��������ѧϰTask03
�����������ɹ�ע�ع�����,�漰��һЩ���ʺ����ֵ�����,�����϶��������ڽ�Щʲô��
���
�����������Դ:ƫ���뷽�
ƫ��
ƫ���������Ǹ���������ϳ���ģ�͵����Ԥ������������������ʵ����IJ��,��,��������������ϵĺò��á�Ҫ����ƫ���ϱ��ֺ�,��Ҫ��ģ�ͱ�ø���һЩ,���Ӳ���,��������������ϡ�
ƫ����ʱ��,������Ҫ���ǵ��������ȥ�Ľ��Լ���ģ��,�Ա�����Ϊ�����dz��˽���ǰ��CPֵ,��Ҫ����һЩ�߶�����������,��ʱȥ�ռ������������ʵ���岢����
����
������������������ѵ��������ģ���ڲ��Լ��ϵı���,Ҫ���ڷ����ϱ��ֺ�,��Ҫ��ģ�͡�������������Ƿ��ϡ�
�������,���ǵķ����Ƚϼֱ�,���ǿ��Ի�ȡ���������,�����ܶ�ʱ�����ֻ������������,��ʱ�������������������ݼ���������
ģ�͵�ѡ��
���ݿ�������,�Ҹ�������ƫ��ͷ����ڶ����пɵ�ģ������һ��ì��,���ǵ����������ҵ�һ��ƽ���,�ܹ�ͬʱ�õ��ϵ͵�ƫ���뷽��,ʹ����������С��

��ѡ��ģ�͵�ʱ��,��Ҫ����Ϊ���Լ���ͷ�IJ��Լ��б�����õ�ģ�;���ʵ������õ�ģ��,��ʵ�����㲢û����ʵ�IJ��Լ�,���ģ�;�����β��������
��������ͨ�����������������������,�γ����ṩ��һ�ֽ�����֤�ķ�����
������֤
������֤���ǽ�ѵ������Ϊ������,һ������Ϊѵ����,һ������Ϊ��֤������ѵ����ѵ��ģ��,Ȼ������֤���ϱȽ�,ȷʵ����õ�ģ��֮��(����ģ��3),����ȫ����ѵ����ѵ��ģ��3,Ȼ������public(��ͷ��)�IJ��Լ����в��ԡ����Ƽ����ò��Լ���������ȥ��ģ����������С��
n�۽�������
���ǵ����η�����żȻ��,���ǿ��Զ�η��顣
�����е�ѵ�����е����ݶ�η���,ÿ���������������ѵ��,һ��������֤,����ÿһ�����Ƕ��ܵõ�һ���������ø���ģ����������ı���ȡһ����ֵ,���ȡ��һ������ֵ��С��ģ�͡�
��̸�ݶ��½�
�ϴ������������Ѿ��Ӵ����ݶ��½��ķ���,�ݶ��½������ҳ�ģ��������ʵIJ���,���ογ������������֪ʶ��
�ݶ��½�����ѧԭ��
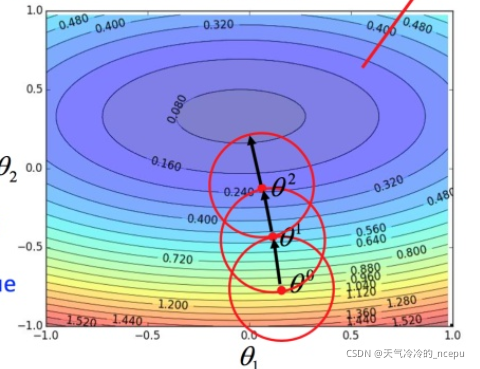
ʵ��������Ҫ���Ĺ����������ȡһ����,Ȼ��һ��Ȧ,�����Ȧ��ȥ����ʧ������С�ĵ�,���ҵ��ĵ��ٻ�Ȧ�ҵ�,�������������Ϳ��Խ���ʧ��������Сֵ�ҵ���
��ô����Ĺؼ�����������ҵ���ʧ����ֵ��С�ĵ㡣
̩��չ����
̩��չ���Ǹ�����ѧ����֪ʶ,�ǵõ�ʱ����ĥ������,���ﲻ�ٸ�����
���ǿ�����Ȧ�ڽ���ʧ����̩��չ��һ��(��ȥ����ĸ߽���):
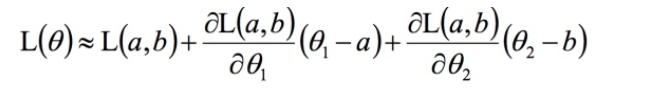
������ֵ��С,��һ��Ϊ��ֵ,ʵ���Ͼ��Ǻ�����ԽС,Ҳ������������(����1,����2 ) �� (L���ڦ�1ƫ��,L���ڦ�2ƫ��) ���ڻ���С,�����������������෴��
�����Ϳ����Ƴ��ݶ��½��Ĺ�ʽ��
���������ַ����ҵ����ʽ���и�ǰ��,̩��չ��ʽ������ʧ�����Ĺ���ֵ��Ҫ�㹻��ȷ��,������Ҫ��ɫ��ȦȦ�㹻С(Ҳ����ѧϰ���㹻С)����֤����Ҳ��֮ǰ��������Ҫ��֤Сѧϰ�ʵ��Ʋ�ȽϷ��ϡ�
������ǿ���̩�չ�ʽ�еĶ�����,�ᷢ�ֶ��˺ܶ�����,����ϲ���Ҳ����,���Ի�������һ�㶨��
ѧϰ�ʵ�ȡ��
ͨ��ԭ��������֮ǰ��ʵ��,�����ܹ�����ѧϰ��ֵ��һ���dz��ؼ��IJ���,ֱ�ӹ�ϵ���ܷ��ҵ��Ǹ�f*��
Adagrad����Ӧ�㷨
ÿ��������ѧϰ�ʶ���������֮ǰ�ֵľ�������
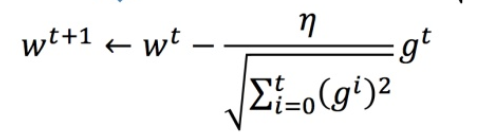
Adagrad������
�� Adagrad ��,���ݶ�Խ���ʱ��,���µ�ֵӦ�ø���,�������ĸ�ֵ����ݶ�Խ���ʱ��,���µ�ֵ��ԽС��
�������
����ʦ����һ�����κ��������ӿ�ʼ,���Ƿ���������������Խ��,�������͵�ԽԶ��������õ��´θ��µ�ֵ�Ĵ�С��һ�����ȡ���Ѿ���:
�O
2
a
x
0
+
b
2
a
�O
|\frac{2ax_0+b}{2a}|
�O2a2ax0?+b?�O
ͬʱ�����ڶ�����½��۲�������
ͬʱ�۲쵽һԪ����·�ĸ��2a���Ǻ����Ķ���,����ֹ��һ���ֳ�����,���Ͷ����ֳɷ��ȡ�
һ
��
��
��
��
��
\frac{һ����}{������}
������һ����?
��õIJ���Ӧ�ÿ��ǵ������֡�����
��
i
=
0
t
g
i
2
\sqrt{\sum_{i=0}^{t}g_i^2}
��i=0t?gi2?? ����ϣ���ھ����ܲ����ӹ�������������ģ������֡�
����ݶ��½���
��ʧ��������Ҫ����ѵ�������е�����,ѡȡһ������
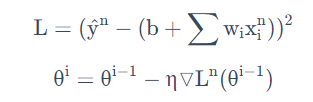
��ʱ����Ҫ��֮ǰ���������е����ݽ��д���,ֻ��Ҫ����ijһ�����ӵ���ʧ����,�Ϳ��ԸϽ�����ֵ��
��������
��������ķֲ��ķ�Χ�ܲ�һ��,��������ǵķ�Χ����,ʹ�ò�ͬ����ķ�Χ��һ���ġ�
�����������ڶ�Ԫ������¿���,����������ֲ��ķ�Χ���ܴ�ʱ,��Ӧ�IJ���Ӱ����ʧ����Ч���ͻͬ,�����������������Ҫ�ġ�
�������ŵķ����ܶ�,���ογ���������,���巽���д�����������ѧϰ��