?2021SC@SDUSC
АыМрЖНбЇЯАгаСНИібљБОМЏ,вЛИігаБъМЧ,вЛИіУЛгаБъМЧ.ЗжБ№МЧзї
Lable={(xi,yi)},Unlabled={(xi)}.ВЂЧвЪ§СПЩЯ,L<<U.
-
ЕЅЖРЪЙгУгаБъМЧбљБО,ЮвУЧФмЙЛЩњГЩгаМрЖНЗжРрЫуЗЈ
-
ЕЅЖРЪЙгУЮоБъМЧбљБО,ЮвУЧФмЙЛЩњГЩЮоМрЖНОлРрЫуЗЈ
-
СНепЖМЪЙгУ,ЮвУЧЯЃЭћдк1жаМгШыЮоБъМЧбљБО,діЧПгаМрЖНЗжРрЕФаЇЙћ;ЭЌбљЕФ,ЮвУЧЯЃЭћдк2жаМгШыгаБъМЧбљБО,діЧПЮоМрЖНОлРрЕФаЇЙћ.
вЛАуЖјбд,АыМрЖНбЇЯАВржигкдкгаМрЖНЕФЗжРрЫуЗЈжаМгШыЮоБъМЧбљБОРДЪЕЯжАыМрЖНЗжРр.вВОЭЪЧдк1жаМгШыЮоБъМЧбљБО,діЧПЗжРраЇЙћ.
SOTA State of The Art дкИУСьгђзюЯШНјЕФФЃаЭ SOTA model:State-Of-The-Art model,ЪЧжИдкИУЯюбаОПШЮЮёжа,ЖдБШИУСьгђЕФЦфЫћФЃаЭ,етИіЪЧФПЧАзюКУ/зюЯШНјЕФФЃаЭЁЃ
SOTA result:State-Of-The-Art result,вЛАуЪЧЫЕдкИУСьгђЕФбаОПШЮЮёжа,ДЫpaperЕФНсЙћЖдБШвбОДцдкЕФФЃаЭМАЪЕЯжНсЙћ,ДЫPaperЕФФЃаЭОпгазюКУЕФадФм/НсЙћЁЃ
BERTФЃаЭ:BidirectionalEncoder Representations from Transformer зжЯђСП+ЮФБОЯђСП+ЮЛжУЯђСП(зжДЪдкВЛЭЌЮЛжУЕФгявхгаВюБ№,МгЩЯвЛИіЯђСПБугкЧјЗж) fine-tunningЗЖЪН Ъ§ОндіЧП EDA ЭЌвхДЪЬцЛЛКЭЛивы Self-attention
TransformerФЃаЭ ЯрЕБгквЛИіКкЯЛзг,НЋinputЕФвЛжжгябдОЙ§КкЯЛзгзЊЛЛoutputСэвЛжжгябд TransformerРяУцУПИіEncoders(input)ЗжБ№га6Иіencoder,УПИіDecodersРяУцга6ИіDecoderЁЂ encoder-decoderФЃаЭ(БрТы-НтТыФЃаЭ)АДееЮвздМКЕФРэНтencoderЛсАбЪфШыЕФаХЯЂБрТыГЩЙЬЖЈДѓаЁЕФЯђСП,етИіЙ§ГЬПЩФмЛсЖдаХЯЂгавЛЖЈЕФбЙЫѕЫ№ЪЇЁЃ УПИіencoderЕФНсЙЙвЛбљ,РяУцгаСНИізгВуFeed Forward Neural NetworkКЭSelf-Attention,encoderЕФinputЪзЯШЭЈЙ§self-attentionВуШЛКѓИУВуЪфГіЕНFeed Forward Neural Network(ЧАРЁЩёОЭјТч)
ЙигкTransformerФЃаЭетЦЊЮФеТаДЕУЗЧГЃЯъЯИЗЧГЃКУ,ЮвЕФећИіРэНтвВЛљгкДЫ,ДѓМвПЩвдНјШЅПДПДгЂЮФдАц,ЯИНкТњТњ:The Illustrated Transformer ЈC Jay Alammar ЈC Visualizing machine learning one concept at a time.
