- Unsupervised Conditional Generation
- StarGAN��Cycle GAN
- Maximum Likelihood Estimation(�����Ȼ����)
��ʮ��Unsupervised Conditional Generation
1������
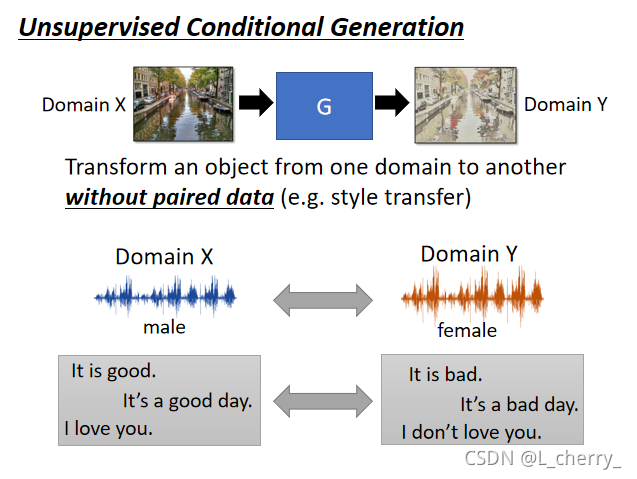
??����:��������һ��domain
X
X
X ��image,������real photo,����һ��domain
Y
Y
Y ��image,�����ǻ���,�������һ��generator������real photo,�������������training��ʱ���㲢����Ҫlabelled data,���Ƿ��ת����ʵ�ֹ���,ֻ������data,machine�Լ�ѧ����ô������һ��ת������һ�ѡ������ļ�����ֹ��������Ӱ����,����Ӧ����������������:
2��ʵ�ַ���
??Unsupervised Conditional Generation�����ַ���:
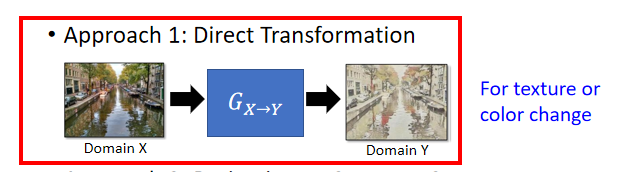
??Approach 1:Direct Transformation:ֱ��learnһ��generator,input Domain X�Ķ���,��취ת�� Domain Y,���ַ�����input��outputû�취��̫��,��������ת�����ܿ���ʵ��:
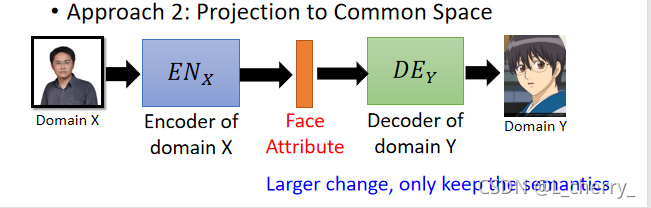
??Approach 2:Projection to Common Space:�����input��output���ܴ�,����˵Ҫ������ת�ɶ�������,��learnһ��encoder,��һ��������ͼ,Ȼ������������������,��������һ��decoder,���decoder���������Ƕ�������,������input��������������һ����Ӧ�Ľ�ɫ��
3������1��ϸ����
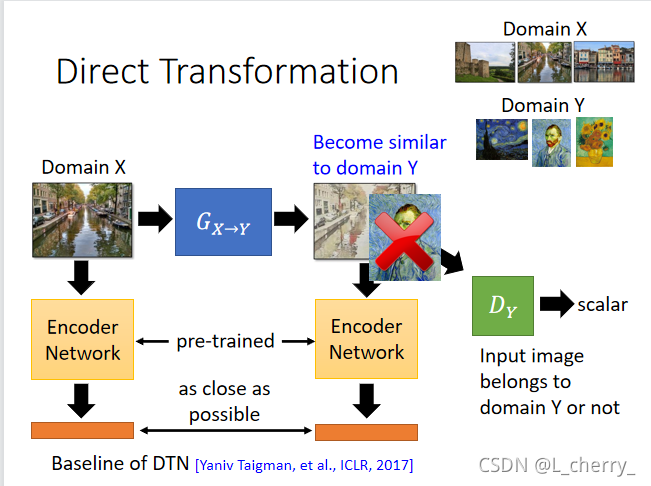
??(1)Approach 1:Direct Transformation������:
