2021SC@SDUSC
1.PaddleOCR论文分析
?PP-OCR是一种实用的超轻型OCR系统。整个PaddleOCR模型仅用3.5M识别6622个汉字;2.8M识别63个字母数字符号。PP-OCR引入了一系列策略来增强模型的能力、减小模型的规模。并给出了相应的烧蚀实验和实际数据。同时,发布了几个预先训练的中英文识别模型,包括文本检测器(使用97K图像)、方向分类器(使用600K图像)和文本识别器(使用17.9M图像)。此外,该算法在法语、韩语、日语和德语等语言识别任务中也得到了验证。
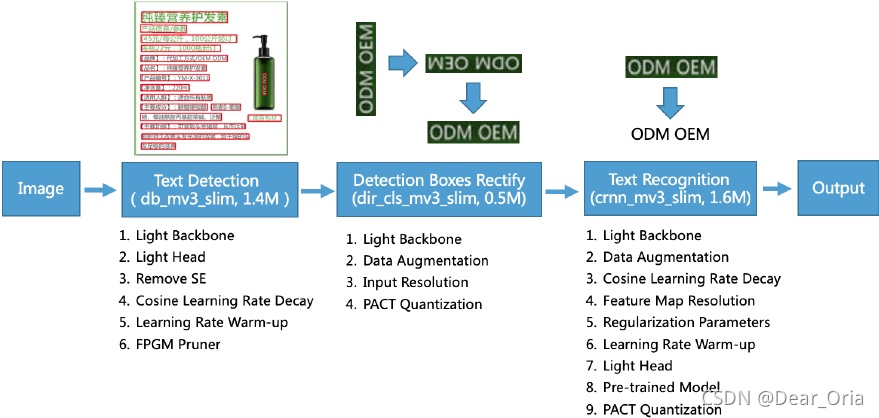
PP-OCR可从总体上分成3个关键技术,分别为文本检测、方向分类和文本识别(如上图)。其中文本识别的作用是定位图像中的文本区域,方向分类的作用是将文本框转换为水平矩形框进行后续的文本识别,文本识别的作用是识别出文本结果。因为我的分工是分析文本识别部分的代码,所以我将在下面的博客中对PP-OCR采用的增强和瘦身策略中关于文字识别的4个关键技术――正则化参数、预热学习率、预训练模型和PACT量化进行简单介绍。
2.文字识别关键技术简介
?2.1正则化参数
?过拟合是机器学习中的一个常见术语。
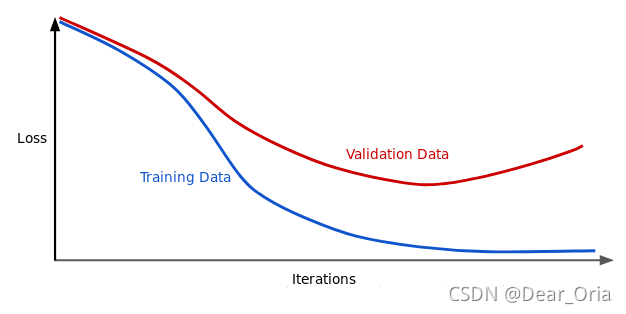
一个简单的理解是模型在训练数据上表现良好,但在测试数据上表现较差。为了避免过拟合,人们提出了许多常规的方法。其中,权值衰减是最常用的避免过拟合的方法之一。PP-OCR采用了L2正则化(L2衰减)。L2 正则化公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和:

其中,Ein 是未包含正则化项的训练样本误差,λ 是正则化参数,可调。将L2正则化(L2衰减)添加到损耗函数中,在L2正则化的帮助下,网络的权值趋于较小,最终整个网络的参数趋于0,模型的泛化性能得到了相应的提高。对于文本识别来说,L2衰减对识别的准确性有很大的影响。
