һ.k-�����㷨��Ӱ������
ʵ�ִ���
import numpy as np
import operator
def knn(trainData, testData, labels, k):
# ����ѵ������������
rowSize = trainData.shape[0]
# ����ѵ�������Ͳ��������IJ�ֵ
diff = np.tile(testData, (rowSize, 1)) - trainData
# �����ֵ��ƽ����
sqrDiff = diff ** 2
sqrDiffSum = sqrDiff.sum(axis=1)
# �������
distances = sqrDiffSum ** 0.5
# �����õľ���ӵ͵��߽�������
sortDistance = distances.argsort()
count = {}
for i in range(k):
vote = labels[sortDistance[i]]
count[vote] = count.get(vote, 0) + 1
# �������ֵ�Ƶ���Ӹߵ��ͽ�������
sortCount = sorted(count.items(), key=operator.itemgetter(1), reverse=True)
# ���س���Ƶ����ߵ����
return sortCount[0][0]
trainData = np.array([[5, 8], [4, 1], [3, 3], [4, 4]])
labels = ['����Ƭ', '����Ƭ', '����Ƭ', '����Ƭ']
testData = [4, 2]
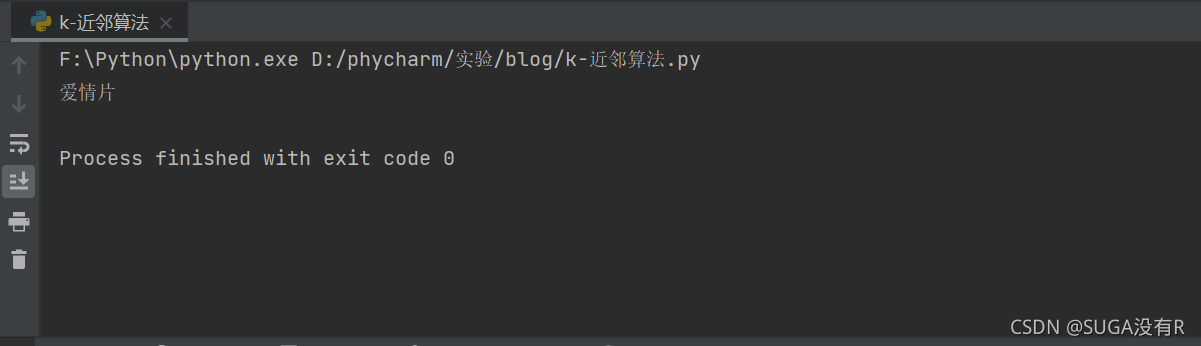
X = knn(trainData, testData, labels, 3)
print(X)ʵ����
��.��дʶ��ϵͳ
���ȵ������������ļ��в��Լ���ѵ����(testDigits��trainingDigits�������Ҫ��һ��),�����Ų�ͬд�������֡�ѵ�����е�������Ϊѵ������ ,֮���ڲ��Լ��м���?
��Ҫʶ��������Ѿ���ͼ��������������������ͼ��ʾ,������ͬ�����غ���״:����32���ء�32���صĺڰ�ͼ�ڰ����طֱ���0��1��ʾ. Ȼ����ת�����ı��洢��ʽ�洢������,��������ͼ��ֱ�Ӵ�TEXT�ĵ��н�ȡ������0,1,2



?