??learnһ��generator,���generator����Domain Xת����Domain Y,һ��Domain X��Domain Y������,û�������м��link�����ʱ����ҪDomain Y��discriminator�ҳ�Domain X��Ӧ�ĸ�Domain Y�����discriminator�����ܶ�Domain Y��image,���Ը���һ��image,�����ж���Domain X��image����Domain Y��image��������generatorҪ�������������취ƭ��discriminator��
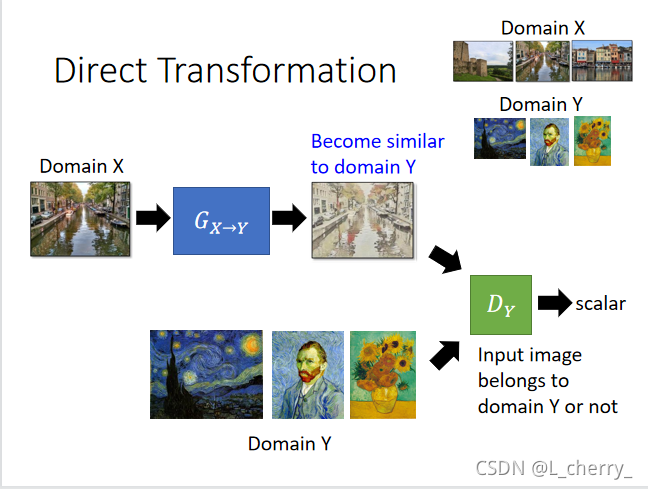
??���ڵ�������generator���Բ��������Ķ���,���ǿ�����ȫ����һ����input�صĶ���,����:

??�����������Dz�����Ҫgenerator�ܹ�ƭ��discriminator,����output���ܺ��Լ���input��һ���Ĺ�ϵ�������ֽ������:һ����ʵֱ��learnһ��generatorҲ�ǿ���work��,��Ϊmachine�����input��̫��;����������һ��train�õ�network,�����������generator��input��output�������pre-train��network,����������train��ʱ��,generatorһ������Ҫƭ��discriminator,һ����ϣ��pre-train��network������output��Ҫ��̫�ࡣ
??����circle GAN,trainһ��Domain X��Domain Y��generator,��trainһ��Domain Y��Domain X��generator(Ŀ����Ϊ����input��outputԽ��Խ��):
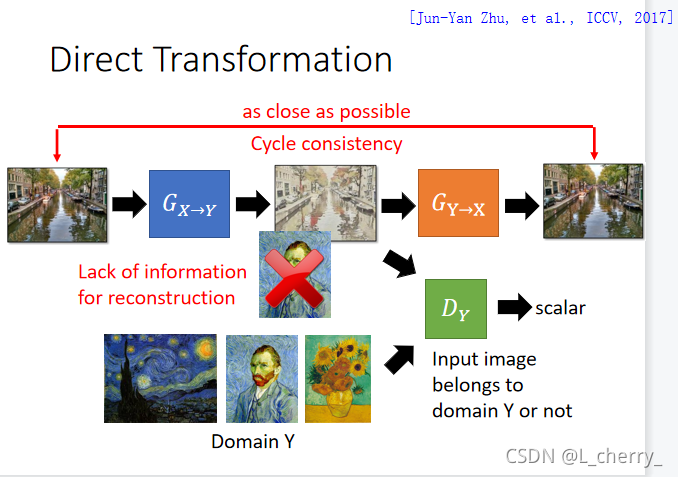
??���Cycle GANҲ������˫���,����һ��ͼtrain���GAN,��Domain Y��ͼ����ȥת��Domain X��ͼ,ͬʱdiscriminatorȷ�����generator��output��ͼ����Domain X��ͼ,��������Domain X��ͼת��Domain Y��ͼ,һ��ϣ��input��outputԽ�ӽ�Խ�á�Ȼ�����GAN�����ϵ�һ��train�ﵽ�õ�Ч��:
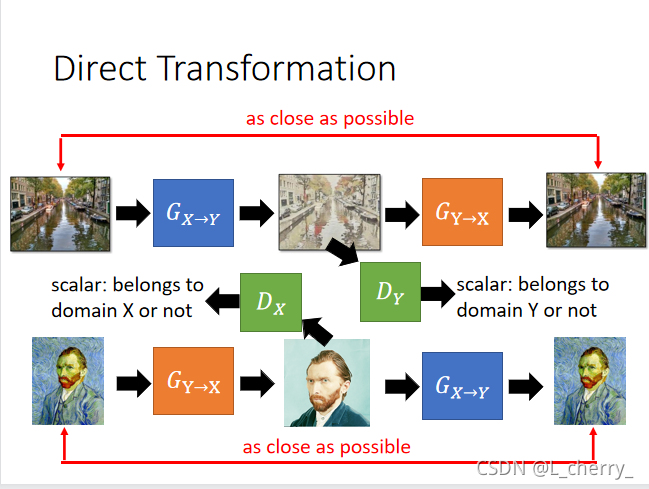
??
