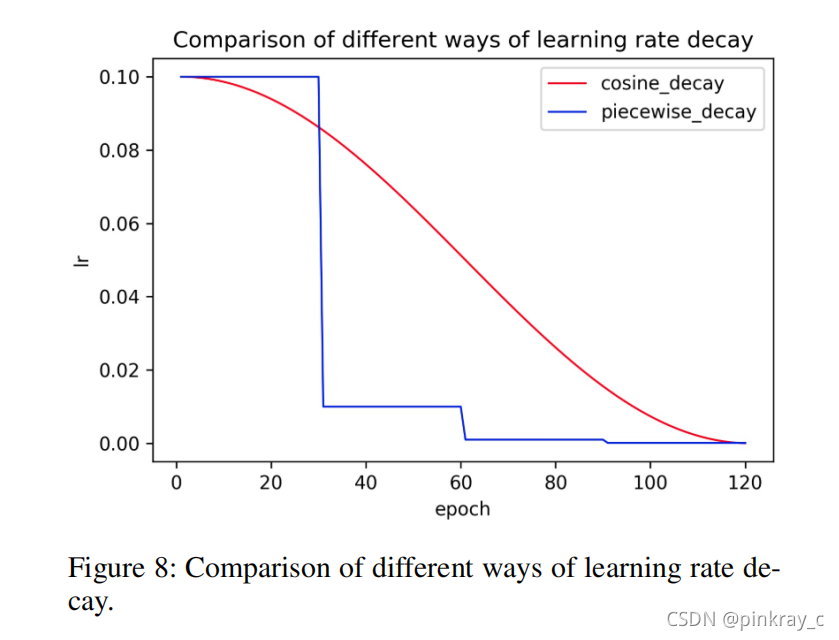
TLA算法 ?
?