����
��һ�� ��״:������ʵ?
�ڶ��� δ��:һֻ��ѻ�����ǵ���ʾ?
������ ��ʷ:�ӡ�������ԡ�����ս�����ۡ�?
���Ľ� ͳһ:��С���ݡ�������ʽ����֪����?
����� ѧ��һ:�����Ӿ� �� �ӡ����������?
������ ѧ�ƶ�:��֪���� �� �߽���������?
���߽� ѧ����:����ͨѶ �� ��ͨ����֪����?
�ڰ˽� ѧ����:�������� �� ��ȡ����������ļ�ֵ��?
�ھŽ� ѧ����:������ѧ �� ����������ƽ̨?
��ʮ�� ѧ����:����ѧϰ �� ѧϰ���ռ������롰ͣ�����⡱?
��ʮһ�� �ܽ�: ���ܿ�ѧ �� ţ�������ĵ�ͳһ
��¼ �п�Ժ�Զ�����������ϵ��ʴ��뻥��ժ¼?
��л
����
���˹����ܡ���������ڳ����˽�30��֮��,������ꡰ���㷭����,��Ϊ�˿Ƽ���˾���ص�ս��������ý�������ķ��,����ܵ����������Ӻ�Ͷ�ʽ����������,���ŷ����ᡢ�߷���̳�������,����ս�Թ滮��̨,��������Ӧ�Ӳ�Ͼ,����һ��������Ϊ����ʱ���ĵ���������ʲô���˹�����?���ڵ��о�����ʲô��?�����η�չ?���Ǵ���ձ��ע�����⡣�����˹����ܺ��ǵ�ѧ�ƺͼ�����dz���,Ҫ�ڶ�ʱ����ȫ����ʶ�������˹�����,��˵��רҵ��ʿ,����Ա���ҵ�о���Ա,Ҳ��ʮ�����ѵ���������,���ںܶ���������߳嵽��ʶ֮ǰ��,�ɴ˲��ɱ�������һЩ˼������۵Ļ��ҡ�
�Դ�ȥ������������,�Ҿͳ����յ��������ת���ľ����������ű��⡣�ҷ��ֺܶ�����ȱ����ѧ����,����ˡ�����AI����һ����1970����о��ڶ�������ѧ��ʿ,����û���о����˹�����,ȴʱ��ʱ��̧����Ԥ������ĩ�յĵ�����ijЩ��˾�Ĺ��ز��ź�ý�巢��������,������һЩ�����о���Ա��Ϊ����ʦ������̩���������,���ʲ������ˡ����³�,���б�����������һλ�������ڳ������˹�������ʦү������λ���ڵ�ȷ�ǻ���ѧϰ�����һ���������,���˹�������1956�꿪ʼ��,��λ����Ҳ�Ÿոճ��������һ���ѧϰֻ���˹����ܵ�һ���������,��������Ҫ����,���Ӿ������ԡ�������,����û������,���������ķ�źܻ���(����һ��:�Ҷ���λѧ�߱���û�����,�������Լ���һ��֪��������)����ʱ����,�����Dz������˻�������Ħ���桢������������ȸ����̫���Ͼ�����ʴ�ۡ������ķ�š�ʮ�³�,��Ȼ����˵��ĦԺ������,����Ҫ��ѹ����,����䶯!��˵һ���ϰ��յ��Ķ�����,����һЩҵ�ڵ��о���Ա����˵���Ļ���,��������ʲô������
�ҵĿ����ܼ�:�����д�����㳴����������,���������˹����ܡ��������������Ĵ�����Ϸ,Ť������Ϣ�ڶ�δ���������,�Ŵ�,�����,�Լ��ŵ��Լ��ˡ�����������Ӿ�˵�����ڵ�����ʲô�̶ȡ�����9�����ڳ�������һ�ҵ�̨�����˹����ܡ���λ������̸��������鹫˾,�и�����ԱͻȻ����,��̨������ͨѶ�����з�����һ��ȫ�µ�����,���ٽ���,�˿��������ۿ�һ�֡��������ܡ��ڼ���֮��Ѹ�ٵ�������(�Ҽ�һ��:���ƺ����������ը��ǰ������),����Ա������״����������ֻʣ���һ�в��������Լ���:�������,�Ͻ��ε�Դ��!�������ڰ�����ӹ��Ź����������ˡ�
�ص����ĵ����⡣ȫ����ʶ�˹�����֮��������,���п�ԭ��ġ�
��һ���˹�������һ���dz��㷺������ǰ�˹����ܺ��Ǻܶ���ѧ��,�Ұ����ǹ���Ϊ����:?
(1)������Ӿ�(���Ұ�ģʽʶ��,ͼ�����������������)��?
(2)��Ȼ���������뽻��(���Ұ�����ʶ�𡢺ϳɹ�������,�����Ի�)��?
(3)��֪������(����������������᳣ʶ)��?
(4)������ѧ(��е�����ơ���ơ��˶��滮������滮��)��?
(5)����������(�������agents�Ľ������Կ������,������������ںϵ�����)��?
(6)����ѧϰ(����ͳ�ƵĽ�ģ���������ߺͼ���ķ���),
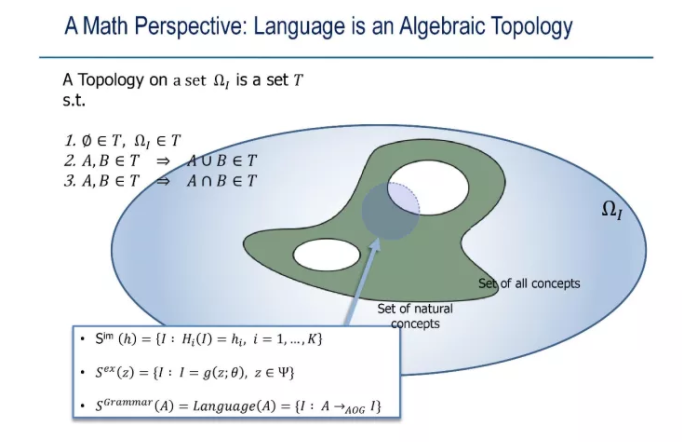
��Щ����Ŀǰ���Ƚ�ɢ,Ŀǰ�������ڽ��淢չ,����ͳһ�Ĺ����С��Ұ�����ͨ�׳�����ս�����ۡ�,�й���ʷ�����ǡ�ս�����ۡ�,������Ϊ��ʡ��,������Сһ�������:�����������ϲ���,�����������Dz��ĵ�����ƽ��̬������Ŀ����ϣ���γ�һ�������Ŀ�ѧ��ϵ,��Ŀǰ�ֺ��Ĺ���ʵ�����һ�������Ŀ�ѧScience of Intelligence��
����ѧ�ƱȽϷ�ɢ,��������о��Ĵ������ʿ�����ڵ�רҵ��Ա,����Ҳֻ���漰����ij��ѧ��,��������רע��ij��ѧ���еľ������⡣����,����ʶ���Ǽ�����Ӿ����ѧ�������һ����С������;���ѧϰ���ڻ���ѧϰ���ѧ�Ƶ�һ����������ɡ��ܶ������ڰ����ѧϰ�͵�ͬ���˹�����,���൱�ڰ�һ���ؼ���˵��ȫ��,�϶������ʡ���������,�����ѧϰ��ͬѧһ��������,���ߺ����������ȱ�,�ȶ�����������,��ͻᷢ��,����CNN�����ж��ٲ�,���Ǻ�dz,�漰�������Ǻ�С������������о���Ա���˹�����,�������ӡ���˵�������Խ�����ä������,������Ȼ������ð����,�����й����ĺ�������®ɽʱ˵����ˮ:?
���ῴ�����ɷ�,Զ���ߵ���ͬ��?
? ��ʶ®ɽ����Ŀ,ֻԵ���ڴ�ɽ�С�
���,�˹����ܷ�չ�Ķϴ�����������ʷ��չ��ԭ��,�˹�������1980�������,���ֻ������ϼ���ѧ��,�������չ,������Щѧ�ƻ���������֮ǰ30����������������ʽ����Ϊ�����о�����,ȡ����֮���Ǹ���ͳ��(��ģ��ѧϰ)�ķ��������ڴ�ͳ�˹���������(���������������ġ�ר��ϵͳ��)��û�з��������Ϸ�֧ѧ�Ƶ���һ����,��ȷ���кܶ�ȫ����Ұ��,�������Ѿ������������ˡ�����֮��ֻ�м���������80-90���,��������۹�,���ɻ��������˸���ͳ����ѧϰ�ķ���,��Ϊ��ѧ����������������(80����Ժ�)���ڴ�ͳ�˹�����ѧ�Ƶ��о���Ա����,�����ֲ��Ǻ��˽���Щ���ֻ���ȥ��ѧ���еľ������⡣��������ķֻ�����ʷ�Ķϴ�, ���������Ŀǰ��ѧ��Ͳ�ҵ��˼·�۵��൱�����ҡ��ľ���,ý���ϵĻ��Ҿ��Ŵ��ˡ�����,�Ի�����̬������,�������ȷʵΪ���ڵ�����һ���о���Ա���о����ṩ��һ���ܺõĽ�����ҵ�Ļ����������̨��������Щ����,���Ӿ��������༭��ͬ�ʺ�ͬ�ж�δߴ���дһƪ�˹����ܵ����ۺͽ��ܲ��ϡ��Ҿ���Ϊ����,�����Լ�30��������Ϳ�ѧ���о��ľ������۲��˼��,dz̸ʲô���˹�����;�����о���״�������빹��;�Լ��������ͳһ��
��д��ƪ���µĶ�����������:?
(1)Ϊ�ڶ����о����ǡ�Ϊ��־�����˹������о����������ѧ�߿�����Ұ��?
(2)Ϊ��Щ���˹����ܸ���Ȥ��ϲ��˼��������,��һ��ǰ�صġ������ԵĽ��ܡ�?
(3)Ϊ������ý���ҵ��Ա,��һ���˹����ܿ���,����һЩ��ʵ��
��������: ���ļ�������ѡ����2014�����ڶ�����ѧ���о������Ľ������档2017��7��,����������ʿҪ������һ�����Ѿۻ�����һ���˹����ܵļ��,��������һЩͨ�����ݡ�2017��9��,��̷��ţ�����̺���ʦ��Ҫ����,�Ҳμ����п�Ժ�Զ������ٰ���˹������˻�������ϰ��,�������ټ�Ա��һ����ʿ�����������ij��塣���û�����ǵ��������,��ƪ�����Dz�����д�ɵġ�ԭ����������Сʱ,��������ɾ�����������Ρ���Ȼ��������,���ϴ�����ͼ��ʾ�����ܱ�Ǹ,����ѹ���ˡ�
����ժҪ:����ǰ�Ľ�dz��̽��ʲô���˹����ܺ͵�ǰ��������ʷʱ��,�������ڷֱ�̽������ѧ�Ƶ��ص��о�������ѵ�,��ʲô����ǰ�صĿ���ȴ�������ȥ̽��,���һ�������˹������Ƿ��Լ���γ�Ϊһ�ų���Ŀ�ѧ��ϵ,������������:��·��������Զ��,�Ὣ���¶���������
��һ�� ��״����:������ʵ
�˹����ܵ��о�,����˵,����Ҫͨ�����ܵĻ���,�������ǿ(augment)�����ڸ�����Ȼ���������ĸ��������е�������Ч��,����ʵ��һ�����������г�����������ᡣ����˵�����ܻ���,������һ������Ļ��������Ļ����ˡ������༸ǧ������������ĸ��ֹ��ߺͻ�����ͬ����,���ܻ����������ĸ�֪����֪�����ߡ�ѧϰ��ִ�к����Э������,����������С���������¹�����ƻõĿ���,̸�������ھ����Ӧ�á����˼�ʻ������˺ܶ�,��˵˵���á��������һ��������ж���,���ڱ���Ҫ�߸���,�������Լ��������,���������û������滻�����,�����˿������ھ��ֺ�һЩΣ�յij���,���й¶�ֳ�,�˲��ܽ�ȥ,���뿿�����ˡ�ҽ�õ����Ӻܶ�:���ܵļ�֫����Ǽ�(exoskeleton)�����Ժ������źŶԽ�,��ǿ�˵��ж���������,�����м��˸����������,���о��Ǽ�ͥ���ϵȷ�������˵ȡ�?