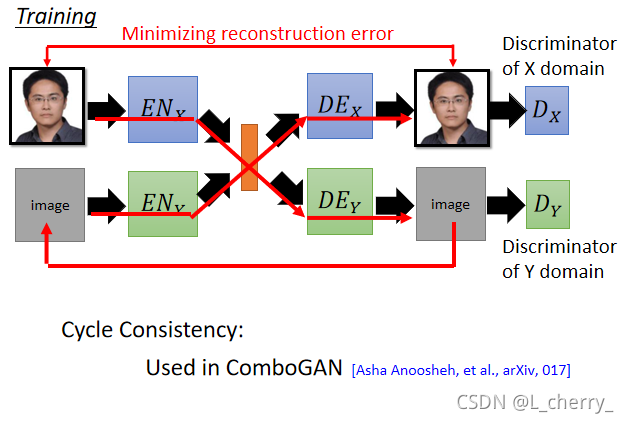
??Cycle GAN���ڻ���һЩ������û�н����:
??���input�Ķ���������,Ȼ����output��ʱ���ٳ��ֳ���,�����ᵼ����;��Щ��Ϣ�����ض����õ��ܺõĻ�ԭ:
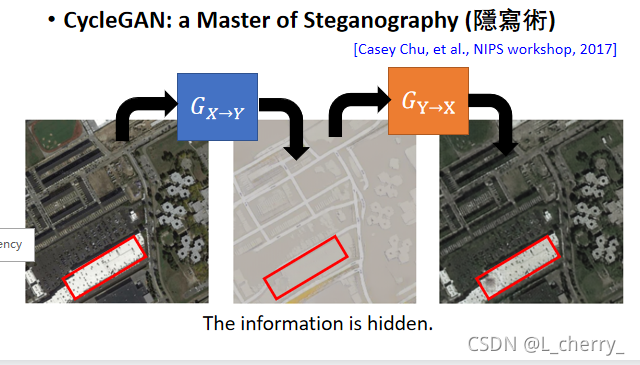
??����Cycle GAN,����Dual GAN��Disco GAN,�����ֺ�Cycle GAN�ķ���һ��,ֻ����ͬ����ʱ���ɲ�ͬ���������:
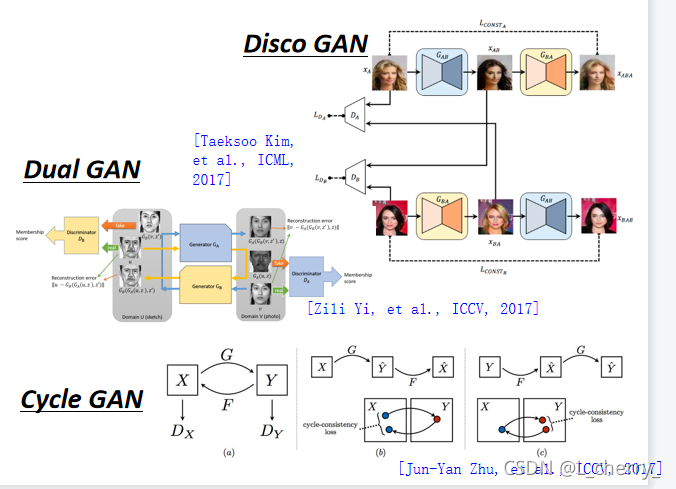
??StarGAN:����Cyle GAN��ʱ��ֻ�ܰ�Domain Xת��Domain Y,��ʱ���������������ж��Domain,��Ҫ�ö��Domain��ת������˵�����ĸ�Domain,��Ҫ���ĸ�Domain�以ת,�����������Ҫѡ���
C
4
2
C_{4}^{2}
C42?��transformation��network,StarGAN������������ֻlearn��һ��generator,�������ڶ��Domain�以ת��
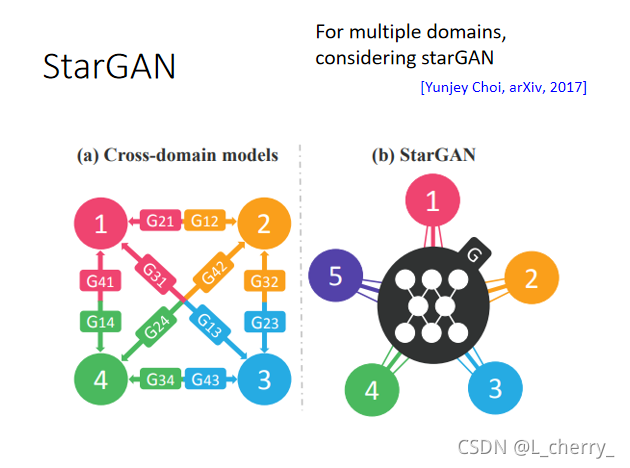
??StarGAN������:
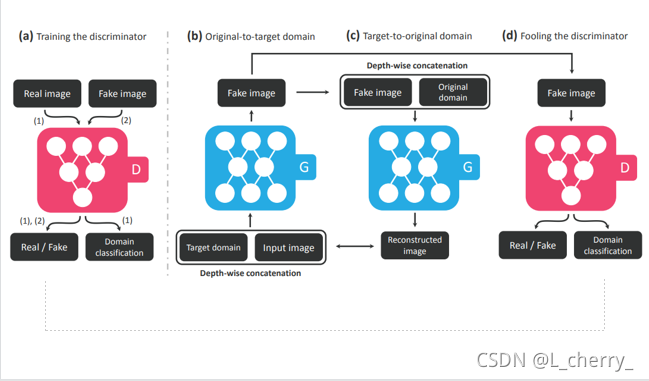
??paper�����:
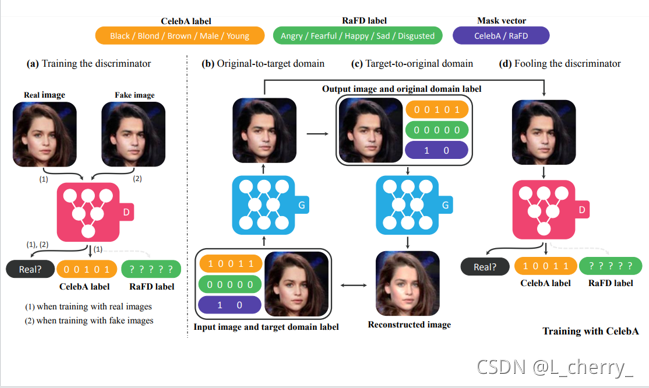