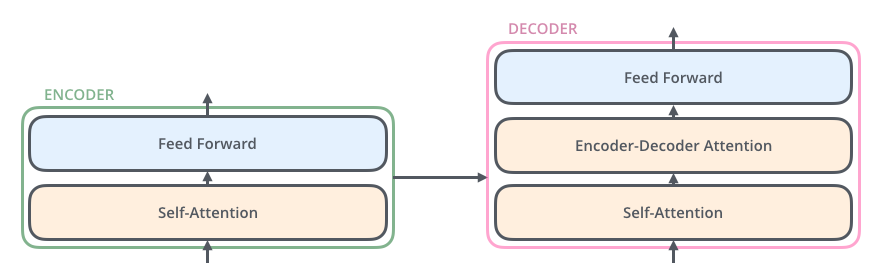
Self-attentionЪЧTransformerФЃаЭжавЛЗЧГЃживЊЕФВПЗжЁЃ
self-attention layer: a layer that helps the encoder look at other words in the input sentence as it encodes a specific word.гУРДАяжњencoderевЕНЪфШыгяОфжаЕФЦфЫћЕЅДЪЁЃ
DecoderвВгаФЧСНВу,ВЛЙ§ЛЙгавЛИіencoder-decoder attention,ВЛЯёФЧСНВуЪЧЛљгкmulti-head attention layerЕФ,ЫќЪЧгУРДАяжњЪфГіОфзгЯрЙиЕФВПЗж(РрЫЦгкseq2seqФЃаЭ),етВуЕФжиЕуЪЧmasking,maskingЕФзїгУЪЧЗРжЙдкбЕСЗЕФЪБКђЪЙгУЮДРДЪфГіЕФЕЅДЪЁЃЕквЛИіЕЅДЪЪЧВЛФмВЮПМЕкЖўИіЕЅДЪЕФЩњГЩНсЙћЕФЁЃ MaskingОЭЛсАбетИіаХЯЂБфГЩ0, гУРДБЃжЄдЄВтЮЛжУ i ЕФаХЯЂжЛФмВЮПМБШ i аЁЕФЪфГіЁЃ
