最近学习了基于Pytorch框架下的MLP、CNN、RNN网络模型,利用在GitHub上获取的商品评论数据进行文本分类实验。本文介绍了如何在Pytorch框架下建立MLP对数据进行二分类,数据集大致如下:
1、导入模块
import pandas as pd
import numpy as np
import jieba
import keras
import re
import spacy
from keras.preprocessing.text import Tokenizer
import gensim
from gensim import models
from torch.nn.utils.rnn import pad_sequence
import torch
2、导入数据
data = pd.read_csv('./data.tsv',sep='\t',index_col=0).astype(str)
data.head()

3、文本数据预处理
3.1 数据清洗
首先需要对数据集进行常规的清洗处理,在实际电商平台中,有时会存在用户购买后没有评论,也会存在商家为了“刷单”自动对产品发布好评,所以需要分别对该文本数据进行缺失值检查、重复值检查并进行删除,减少对研究目的不必要的影响。同时,因为过短评论的研究价值不大,所以筛选掉了评论文本小于等于5的数据,上述清洗过程统一自定义打包成clean函数如下:
def clean(data):
#去除缺失值
Nan = data.dropna()
print("去除缺失值后:",Nan.shape)
#去除重复值
dup = Nan.drop_duplicates()
print("去除重复值后:",dup.shape)
#筛选评论文本数大于5的评论
clean_data = dup[dup['text'].str.len() > 5]
print("筛选掉评论文本数大于5的评论后:",clean_data.shape)
clean_data.reset_index(inplace=True)
return clean_data

运行后发现该数据不存在缺失值,但存在10条重复值,删除小于等于5的文本数据后剩余9702条评论。
3.2 分词并去除停用词
首先,需要排除文本中的数字、字母等不是中文字符的文本,利用re模块定义find_chinese函数如下:
#排除数字、字母等不是中文字符的数据
def find_chinese(file):
pattern = re.compile(r'[^\u4e00-\u9fa5]')
chinese = re.sub(pattern, '', file)
return chinese
for number in range(len(newdata)):
newdata[number]=find_chinese(newdata[number])
然后利用jieba模块对文本进行分词并把结果存入列表中,传入存有中文停用词数据的xlsx文件,用if判断语句来去除停用词(比spacy快多了…),这两步可以包装成函数如下:
#去除停用词
def del_stop(texts):
stop_words=pd.read_excel("stop_words.xlsx",header=None)[0].tolist()
texts = list(map(find_chinese,texts))
texts_temp = []
n = 0
for sentence in texts:
n += 1
doc = ''
sentence_list = jieba.lcut(sentence)
for word in sentence_list:
if word not in stop_words:
doc += word
texts_temp.append(doc[1:])
return texts_temp
#分词
def split_words(texts):
texts_temp=[]
for sentence in texts:
sentence_list=jieba.lcut(sentence)
texts_temp.append(" ".join(sentence_list))
return texts_temp
打印出结果列表前十项如下图所示:

3.3 文本向量化处理
因为实验的最终目的为对文本进行分类,所以需要把文本转换成数学表示方式――向量,即词嵌入技术。本文采用了Doc2Vec方法将文本中的每个词封装成向量表达方式,利用gensim模块中的Doc2Vec函数来进行训练,根据该函数输入参数的要求,需要把上面处理后的数据再转换一下:
words = []
for i in result:
a = i.split(' ')
words.append(a)
print(words[:10])
长这样:

然后需要再利用TaggedDocument函数对数据进行打标签:
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
train_docs = []
for i, text in enumerate(words):
document = TaggedDocument(text, tags=[i])
train_docs.append(document)
打完之后如下图所示:

tag了之后就可以扔进函数里进行训练啦~本文设置了向量维度vector_size为50,训练模型的线程数workers为4,训练迭代次数epochs为5:
model_dm = Doc2Vec(train_docs, dm=1, min_count=1, window=3, vector_size=50, sample=1e-3, negative=5, workers=4)
model_dm.train(train_docs, total_examples=model_dm.corpus_count, epochs=5)
因为该训练输出结果只是文本数据中每个词进行了向量化,需要合并原先的label值一起传入到MLP模型中进行训练:
doc_vec = []
for i in range(len(train_docs)):
doc_vec.append(model_dm.dv[i].tolist())
data = pd.DataFrame(doc_vec)
newdata = pd.concat([data,label],axis=1)
newdata.head(3)
newdata.to_csv('doc2vec.txt',sep = '\t',header = False)
向量化后长这样:

合并后的数据shape为9702行51列(最后一列为label),并把结果保存到本地txt文件中。
4、建立并训练模型
4.1 构建MLP网络
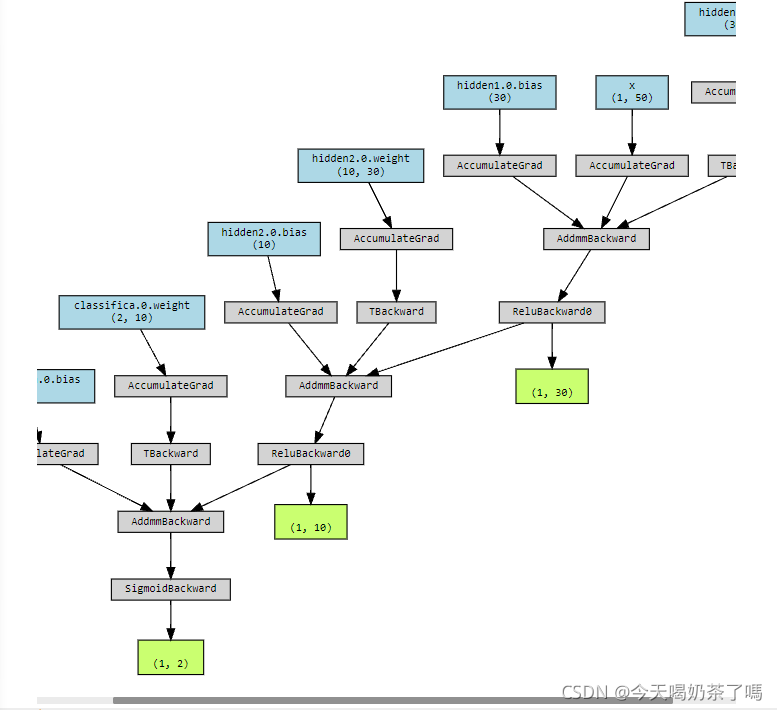
该部分是参考了书本和老师的代码,具体该MLP有两层隐藏层,一层分类层,并通过定义向前传播路径(具体细节就不解释啦):
import torch.nn as nn
import torch
import matplotlib.pyplot as plt
from torchviz import make_dot
class MLPclassifica(nn.Module):
def __init__(self):
super(MLPclassifica,self).__init__() ###继承父类的方法 https://blog.csdn.net/a__int__/article/details/104600972父类继承理解
#####定义第一个隐藏层
self.hidden1 = nn.Sequential(
nn.Linear(
in_features = 50, ####输入特征数量
out_features = 30, ####输出特征数量
bias = True, ###偏置
),
nn.ReLU()
)
#####定义第二个隐藏成
self.hidden2 = nn.Sequential(
nn.Linear(30,10),
nn.ReLU()
)
######分类层
self.classifica = nn.Sequential(
nn.Linear(10,2),
nn.Sigmoid()
)
#####定义向前传播路径
def forward(self, x):
fc1 = self.hidden1(x)
fc2 = self.hidden2(fc1)
output = self.classifica(fc2)
###输出为两个隐藏层和输出层
return fc1,fc2,output
mlpc = MLPclassifica()
##可视化
x = torch.randn(1,50,requires_grad = True)
y = mlpc(x)
Mymlpcvis = make_dot(y, params=dict(list(mlpc.named_parameters())+ [('x',x)]))
Mymlpcvis
对该网络可以通过可视化如下(貌似截不全):
4.2 训练模型
首先导入相关模块并把数据切分成训练集和测试集:
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
from sklearn.manifold import TSNE
X_train, X_test, y_train, y_test = train_test_split(np.array(newdata.iloc[:,:50]),
np.array(newdata.iloc[:,50]),test_size=0.25, random_state=123)
然后需要分别把训练数据和测试数据都转换成张量,转换后要把X和y合并起来,并定义一个数据加载器,将数据进行批量处理:
import torch.utils.data as Data
X_train_t = torch.from_numpy(X_train.astype(np.float32))
y_train_t = torch.from_numpy(y_train.astype(np.int64))
X_test_t = torch.from_numpy(X_test.astype(np.float32))
y_test_t = torch.from_numpy(y_test.astype(np.int64))
train_data = Data.TensorDataset(X_train_t,y_train_t)
train_loader = Data.DataLoader(
dataset = train_data ,
batch_size = 64 ,
shuffle = True, ###每次迭代前打乱数据
num_workers = 3, ##使用多进程加载的进程数,0代表不使用多进程
)
然后需要定义一个优化器,并使用Canvas进行结果可视化。最后开始训练该模型,设置训练迭代次数epoch为15:
###加载数据完善整个网络
from torch.optim import SGD,Adam
import seaborn as sns
import hiddenlayer as hl
###定义优化器
optimizer = torch.optim.Adam(mlpc.parameters(),lr=0.01)
loss_func = nn.CrossEntropyLoss() ###二分类损失函数
####记录训练过程的指标
history1 = hl.History()
####使用Canvas进行可视化
canvas1 = hl.Canvas()
print_step = 25
###对模型进行迭代训练,对所有数据训练epoch轮
for epoch in range(15):
##对训练数据的加载器进行迭代计算
for step, (b_x , b_y) in enumerate(train_loader):
##计算每个batch的损失
_, _, output = mlpc(b_x) ###MLP在训练batch上的输出
train_loss = loss_func(output , b_y) ####二分类交叉熵损失函数
optimizer.zero_grad() #####每个迭代的梯度初始化为0
train_loss.backward() #####损失的后向传播,计算梯度
optimizer.step() #####使用梯度进行优化
niter = epoch*len(train_loader) + step +1
if niter % print_step == 0:
_, _, output = mlpc(X_test_t)
_, pre_lab = torch.max(output, 1)
test_accuracy = accuracy_score(y_test_t, pre_lab)
## 为history添加epoch,损失和精度
history1.log(niter, train_loss=train_loss, test_accuracy=test_accuracy)
###使用两个图像可视化损失函数和精度
with canvas1:
canvas1.draw_plot(history1['train_loss'])
canvas1.draw_plot(history1['test_accuracy'])
结果如下:

可以看出测试集的准确率为0.78左右。
5、改进方向
1、本文在去除停用词方面使用的是固定的stopwords数据文件,对于不同主题的文本数据没有考虑到主题词对结果的影响
2、提高模型正确率可以参考提高向量维度、训练epoch次数等方面