??
4������2��ϸ����
??(2)Approach 2:Projection to Common Space:����Ҫ��image project��һ��latent space,����decoder�����ϻ������������������Domain,���˵ĺͶ��������,��Ҫ������Domain��������ת��,��Ҫһ��Domain X��encoder,��������ͷ��Ͱ��������������,һ��Domain Y��encoder,������������ͷ��Ͱ��������������,������encoder�IJ��������Dz�һ���ġ�������������������������vector����decoder����,�������Domain X��decoder,��ô�õ��ľ�������ͷ��,��֮,�õ����Ƕ���Ԫ�����ͷ������ϣ�������������µ�����:
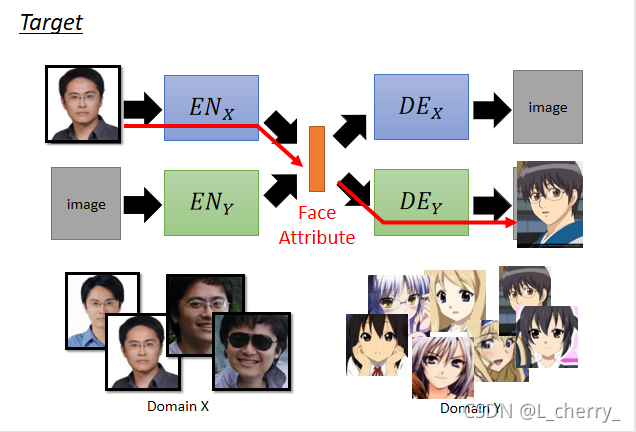
??����ʵ�������������Domain X��Domain Y֮��Ķ�Ӧ��ϵ,Ҫ��������·dz�����,����һ��supervised learning������,����������һ��unsupervised learning������,ֻ��Domain X��image��Domain Y��image,�����Ƿֿ���,��ôtrain��Щencoder��decoder?