ransformerжаЕФУПИіEncoderНгЪевЛИі512ЮЌЖШЕФЯђСПЕФСаБэзїЮЊЪфШы,ШЛКѓНЋетаЉЯђСПДЋЕнЕНЁЎself-attentionЁЏВу,self-attentionВуВњЩњвЛИіЕШСП512ЮЌЯђСПСаБэ,ШЛКѓНјШыЧАРЁЩёОЭјТч,ЧАРЁЩёОЭјТчЕФЪфГівВЮЊвЛИі512ЮЌЖШЕФСаБэ,ШЛКѓНЋЪфГіЯђЩЯДЋЕнЕНЯТвЛИіencoderЁЃ
УПИіЮЛжУЕФЕЅДЪЪзЯШЛсОЙ§вЛИіself attentionВу,ШЛКѓУПИіЕЅДЪЖМЭЈЙ§вЛИіЖРСЂЕФЧАРЁЩёОЭјТч(етаЉЩёОЭјТчНсЙЙЭъШЋЯрЭЌ)ЁЃ
Self-attention ДгУПИіEncoderЕФЪфШыЯђСП(УПИіЕЅДЪ)ЩЯДДНЈШ§ИіЯђСП:QueryЁЂKeyЁЂValue
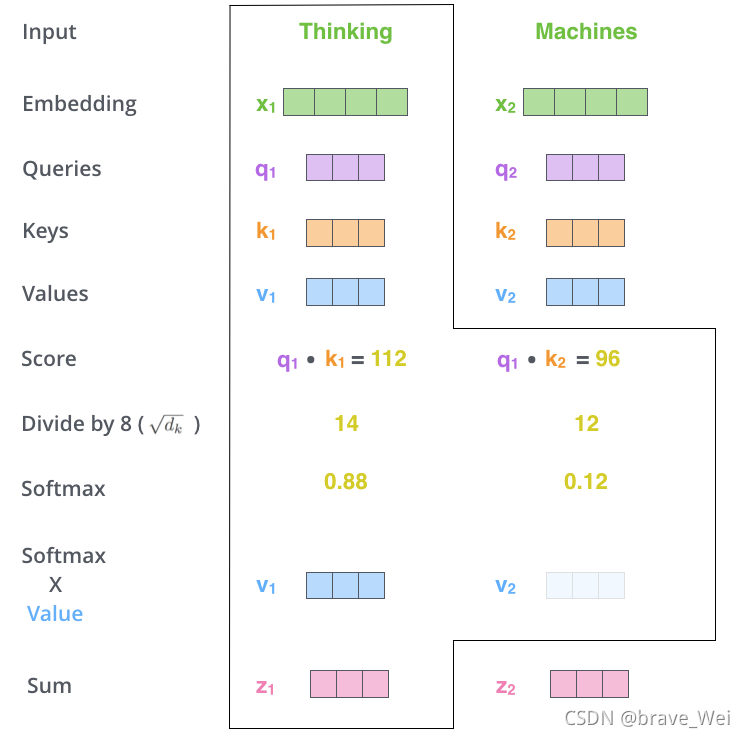
1.ScoreМЦЫу
2.Divide by 8()
