? ? ? ?
目录
5.1 编码器-解码器(Encoder-Decoder)结构
???????? 序列到序列(Sequence to Sequence)模型是一种重要的语言生成框架,在机器翻译、自动摘要、对话系统等领域被广泛应用。在训练和测试过程中,序列到序列模型先通过编码器对输入文本进行编码,再通过解码器解码生成目标文本。
5.1 编码器-解码器(Encoder-Decoder)结构
? ? ? ??机器翻译是序列转换模型的一个核心问题,其输入和输出都是长度可变的序列。为了处理这种类型的输入和输出,我们可以设计一个包含两个主要组件的结构。第一个组件是一个?编码器(encoder):它接受一个长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。第二个组件是?解码器(decoder):它将固定形状的编码状态映射到长度可变的序列。这被称为?编码器-解码器(encoder-decoder)结构。
? ? ? ? 编码器解码器可以通过两个RNN模型串联构成。遵循“编码器-解码器”结构的设计原则,循环神经网络编码器可以使用长度可变的序列作为输入,将其转换为形状固定的隐藏状态。 换言之,输入(源)序列的信息被?编码?到循环神经网络编码器的隐藏状态中。 为了连续生成输出序列的词元,独立的循环神经网络解码器是基于输入序列的编码信息和输出序列已经看见的或者生成的词元来预测下一个词元。下图为示例

? ? ? ? 上图中?特定的“<eos>”表示序列结束词元。 一旦输出序列生成此词元,模型就可以停止执行预测。 在循环神经网络解码器的初始化时间步,有两个特定的设计决定。 首先,特定的“<bos>”表示序列开始词元,它是解码器的输入序列的第一个词元。 其次,使用循环神经网络编码器最终的隐藏状态来初始化解码器的隐藏状态。这种设计还可以将解码器前一时刻的结果作为下一时刻输入的一部分。
5.2 模型结构
? ? ? ? 序列到序列模型一般采用两个RNN分别作为编码器和解码器。在编码器和解码器的每个时间步t,编码状态和解码状态的隐状态表示为:
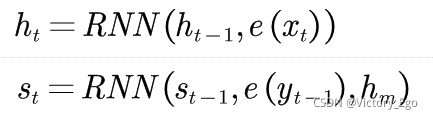
其中分别表示编码器和解码器在时间步t的编码状态和解码状态?;
是编码器和编码完整个输入X之后最后一个位置的隐状态,可以堪称对X中包含的所有输入信息的总结,解码器的起始状态用
进行初始化;RNN函数代表RNN中一系列非线性变换,既可以是标准的线性层加上激活函数,也可以是更复杂的LSTM或GRU,RNN函数中的参数即需要输入非线性变换中的信息;
指词y对应的词向量。在得到每一个时间步的解码状态后,模型通过一个多层感知器计算在整个词表上的概率分布,以便预测相应位置的输出:

在得到该概率分布后,模型就可以通过最大似然估计进行训练。?
?5.3 pytorch编写
1.构建batch
? ? ? ? 将每个单词的长度利用空白符补全构成同样长度,再添加开始和结束符号。
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps
def make_batch():
input_batch, output_batch, target_batch = [], [], []
for seq in seq_data:
for i in range(2):
seq[i] = seq[i] + 'P' * (n_step - len(seq[i]))#补齐长度
input = [num_dic[n] for n in seq[0]]
output = [num_dic[n] for n in ('S' + seq[1])]#添加开始标志
target = [num_dic[n] for n in (seq[1] + 'E')]#添加结尾标记
input_batch.append(np.eye(n_class)[input])
output_batch.append(np.eye(n_class)[output])
target_batch.append(target) # not one-hot 这个不用one-hot
# make tensor
return torch.FloatTensor(input_batch), torch.FloatTensor(output_batch), torch.LongTensor(target_batch)?2.Seq2Seq
? ? ? ? 构建两个RNN串联,设置各张量大小。
????????设置Dropout时,torch.nn.Dropout(0.5), 这里的 0.5 是指该层(layer)的神经元在每次迭代训练时会随机有 50% 的可能性被丢弃(失活),不参与训练,一般多神经元的 layer 设置随机失活的可能性比神经元少的高。
# Model
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq, self).__init__()
self.enc_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.dec_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.fc = nn.Linear(n_hidden, n_class)
def forward(self, enc_input, enc_hidden, dec_input):
enc_input = enc_input.transpose(0, 1) # enc_input: [max_len(=n_step, time step), batch_size, n_class]
dec_input = dec_input.transpose(0, 1) # dec_input: [max_len(=n_step, time step), batch_size, n_class]
# enc_states : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
_, enc_states = self.enc_cell(enc_input, enc_hidden)
# outputs : [max_len+1(=6), batch_size, num_directions(=1) * n_hidden(=128)]
outputs, _ = self.dec_cell(dec_input, enc_states)
model = self.fc(outputs) # model : [max_len+1(=6), batch_size, n_class]
return model
3.训练模型
同之前RNN模型,但这里的交叉熵计算是存在一定问题的
model = Seq2Seq()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
input_batch, output_batch, target_batch = make_batch()
for epoch in range(5000):
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
hidden = torch.zeros(1, batch_size, n_hidden)
optimizer.zero_grad()
# input_batch : [batch_size, max_len(=n_step, time step), n_class]
# output_batch : [batch_size, max_len+1(=n_step, time step) (becase of 'S' or 'E'), n_class]
# target_batch : [batch_size, max_len+1(=n_step, time step)], not one-hot
output = model(input_batch, hidden, output_batch)
# output : [max_len+1, batch_size, n_class]
output = output.transpose(0, 1) # [batch_size, max_len+1(=6), n_class]
loss = 0
for i in range(0, len(target_batch)):
# output[i] : [max_len+1, n_class, target_batch[i] : max_len+1]
loss += criterion(output[i], target_batch[i])
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()由于特定的填充词元被添加到序列的末尾,因此不同长度的序列可以以相同形状的小批量加载。但是,应该将填充词元的预测排除在损失函数的计算之外。这里可以利用李沐老师带遮蔽的softmax交叉熵损失函数
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项。"""
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction = 'none'
unweighted_loss = super(MaskedSoftmaxCELoss,
self).forward(pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
loss = MaskedSoftmaxCELoss()
l = loss(Y_hat, Y, Y_valid_len)#传入实际长度和预测值、实际值4.测试模型
# make test batch
def make_testbatch(input_word):
input_batch, output_batch = [], []
input_w = input_word + 'P' * (n_step - len(input_word))
input = [num_dic[n] for n in input_w]
output = [num_dic[n] for n in 'S' + 'P' * n_step]
input_batch = np.eye(n_class)[input]
output_batch = np.eye(n_class)[output]
return torch.FloatTensor(input_batch).unsqueeze(0), torch.FloatTensor(output_batch).unsqueeze(0)
# Test
def translate(word):
input_batch, output_batch = make_testbatch(word)
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
hidden = torch.zeros(1, 1, n_hidden)
output = model(input_batch, hidden, output_batch)
# output : [max_len+1(=6), batch_size(=1), n_class]
predict = output.data.max(2, keepdim=True)[1] # select n_class dimension
decoded = [char_arr[i] for i in predict]
end = decoded.index('E')
translated = ''.join(decoded[:end])
return translated.replace('P', '')
print('test')
print('man ->', translate('man'))
print('mans ->', translate('mans'))
print('king ->', translate('king'))
print('black ->', translate('black'))
print('upp ->', translate('upp'))测试结果

?5.预测结果的评估
我们可以通过与真实的标签序列进行比较来评估预测序列。虽然 BLEU(Bilingual Evaluation Understudy)的提出最先是用于评估机器翻译的结果??,但现在它已经被广泛用于测量许多应用的输出序列的质量。原则上说,对于预测序列中的任意元语法(n-grams),BLEU 的评估都是这个
?元语法是否出现在标签序列中。
用?表示?
元语法的精确度,它是两个数量的比值,第一个是预测序列与标签序列中匹配的?
?元语法的数量,第二个是预测序列中?
元语法的数量的比率。详细解释,即给定的标签序列?
和预测序列?
,我们有
。另外,?
表示标签序列中的词元数和?
?表示预测序列中的词元数。那么,BLEU 的定义是:
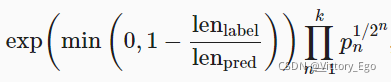
?其中?是用于匹配的最长的?nn?元语法。
根据上式中BLEU 的定义,当预测序列与标签序列完全相同时,BLEU 为?1。此外,由于?元语法越长则匹配难度越大,所以 BLEU 为更长的?
?元语法的精确度分配更大的权重。BLEU的代码实现如下:
def bleu(pred_seq, label_seq, k): #@save
"""计算 BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[''.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[''.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[''.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score5.4 小结
-
根据“编码器-解码器”架构的设计,我们可以使用两个循环神经网络来设计一个序列到序列学习的模型。我们也可以使用多层循环神经网络。
-
我们需要填充长度使得各句子具有共性,此外可以使用遮蔽来过滤不相关的计算,例如在计算损失时。
-
在“编码器-解码器”训练中,Teacher-forcing将原始输出序列(而非预测结果)输入解码器。
-
BLEU 是一种常用的评估方法,它通过测量预测序列和标签序列之间的
元语法的匹配度来实现。
5.5 参考文档
9.7. 序列到序列学习(seq2seq) ― 动手学深度学习 2.0.0-alpha2 documentation