??�������:encoder X��decoder X���������һ��auto-encoder,inputһ��Domain X��ͼ,��������reconstruct�ص�ԭ��Domain X��ͼ��ͬ��,��������Domain Y��ͼ��Ȼ����train��ʱ��minimize���ǵ�input��output��
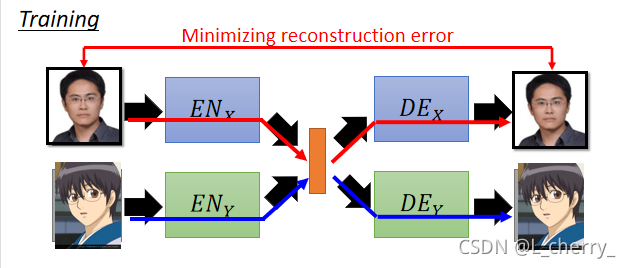
??�������ķ���ȷʵ���Եõ�����encoder������decoder,�����������������encoder������decoder��û�й�����,��������Ҫ��discriminator,�����Dz���ij��Domain��ͼ,������ǿ��Domain X��decoder��Domain Y��decoder���Ƚ�realistic��
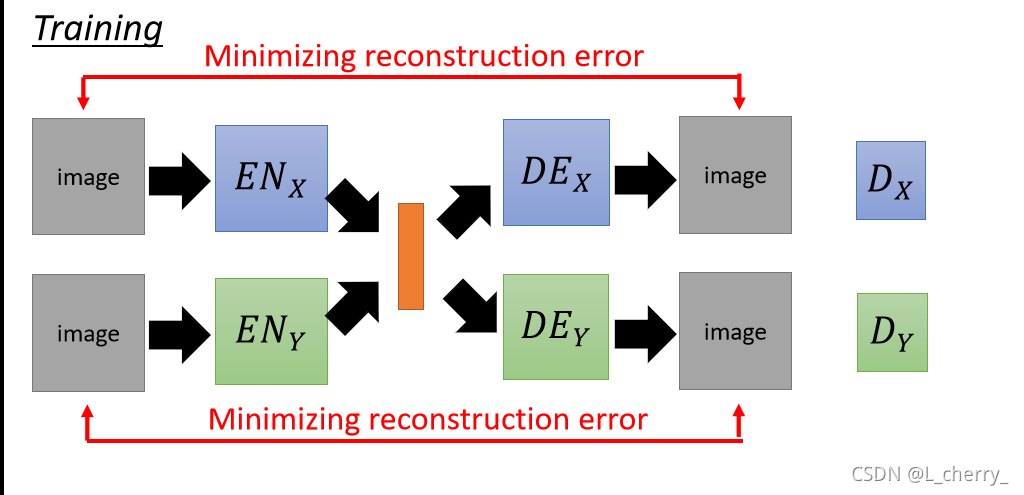
??��Ϊtrain������auto-encoder separately,������ͬ���Ե�ͼ����ܲ���ͶӰ��DZ�ڿռ��е���ͬλ�á����ܵõ����½��:
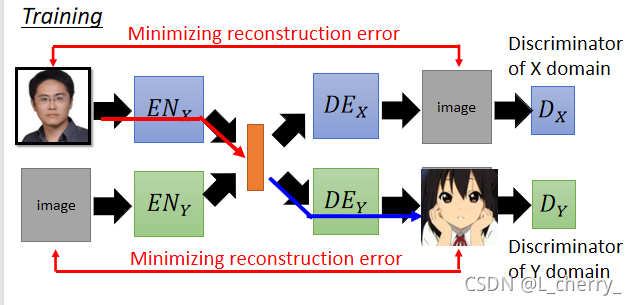
??�����Ľ������:�ò�ͬDomain��encoder��decoder���ǵIJ���tie��һ��,��������encoder������hidden layer�IJ����ǹ��õ�,����decoderǰ�漸��hidden layer�IJ����ǹ��õ�,���漸���Dz�һ���ġ�
 ??��Ľ������:(1)��һ��Domain��discriminator,���discriminator�����жϸ�����latent vector��������encoder X����encoder Y,Ҳ����˵ͨ��discriminatorǿ��������Domain��embedding ��latent feature��һ����,���Ǿͻ���ͬ����dimension����ʾͬ�������� :
??��Ľ������:(1)��һ��Domain��discriminator,���discriminator�����жϸ�����latent vector��������encoder X����encoder Y,Ҳ����˵ͨ��discriminatorǿ��������Domain��embedding ��latent feature��һ����,���Ǿͻ���ͬ����dimension����ʾͬ�������� :
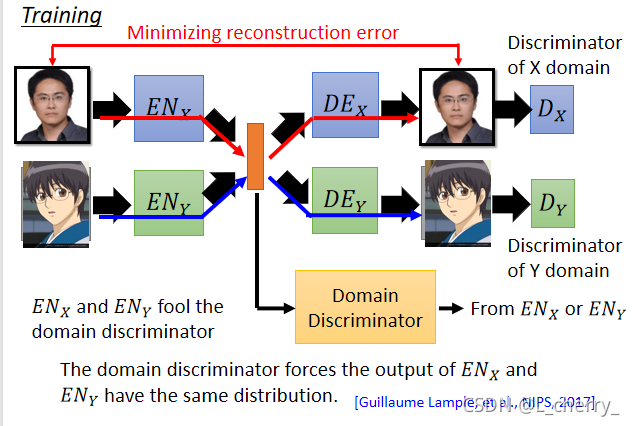
??(2)Cycle Consistency(ѭ��һ����):��һ��imageͨ��encoder X���code,��ͨ��decoder Y���������,Ȼ��ѵõ���image�ٶ���encoder Y,��ͨ��decoder X,���������,Ȼ��ϣ��input��outputԽ�ӽ�Խ�á�
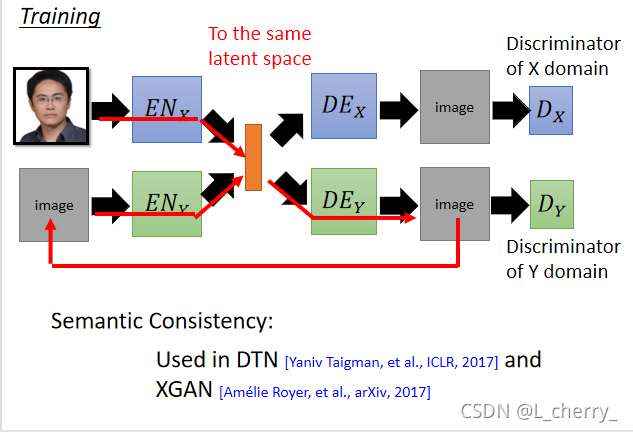
??(3)Semantic Consistency(����һ����):��һ��ͼƬ����encoder X,�������code,�����������code��encoder Y�����,�õ��Ľ������encoder Y,�õ�code,ϣ��ͨ��encoder X�õ���code��ͨ��encoder Y�õ���codeԽ�ӽ�Խ�á�
??