?����
import numpy as np
from os import listdir
import knn as k
def classify0(inX,dataSet,labels,k):
dist=(((dataSet-inX)**2).sum(1))**0.5
sortedDist=dist.argsort()
classCount={}
for i in range(k):
voteLabel = labels[sortedDist[i]]
classCount[voteLabel]=classCount.get(voteLabel,0)+1
maxType=0
maxCount=-1
for key,value in classCount.items():
if value > maxCount:
maxType = key
maxCount = value
return maxType
def img2vector(filename):
returnVect = np.zeros((1, 1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0, 32 * i + j] = int(lineStr[j])
return returnVect
# load the training set
hwLabels = []
trainingFileList = listdir('D:/phycharm/test/trainingDigits')
m = len(trainingFileList)
trainingMat = np.zeros((m, 1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i, :] = img2vector('D:/phycharm/test/trainingDigits/%s' % fileNameStr)
# iterate through the test set
testFileList = listdir('D:/phycharm/test/testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('D:/phycharm/test/testDigits/%s' % fileNameStr)
classifierResult = k.knn(vectorUnderTest, trainingMat, hwLabels, 3)
print("��ʶ�����: %d, ʵ��ֵ��: %d" % (classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount += 1.0
print("\n��ʶ��������Ϊ: %d" % errorCount)
print("\n��ʶ��Ϊ: %f %" % ((1 - errorCount / float(mTest)) * 100))
ʵ����

?�ο���Ƶѧϰ:����ѧϰ-�����㷨��Ӧ��ʵ��(��)��д��ʶ��ʵս_��������_bilibili
��.KNN����Լ����վ�����Ч��
(1)�ռ�����:�ṩ�ı��ļ���
(2)������: python�����ı��ļ���
(3)��������:ʹ��Matplotlib������ά��ɢͼ��
(4)ѵ���㷨:�˲��E��������K-�����㷨��
(5)�����㷨:ʹ���ṩ�IJ���������Ϊ�������������������ͷDz�����������������:�����������Ѿ���ɷ��������,���Ԥ�����
��ʵ�����ͬ,����Ϊһ������
(6)ʹ���㷨:�����������г���,Ȼ����������һЩ�����������ж϶Է��Ƿ� Ϊ�Լ�ϲ��������
?
1.���ı��ļ��н�������Դ��:?
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines())
returnMat = np.zeros((numberOfLines,3))
classLabelVector = []
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat,classLabelVector
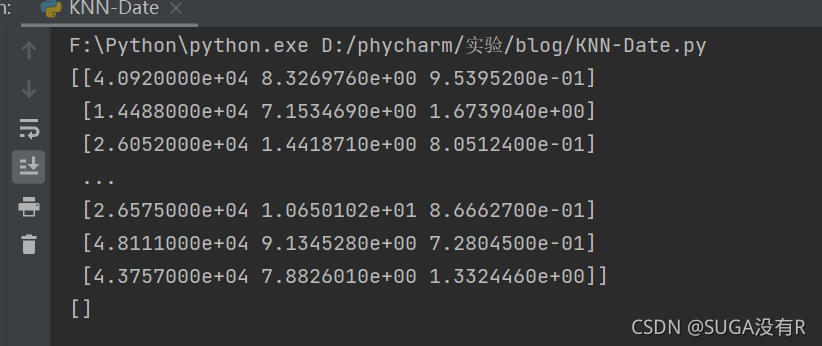
datingDataMat,datingLabels=file2matrix('D:/phycharm/test/Date/datingTestSet.txt')
print(datingDataMat)
print(datingLabels)ʵ����:
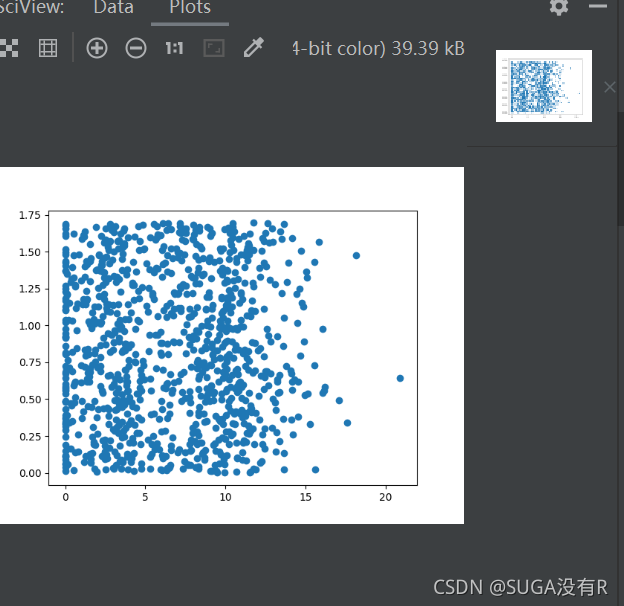
?2.ʹ��Matplolib����ԭʼ���ݵ�ɢ��ͼ
fig=plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2])
plt.show()ɢ��ͼʹ��datingDataMat����ĵڶ�������������,�ֱ��ʾ����ֵ������Ƶ��Ϸ����ʱ��ٷֱȡ� �͡�ÿ�������ѵı���ܹ�������
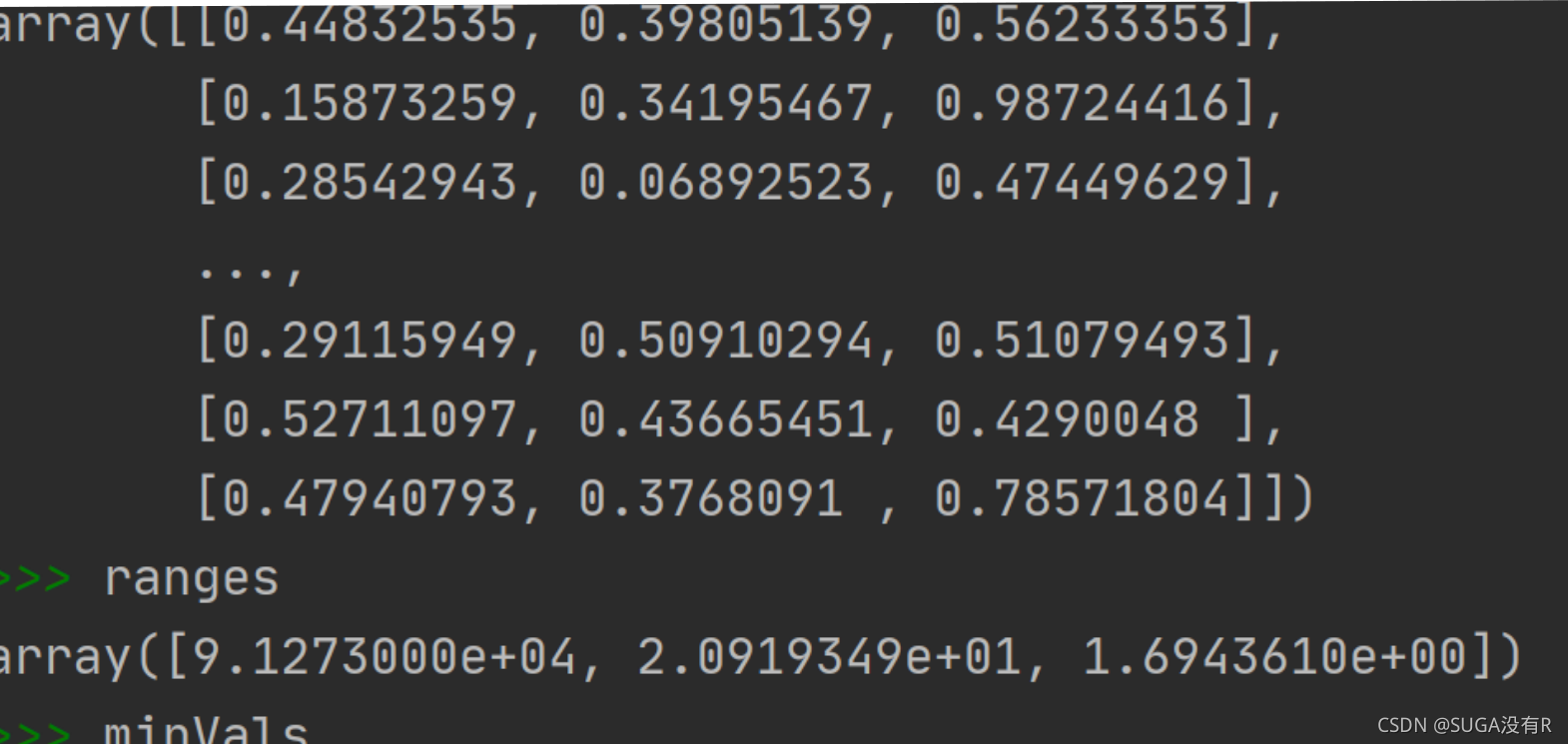
?3.��һ����ֵ
Դ��:
def autoNorm(dataSet):
minVals=dataSet.min(0)
maxVals=dataSet.max(0)
ranges=maxVals-minVals
normDataSet = zeros(shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet-tile(minVals,(m,1))
normDataSet=normDataSet/tile(ranges,(m,1))
return normDataSet,ranges,minValsʵ����:
?������:
def datingClassTest():
hoRatio = 0.10
datingDataMat,datingLabels = file2matrix('D:/phycharm/test/Date/datingTestSet.txt')
normMat,ranges,minVals=autoNorm(datingDataMat)
m=normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult = k.knn(normMat[i,:],normMat[numTestVecs:m,:],\
datingLabels[numTestVecs:m],3)
print("the classifier came back with: %d, the real answer is : %d"\
%(classifierResult,datingLabels[i]))
if(classifierResult != datingLabels[i]):errorCount+=1.0
print("the total error rate is : %f" % (errorCount/float(numTestVecs)))