我们这次用的数据集不再是tensorflow中内置的数据集,而是自定义的数据集,我们先看一下我们的数据??
所有的数据都存储在2_class这个文件夹中

文件夹中有airplane与lake这两个子文件夹

分别存放的是飞机与湖泊的卫星图像
- airplane

- lake

目录
1??导入库
我们这里首次用到了glob这个库,这个库是python自带的库,用于处理路径中的文件的
random也是Python自带的库,用于进行一些随机的操作
2??数据处理
2.1??获取图像
首先我们获取所有的图像
![]()
我们在2_class中有两个子文件夹,现在我们都要,所以我们用*表示,后面的*.jpg表示我们要所有的jpg文件
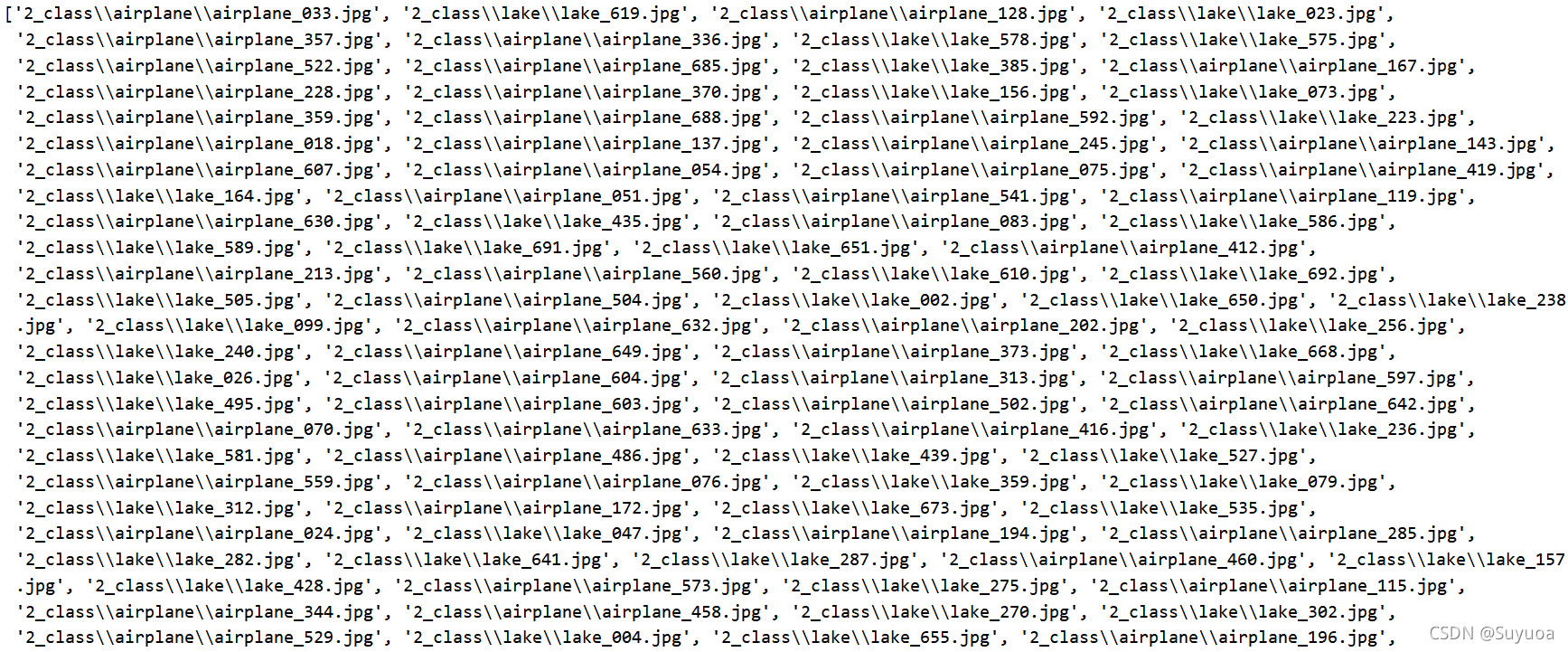
glob.glob的返回值是一个列表,我们打印出来看一下



![]()
我们可以发现all_iamge_path的前面都是飞机,后面都是湖泊,所以我们在这里要进行乱序以达到更好的训练效果,此处我们使用ramdom.shuffle()

![]()
2.2??定义标签
我们定义飞机的标签为0,湖泊的标签为1,我们先创建一个字典明确对应关系
![]()
为了最终预测方便我们再定义反过来(索引对标签)的字典

![]()
2.3??制作标签集
定义之后我们要为所有的图像添加标签,我们发现在路径中,中间的子文件夹名称就是该图片对应的标签,所以我们现在把这个名称取出来
这里我们要用到str的内置方法split,这个方法我在这个里面有介绍?python str基本用法_potato123232的博客-CSDN博客
![]()
- 不同系统的路径分隔符可能有区别,我们当前使用的是windows,用的是双斜杠(\\)
我们打印出来看一下

![]()
3??加载图像
tensorflow有内置读取文件的方法 tf.io.read_file()参数为文件路径
我们现在读取一个文件试一下这个方法



![]()
当前的类型是一堆二进制的数据,我们要将其解码,使其变为tensor,我们使用tf.image.decode_jpeg()进行解码,第一个参数为要解码的对象,第二个参数为通道格式,我们当前为彩色图像,所以为3



![]()
这个就是我们要用到的类型,我们现在先看一下它的shape
![]()
![]()
前面两个是宽高,第三个是通道(rgb三通道)
再看一下它的dtype
![]()
![]()
发现是uint8,我们训练中最好转换为float,我们使用tensorflow的cast方法进行类型转换
![]()
之后我们对图像进行归一化,由于当前图像的取值范围为(0-255)所以我们除255(一般的图像取值范围都是0到255)

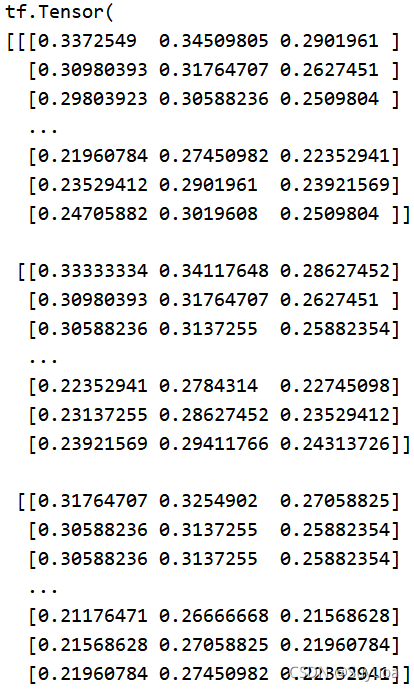
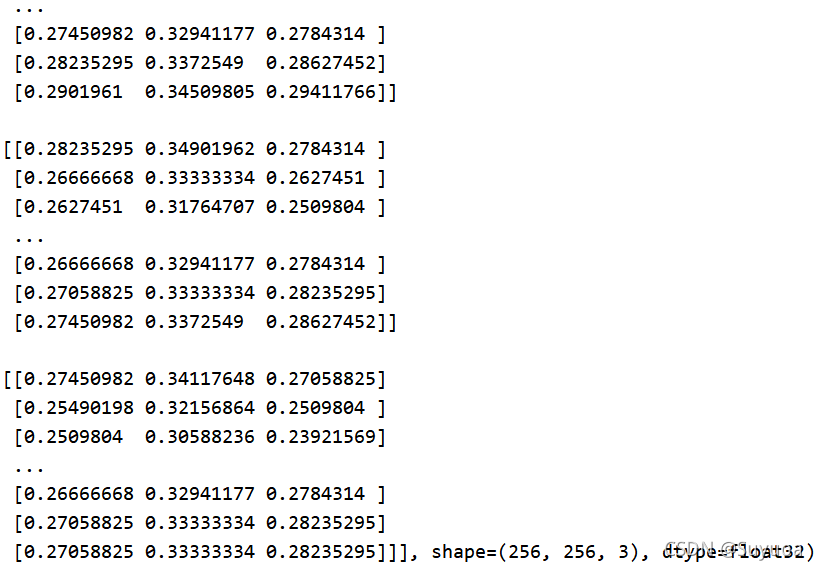
我们为了今后方便将上面的过程封装成一个函数
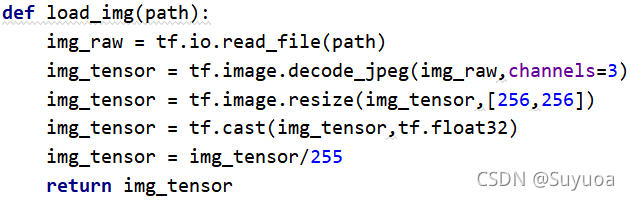
我们正好梳理一下流程
首先我们需要图片的路径,然后读取该路径的文件
之后解码该文件
再之后我们需要加入一步操作,我们刚刚进行的是单张的流程,所以不涉及到图片大小不一的情况,我们在训练的过程中,将图片的大小统一会达到更好的效果,所以我们此处使用tf.image.resize改变图像的大小
此处我们将其都改为(256,256)的图像大小,之后将其类型转变为float32,再之后归一化
4??创建数据集
4.1??创建图片路径数据集
首先我们创建所有图片路径的数据集
![]()
我们看一下当前的路径集