5��Ӧ��������
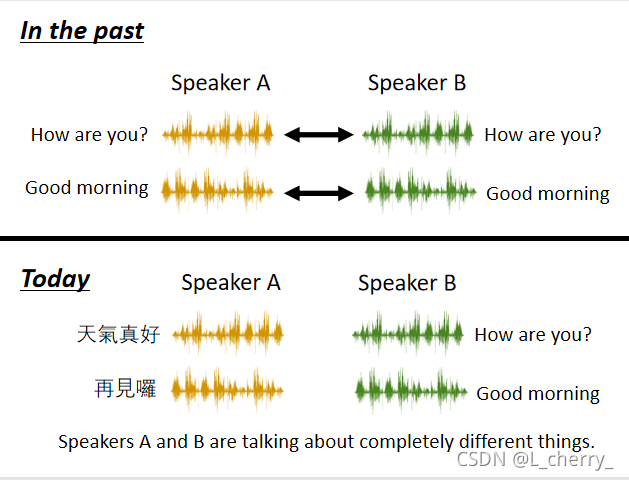
??Ӧ����Voice Conversion(����ת��),��A������ת��B��������
??
��ʮһ��Theory behind GAN
??GAN���Ǹ��ݺܶ�exampleȥ�������ɡ�
??�������û���ȥ�ҳ�������Ҫ�����ݵ�distribution:
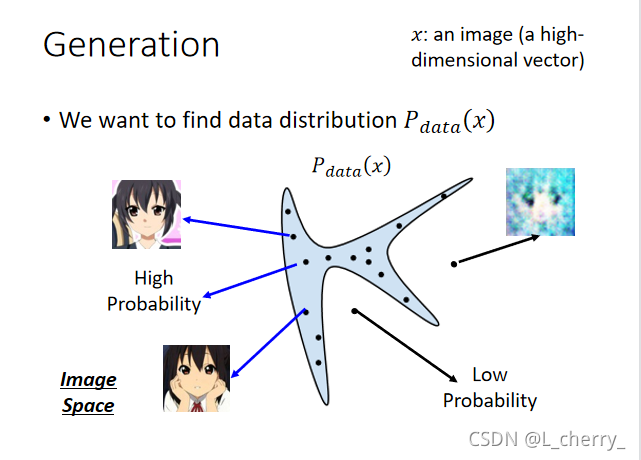
??����GAN֮ǰ��ô��generative�����?�CMaximum Likelihood Estimation(�����Ȼ����):
??(1)������һ��data��distribution
P
d
a
t
a
(
x
)
P_{data}(x)
Pdata?(x),���distributionʵ���ϳ�ʲô�����Dz�֪����,���ǿ��Դ����distribution����sample��һЩdata��
??(2)�����������Լ�ȥ��һ��distribution
P
G
(
x
;
��
)
P_G(x;\theta )
PG?(x;��) ,���distribution����һ�����
��
\theta
�� ���ٿص�:(��������һ��Gaussian Mixture Model,
��
\theta
�� ����means and variances of the Gaussians)������Ҫ�����������ʹ�����ǵõ���
P
G
(
x
;
��
)
P_G(x;\theta )
PG?(x;��)��
P
d
a
t
a
(
x
)
P_{data}(x)
Pdata?(x)Խ�ӽ�Խ�á�
??��������:

??