����,�ⷽ��Ľ�չ�ܲ������⡣��ǰ�ձ�������ҫ���ǻ�����������,�й���һ�δ�������Ҳ���������ˡ��Ƕ������ȱ�д�ij���,���һ�������˷����¹�һ���Ӱ��������ⶼ��¶��,�������ǵĻ�����һ���ж�û�С�����Ҳ���˻����˹�ȥ,ͬ�����˺ܶ����⡣����һ���ļ�������,�����˽��������ֳ�,������һ�������ĵ���,Ҫ����ʹ�����,������¾ͱ���ס��,�������á���һ��,һλͬ���ڲ����ϰ뿪��Ц˵,�����ڵļ���,Ҫ��һ�������˳�ʱ������һ����������,����Ҫ�Դ������͵ĺ˵�վ,һ������������е�ͼ����豸,��һ������������ȴϵͳ��˳��˵һ��,���ԵĹ��Ĵ�Լ��10-25�ߡ�
��������,����Ҫ����,����˵�ò���,�������������Ͽ�����������������̾Ϊ��ֹ�ı��֡�����,��һ�Ҳ�ʿ�ٶ���ѧ��˾(Boston Dynamics)����ʾ,���ǵĻ�����,��ô�߶��߲�����,�����ߵ��˿����Լ�������,������Ұ����ּ��������,���м������صĵ�¿����Ҳ�ܿᡣ��ҹ�˾������������������֧�ֿ���������������,���ȸ��չ�֮�Ͳ��ٳнӹ�����Ŀ������,�ȸ跢�ֳ�����Ǯ,Ŀǰ���Ҳ�����ҵ��·,���һֱ����֮�С�������,�ǹȸ費�Ǻ�ţ��?DeepMind��Χ�岻��Ҳһ�δδ̼��й��˵�����?��һ������Ļ��������塢һ������Ļ����˴���,���Ƕ���ͬһ����˾�ڲ�,��Ϊʲôû������һ���˹����ܵIJ�Ʒ��?���Ǻγ�����ҹ�Լ��յķ�ս֮�а���

�˹����ܳ�������ô��ʱ��,��������Χ����,�������������ߵ��������?û�С��������˹����ܽ����ͥ����?��ʵ��û�С�������Ψһֱ����̹����ǻ��ڴ����ݺ����ѧϰѵ�����������������,����ܸ�Ta�Ĺ��������ϼҺ����˵Ļ�,��ͽ��������ס��� ����������˵���������û�б�Ta���ñ������Ļ�,Ҫô��������еû�,Ҫô������������ԡ�?

Ϊ�˲��Լ�����״,�������������о���2015������ɼ������Pomona����һ��DARPA Robot Challenge(DRC),���������������������ĵ�һ�����кܶ����μ����������,��ͼ�Ǻ����Ƽ���ѧ��Ӯ�˵�һ��,�ұ������ǵĻ��������ֳ����Ž�ȥ�����֡������������������õĸ�������Ƭ��һ��,��������������,ȫ��ð�̵ľ��ֳ��档�������Լ�����һ�����ӹ���,�Լ��³�,����,ȥ�ù���,�ط���,��ǽ�Ͽ���,����һ��שͷ�����ϰ���,��¥�ݵ�һϵ�ж������ҵ�ʱ����ѧ�����ֳ���,��Ϊ���Ǹպ���һ�����DARPA��Ŀ,��Ŀ����������IJ���Ա����ʱ,�ҵ�һ�о����Ǻ���,�о�������������������,ԭ�����������еĶ���������������ң�صġ�ÿһ����ÿһ�������ֱ���һ������,ÿ��ѧ������һ��ģ�顣��֪����֪��������������ָ�ӡ�����˵�����������ʵ��û���Լ��ĸ�֪����֪��˼ά�������滮����������ɵĽ����,��Ϳ��Կ���һЩ����˼������顣����˵���������ȥץ�Ű��ֵ�ʱ��,��Ϊ������̨�˵ĸ�֪,���һ����,��ûץ��;���߽Ų�¥�ݵ�ʱ�����һ���,�����ľ�ʧȥ��ƽ��,�����ں�����Ƶ�ѧ��û��������֪�ź�,һ��ʧȥƽ��,����������Ӧ�ˡ������뿴,�����˲Ȼ���һ�����ܱ���ƽ��,��Ϊ�������˶���һ��Ӧ,�����Ǹ�ѧ��ֻ��ԶԶ�ؿ���,����Ӧ������,���Ի����˾Ͷ������ᡣ
���һ���ij�������һ�������������������趨��,�����Ŷ�Ҳ�������������ġ������û�������ij���,��Ҫ���������?���������������û���˳���,����������˳���,��Ҫ���(�����Խ������ֹ�Э��)�Ļ�,�Ǹ��ӶȾ���Ҫ�������������ˡ�?

��ʵ,Ҫ����ȫ�����ֶ�����,���ڵĻ����˶�������������,���������������Ѿ����ռ�֮�С���ͼ����ʵ������һ�ҹ�˾��������Ŀ,�����˿��Կ�����������������ǯ�ӳ���ը����,���ǿ���ʵ�ֵġ����ڵĻ�����,��е������һ���Ѿ��ܲ�����,����Ҳ������ȫ���á����������ᵽ�IJ�ʿ�ٶ���ѧ��˾�Ļ����˵�¿��ɽ·���ȶ�,����������������,��¡¡������,��ս����ȥ��Ŀ�궼����¶�ˡ��ر�������ִ�ڡ����,�����ô��,��ô����?
2015������DRC����,��ʱ�Ͷ����������������о����ش���Ŀ���������(����������Ա)�ӱ��濴,��Ϊ��������Ѿ������,Ӧ��������˾ȥ����;���п������������,����һʱ���û�д������ѽ�����ˡ������ʶ�ϵ������ij�̶ֳ��Ͼ��ǡ����еĶ��족������ǰ��������
С��һ��,���ڵ��˹����ܺͻ�����,�ؼ�������ȱ�������ij�ʶ�����ij�ʶ��Common sense���� �����˹������о������ϰ�����ôʲô�dz�ʶ?��ʶ���������������������������������֪ʶ:(1)��ʹ��Ƶ�����;(2)�����Ծ�һ����,�Ƶ������Ұ�����ȡ����֪ʶ�����ǽ���˹������о���һ�����Ŀ��⡣����2010����,һֱ�ڴ���һ����ѧ���Ŷ�,�����Ӿ���ʶ�Ļ�ȡ���������⡣�����Զ�������������һ�������Ӿ���ʶ����,Ҳ��ת¼��������,���ûᷢ����������ô�Dz���˵,�������������˹����ܻ���ңԶ��?��ʵҲ��Ȼ���ؼ����о���˼·Ҫ�Ҷ�����ͷ�����Ȼ���Ѿ�Ϊ�����ṩ�˺ܺõİ���������,�Ҿ�����һ��,��Ȼ�������չʾ�Ľ��
�ڶ��� δ��Ŀ��: һֻ��ѻ�����ǵ���ʾ
ͬ����Ȼ�������,���ǶԱ�һ�����ʹ�С��������ѻ�����ġ������к�ǿ������ģ������,��˵һ���̾�,��˵����,�����ظ�,��������ڵ�ǰ����������������������ˡ����߶�����˵��,�����ĺ���������˶�������˵�����ᄈ������,Ҳ�������Dz��ܰ�˵�Ļ���Ӧ������������������塢����������,�������������������,��ѻ��Զ�����Ĵ���,�����ܹ����칤��,���ø��������ij�ʶ���˵Ļ����᳣ʶ������,�Ҿͽ���һֻ��ѻ,�������ڸ��ӵij��л�����,�����ཻ�����档YouTube�����в����ⷽ�����Ƶ,��ҿ��������������Ҹ�����Ϊ,�˹������о��ø�һ������ѻͼ�ڡ�, ��Ϊ���DZ�������������ѧϰ��

��ͼa��һֻ��ѻ,���о���Ա���ձ����ֺ�������ġ���ѻ��Ұ����,Ҳ����˵,û�˹�,û�˽̡������뿿�Լ��Ĺ۲졢��֪����֪��ѧϰ��������ִ��,��ȫ�����������������ɻ����˵Ļ�,������������ʵ�����л��������������һ�����������˺�������,��Ҫ�ڳ������ȥ,������ǹ�������
����,��ѻ����һ������,����Ѱ��ʳ����ҵ��˼��(������η��ּ�������й���,��������һ��������),��Ҫ����,���������������������������������������,������ɻ�ʹ�ù���,�Ҽ���ʯͷ,һ���ĵ��ڵ���,һ���еȵ������������ҡ���ѻ��ô�Զ�����,���Ѽ��������������,���ֽ������������������������,���ͷ���һ������,�ѹ��ӷŵ�·���ó�����ȥ(ͼb),����ǡ�����������ˡ�������һ������,��Ȼ�����������,������·�м�ȥ����һ����Σ�յ��¡���Ϊ��һ����ˮ������·����,��ʱ���������ˡ�������Ҫǿ��һ��,���������û�д�����ѵ����,Ҳû����ν�ලѧϰ,��ѻ������û�еڶ��λ��ᡣ�����뵱ǰ�ܶ����ѧϰ,�ر������ѧϰ��ȫ��ͬ�Ļ��ơ�
Ȼ��,���ֿ�ʼ�۲���,��ͼc���������ڿ�������·�Ƶ�·��,���Ӻ�����ʱ��ͣ���ˡ���ʱ,�������һ����������̵ơ������ߡ�����ָʾ�ơ�����ͣ������ͣ��֮�临�ӵ������������,�ĸ������ĸ�������á���ʲô������á������֮��,��ѻ��ѡ����һ�������ڰ������Ϸ���һ������,��������(ͼd)��������Ҫǿ����һ��,Ҳ�����۲��ѧϰ���DZ�ĵص�,�Ǹ���û����Щ�������������������,ͬ���������ϵ,���ᵽ��ǰ�ĵص����á���һ��,��ǰ�ܶ����ѧϰ�������������ġ�����,һЩ��ǿѧϰ����,�û�����ץȡһЩ�̶�����,���ľ���,��һ��λ�ö�����;����Ϸ���˹������㷨,��һ������,�ֵ����¿�ʼѧϰ�����Ѽ������������,�ȳ�������ȥ,Ȼ��ȵ����˵�����(ͼe)�����ʱ��,���Ӷ�ͣ�ڰ���������,�����ڿ��Դ��ݲ��ȵ��߹�ȥ,�Ե��˵��ϵĹ��⡣��˵�����ѻ�ж����,���������������������ܡ������ѻ�����ǵ���ʾ,����������:
��һ������һ����ȫ���������ܡ���֪����֪��������ѧϰ����ִ��, �����С�����ǰ��˵��, ������һ�������Ŀ�ѧ�Ҷ�������˵�����,��ѻ������֤����,�������ڡ�
�������˵���д�����ѧϰ��?�����ѻ�м������˹���ע�õ�ѵ�����ݸ���ѧϰ��?û��,���Լ��������ͨ�����������������,û�˽�����
��������ѻͷ�ж��?�������Ե�1%��С�� ���Թ��Ĵ�Լ��10-25��,����ֻ��0.1-0.2��,��ʵ�ֹ�����,��������Ҫǰ��̸���ĺ˶������硣 ���Ӳ��оƬ�����Ҳ�������ս��˼·��ʮ����ǰ�ҵ��п�Ժ����������, ��˵Ҫ���Ӿ�оƬVPU,Ӧ�ñȺ�����GPU����ǰ�������������һ���������ϵ�ṹ�Ĵ���Ŀ,Ҳ�����Ŀ�ꡣ���������������뿴,�����кܴ�Ļ�����������,��������,�������Dz�֪����ô��һ����ѧ���ֶ�ȥʵ������⡣��ͨ��һ��,����ҪѰ�ҡ���ѻ��ģʽ������,����Ҫ�����ġ�ģʽ�����ܡ���Ȼ,���DZ���ҲҪ����,�����ġ�ģʽ����������ҵ��,���ijЩ��ֱӦ�û�����Ч�������ﲻ��˵Ҫ�������������ⶼ�����,��������ҵӦ�á����������������,Ҳ�����о���ҵ��ֵ��������̸���ǿ�ѧ�о���Ŀ�ꡣ
������ ��ʷʱ��:�ӡ�������ԡ�����ս�����ۡ�
Ҫ������˹����ܵķ�չ����,���ȵûع���ʷ����������ʷ,��Ԥ��δ������һ��,�Ҿͽ���Լ��ľ���̸һ���ҵĹ۵�,������ȷ��ȫ�档Ϊ���÷�רҵ��ʿ��������,�Ұ��˹����ܵ�60����ʷ���й���ʷ��һ��ʱ����һ�����,�����Բ�Ҫ��������ƹ�����졣����ͼ��ʾ,�����ʱ����������ʱ��Ϊ��,�й�һ����ͺ�һ���ꡣ
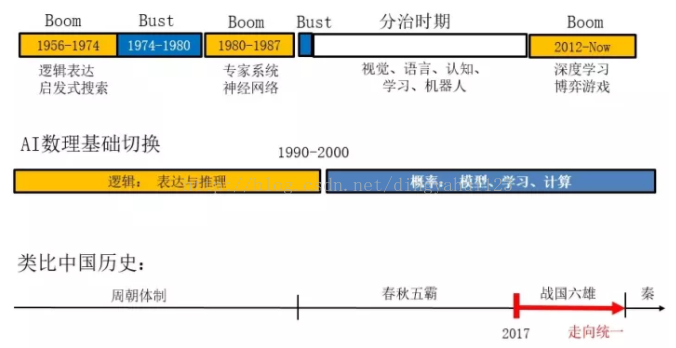
����,�ӱ���һ����������ӳ��һЩ��ҵ���ź�������Ų�����,�˹����ܾ����˼�����,Ӣ�Ľ���Boom and Bust,��˼��һ����ϡ�һ���ɢ,������ÿ����ʢ�ڶ��в�ͬ�ļ��������������á�����һ�ε�������1956-1974,����������ν������֪ʶ�������ʽ�����㷨Ϊ��������ʱ���Ѿ���ʼ�о������ˡ�Ȼ������һ�ζ��졣���ʱ��,�й������ĸ�,��ʼѧϰ�����Ƽ�������Сѧ��ʱ��,��������ֽ��������������¹�������,ʮ�ֺ��档1980������������˵ڶ����ȳ�,һ����ţ�Ľ��ڡ��о���Ա�dz��ˡ���ר��ϵͳ��֪ʶ���̡�ҽ����ϵ�,�й���ʱҲ����������ҽ��ϵͳ����Ȼ�������Ҳ��ѧ������ͼ�齱,����Щ�о�û�кܺõ����۸�����1986���������й��ƴ�����ϵ,�ҶԼ����רҵ�������������Ȥ,�����Ǿ���һ�����ߺͼ���,���˹����ܷ���ˮ����,ֵ�ó���̽��,�����Һ����ȥѡ�����˹����ܵ��о����γ�,�����Զ���ϵһ��������������ʦ�������ĿΡ������,�Һ�ʧ��,�о��˿��ˡ������������Է���Ϊ��������,����ʵ�����Զ����ʱ�˹������������ԱҲ�ܱ���,ûʿ��������,�Ҿ�ȥ�Ķ������˵����ܵ��������:������ѧ������ѧ����֪��ѧ��,������������˼�����Ӿ�������˵�ѧ�ơ���80���ĩ�и����ݵ���������о��ȳ�,���ǵ�ʱ����������,�ҵĴ�ѧ��ҵ���ľ�����������ġ����,�˹����ܾ͵����˽�30��ĺ�����
�������ȳ��������������������ѧϰ�ƶ��ġ�������ǰ�Ľ�ѵ,һ��ʼѧ���Ƕ��ܽ���,��������˵�����������ض�����,����ͨ���˹�����,��Ҳ�Ҫ����������,����ס�ˡ���˾Ҫ������,Ȼ��,��ҿ�ʼ����������������̤�¼�,����ǰ����������ѵ�,���ǽ�ͣ,���Ǻ���������Ÿ������˲�֪��,ƴ�������漷���˹����ܵ�ȷ��̫��Ҫ��,˭�������������˳���Ҳ������Ϊ��������,�������ж����ˡ����첻����,�Ǿ�Ҫ������������ô���ˡ�����˵,���Ҷ���ѧ��ʼ,�˹�����������ʴӹ������߾���ʧ�˽�30�ꡣ�����ڻ�ͷ��,��ʵ����ʱ��û����ʧ,���Ƿֻ��ˡ��о���Ա�ֱ�ۼ���������������߽���ѧ��:������Ӿ�����Ȼ�������⡢��֪��ѧ������ѧϰ��������ѧ����Щ�����γ����Լ���ѧ��Ȧ�ӡ����ʻ��顢�����ڿ�,�������,������չ���˹��������滹��һЩ���������塢��ʶ����,���������������,���������ࡣ�Ұ���30�����һ��������ʱ�ڡ�,�൱���й���ʷ�ġ�����ʱ�ڡ���������Ծ��൱����ֳ�ȥ�����ѧ��,��Ҹ��Է�չ׳��
��Ρ�����һ������ۻ��������Ұ��˹����ܷ�չ��60���Ϊ�����Ρ�
��һ��:ǰ30�����������ı���������Ϊ������������һЩ�ܳ��Ĵ�������,��John McCarthy��Marvin Minsky��Herbert Simmon�����Ƕ��ܶ���֪��ѧ�Ķ���,�к�ǿ��ȫ�ֹ����Щ�����Ҷ���ѧ��ʱ����Ľ������,�����ù�ͼ�齱������һ�Ѵ�����,���ǵĹ��������ǻ�������������������һ�����Ķ�����չ�úܸɾ���Ư��,��ֵ������ѧϰ���������Ȥ,���Բο�һ�����¹�����:The Handbook of Knowledge Representation,2007���д��,1000��ҳ������,��Щ���ŵ�֪ʶ���ﲻ���,ȫ��̸��û��ʵ�ʵ�ͼƬ��ϵͳ;����,һ��1000��ҳ����,PDF�ļ�ֻ��10M,���طdz��졣�������ڸ����������,PPT���1G, ��Ϊ�д�����ͼƬ����Ƶ,����ʵ�����ӡ����������ġ����ơ�,���൱���й����ܳ�,������������һ�������ɢ����������,����ָ�Ӳ���,���߽���,����һ���������ʱ�ڡ����˹���������Ҳ�ֳ����������
�ڶ���:��30���Ը���ͳ�ƵĽ�ģ��ѧϰ�ͼ���Ϊ������10����ķ�չ֮��,��������ԡ���1990�����ڶ���ʼ�ҵ��˸���ͳ������¡����ơ�:ͳ�ƽ�ģ������ѧϰ����������㷨�ȡ���������Ƶ�ת������,�������õ�����ô�����ˡ�����ͨ��һ��,����������֪�Ⱦ���,��ǰ�������˹����ܵķ�չ����,Ѻ���˷���(���൱��80�����������Ӣ�ض���Ʊ;90���ĩ,Ѻ�����й����ز�����һ����)������û�н����й�ý���������Ұ���Ҽ�Ҫ����һ��,��������Ҳ����ѧϰ��һЩ��ѧ֮����

��һ���˽�Ulf Grenander������60����Ϳ�ʼ��������̺���ģ��,�������������60������ڰټ�������ʱ��,�����������ﶼ��̸�����������ʱ��,����ʼ������ģ�ͺͼ���,�����˹���ģʽ����,��ͼ����Ȼ�����ģʽ����һ��ͳһ������ģ�͡�������ǰ̸������Ӿ���ʷ�IJ�����д����,���ո�ȥ����������ѧѧ��AMS�ո���������������һ������(Grenander Prize)������ͳ��ģ�ͺͼ��������й���ѧ�ߡ���������ѧ��˼����������
�ڶ�������Judea Pearl����������UCLA��ͬ��,ԭ����������ʽ�����㷨�ġ�80��������Ҷ˹����Ѹ���֪ʶ��������֪����,�����������IJ�ȷ���ԡ���90���ĩ,����һ���о��������,����һ��������ʱ����2011����Ϊ��Щ����������ͼ�齱������һ��֪ʶԨ����˼ά��Ծ����,������ԭ��˼�롣80������,���ڸ߲��������ġ�˳�㴵ţһ��,���ǵ�һ����UCLA�����ϵ��ͳ��ϵ��ְ�Ľ���,���Ƕ���֮��ڶ���������ְ�ġ���ʵ�����ֿ�ѧ���о���ʱ˼�볬ǰ,�ҹ������������ʱ��,���ߵ�ͬ�ж�������,���Ͽɡ�
����������Leslei Valiant��������ɢ��ѧ��������㷨���ֲ�ʽ��ϵ�ṹ����Ĵ�������,2010������ͼ�齱��1984��,��������һƪ����,������computational learning theory�������������ܼ�������̵����⡣��һ������:�㵽��Ҫ�������ӡ����ݲ��ܽ��Ƶء���ij�����Ŷ�ѧ��ij������,����PAClearning;�ڶ�������:����������������ۺ���һ��,�ܷ��������?�����,��ô���ϼ���������,�Ϳ���������ǿ���������������Boosting��Adaboost����Դ,����������һ����ʿ��������㷨��˳�㽲һ��,�������ѧϰ��ԭ��,��ʵ�й�������������й۲쵽��,������˵�ġ��������Խ����������������������Խ����Ǹ���,���̵�ʱ�����һ�������Բ�,������Զﴫ��,˵�ɡ�Ƥ������ValiantΪ�˷dz��͵�����1992��ȥ��������ʱ��,��һѧ�ھ������Ŀ�,��ʱ��������˵��,���Ͽλ�����������������Լ����е�����ֱ�Ӳ�����ҵ������ȥ��,�����ﶼ�Ҳ����ο���,Ҳû���κ��˿����ʡ��డ,100�ֵĿ��ҿ���40��֡��Ͽε��˴���ʮ����,��������ֻ��ʮ������,�ҿ�ʼ�����Dz���Ҫ�ҿ��ˡ����,���Ǽ�ֵ���ĩ�����ѳɼ��������칫������,���һ���������������ȥ���ֵ�ʱ��,��������ÿ���˶���A��
���ĸ�����David Mumford���Ұ�����������,�е�˽��,��Ϊ�����Ҳ�ʿ��ʦ����˵��60������������˹����ܸ���Ȥ����Ϊ����ѧ�����ر�ǿ,�ϴ������ογ̵�ʱ��ͷ����ܹ�֤��������,���һ·������ʰ,���˷ƶ��Ľ�������,����80�������,����������,���Ǿ���ת�ص��˹����ܷ�����,�Ӽ�����Ӿ��ͼ�����ѧ���֡�����˵����ԭ���������ε���ȫ��������ܷ�������,��������,��Ҳ�����ˡ���ѧ��������,��Ҳ���Ӵ��ˡ�������Ӿ�80�����90�����,һ���������ɾ��������κͲ�����,�����ⷽ����м�,������������������������ʹ�ͷ��ʼѧ����,�Ǹ�ʱ�����㲻��������ʹ���ȥ��¥��ͳ��ϵ���ڵ���,����ȥ�ʹ���һ�������ĸ���ѧ��Persy Diaconis������ȫ��һ��ѧ��,���¼���ȥѧϰ�¶���,ֱ���ؼ�����ϵ,���������������ù��˵Ĵ��ӵ����Ҷ��� �� ������������ĵط���Ȼ��,������˹���ģʽ���ۡ����Ĺ���,�Ҿͱ��Ӳ�˵�ˡ�
���ʱ��,����һ����Ҫ��������������������ѧϰ�Ķ����ѧ����Hinton�����ϴ�ѧ��ʱ��,80���������һ���������ȳ�,���ͳ����ˡ�������˼��,Ҳ�ܼ��,�Ǹ�ѧ���͵��������ͬ����,��������Ŷ��е���ҡ������,��ƾ��һ��ͨ����(����),Ѹ�ٺ����ϱ�������˳��˵һ��,�Ҹ�Hintonֻ����һ�档��������ʹ�������ܵ���������,ǰ������UCLA������(��ʱ�����ѧϰ�ոտ�ʼ����),���ǰ�����һ����̸��һ����,����˵��������������ˡ�,��Ϊ����������������ͳ������ģ�ͺ�����㷨��һЩ����,����ѧ�ɵ�һЩģ�ͺ��㷨���������Ĺ��������������кܶ౾�ʵ���ϵ���Ҵ�ӡ��һƪ�������¸�����������ȥ��·�Ͽ�������һƪ������ʽ(�����Ʒ�)����ʽ(ϡ��)ģ�͵�ͳһ����ɵ���Ϣ�߶ȵ�����,����Toronto��ͷ����ʼ�,˵�ܸ��˶�����ƪ���ġ�������˼����,��ƪ���ĵij���,�Һ�ѧ������Ͷ��CVPR����,���������ǡ�(5)ǿ�Ҿܾ�;(5)ǿ�Ҿܾ�;(4)�ܾ��������۶��ܶ�:����ƪ���²�֪����,�ܹ���weird�������Ǿ�������������,�����÷��� (rebuttal),�����������ر�¼ȡ�ˡ���Ȼ,������Ҳû�˶���������,�Ҿ�д��һƪ��������,������ʱ�����ˡ��Ұ���ƪ���ĸ�����,Hinton�Ͼ����м�,��һ��Ҳ������Ƶ����⡣���,�����ֻ�ȥ���������,���ڽ����ICIP������������ϻ��ᵽ�������,����Ҳ����Ϊһ�����Ӿ����������·�������������һ��ʮ�ֹؼ�������,�������������ͳ��ģ�����ͳһ����(��������ѧ,ϣ��ͳһij�������ͳ�),�����Ʋ���ȥ�ġ�
��Զ��,�ص��˹����ܵ���ʷʱ��,������һ���Ƚ�ͨ��˵��,�ô�Һü�ס,�൱�������й����ڵ���ʷ�������������������൱���ܳ�,��80�����������߽���,�˹����ܴ���ж���ʮ�겻������,˵���˹����ܴ�Ҷ����ò��ŵ�,�������ˡ���ʵ,������һ���������ʱ��,������Ӿ�����Ȼ�������⡢��֪��ѧ������ѧϰ��������ѧ���ѧ�ƶ�����չ���ڷ�չ׳��Ĺ�����,��Щѧ�ƶ�������һ���µ�ƽ̨����ģʽ,���Ǹ��ʽ�ģ��������㡣����ʱ����Ȼ��һЩ��ս,���������ƽ����ʱ�ڡ���ô���ڿ�ʼ����һ��ʲô״̬��?�⡰������ԡ�����������̺�����,��һ����ͬƽ̨�Ͽ�ʼ�����ˡ�����˵�Ӿ�������ѧϰ����Ϳ�ʼ�ں��ˡ������Ӿ�����Ȼ���ԡ��Ӿ�����֪���Ӿ��������˿�ʼ�ں��ˡ�������,�Һͺ����߾Ͷ����֯��������ϯ���ֻᡣ����,ѧ��֮����ʼ�沢��,�������й���ʷ�ϵġ�ս�����ۡ�ʱ�ڡ��������,����ԭ�������˹������������������:���ľ��ߺ��������¡���������ʵ�ܽӽ�,�Һ�������ǹ鲢��һ������,һ����������,�Ұ�������Ϊ��ս�����ۡ�������,�Ҹ���Щ������Ӿ����о�����������˵,���Dz�Ҫ�������Ӿ�������,��Ͻ���ȥ�������̡�,�������Ӿ�,�Ѿ�û�ж����¶�����������,���ܵ�������˾������һ����;���鷳����,���������˴����,����ĵ��̸�ռ�ˡ����DZ�Ȼ����������,�������ڷ��������顣�ҵ��ж���,���Ǹոս���һ����ս��ʱ�ڡ�,�Ժ��Ҫ����Щ����ͳһ�������������DZ����������������Ӿ�����Ȼ���ԡ������˵�����,�������кܷḻ�����ݺ����⡣�����������Щ����domain���ں�,������������ѧϰ�ͳ����˹�����ר��,����˵����ȥ���������ڽ�����ôһ���ɵġ������ʱ��,�кܶ����������ȥ̽��ǰ��,��Ҫ���������ʱ�����������ݽ��ĵ�һ������:�˹����ܵ���ʷ����״,��չ�Ĵ����ơ�����,�����ҽ����ݽ��ĵڶ�������:��һ��ʲô���Ĺ��ܰ���Щ���������ͳһ�������Ҳ���˵���д�,ֻ�Ǹ�������һЩ���⡢���Ӻ�˼·,�����˼������Ҫָ���Ҹ����ṩ����,���ػ�ȥ,�����������ܷ����¡�
���Ľ� �˹������о�����֪����:С���ݡ�������ʽ
������һ������,�����ڸ�������Ⱥ�����Ϊ�����С��ص�ǰ����ѻ������,����Ϊ����ϵͳ�ĸ�Դ�����ݵ���������ǰ������:
һ�����������۵���ʵ����������������ⲿ������������ѻ�ṩ�ġ�����ı߽��������ڲ�ͬ�Ļ���������,���ܵ���ʽ���Dz�һ���ġ��κ����ܵĻ������������������缰���������,��Ӧ������硣
�����������������������������ֵ���������������һ����������ġ����衱������������,Ҫ����Է��Ͱ�ȫ����,�����ֵĴ�����Ҫ������������Щ��������������������������ġ������������Ϊ���DZ��������������ġ���������˼�ֵ�ۺ;��ߺ���,��Щ��ֵ�����ܶ��ڽ��������о��Ѿ��γ���,���������з��ֵĸ��ֻ�ѧ�ɷֵĽ��͵���,���Ͱ�(����)��Ѫ����(ʹ��)����������(���ǡ���ȷ����)��ȥ����������(���桢�˷�)�ȡ�����������������������������ֵ��������ֵ��,��ôһ�ж��ǿ����Ƶ������ġ�Ҫ����һ������ϵͳ,������˻�����Ϸ�����е����������,�����ȸ����Ƕ��������Ļ����ж��Ĺ���,�ٶ�һ��ģ�͵Ŀռ�(������ֵ����)����ʵ,����Ļ���Ҳ����ÿ�����ܵĸ��������㡣Ȼ��,���ͽ�����ij�����������Ⱥ��֮��,��Ӧ������������,������ѻ�����ҵ�һ����·:��ʶ���硢�������硢�������硣����˵��ģ�͵Ŀռ���һ����ѧ�ĸ���,��������ʱ�̶��ڸı�֮��,Ҳ����һ������ĵ�,������ռ����ƶ���ģ�͵Ŀռ�ͨ����ֵ���������ߺ�������֪����֪������ƻ��������ͨ����˵,һ����ģ�;�������ۡ������ۡ���ֵ�۵�һ����ѧ�ı������ռ�ĸ��ӶȾ����˸�������̺ͳɾ͡��Һ���ὲ��,���ģ�͵ı��﷽ʽ�Ͱ�����Щ����Ҫ�ء������������Ļ�������(���)��,��һ����Ҫ����:��ʲô������ģ���ڿռ��е��˶�,Ҳ����ѧϰ�Ĺ���?��������:
һ�� ���������ݡ��ⲿ����ͨ�����ָ�֪�ź�,���ݵ�����,�������ǵ�ģ�͡�������Դ�ڹ۲�(observation)��ʵ��(experimentation)���۲������һ������ѧϰ����ͳ��ģ��,����ģ�;���ij��ʱ��Ϳռ�����Ϸֲ�,Ҳ����ͳ�ƵĹ���������ԡ�ʵ������������ѧϰ�������ģ��,����Ϊ������ϵ��һ�������ͳ������Dz�ͬ�ĸ��
�������ڵ���������������ڵļ�ֵ������������Ϊ�����ڴﵽij��Ŀ�ġ����ǵļ�ֵ����������������������γɵġ���Ϊ����IJ�ͬ,���������Ի�������Щ�����dz�����,��������һЩ���������ġ��ɴ�,�γɲ�ͬ��ģ�͡������˵��ԡ����Զ����Կ���һ��ģ�͡��κ�һ��ģ������������������ͬ���졣����,���Ǿ�����һ���ܹؼ��ĵط���ͬ�����ڸ���ͳ�ƵĿ����,��ǰ�ĺܶ����ѧϰ����,����һ�����ҳ����������ݡ�С����ʽ(big data for small task)�������ij���ض�������,������ʶ�������ʶ��,���һ���ļ�ֵ����Loss function,�ô�������ѵ���ض���ģ�͡����ַ�����ijЩ������Ҳ����Ч������,��ɵĽ����,���ģ�Ͳ��ܷ����ͽ��͡���ν�������ǰ�ģ���õ���������,������ʵҲ��һ�ָ��ӵ��������DZ�Ȼ�Ľ��:���ֵ��ǹ�, ��ôϣ���ö���?
�Ҷ�����һֱ���ᳫ��һ���෴��˼·:�˹����ܵķ�չ,��Ҫ����һ����С���ݡ�������ʽ(small data for big tasks)��,Ҫ�ô����������Ǵ�����������������ϵͳ��ģ�͡�����ѧ˼����,������һ��˼·�ϵĴ��ת��͵߸�����Ȼ��֤������,����˹����,���Ͷ��������ˡ�,����е����顣����Ϊһ�������ʵ�˵���ǡ��������������ܡ����˵ĸ��ָ�֪����Ϊ,ʱʱ�̶̿��DZ����������ġ������ҹ�ȥ�ܶ�����һֱ��ֵĹ۵�,Ҳ��Ϊʲô�������ϲ��Ͽ����ѧϰ���ѧ�ɵ�����,��Ȼ���Լ��������ᳫͳ�ƽ�ģ��ѧϰ��һ����,���Ǻ����ҿ����˸��������;��ơ���Ȼ,���ǵļ���ǰ��������ϵͳ�Ѿ�����ǰ�潲�Ļ���������,���ϵͳ������������Ľ���������,�Dz���ͨ�����������˴�ĥ(��̭)�������ء��е���!������ǰ�������չ�Ĺ��̶����ǽ���,����ϵͳ��Ӱ����Էֳ�����ʱ���:(1)������Ľ���,����������۵�һ���۵����������pheontype landscape����;(2)ǧ����Ļ��γ��봫��;(3)��ʮ������ѧϰ����Ӧ�� �����˹������о�ͨ�����ǵ��ǵ������Ρ�
��ô,��ζ������������?��������Ȥ�������ж���,�Ǹ�ʲô�ռ�ṹ?�������,��������֪��ѧһֱ˵�����,д�������������˹����ܷ�չ��һ������ս����������Щǰ������,��������������,�����������ڷֱ����������������������,���ܲ����ҵ����Եġ�ͳһ�Ŀ�ܺͱ���ģ�͡���ȥ������,�ҵ��о�����һֱ������������������ۺ���һ���о�,Ŀ�ľ���Ѱ��һ��ͳһ�Ĺ���,�ҵ�����ѻ������⡣
����� ������Ӿ�:�ӡ���������� Dark, Beyond Deep
�Ӿ�����������Ҫ����Ϣ��Դ,Ҳ�ǽ����˹�����������õĴ��š����Լ����о�Ҳ���Ǵ��������ֵġ���һ����һ�����������������Ӿ���������⡣��Ȼ,�ܶ�����ԶԶû�б������

�����Ҽҳ�����һ���ӽǡ�����ǰ��һ������,��Ů����ѧ�ؼ�,������дһ�������Ŀ������,��������һ����Ϊ���ӡ�ͼ�����һ�����صĶ�ά����,�������Ǹ�֪���dz��ḻ����ά��������Ϊ����Ϣ;�㿴��ʱ��Խ��,�����ҲԽ�ࡣ�������оټ���������(ָ������о���Ա)���ӵġ����Ǻܹؼ����о����⡣
һ�����γ�ʶ��������ά������������ǰ������Ӿ����о�,��Ҫͨ������ͼ��(���ӽ�)֮��������Ķ�Ӧ��ϵ,ȥ������Щ������ά��������ϵ��λ��(SfM��SLAM)����ʵ��ֻ��Ҫһ��ͼ��Ϳ�����ά���ι����������������2002��һ��ѧ�����巢����һƪ����,�ܵ���ʱ����ѧ�ɵij�Ц:һ��ͼ����ô�ܼ�����ά��,��ѧ��˵��ͨѽ����ʵ,�����ǵ����컷����,�кܶ༸�γ�ʶ����:����,���������Ӹ߶Ⱦ�����С�ȵij���Լ16Ӣ��,����Լ30Ӣ��,��̨Լ35Ӣ��,�Ÿ�Լ80Ӣ�� �� ���ǰ����˵�����ߴ�Ͷ�������Ƶġ�����,���컷�����кܶ��ظ��Ķ���,���缸������һ����Сһ��,������ƺͳ��й滮���й�����Щ����geometric common sense,�������Щ���ε�Լ���Ϳ��Զ�λ�ܶ�����άλ��,ͬʱ�������λ�ú��ᡣ
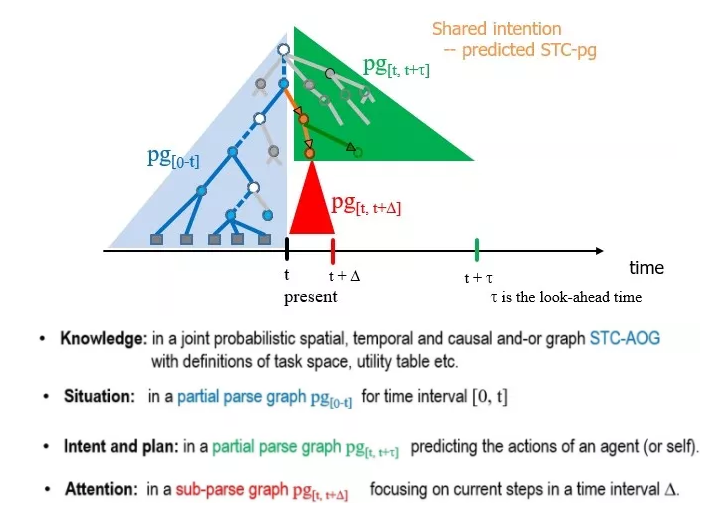
����ͼ��ʾ,�������ά������,���ǵ�����Ϳ��Ա����Ϊһ����ηֽ�(compositional)��ʱ������Ľ���ͼ(Spatial,Temporal and Causal Parse Graph),��� STC-PG��STC-PG��һ��������Ҫ�ĸ���,����������ܡ�
�����ؽ���һ������Ҫ�ı�����,������������Ҫ��ʮ�־�ȷ�����λ�á�����,�˶���ά�ĸ�֪��ʵ���Ƿdz�����,���ľ�ȷ��ȡ�����㵱ǰҪִ�е�������ִ�еĹ�����,�㲻�ϵظ�����Ҫ����߾��ȡ�����,��Ҫȥ�ü��������һ������,һ��ʼ��Ա��ӵķ�λֻ��һ�����µĹ���,�����߽������ֵĹ������������ȡ�
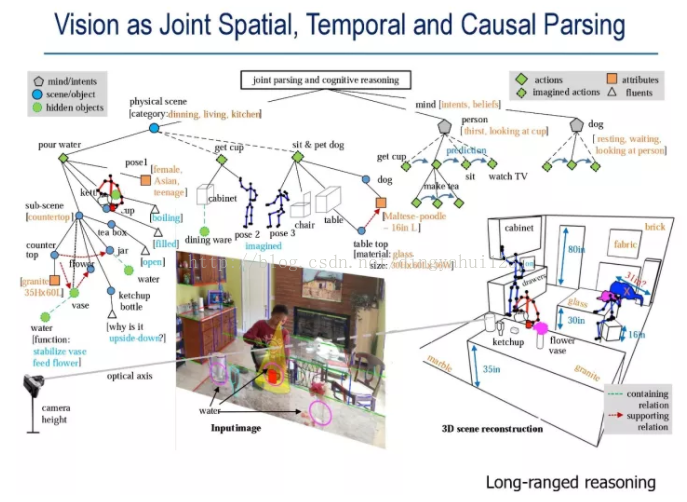
��ͻص���һ��̸������,��ͬ����Լ�����ʶ��ľ���Ҫ��һ�����������Լ���dz���Ч��һ����Ҫԭ�����,����ǰһ����ʿ��������(��������������)��������ѧ�����ⷽ��ȡ���˺ܺý�չ,������Բ鿴����������¡�
��������ʶ��ı����ǹ������������ںܶ�ѧ���������ķ���ͷָ����һЩͼ������,�ô�����ͼƬ���Ӻ��ֹ���ע�Ľ��ȥѵ��������ģ�� �� ���ǵ��͵ġ����ġ�ģʽ����һ�������Ķ��屾���Ͼ��ǹ��ܡ����㿴��һ����ά�ռ�֮��,���Ժܿ�Ϳ��������ҿ��Ը�ʲô:����ط���ˮ,��������ñ���,����������ſ����ӵȡ��ִ�����������Ǹ��ϵĿռ�,����һ��������Զ��ֹ���,���Լ�ȥ�����Ѿ��������ˡ�����,��ʽ��������������ϴ�ˡ��ò͡����졢�Է������ҿ���˯������ױ�����·������顣�����Ķ����ǰ������������ܹ���ʲô,����������Ǹ�ʲô,���չ��ܻ���,��Щ�������������������,ʵ��ͼ���в�û�С����Ը�֪��ʶ�������˶��滮����ֱ�ӻ�ͨ��,�Ӱ�졣�ҵIJ�ʿѧ����һ������������,����ҵȥ��MIT����֪��ѧ����,���ڴ�����һ���Զ���ʻ��AI��˾��Ϊ��������Щ����,������ʮ�ַḻ�Ķ���ģ��,��Щ�������ݳ߶ȷ�Ϊ����(����ͼ)����һ��(��ͼ)��������������صĶ���,������վ��˯���������ȵ�;�ڶ���(��ͼ)�����ֵĶ�����ص�,���ҡ��硢�⡢�˵ȵȡ���Щ��ά����ģ��(��ά�ռ��һάʱ��)����ͨ���ճ����¼����,�������˵Ķ����ͼҾ�֮��,�Լ��ֺ���֮��Ĺ�ϵ������Ϊ��һ��,����ѧ�о��������ǽ�����ֳ�������,�ֱ�������Ƥ�㲻ͬ����:һ���Ǹ��ֵĴ�С�й�,���ֵĶ�����ص�,�������ϵĶ���;��һ���Ǹ������й�,����Ҿ�֮�ࡣ
�����������,���Ǿ�֪��:��������ͼ,��Ȼͼ��������ȫ��ͬ,����������ͬһ�ೡ��,�������ǵȼ۵ġ��˵Ļ����Ϊ,���������ĸ����ҡ��ĸ���ʷʱ��,�����Dz���ġ��������ܷ����Ļ���,Ҳ���ǰ���ŵ�һ���µĵ���,�㲻��Ҫ������ѵ��,���Ͼ������⡢��Ӧ�����������ܹ���һ������һ��������?

