ЫуЗЈЗжЮі
е§ЯђзюДѓЦЅХфЗЈ,ЖдгкЪфШыЕФвЛЖЮЮФБОДгзѓжСгвЁЂвдЬАаФЕФЗНЪНЧаЗжГіЕБЧАЮЛжУЩЯГЄЖШзюДѓЕФДЪЁЃе§ЯђзюДѓЦЅХфЗЈЪЧЛљгкДЪЕфЕФЗжДЪЗНЗЈ,ЦфЗжДЪдРэЪЧ:ЕЅДЪЕФПХСЃЖШдНДѓ,ЫљФмБэЪОЕФКЌвхдНШЗЧаЁЃИУЫуЗЈжївЊЗжСНИіВНжш:
ИУЫуЗЈжївЊЗжЮЊСНИіВНжш:
1ЁЂвЛАуДгвЛИізжЗћДЎЕФПЊЪМЮЛжУ,бЁдёвЛИізюДѓГЄЖШЕФДЪГЄЕФ
ЦЌЖЮ,ШчЙћађСаВЛзузюДѓДЪГЄ,дђбЁдёШЋВПађСаЁЃ
2ЁЂЪзЯШПДИУЦЌЖЮЪЧЗёдкДЪЕфжа,ШчЙћЪЧ,дђЫуЮЊвЛИіЗжГіРДЕФДЪ,ШчЙћВЛЪЧ,дђДггвБпПЊЪМ,МѕЩйвЛИізжЗћ,ШЛКѓПДЖЬвЛЕуЕФетИіЦЌЖЮЪЧЗёдкДЪЕфжа,вРДЮбЛЗ,ж№ЕНжЛЪЃЯТвЛИізжЁЃ
3ЁЂађСаБфЮЊЕк2ВНжшНиШЁЗжДЪКѓ,ЪЃЯТЕФВПЗжађСа
НгЯТРДЭЈЙ§вЛИіЪЕСІИјДѓМвНВНтОпЬхВйзїЁЃ
аЮЯѓЛЏбнЪО
ЪзЯШЮвУЧашвЊбЁШЁвЛИізюДѓЕФНиШЁГЄЖШ,ЭЈГЃЮвУЧбЁШЁДЪЕфжаЕЅИіЗжДЪЕФзюДѓГЄЖШ,дкШчЯТАИР§жа,зюГЄЕФЗжДЪЮЊ(жаЙњШЫ)ГЄЖШЮЊШ§,ФЧЮвУЧУПДЮОЭШЁШ§ИізжЗћРДНјааЗжДЪ

ДгзѓВрПЊЪМбЁжаЧАШ§ИізжЗћНјШыДјЗжађСа

ХаЖЯДЫЪБИУађСаЪЧЗёДцдкгкИјЖЈЕФДЪЕфжаЁЃКмвХКЖЁАЮвЪЧжаЁБВЛдкДЪЕфжа,ФЧУДДггвВрПЊЪМНЋзюКѓвЛИізжЗћДгД§ЗжађСажаЩОШЅ

КмвХКЖ,ЁАЮвЪЧЁБвРШЛВЛдкЗжДЪДЪЕфжа,МЬајДггвВрЩОШЅзжЗћ

ШчЩЯЭМЫљЪО,ШєД§ЗжађСаЕФГЄЖШЮЊ1,дђХаЖЈЮЊЕЅИіДЪ,НЋЦфДцШывбЗжСаБэжа,ВЂДгД§ЗжађСажаЩОГ§,дкЪЃгрЕФађСажажиаТзщНЈД§ЗжађСа,МЬајЯТвЛТжЗжДЪ

ОЙ§МИТжбЛЗ,ЫљгаД§ЗжађСаГЄЖШЮЊСу,ЕУЕНСЫвЛИіЗжДЪНсЙћ,ШчЯТЭМЫљЪО

ДњТыЪЕЯж
dict.txtЮФМў(дкетРяжЛЪЧеЙЪОСЫМђЕЅАцЕФДЪЕф,ПЩвдздМКжЦзїШЮвтДЪзщЛђепДгЭјеОЯТди)
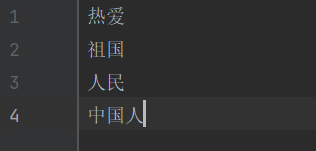
#ДДНЈзжЕфСаБэ
dic = []
def init():
"""
ЖСШЁДЪЕфЮФМў
диШыДЪЕф
:return:
"""
with open("dict.txt", encoding="utf8") as dic_input:
for word in dic_input:
dic.append(word.strip())
#ЪЕЯже§ЯђзюДѓЦЅХфЗЈ
def cut_words(raw_sentence, word_dic):
#ЭГМЦДЪЕфжжзюГЄЕФДЪ(ШєаЁгкД§ЧаЗжзмГЄЖШ,дђУПДЮДгЮДЦЅХфДІеветУДГЄЕФзжЗћДЎПЊЪМЦЅХф)
max_length = max(len(word) for word in dic)
sentence = raw_sentence.strip() #вЦГ§зжЗћДЎФкЕФПеИё
#ЭГМЦађСаГЄЖШ
words_length = len(sentence)
#ДцДЂЧаЗжКУЕФДЪгя
cut_word = []
while words_length > 0:
max_cut_length = min(max_length, words_length)
#ДДНЈД§ЗжађСаsub
sub = sentence[0 : max_cut_length]
#НјаавЛТжЗжДЪ,дкзѓВрЧаГівЛИіДЪ
while max_cut_length > 0:
if sub in dic: #ШєД§ЧаЗжЕФДЪдкДЪЕфжа,дђНЋЦфМгШывбЗжСаБэ,ЬјГібЛЗ
cut_word.append(sub)
break
elif max_cut_length == 1: #ЪЃЯТЕЅИізж,НЋЦфЧаЗж,ВЂЬјГібЛЗ
cut_word.append(sub)
break
else: #ЖМВЛЗћКЯдђДггвВрШЅЕєвЛИіДЪ,жиаТЗжДЪ
max_cut_length = max_cut_length - 1
sub = sub[0 : max_cut_length]
#НЋЧаЕєЕФЕЅДЪЩОШЅ
sentence = sentence[max_cut_length:]
words_length = words_length - max_cut_length
words = "/".join(cut_word)
return words
def main():
"""
гкгУЛЇНЛЛЅНгПк
:return:
"""
init()
while True:
print("ЧыЪфШыФњвЊЗжДЪЕФађСа")
input_str = input()
if not input_str:
break
result = cut_words(input_str, dic)
print("ЗжДЪНсЙћ:")
print(result)
if __name__ == '__main__':
main()
аЇЙћеЙЪО
ЪфШыађСа:ЮвЪЧжаЙњШЫ,ЮвШШАЎЮвЕФзцЙњ
ЗжДЪНсЙћ:Юв/ЪЧ/жаЙњШЫ/,/Юв/ШШАЎ/Юв/ЕФ/зцЙњ/КЭ/ШЫУё