?2.2预热学习率
?学习速率的预热也有助于文本识别。学习率是神经网络训练中最重要的超参数之一,针对学习率的优化方式很多,Warmup是其中的一种。Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习来进行训练。
?2.3预训练模型
?预训练模型就是已经用数据集训练好了的模型。如果训练数据较少,对现有的网络进行微调,这些网络是在ImageNet这样的大数据集上训练的,可以达到更快的收敛和更好的精度。在真实场景中,用于文本识别的数据往往是有限的。如果使用数千万个样本对模型进行训练,即使这些样本是合成的,使用上述模型也可以显著提高精度。
?2.4PACT量化
?PP-OCR使用PACT量化来减小文本识别器的大小。PACT量化(PArameterized Clipping acTivation)是一种新的量化方法,该方法提出在量化激活值之前去掉一些离群点来降低模型量化带来的精度损失。提出方法的背景是作者发现:“在运用权重量化方案来量化activation时,激活值的量化结果和全精度结果相差较大”。作者发现,activation的量化可能引起的误差很大(相较于weight基本在 0到1范围内,activation的值的范围是无限大的,这是RELU的结果),所以提出截断式RELU 的激活函数。该截断的上界,即α 是可学习的参数,这保证了每层能够通过训练学习到不一样的量化范围,最大程度降低量化带来的舍入误差。
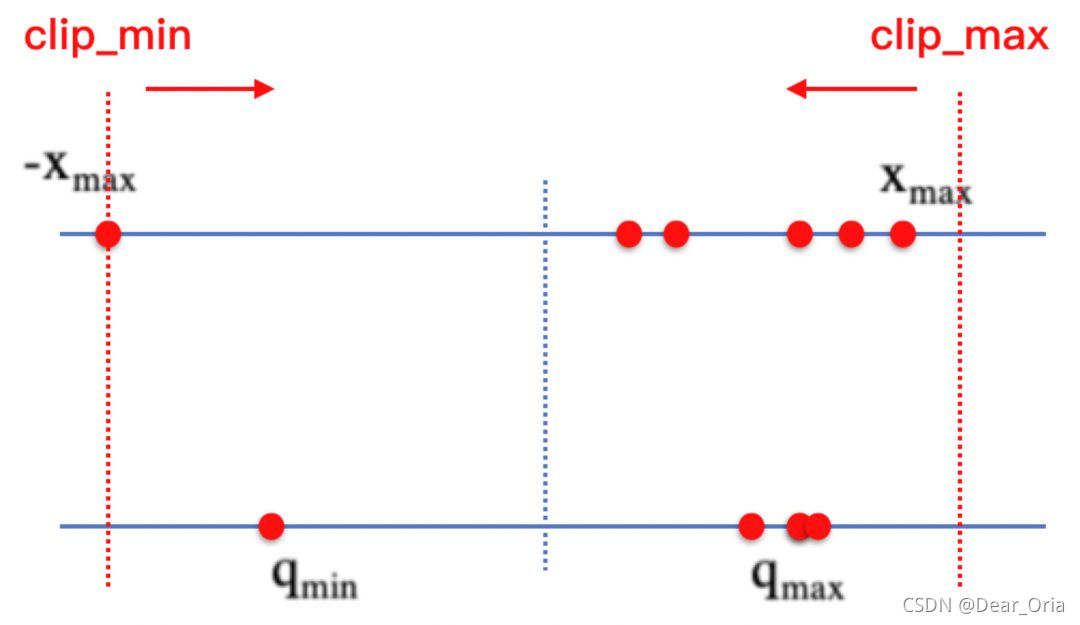
如上图,PACT解决问题的方法是,不断裁剪激活值范围,使得激活值分布收窄,从而降低量化映射损失。PACT通过对激活数值做裁剪,从而减少激活分布中的离群点,使量化模型能够得到一个更合理的量化scale,降低量化损失。PACT的公式如下所示:
可以看出PACT原始的思想是用PACT代替ReLU函数,对大于零的部分进行一个截断操作,截断阈值为α。