我们从types可以看出来,现在里面全都是字符串
4.2??创建图片数据集
然后我们将路径集中的每个元素都执行一遍load_img(),此处我们使用的是tensorflow中的map方法,这个方法与python内置的map方法使用方式相似,我在这里有介绍?python内建方法_potato123232的博客-CSDN博客
![]()
现在我们再看一下现在的图片数据集


4.3??创建标签数据集
![]()

4.4??创建图片+标签数据集(总数据集)
在这一步中我们要把刚刚的图片数据集和标签数据集合为一个数据集,我们使用tf.data.Dataset.zip()将两个数据集合并
![]()
- zip的参数是元组类型,如果不加小括号会报错


4.5??定义训练集与测试集
我们取上面创建的数据集一部分作为训练集,另一部分作为测试集,我们先看一下一共有多少张图片

![]()
我们可以使用20%的数据进行验证,其余图片进行训练,我们现在定义这两个数值,这里由于乘0.2可能会出现小数,我们的数量是不能有小数部分的,所以我们取整形部分


之后我们跳过总数据集的前test_count个数作为训练集,然后取前test_count作为测试集

- skip() 跳过,参数为要跳过的个数

5??设置重复,随机与batch
首先我们定义BATCHSIZE为16,这个和cpu性能相关,如果cpu性能好可适量增大,BATCHSIZE越大训练速度越快,BATCHSIZE对训练精度无影响
![]()
此处由于加入了重复,所以随机是有必要的(虽然我们上面对数据集加入了初始随机),因为如果不加入随机我们每次传入的图片顺序还是一样的,对最终训练的结果有不好的影响
![]()
- shuffle的参数名称为buffle_size是在多少个数据内进行随机的意思,batch的参数名称为batch_size,这两个参数没有关联
![]()
![]()
我们可以发现与上面的train_ds相比,train_ds加入了一个维度None,这个是因为我们加入了batch,我们每加入一次batch就会多出一个维度,所以我们要注意添加batch的次数
我们给测试集也加上batch,测试集不用加shuffle因为无论是否乱序都要测试,而且测试的顺序不影响最终的acc或loss,不用加shuffle就不用加repeat
![]()
![]()
![]()
6??创建模型
我们使用的网络为卷积神经网络,我们的网络是这样的

我们看一下这个模型的summary
![]()

