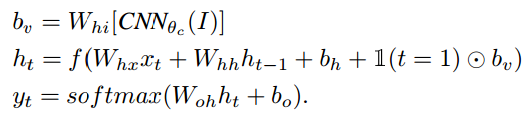0.入门二《Deep Visual-Semantic Alignments for Generating Image Descriptions》
这篇论文相对于上篇论文《Deep Fragment Embeddings for Bidirectional Image Sentence Mapping》是可以生成描述description,而且retrieval也得到了提升。
文本的处理
这篇论文句子提取的不再是单词之间的属性(dependency)。而是首先对每一个单词都生成一个特征向量,这是通过双向RNN(BRNN)生成的,因为RNN网络可以学习上下文信息,单词是与整个句子的语义相关的。
RNN函数如下:
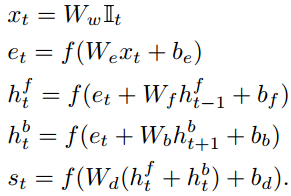
其中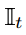 是1-of-k向量。
是1-of-k向量。
图像的处理
依然采用RCNN模型。对于image和sentence对应的相似度计算方法如下式:
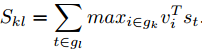
模型结构
 以上模型通过训练后,学习到的只是Word和image的region的对应关系,这可能会使得邻近单词(它们可能相关)被对应到不同的label中。论文通过使用马尔科夫随机场来输出最佳的每个Word对应的region的序列。马尔科夫随机场对应的势函数为:
以上模型通过训练后,学习到的只是Word和image的region的对应关系,这可能会使得邻近单词(它们可能相关)被对应到不同的label中。论文通过使用马尔科夫随机场来输出最佳的每个Word对应的region的序列。马尔科夫随机场对应的势函数为:
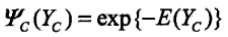
而E(Yc) 是能量函数,注意前面是负值,要使得最后序列的概率最大,则能量函数应尽量小。所以这里定义能量函数的条件为,使用链式条件随机场的形式:
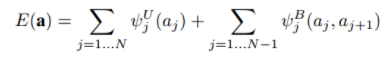
其中,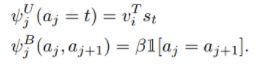
对于后面一项,当两个前后的word分配同一个标注时,希望能量函数为0(即尽量小),否则为β。第一项可能认为是固有属性,直接与第二项相加。当β越大,意味着如果希望能量函数越小,分配到同一个box的连接的word会趋向于更多。
以上解决的是latent alignment(潜在对齐)问题。
之后通过使用generator的RNN的生成captioning,模型如下:
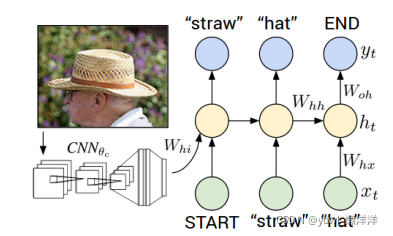
具体计算过程为: