做结构方程的时候分组比较用的比较多,咨询的同学也多,之前写过mplus的做法,今天就再给大家写个用R的,不论你是做中介还是做验证性因子分析,等等,反正用结构方程能做的都可以套这个方法,而且在R语言的lavaan包中,分组比较的做法也是非常简单的,今天就带大家来了解下。
为何要分组比较
很多时候我们会关心,某结构方程中的某条系数是不是存在组间差异,比如说性别差异,年龄差异,文化差异(跨文化),这个时候我们想做的是整个模型系数的比较,你想要单因素分析?搞个T检验?再搞个卡方,弄个回归?都是行不通的。
这个时候就得求助与模型的分组比较,比如大家去看下面这个文章:
- Liu, Yiming, Jerry C. Sun, and Ssu-Kuang Chen. "Comparing Technology Acceptance of AR-Based and 3D Map-Based Mobile Library Applications: A Multigroup SEM Analysis."?Interactive Learning Environments, 2021.
它回答的问题有两个,一个是什么因素影响移动图书馆的使用(这个问题直接拟合结构方程就行),另外一个问题就是不同组间系数是不是不同。对于第二个问题的回答,作者就是用的分组比较。这样的文章有很多,大家都可以搜搜看。
潜变量比较之前依然是涉及到一个东西叫做测量不变性。
测量不变性的做法
测量不变性之前也有给大家仔细地写过两篇文章,大家可以去翻翻哈(之前写的是纵向数据有个残差等值,此处忽略),这儿主要写做法:
一般来讲我们做测量不变性都是有固定顺序的,首先是configural invariance(构形不变性),然后是weak invariance(单位等值)然后是strong invariance(尺度等值)。大家不要记中文一定要把这几个英文记住,因为中文好像很不统一。
具体地,组间相同的因子结构就意味着configural invariance是成立的,载荷相同就意味着weak invariance是成立的,最后载荷和截距如果都相同则strong invariance是成立的,看一个例子:
测量不变性一定是通过验证性因子分析来做,分别设定不同的测量不变性水平,然后进行模型的比较就可以识别出我们的数据到底符合测量不变性的哪一个水平了。下面这个例子就是分别进行了configural invariance(构形不变性),然后是weak invariance(单位等值)然后是strong invariance的拟合:
HS.model <- ' visual =~ x1 + x2 + x3
textual =~ x4 + x5 + x6
speed =~ x7 + x8 + x9 '
fit1 <- cfa(HS.model, data = HolzingerSwineford1939, group = "school")
fit2 <- cfa(HS.model, data = HolzingerSwineford1939, group = "school",
group.equal = "loadings")
fit3 <- cfa(HS.model, data = HolzingerSwineford1939, group = "school",
group.equal = c("intercepts", "loadings"))
lavTestLRT(fit1, fit2, fit3)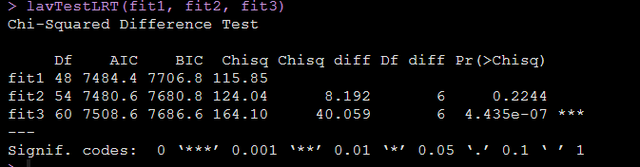
那么在我们这个例子中就可以看到,用德尔塔卡方看的话,fit1和fit2是没有显著差异的,所以我们的数据是符合weak invariance的。因为fit3和fit2之间的差异显著了,所以fit3没有fit2好,那么本例数据中组间的测量不变性就只是符合weak invariance并不符合strong invariance。
Because the first p-value is non-significant, we may conclude that weak invariance (equal factor loadings) is supported in this dataset. However, because the second p-value is significant, strong invariance is not. Therefore, it is unwise to directly compare the values of the latent means across the two groups
