通过使用框架来实现线性模型
import torch
import numpy as np
from torch.utils import data
import sys
sys.path.append("E:\ANaconda\envs\pytroch_env\Lib\site-packages")
from d2l import torch as d2l
true_w=torch.tensor([2,-3.4])
ture_b=4.2
features,lables=d2l.synthetic_data(true_w,true_b,1000)
调用框架中现有的API(接口)来读取数据,每次随机抓取十个数据
def load_array(data_arrays,batch_size,is_train=True):
'''构造一个pytorch数据迭代器'''
dataset=data.TensorDataset(*data_arrays) #*号可以表示list中的各个数据
return data.DataLoader(dataset,batch_size,shuffle=is_train) #每次随机挑选batch_size个样本出来,打乱顺序
batch_size=10
data_iter=load_array((features,lables),batch_size)
next(iter(data_iter)) #next() 返回迭代器的下一个项目。next() 函数要和生成迭代器的 iter() 函数一起使用。使用框架预定义好的层
from torch import nn #神经网络的缩写
net=nn.Sequential(nn.Linear(2,1)) #输入维度输出维度 线性层或全连接层 ,Sequential 可以理解为list of layers
#初始化参数权重
net[0].weight.data.normal_(0,0.01)
net[0].bias.data.fill_(0)使用均方误差和实例SGD
loss=nn.MSELoss()
trainer=torch.optim.SGD(net.parameters(),lr=0.03) #parameters表示所有模块数据[w,b]开始训练
num_epochs=3
for epoch in range(num_epochs):
for x,y in data_iter:
l=loss(net(x),y) #net中已经包含了w,b的参数
trainer.zero_grad()
l.backward() #torch已经帮忙做了sum了,可以直接backward
trainer.step() #优化更新模型
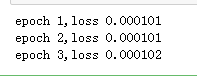
l=loss(net(features),lables)
print('epoch %d,loss %f'%(epoch+1,l.mean()))框架让代码更简洁
?