3.SOFTMAX
4.Softmax X Value
5.Sum
ОЙ§вдЩЯМЦЫуЕУЕНSelf-attentionВуЕФЪфГі,ОпЬхМЦЫудРэдкДЫВЛЩюОПЁЃ
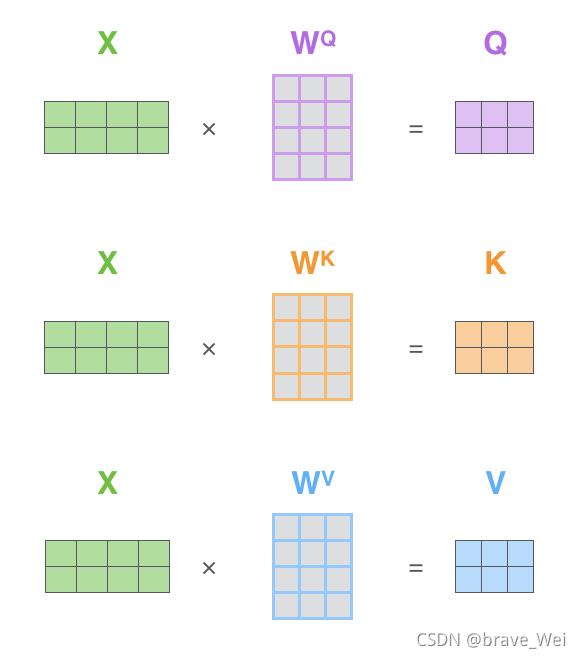
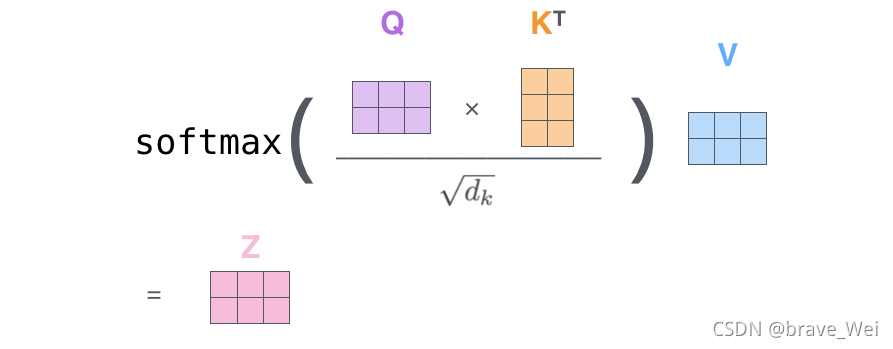
?ЩЯЭМЪЧself-attentionЕФОиеѓМЦЫудРэ
НгЯТРДПДПДНтТыЦїЖЫDecoder
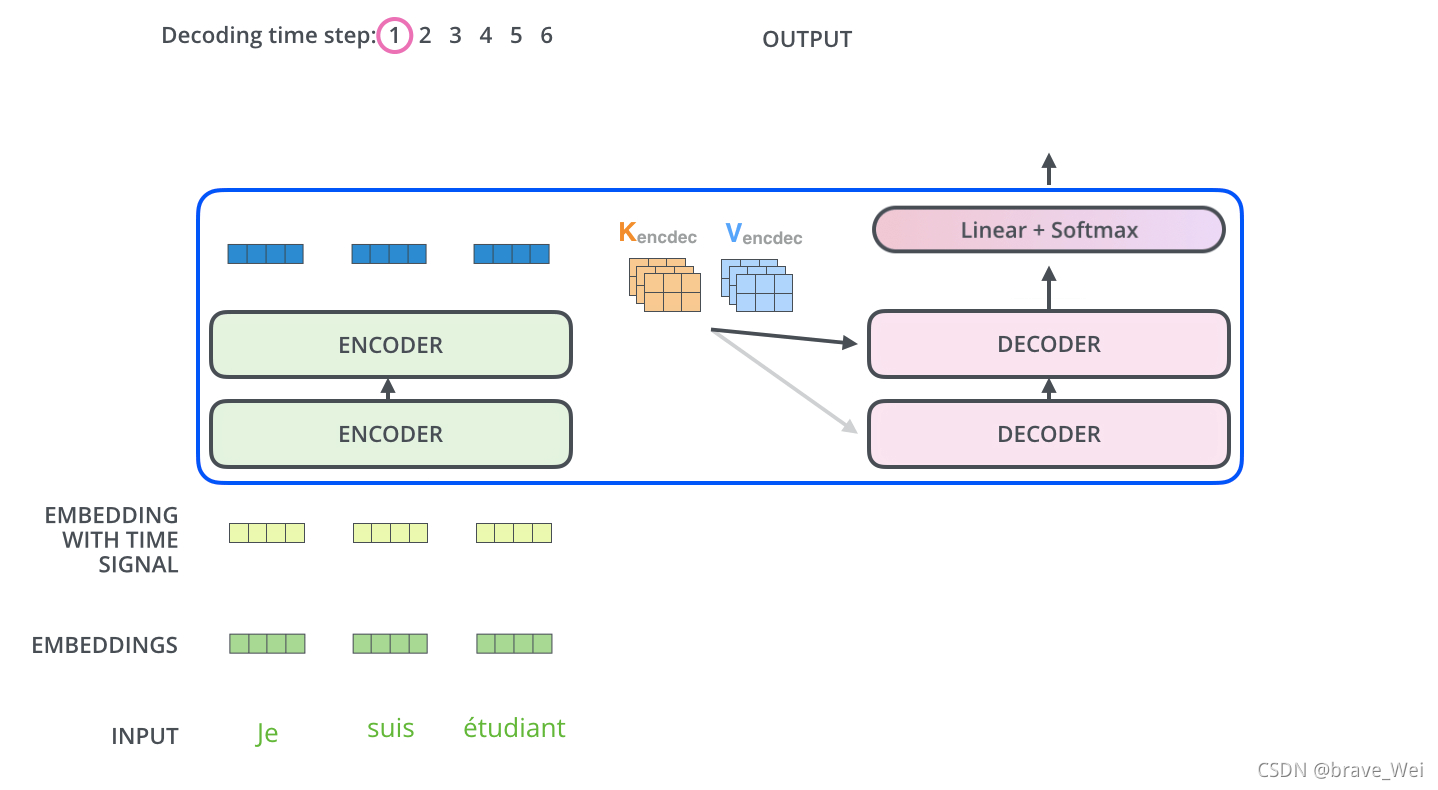
?ЙигкSelf-attentionжаЕФencoderЛЙгаКмЖргХЛЏдкДЫВЛзИЪі,ТлЮФРяКмЯъЯИЁЃ
?DecoderжївЊЪЧЖдЪфШыЯђСПЕФkКЭvНјааВйзїНтТы ,РяУцЕФВуДЮКЭencoderВюВЛЖр,ВЛЙ§РяУцгавЛИіattentionВуАяжњDecoderзЈзЂгкЪфШыОфзгжаЖдгІЕФДЪ,РрЫЦгкseq2seq modelЁЃ
UDAДѓжТЗжЮЊСНВПЗж fine-tuningКЭEvaluatio