??Maximum Likelihood Estimation==Minimize KL Divergence(KLɢ��)

??�����һ���ܸ��ӵĶ���,����������,��û�а취��������likelihood,֮�������µ��뷨,��machine�Զ������µĶ�����
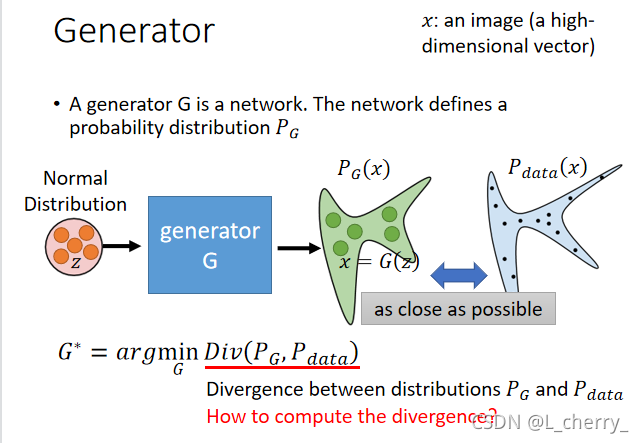
??����GAN����minimize divergence��������:

??����sample֮��,������ô֪��֪��������sample��divergence?�Cͨ��discriminator��

??һ����ѧʽ:
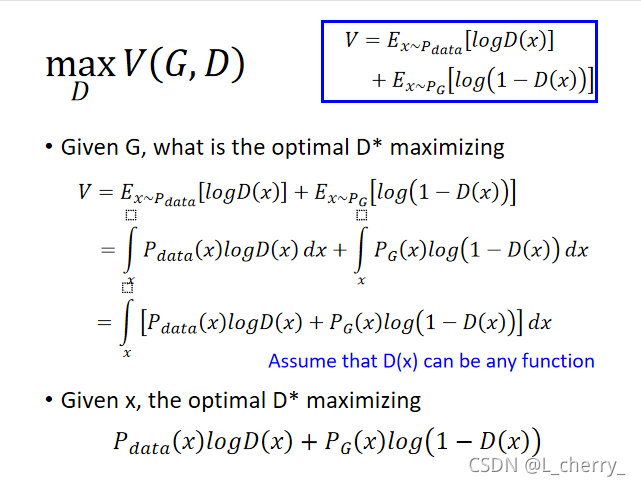
??
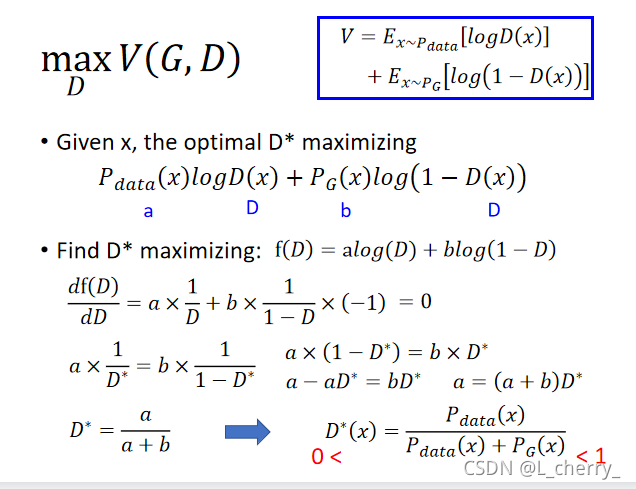
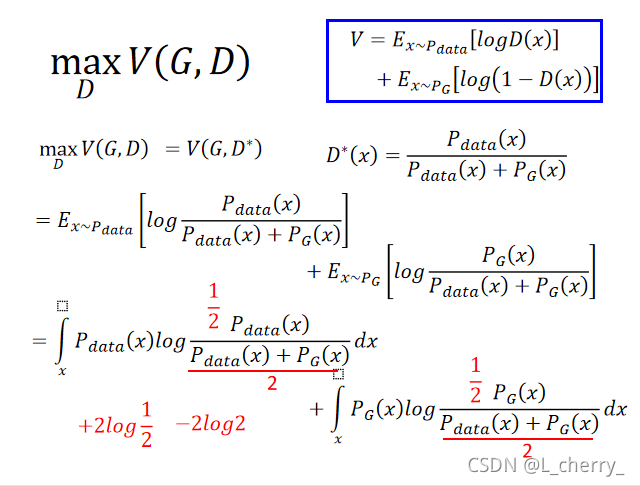
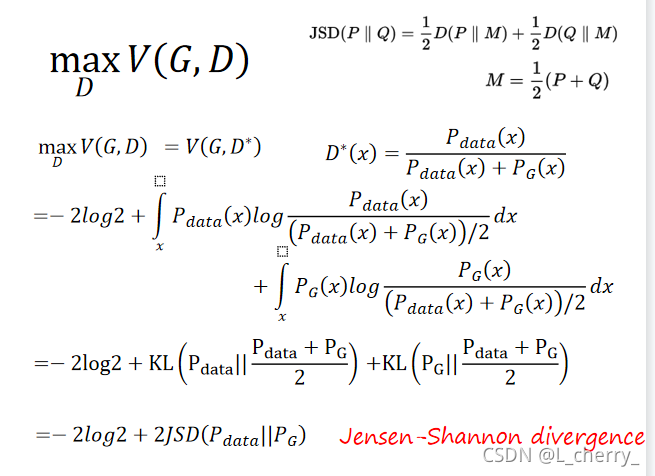
??����������:����������ʾ��
??��������취�����min-max��problem,��GAN�еĽⷨ��:

??������Ҫ�����optimization��problem,��Ҫ��ô��:
??���Ȱ����ʽ�Ӽ�д:
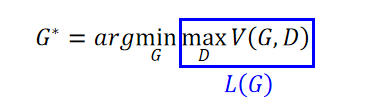
??���ڵ�����ͱ��,����ʹ��gradient descent:
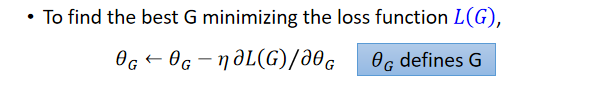
??����
L
(
G
)
L(G)
L(G)��������?