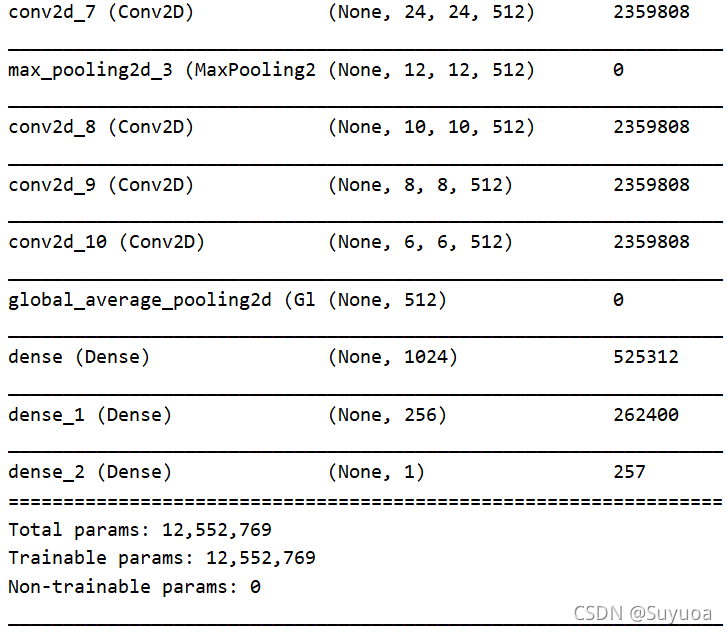
- 这个模型很像VGG模型,后面会提到
这里要注意下面几点
- 图像大小
我们卷积到最后图像大小为(6,6),这个时候依然可以使用(3,3)的卷积核进行卷积,但如果输出的图像大小小于卷积核大小,这个时候就不能继续卷积了,如果继续卷积会报错
![]()
- 最后一层的神经元个数
二分类我们最终输出一个结果就可以了,我们可以设置一个阈值(一般为0.5),大于或等于阈值我们判定为飞机,小于阈值我们判定为湖泊
![]()
7??编译模型

- 优化器
我们这里没有直接使用'adam'这个字符串,而是使用了tf.keras.optimizers.Adam(),我们使用后面的这种方法可以对优化器添加参数,如果使用前面的方式使用的就是默认参数,这里我们修改了学习速率,我们把学习速率搞小一点
- 损失
我们的所有loss存放在tf.keras.losses中,上面我们用的是大写的BinaryCrossentropy,这个和咱们之前直接输入字符串的效果相同,还有一种小写的,这个需要添加参数,我们现在暂时不用这个
![]()
如果我们进行多分类任务的话损失就要改成CategoricalCrossentropy
![]()
CategoricalCrossentropy有个参数是from_logits,如果我们在构建神经网络时最后一层没有激活函数,则from_logits就置为True,如果我们有激活函数就置为False