多组比较实例解析
论文中因为具体的研究问题,它做的是结构部分路径系数的比较,这儿我依然是给大家写个最简单的测量部分的比较。我现在有来自两个学校的301个观测数据,数据大概长这样:
这些观测都是来自两个学校的,我现在想以学校school进行分组评估不同学校验证性因子分析的结果一致性,我就可以写出如下代码:
HS.model <- ' visual =~ x1 + x2 + x3
textual =~ x4 + x5 + x6
speed =~ x7 + x8 + x9 '
fit <- cfa(HS.model,
data = HolzingerSwineford1939,
group = "school")
summary(fit)运行上面的代码你就可以发现,验证性因子分析的结果都是分组展示的。这个就是分组比较的常规操作,同学们做的比较多的会是将所有组间的某个系数进行固定,怎么做呢?接着往下看:
首先我们可以通过给系数打标签的方式进行系数的固定,这个是自由度很高,但是比较麻烦的方法,比如我想将两组间验证性因子分析的某个载荷进行固定,固定为组间相同。我就可以写出如下代码:
HS.model <- ' visual =~ x1 + x2 + x3
textual =~ x4 + x5 + c(codewar,codewar)x6
speed =~ x7 + x8 + x9 '上面的这个代码就将组间的x6的系数都固定为了codewar,当然这个codewar都是可以换的哈,你换成你的名字都是无所谓的,只要是一样的就行,就表示我限制两组间x6的载荷必须是相同的,那么结果如下:
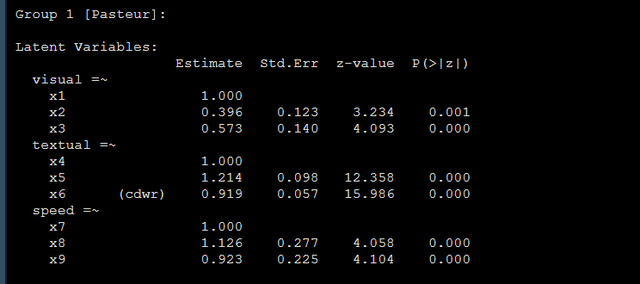
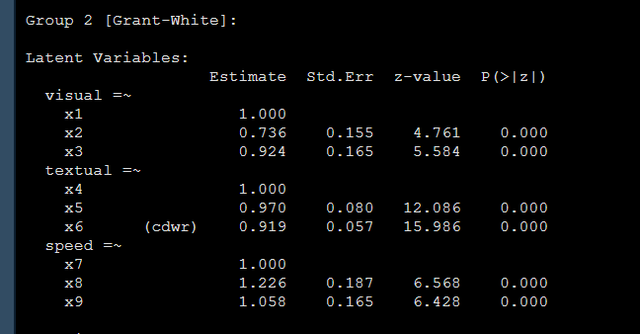
两个组的相同标签的系数,在我们的例子中x6的载荷系数都是0.919,
上面给大家写的是实现方法一,我们再看一个更加便捷的,很多同学还有将组间的所有载荷,或者某几条路径都固定为相同,论文中做组间比较的第二步就是将所有路径系数全部设定为组间相同,得到了一个fully constrained model,像这样的需求在R语言中也可以很快地实现。
大家在拟合模型的时候记住另外一个参数group.equal,比如你想将组间的因子载荷固定为相同你直接设定group.equal参数就可以,看代码:
HS.model <- ' visual =~ x1 + x2 + x3
textual =~ x4 + x5 + x6
speed =~ x7 + x8 + x9 '
fit <- cfa(HS.model,
data = HolzingerSwineford1939,
group = "school",
group.equal = c("loadings"))
summary(fit)运行上面的代码你就会发现组间的所有因子载荷都被自动打上了标签,两组间的相同因子载荷都是相同的。
这儿我只是给大家写了固定载荷的方法,也就是group.equal参数的其中一个取值,还有很多可以固定的部分,请同学们参见下图,自己尝试一波:

一般情况下,group.equal参数还会和group.partial参数结合起来适用,使得我们做组间比较的时候更加的高效。
作者做了一个unconstrained model,又做了一个fully constrained model,发现fully constrained model是显著地差于unconstrained model的,就说明路径系数一定存在组间不一致,然后通过路径系数的释放-比较-释放的循环过程,最终发现了组间到底是那条系数不一致的。至此,论文的问题2也就解决了。
小结
今天给大家写了结构方程模型的组间比较问题,回顾了一下测量不变性的做法,希望对大家有所帮助。感谢大家耐心看完,自己的文章都写的很细,代码都在原文中,希望大家都可以自己做一做,请转发本文到朋友圈后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先收藏,再点赞分享。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦,另欢迎私信。