??���ԡ�
??������һ��function,���ǵ�ʽ�Ӻ���״����,��ô��������?����µ�ͬ������
x
x
x��������һ��function���:
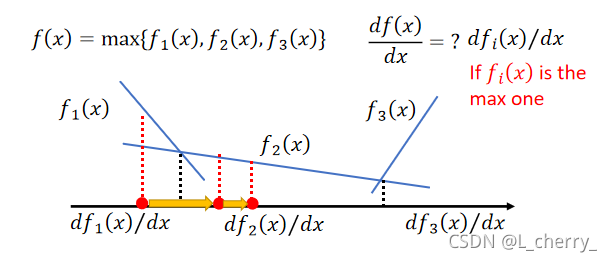
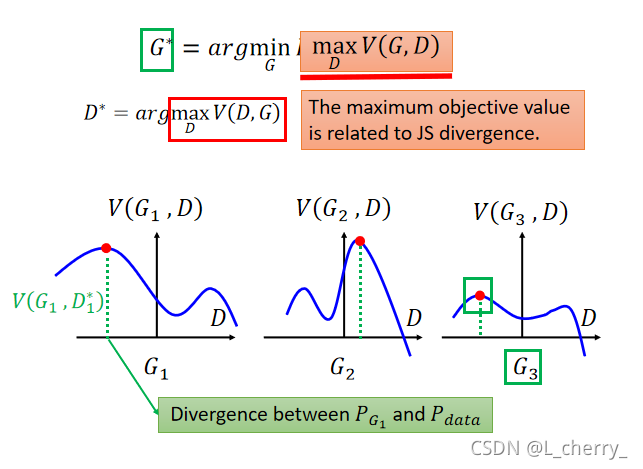
??�ص����ǵ�optimization problem:
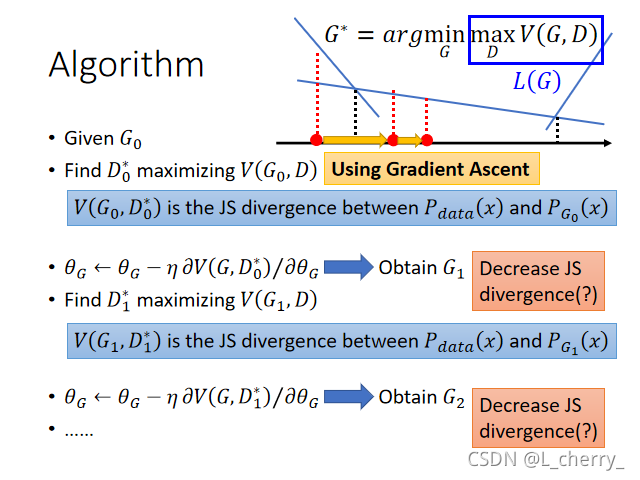
??������process��ʵ��GAN��һģһ����,����update����δ�ص�ͬ�������minimize JS divergence,����:
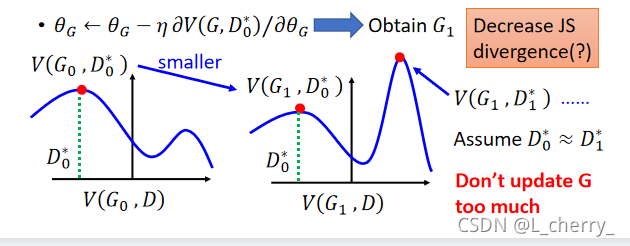
??ʵ��������GAN��ʱ������ʵ����ô����?
??ʵ����ֻ����Sample��������ʽ:
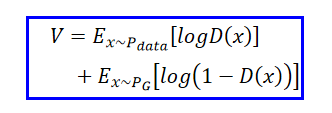
??

??���ϰGAN��algorithm:

??��ʵ����:

??
??
??
�����Ƕ�blibli����������ѧϰ2020���ܽ�,������Ȩ������ɾ����