8??训练模型
首先我们定义训练集与测试集的每一个epoch所进行的批次数

之后我们使用fit()对神经网络进行训练

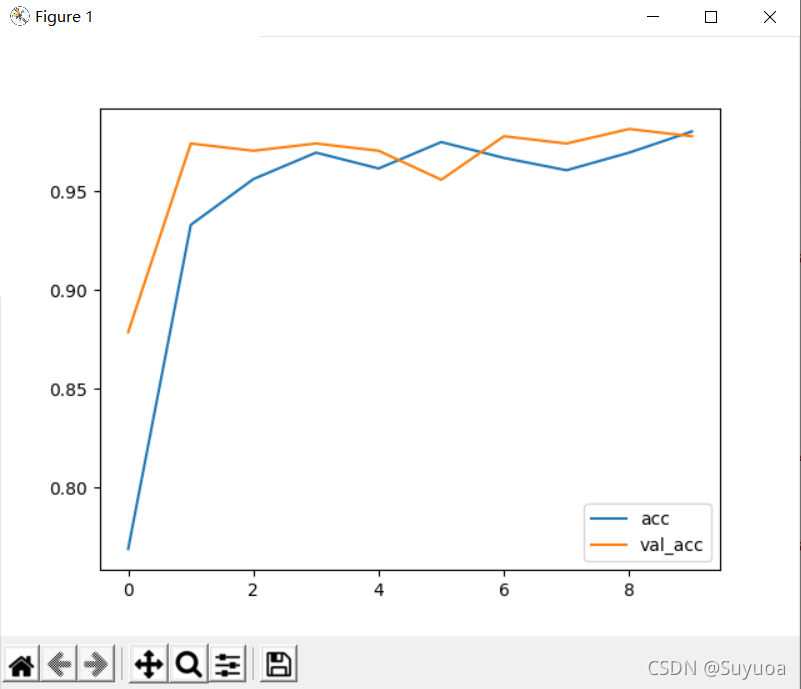
训练之后我们将结果绘制成曲线看一下情况
- acc

- loss

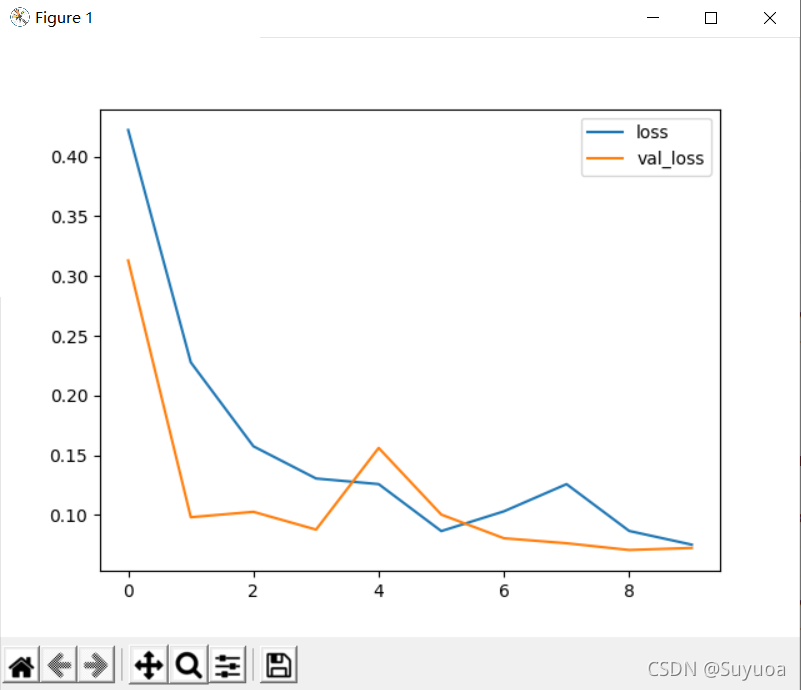
发现准确率已经超过了0.95,这个在实际生活中的某些场合中已经达到了可以使用的程度
9??保存模型
像这种CNN的模型训练的时间比较漫长,所以我们此处先简单介绍一下如何保存模型,训练后我们对训练好的模型进行保存,之后我们再次要使用到这个模型的时候就不需要再训练了
![]()
运行结束后会出现这样一个文件夹

里面有这些文件,这个就不在这里多介绍了,后面会具体的提到如何保存模型

10??读取模型
这个时候我们就再另一个新开的py文件中读取模型了

11??预测模型
我们先从百度上找一张飞机的图片与湖泊的卫星图片,当然我们也可以直接使用数据集中的图片,但是如果找原来的图片意义不大,因为从训练数据中找的图不能验证模型的成果

我们训练的数据怎么处理的原数据,在预测的时候也要对被预测图片进行一遍相同的处理,所以我们要再次使用一次上面定义的load_img()
首先定义load_img()
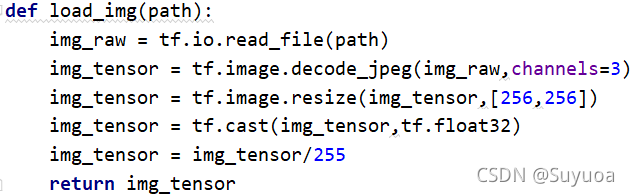
然后使用load_img()
![]()
我们看一下它的shape
![]()
![]()
发现shape是三维的,而我们训练时的图像是四维的,我们需要再提升一个维度
![]()
![]()
![]()
现在我们就可以进行预测了

![]()
我们发现得到了一个概率值,这个值越靠近1就是越像湖泊,越靠近0就越像飞机,那我们现在就可以直接进行判断了

![]()
为了方便我们现在把预测的过程也封装成一个函数

现在我们用这个函数预测一样刚刚湖泊的图片
![]()
![]()
如果想把图片展示出来,然后加上预测的文字,那么我们可以使用opencv,方法在这里可以找到?1.图像基本操作_potato123232的博客-CSDN博客_图像基本操作