�ص�ǰ����Ǹ�STC-PG����ͼ,ÿ������������ʵ�ͷֽ��ΪһЩ�������� (��STC-PGͼ�е���ɫ��Ƭ�ڵ�)���ɼ�������������ĸ��ֹ��ܾ����Գ����ķ��ࡣ �����ܾ��ǰ��˵ĸ�����̬�ŵ���ά������ȥ���(����������ͼ��������)��������ȫ��ͬ�ڵ�ǰ�����ѧϰ�����õķ������
���������ȶ������ϵ�����������ǵ�����ռ������������ĸ�������(���ܡ�����)֮��, ��һ������Լ���������������Ƕ�ͼ��Ľ��ͺ����ⱻ�����Ϊһ������ͼ,�������ͼ����������������,������Ǵ���ġ������ȶ������˿��Կ��ٸ�֪��,����㷢����Χ��������,Ҫ����,�㷴Ӧ�dz���,�Ͻ����������������Ŀ���Ү³��ѧ����Brian Scholl����֪ʵ�鷢��,�˶������ȶ��Եķ�Ӧ�Ǻ��뼶,��һ��Ӧʱ���Լ 100ms�����Ƕ�ͼ����������������֮���������ϵ,ÿ�������֧�ŵ����������,�������ͼ,���ƺ�ǽ�ϹҵĶ���,���û��֧�ŵ�,�ͻ������(��ͼ)������о�����,MIT��֪��ѧϵ��Josh Tenenbuam�������Ҷ����˶��ꡣ

�������һ���µij��������minimax��:minimize instability and maximize functionality��С�����ȶ�����������ԡ������ǰ������ͼ��������õ�MDL(��С��������)��Ҫ�����ס����ǽ��������Ӿ��Ļ���ԭ��,���ܺ���������Ƴ����Ļ���ԭ���γߴ��Ǹ����ڹ����Ƴ�����,�������ӵĸ߶Ⱦ�����Ϊ��Ҫ�������,���Ծ�����С�ȵij��ȡ��ص��Ҽҳ���������,��ͻ���,�������ˮ����α�������?ˮ�ǿ�������,��ƿ��ˮ�����ˮ�ɸ��ַ�ʽ�Ƴ����ġ�����,�����ע�,���ϵķ��ѽ�ƿ���ǵ�����,Ϊʲô��? ����ܺ����,��ҵ�ϴͷ��������ʱ��,ƿ���Dz���Ҳ�ǵĵ��ŷŵ���?����Ƕ�ճ��Һ���������������֮��Ľ�����ɴ�,����Կ������Ƕ�һ�������������Ǻεȡ���̡�,ԶԶ�����������ѧϰ�������������ͼ�⡣
�ġ�����ע���Ԥ�⡣��������ͼ��һ���˺�һֻ��,���ǿ��Խ�һ��ʶ���䶯�����۾�ע�ӵĵط�,�ɴ��Ƶ��䶯���������������ǿ��Լ������ڸ�ʲô�����ʲô,����˵�������ǿ���,�������ˡ�ͨ��ʱ���ۻ�֮��,����֪����֪����Щ,Ҳ�����������˻���û�п���ʲô����ʱ������Ԥ��,���������ʲô��ֻ�а���Щ�����������,�������ܸ��õ����˽��н���������,��Ȼ����ֻ����һ��ͼƬ,����STC-PG��,����������ʱ��ά��,���˺Ͷ����֮ǰ��֮��Ķ���,��һ����εķ�����Ԥ�⡣���������ܹ�Ԥ�б��˵���ͼ������Ķ���,��ô�����ܺ��˽��л����ͺ���������,���ǽ������ԶԻ��������˻������ͺ���;����,�����ճ��ཻܶ��Э��,������Ĭ��,����Ҫ����Ҳ���������¡�
�������һ��ͼ,�Ƕ��������һ���ۺϳ����Ľ���ʵ���������ҵ�ʵ������������һ���Ӿ�ϵͳ�������Ƶ����������Ϊһ������ۺϵ�STC-PG���ڴ˻�����,�Ϳ���������ֵ�����(I2T)�ͻش����� QA�����ǰ��������Ӿ�ͼ�����,��ַ:visualturingtest.com��?

���һ�ڽ��Ļ����˾�������,��Ҳ��һ��DARPA��Ŀ�����Ծ����ô�����Ƶ,��������������˵���ά��ģ�͡����������ԡ���ϵ�ȵ�,Ȼ������ش���ָ�����1000������⡣����һ�������Ӿ������о�VQA(�Ӿ��ʴ�),�����ô�����ͼ����ı�һ��ѵ��,���ǵ��͵ġ����ġ�ϵͳ,�������ǡ����ס����ش������û����������ͼ�������,��������ͨ�����������������VQA֮ǰ,�������˶��ꡣ����ϵͳ����ĿDARPA����������,��ʱ�����ŶӸ������������������,���ڿ��е�һ����ʵ���������ֻ���:��dz�ĸ�������,��Ҷ��ܳ�,���Ӹ���Ķ�����Ҷ����ߡ�
��Ȼ˵������,�Ҿ�˳��˵˵һЩ���������顣��Լ��2008�꿪ʼ,CVPR����ķ����ͱ��ˡ����������,��֯�������ݼ�����,��̸������,�������ֹ�˧���й��ܶ�ѧ�����ŶӾͿ�ʼ����,�׳ơ�ˢ�����Ǹ�ʱ�����Щ��֯���ݼ�����˵(��ʵ���Լ�2005���������ں�������ɽ���������ݱ�ע��,����һ��Ϳ����������,������ˢ��),������Щ����ǰ�����϶����й�ѧ�����߹�˾�����ڹ�ȻӦ����,�ְ���ǰ���������й������ֻ�λ�ˡ�����ˢ��ȴ�ƹ��������,ˢ��������AI�о��ġ�������νˢ��,һ�����������˼ҵĴ���,�Ľ��������������ģ��,�����ٶȿ졣����������һ�Ҽ�����ţ���й���˾(���Ǹ��Ӿ���),�Ǹ���˾���з����ܷdz�����,˵����ˢ������Ӯ,����һ����ѧ�����ڻ��¡������ò��ͷ���,��˵�˼Ҿ�������ѧ��������Ū,������ô����Ŷ�������ˢ,������������û���㷨�����Լ��ġ�����˼�֮ǰ����������,���Ǹ���û���档�ܶ˾��������ˢ��Ľ�������Լ�����������һ��ˮƽ��
�塢�������������������ѧϰ��ǰ����̸�˳��������������,������̸һ�������ʶ�������,�Լ�Ϊʲô���Dz���Ҫ�����ݵ�ѧϰģʽ,���ǿ���һ������������
�������Ƿdz���������ᶯ��,����˵��ʲô���鶼�DZ������������ġ���һ��,2000��ǰ��˾��Ǩ���Ѿ�Զ������������ѧ֮ǰ������( ��ʷ�ǡ� ����ֳ�д��� ):?
����������,��Ϊ����;��������,��Ϊ��������?��ô,��Ҳ�ʹ��Ź�����Ŀ���������������,�������teleological stance�������������������ʲô��?��������ʲô��?��ô��?��Ȼ,��û�����������������ͷ�������������ġ��ܶණ��,�����ò��ϵ�ʱ��,�����Ӷ�����;һ��Ҫ����,��ͻᵱ�������������������ۡ�,û�취,��������!������ʲô�������ʲô,ÿʱÿ�̶����������ֽ�����ƨ�ɾ����Դ���,һ����Ա���ڲ�ͬλ��,�����в�ͬ��������˼·,λ��һ��,���Ͼ͡������˷ǡ��ˡ����ǵ�֪ʶ�Ǹ������ǵ���������֯�ġ���ôʲô����������?��α������ѧ������?ÿ��������ʵ���ڸı䳡���е�ijЩ�����״̬��ţ�ٷ�����һ����,�����ﱻ������:����fluent������ʻ�û�����뵽����,����һ�ֿ��Ըı��״̬,�����ҷ���Ϊ����̬���ɡ�����,��ˮ�տ�,ˮ�¾���һ����̬;���ѽ���ƿ�ӵĿռ�λ�ù�ϵ��һ����̬,���Ա�������;����һЩ��̬���˵�����״̬,��������ۡ�ϲ�á���ʹ;��������ϵ:��һ����,�����ѡ��ٵ����ѵȡ�����Ͷ���ææµµ,�����ڸı������̬,��������ǵļ�ֵ����(����)��
������һ��,��������̸����ͼ���е���ά�������˵Ķ�������ʵ,����������ϵ����������ν�������:�˵Ķ���������ij����̬�ĸı䡣����ͼ����ʵ����̽(����Ħ˹)�ư�һ��,����Ҫ�������������Ǻ�С����˿����,����,���ܿ�����Щ��˿����,����ͨû������̽ѵ�����˾Ϳ���������ô,��β��ܿ�����Щ��˿������?��һ������Ҫ������֪ʶ,���֪ʶ��Դ��ͼ��֮��,��������Ĺ������õ���,����һ��ͷ����ô���������?���о�����Ϊ�Ķ���Ŀ��,������Ա������ı�ʲô����̬��?
�Ұ���Щͼ��֮��Ķ���ͳ��Ϊ�������ʡ��� Dark Matter������ѧ����Ϊ���ǿɹ۲�����ʺ�����ֻ��ռ���������5%,ʣ�µ�95%�ǹ۲첻���İ����ʺͰ��������Ӿ����ʮ������:��֪��ͼ������ֻռ5%,�ṩһЩ��˿����;�������95%,�������ܡ�����������������ȵ���Ҫ���˵������������������ɵġ�

���������ʶ,��������һ������(����ͼ��)�����������������CVPR2015�귢��paper,��Ҫ������������,��Ҳ���Һ�ϲ����һ��������һ����Ҫ��ɵ��������Һ���,�ı��������Ǹ����ҵ���̬�����������UCLAһ��ѧ��,���������ϵĹ�������ѡ����һ������,��������û���κι���֮��,��Ϊ��Ҳ����ô����������ϸ��һ��,�������൱���ӡ���������Ͱ����˺ܶ���Ϣ:��Ϊʲôѡ������Ӷ���ѡ��Ķ���,��Ϊʲô���Ŵ�����������λ��?���Ӷ��������ö���,�ⶼ�Ǿ�������ġ���м�ǧ����Ŀ�����������ѡ�ⷨ,��û��ѡ��,˵�������ѡ����������ѡ��϶����,��������?���Ƽ�����,�����ܹؼ�,һ�������������ˡ�
��ͨ����һ��ĥ��һ�ԱȾ��������������ʲô,��ʲô���š���ǰѧͽ���Ǹ���ʦ��ѧ,ʦ��������������,ͽ�ܾͿ���,ʦ��Ҳ����,ͽ�ܾͿ��Լ�������ʱ��ʦ����Ҫ��һ��,��Ȼ�������ʦ��,�����ķ��롣��ʱ��ʦ�����Ų����㿴;Ī�Ե�С˵������������ڡ��˾����ڹ۲��ʱ��,���������ѧ���ˡ����ڵ�һ���µij���(ͼ��),ԭ��ѧϰ����Щ���߶���������,��ȫ���µij���������,���ֲ��䡣������������������Կ�,��ô��?�˵�Ȼû������,ѡ���ľͷ����������,Ȼ���ҵĶ���Ҳ��һ��������Ǿ�һ����,���������,��û��ʲô��������,û�д�������ѵ��,�ⲻ�����ѧϰ������������㷨��ô������?���ǰѶ���������ռ䡢���������������DZ����Ϊһ��Spatial,Temporal and Causal Parse Graph(STC-PG)�����STC-PG��������Կռ������(���塢��ά��״�����ʵ�)��ʱ���϶����Ĺ滮��������������������������,����������ܹ�ʵ��,���ܻᱻ�ҿ�,������һ�������,��ʱ�䡢�ռ���������ôһ������ͼ,����һ���⡣Ҳ����,�����ﵽĿ��,�ı���ij����������̬������ǿ������:?
һ�����STC-PG�ı���������������ġ��������Ĺ��������㶯��֮ǰ������˵�,������Ľڵ�ͱߴ������ͼ������û�е�,Ҳ�����ҳ����ġ������ʡ���
�����������Ĺ�����,�������������ڡ�top-down���Զ����µļ�����̡�Ҳ����������Ƥ������ѧϰ���Ĵ�����֪ʶ�������㿴���ġ���˿������,�γ�һ�������Ľ⡣������Top-down�ļ��������Ŀǰ����ȶ������������û�еġ�������ֻ��feedforward ������㴫����Ϣ�������Ҫ˵��,�Dz�����Back-propagation��?�Dz���top-down��һ��ǰ,LeCun��UCLA������,������������,��˵DNNĿǰȱ�������һֱ�ᳫ��Top-Down������̡�
����ѧϰ�������ֻ��Ҫ���ٵļ������ӡ����һ����Ҫ̫�������,˵��Ta�Դ��������ϡ�,���̲�����˳��˵һ��,����UCLA����,��ĩѧ�������ʦ������ѧ������һ��������ѧ�������������ڸ�������̫���ˡ��Բ���,��ûʱ������Ͽν���ô������,�����⡢�⺣ѵ��,�Dz����汾��,Ҳ����ѧϰ�ı��ʡ���Ի:��ѧ����˼����,˼����ѧ�����������ġ�˼��Ӧ��������,������Ȼ���������������Ϊ������,�γ�һ�����Ϲ��ɵ���Ǣ�Ľ���,���ҿ�������һ��STC-PG��
��ôSTC-PG������Ƶ���������?����ĸ����һ��STC-AOG,AOG����And-Or Graph���ͼ��������ͼ��һ�����ӵĸ����ͼģ��,�����Ե��������ĺϺ�����ĸ����¼�,ÿһ���¼�����STC-PG��������������ԡ���֪�������˵�������һ�µġ����ҿ���,���STC-AOG��һ��ͳһ����,�������Լ�DNN���Դ�ͨ�ؽڡ�����Ͳ��ི�ˡ������Һ��ҵ����ӽ�,������������ƪ���µ�ʵ��,���ʵ����������������ڵ�һ�������ǡ�������,�Ҹ���һ������ʲô�в���,Ȼ��ʼ������������㷨(������)�ķ�������������ͼ��?
��һ��ʵ��(ͼ��)���Ҹ���һЩ����,�������,�����˵�һѡ�������������,�������ģʽʶ��,��ͬʱ�����������ӵĶ������ٶ�;������ӱ�����ɫ�ط���ʾ��Ҫ���յĵط�,�����ı�ʾ������������λ�á��ڶ�ѡ����һ��ˢ�ӡ�
�ڶ���ʵ��(ͼ��)��������Ҫ����Щ��������,��������һЩ���ﳣ��������,�����Dz��������ĵ�һѡ���ǹ�,�ڶ�ѡ���DZ��ӡ����ߵ�ȷ�������ѡ�����Ǽ�����Ӿ���������,�Զ��ġ�
������ʵ��(ͼ��)���������ǻص�ʯ��ʱ��,һ��ʯͷ�ܸ�ʲô����?�����Ҿ���˵,����ʯ��ʱ��������,�����ڵ�С����������Ϊ�����ܹ������������ı���,����,���ߺ�����Խ��Խ�ض���,һ��������һ������,�˶����Խ��Խɵ�ˡ��Ӿ���֪���˻���ģʽʶ���������:��ԭ�����ߵ�������һ��ģʽʶ��Ҳ��������ѻ�������ˡ�
������Ӿ�С��:�Ҽ���ܽ�һ���Ӿ�����ʷ������ͼ��

�Ӿ��о�ǰ��25���������������,����״������Ϊ���ĵ��о�:Geometry-Based and Object-Centered�����25���Ǵ�ͼ���ӽ�ͨ����ȡ�ḻ��ͼ����������������������ʶ�𡢷���: Appearance-Based and View-Centered�����ε�Ȼ�������ۡ���ô���κ����ԭ����ʲô��?������״���������Ϊ������,�����������,Ȼ���ǵ����ܡ����������,�������Щ������������ͼ��,���Ǻ����������ڡ��Ұ��ڵ�ǰͼ���ǿ������ġ���������dark matter����������dark matter energyռ95%,ȷȷʵʵ��������������dark matterҲռ�˴֡����㿴���Ķ��������������ѧϰ�ܹ������,����˵����ʶ������ʶ��,���Ǻ�С��һ���ֿ��ü��Ķ���;���������ں���,������������������,���Ǹ���ѻ�������ġ�
����,�ҵ�һ��������:������Ӿ�Ҫ������չ,���뷢����Щ��dark matter������ͼ���������95%�İ�������ͼ���пɼ���5%����˿����,�������˼��,���ܵ������������⡣���ڴ�Ҷ�ϲ�����Լ�����ǰ���һ��Deep,��Ϊ������������ˡ������,����ʵ���Ƿdz���dz�ġ����������,�����������������ٲ�,��ֻ�Ǵ����ɼ���ͼ�������������������,û��������5%,��?��Щ��Ϊ���ѧϰ����˼�����Ӿ���ͬѧ,��˵������ô?���û��,���滹�и�������ݡ�
�Ӿ��о���δ��,����һ�仰��˵:Go Dark, Beyond Deep �� ����,��Խ�����һ��,�Ӿ�����֪�����Խӹ��ˡ�
������ ��֪����:�߽���������
��һ�ڽ��������ܵİ�����,�Ѿ����ڸ�֪����֪�Ľ���ˡ�����������һ��,�ͽ������붯�����������Mind, �������練ӳ�ⲿ����,ͬʱ�ܵ����������Ӱ���Ť�����о��ں�����:
Ta����ʲô��?֪��ʲô��?ʲôʱ��֪����?����ʵ�Ƕ��Ӿ�����ʷʱ������֡�?
Ta�����ڹ�עʲô?���ǵ�ǰ������ִ�е�����?
Ta����ͼ��ʲô?�������ʲô?Ԥ��δ����Ŀ�ĺͶ�����?
Taϲ��ʲô?��ʲô��ֵ����?���ڵھŽڻ�̸���������ӡ�
�Դ��˹�����һ��ʼ,�о��߾������Щ����,����������Minsky:society of minds,����ѧ�о�����Theory of minds����2006���ʱ��,MIT��֪��ѧϵ��Saxe��Kanwisher(������һ����Ŀ������)�����˵Ĵ���Ƥ����һ��ר�ŵ���,���ڸ��ܡ����������˵��뷨:��֪��������ʲô����ʲô�������˹����ܵ���Ҫ���֡�
˵��ͨ������,������������������������:ij���ܹ�ͬʱ�뼸��Ů����ά�ֹ�ϵ,���Ҳ����Է�����,�������Ǽ���Ů���ѻ��֪�顣����ʵ��������,��Ϊ��һ��С�ľ�Ҫ��¶�ˡ�����Ҫ��ס��˭˵��ʲô�ѻ����������ߴ�Ӧ��ʲô�¡������˵������Ƥ����һ�����ر�,��������ЩŮ���ѵ���������ܲ���ô�����Ӱ�еļ����Ҫ�ر�ѵ���ⷽ��ġ�����족����,�����㾡�����öԷ�����������ġ����Ǽ���״������ʵ������,һ�����˽�ԵĻ��,�����Dz������,Ҳ���ǡ�����̹��������?

�����������������뷴��������,����Ҳ��(����ͼ)������˵�����(ͼ��),���ع��ӵ�ʱ��,��鿴��Χ�Ƿ�����������߶������������;�����,���Ͳ���,����Ҫ�ҵ�û�˿�����ʱ��͵ط��ء���������ڹ۲���,֪����֪��ʲô��ͼ����һ�������ˮ̡���ŵ���Ƶ��ˮ̡ץ�������Ժ�,������������ڰ��϶�������,��֪���������������������ŵ��㡣ˮ̡����취���������,���������ص�ˮ����,Ȼ���������ȥ�ҡ���˵���˶���֮�以��֪���Է�����ʲô��
С����һ����ʱ��ʼ�����������ʶ��һ���ؼ���Ӧ֤����:����ָ�������㿴,�㿴���ˡ�����û������,����֪����Felix Warneken�����ڹ����ѧ������ѧϵ���������ڡ�������ʿ����ʱ������һϵ������ʵ�顣һ��һ����С����֪�����㿪��,С�������⡢����ȥ��æ��С�������֪�����˽������,������˻�������������С������һ�������˵Ļ�,��Ҫ���һ��������,����ϣ����֪���������ʲô,�����˹����ܵ�һ�����ı��֡�
�����˹����ܺ���֪��ѧ,�Լ����������������˶�������������Ȥ,����,�����ǰ���������ϡ�ֽ��̸��,�õ���һЩtoy examples��Ϊ������������Ҫ����ʵ������о�,����Ҫ�Ӽ�����Ӿ����֡�������Ӿ����������,�ִֶ���æ��ˢ��,һʱ��ỹû��˼�����Ǹ����⡣�ҵ�ʵ���Ҿͽ����ȵ�,����һЩ������̽��,Ŀǰ���ڻ����ƽ�֮�С�

����������һ��������,����ͼ��������ڳ�����,��ǰ��������¯����һ������ͷ�ڿ�����,�����һ��,Ҳ�����ǻ����˵��۾�(ͼ��)�������ܹ�������Ŀǰ�ڿ�ʲô(ͼ��),Ȼ��,ת���ӽ�,������Ŀǰ������ʲô(ͼ��)��?
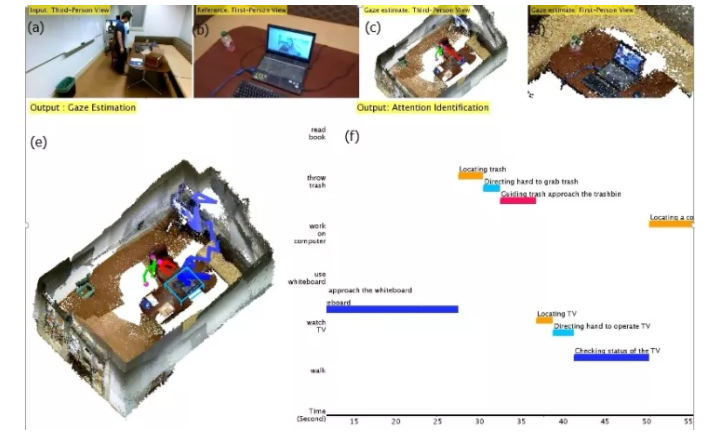
�������ͼ��ʵ�����Ƶ�Ľ�ͼ����������������Ѿ���Ϥij����ά����(ͼe),���ڹ۲�һ�����ڷ�����������(ͼa)��Ϊ�˷�������,���Ǿ���������һ������Ժ����ҽԺ����,��������Ҫ֪������������ڸ�ʲô,��ʲô(ͼc)���������������һ����ά����Ƶ(ͼa)������ʼ��������˵��˶��켣���۾�ע�ӵĵط�,��ʾ��ͼe����Щ�켣��ͼf����Ϊ���ࡣȻ��,ͼd(���Ͻ�)�������������,�����Ӧ���ڿ�ʲô��ͼƬ��Ҳ����,���������嵽���������,����֪����������ͼb�Ա�,�dz��Ǻϡ�ͼb������˴�һ���۾�,�۾���һ��С����ͷ��¼������,��ȷʵ�ڿ��Ķ��������ʵ������κƽ��ʿ�ṩ��,����������ǰУ��֣������ʦ�����һ�������ʦ,��ʿ�ڼ�����ʵ���ҷ���,�����ֻ������ޡ��ȡ������������Ҫ�Ʋ���������ʱ�ս���,������ʱ���ת��,����Э����Ȼ��,��һ�����������ʲô,��ͼ��ϸ���Ҳ��ི�ˡ�����������ĵ�״̬,Ҳ������һ��STC-AOG ��STC-PG �������,����ͼ,���°����IJ��֡�
һ��ʱ������ĸ��ʡ����ͼ��,STC-AOG����������˵�һ���ܵ�֪ʶ,���������еĿ�����,�Ҵ�������һ������������⡣ ʣ�µ������Ե�ǰʱ�յ�һ������,��һ��STC-PG����ͼ���˽���ͼ����������,ͼ�б���Ϊ����������,ÿ��������Ҳ��һ��STC-PG ����ͼ��
������ǰ���龰situation,����ͼ����ɫ�����α�ʾ����ǰ�������ʲô,��Ҳ��һ����,��ʾ�Ӿ���0-tʱ���֮�����������������һ������ͼ��
���������붯���滮ͼ,����ͼ����ɫ�����α�ʾ����Ҳ��һ����λ��Ľ���ͼ,Ԥ�������滹����ʲô����,
�ġ���ǰ��ע����,����ͼ�ĺ�ɫ�����α�ʾ�����������ڹ�עʲô��
������������ͼ����һ��,�����ϴ����������Դ��Ĺ�ȥ�����ڡ�δ���Ķ���ʱ���ڵ�״̬����һ��ͳһ��STC-PG �� STC-AOG�����͡� ����һ����εķֽ⡣ ��Ϊ��Composition, ����Ҫ�������ͺ��١�
����Ҫ˵��,�ҵ����������Ҳ�в��,��һ�ٶ���ء���Ҫ˵����,����һ�ٶ����ʵ��ֻ��һ��,�Բ���?��Ϊ������������ʶ��,�м�Ķ�����ʲô�㲻֪��,������ȥ�����м���Щ����,ֻ�����һ������������
����˵���������,�ǻ����˶�ij��������״̬��һ������,���������һ���������,������Ʋ���Ψһ��,���ڲ�ȷ���ԡ�����,���϶��������ࡣ��ͬ���˹۲�ij����,���ܹ��ƶ���һ������ô��һ���������˹�������Ļ�����,���������������N�������˻�����,�������кܶ�N�������ҡ�minds��Ȼ��,ÿ�����жԱ�����һ������,�����N x(N-1)��minds�����֪��������ʲô,��֪��������ʲô,��������ƽ�����ġ�����һ�ٸ����ѵĻ�,�ĸ��������Դ�����ʲô�����ﶼ��������ϵԽ��,����Ҳ��Խ��,Խȷ����Ȼ,��������ֻ����һ������,�ڸ��ӡ��Կ��Ļ�����,���Dz��ò��ö�ı������˾��ܲ�����������ɽ����ʱ,�������˾��ܲ����Ҫ����һ�ס���ν������թ,������ʱ���ҹ����һ��������Ϣ������,���������塷�кܶ����ľ��ʹ���,������褴�Ƹǡ����ɵ��顣�����������ͼ�������ܽ�һ�¡�������A��B����һ����һ��������,�����Դ�����ı���ģʽ��ͼ����һ��Ƕ�ĵݹ�ṹ,ÿһ����Բ����һ�����Ե�����mind��
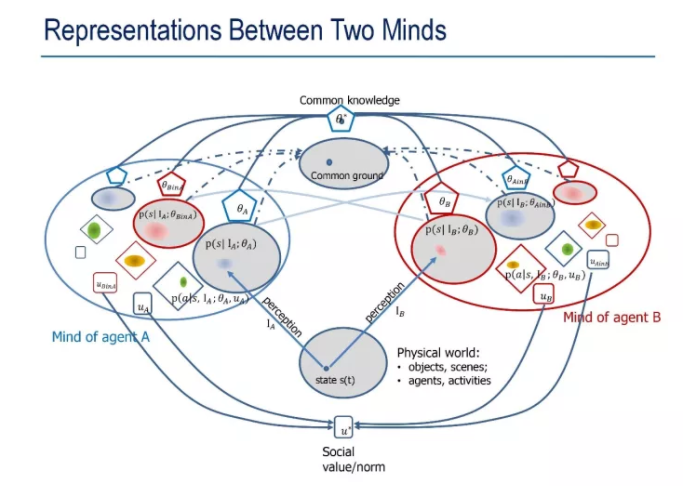
ÿ��mind��������̸����֪ʶSTC-AOG ��״̬STC-PG,�������˼�ֵ����,���Ǽ�ֵ��,�;��ߺ�������ֵ����������,Ȼ����ݸ�֪���ж�ȥ�ı�����,��������ͳ����ˡ��Һ�����ϸ̸������⡣
������м���Ǹ���Բ������ʵ����(���ϵۡ���mind,����ֻ��TA֪��,���Ƕ���֪��),�����м���Ǹ���Բ�ǹ�ʶ������˵Ļ�������Ṳʶ���ڸ�֪������,����γ�һ��ͳһ�Ķ���,��ͬ����,���Ǵ�ɹ�ʶ������,���һ��Է�,��������,��Ҷ������������ʲô��,���û�й�ʶ��û��Ū������,��ָ¹Ϊ�������ߡ��ʵ۵���װ��,��������Щminds֮������˲�һ�µĶ�����������ν����ʶ�ۡ���������⡣��ǰ,�ڴ�ѧѧϰ��ʶ��,��ʦ���ñȽϿշ�,��������;������ѱ���д����,һ�ж�����ˡ���Ҳ���˹����ܱ����������⡣����Ҫ��ɹ�ʶ,��ͬ��֪ʶ,Ȼ����һ��С�����塢��������ɹ�ͬ�ļ�ֵ�ۡ������˹�ͬ��ֵ�۵�ʱ��,���������º������淶,�ⶼ�����Ƶ������ˡ���˵,�������ס��������һ���µ���������罻Ⱥ��,������ȹ۲쿴����Ҷ�����ô����˵���ġ�������Ҫ���˹������� ���������˵�����������º������淶������˵,�����ʶ���ǻ����˷�չ�ıؾ�֮������ѻ֪�������ڸ�ʲô,�����ܹ������������������档��ô��δ�ɹ�ʶ��?���Ծ��DZ�Ҫ���γɹ�ʶ�Ĺ����ˡ�
���߽� ����ͨѶ:��ͨ����֪����
��Ҫ���ܵ��˹����ܵĵ��������������ԡ��Ի���������������Ӿ������Խ�ϵ����ֻ������˱���,�����Լ��۲�ĽǶ���̸,�Ӿ����������ܲ��ɷֵġ�
��������������Ƕ��ص�,��Ȥ���������˶��滮���ĸ���������ΪʲôҪ�Ի���?���Ե���Դ����Ҫ��һ�����Դ�(mind)��һ����Ϣ���ﴫ����һ����,��Ͱ�����һ�ڽ���֪ʶ��ע�⡢����ƻ�,����Ϊͼ�������������εı��ϣ��ͨ���Ի��γɹ�ʶ,�γɹ�ͬ������滮,��������һ���ж�������,���Բ����Ļ�������ҪѰ�����������֮����Ѿ��зḻ�Ľ����ķ�ʽ,�ܶ������֫�����ԡ��˵ĶԻ���һ��������,����ƾ�(pantomine)ͬ�����Դ��ݺܶ���Ϣ������,�����Բ���֮ǰ,������Ѿ�����ʮ�ַḻ����֪����,Ҳ������һ��̸����Щ���û����������֪����,�����ǿն��ķ���,�Ի�Ҳ�����ܷ�������������ѧʵ�����,12���µ�С���Ϳ���֪��ȥָ����,��С����Ͳ���,���Ǻܶද����Զ�ﲻ�����ˮƽ���ٸ�����,�������˸�ʵ�顣һȺ���������ڶ�����,һ�����������һ��С����,��������С�����ܲ�����,Ȼ���������ȥ�ҡ���Χһ������ŵ�������������ɹ̫��,��������֪���Ǹ�С����ȥ���ˡ�������˵Ļ�,���Ǿͻ����ĵ�ָ�Ǹ�С���ķ���,�������Ǻ�����,ȥ�������˵�,����Ϊ��,��������Ϊʲô�����˽��������ˡ����ɲ���,���ɲ�ָ,����û���������,�����Դ��������һ����ȱ��һ�顣�˺Ͷ������,����֮�����ܹ������Ǹ���,��Ϊ�Դ����кܶ�ͨ�ŵ���֪����(����������ͨѶЭ��)�ڴ���Ƥ������,û����Щ��֪���ܾ�û��ͨ�š��о����Ե��˲�ȥ�о����µ���֪����,���Dz����кܴ��Ϣ�ġ��������ͼ��Դ������ѧ���о���һ��������� Michael Tomasello��?

������Ҫ�����֪����,���Ե��о������������Ӿ����ⲿ����ĸ�֪���������˶����������,�������Ծ�����Դ֮ˮ���ޱ�֮ľ����Ҳ����Ϊʲô��ǰһЩ��������˶��ڡ����ס�������������һ��������ĵĹ���:��Ϣ��һ�η��͡���ij��(sender)Ҫ����һ����Ϣ��ij��(receiver),����һ����ͨѶcommunication�����ͨѶ����ѧģ���ǵ��건��ʵ������ũShannon1948�����������Ϣ�ۡ����Ȱ�������,��Ϊ�����������Ƚ϶�,�ȽϿ�;�������ͨ��,��Щ���������;Ȼ�����,ij�Ҿ��õ��������Ϣ������ͼ��
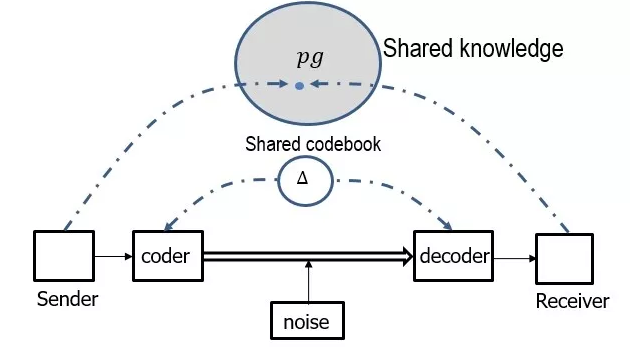
�����ͨѶ����֮���������������ļ��衣��һ�������߹���һ���뱾,������û������,����һ���������衣�ڶ������������и��������ⲿ�����֪ʶ������,���Ƕ�֪�����������ڷ���ʲôʲô�¼�,�����ĸ���Ʊ����Ҫ����,�ĸ��ط�Ҫ����ʲôս���˵ȵȡ��Ҹ��㴫��ȥ�������Ϣ��ʵ��һ������ͼ��Ƭ��(PG:parse graph)���������ͼ��Ƭ�ζ����������������һ��״̬���߿��ܷ�����״̬�����������״̬Ҳ�п��ܾ������Դ�Mind�����һ���뷨���о�����̬(fluents)������,�ܶ�Ů������绰,���������ࡱ,���ڽ������ĵ�һЩ�������ܡ�
���û�������ͬ���ⲿ����,���Ҹ����Ͳ�֪������˵ʲô����������˾���һ��һ��Ц��,���ǿ����������������й���˵��������,���Ƿdz��ḻ��һ���Ļ�����,���Ƕ�����˭��������,������������С��Ը�ͼ�ֵ��,���ֵ�������������ˡ�Shannon��ͨѶ����ֻ�����뱾�Ľ���(������Ƶ�����)��ͨѶ����(3G,4G,5G)��1948�������Ϣ�ۺ�,�����кܶ�����ˡ���ѧ����ǿ���˽����������,�������һֱû��ʲô���ͻ�ơ�Ϊʲô?��Ϊ���Ǻ����˼������ش����ʶ�۵�����,�ܶ���̸:
��Ӧ��Ҫ��һ��:���Դ������Ƿ������һ����ͬ������ģ��?����,����֮��,��Ҳ����������������?������⡣��ô�ҷ������Ϣ��ʱ��,���Ҫ����������������⡣?
��Ӧ��Ҫ��һ��:ΪʲôҪ�������Ϣ?���Dz����Ѿ�֪����,�ҹز���ע�����Ϣ��?�Ұ���������?������ʲô��Ӧ?��һ�仰˵��ȥ��ʲô�����??
��Ҫ��һ��:��ΪʲôҪ�������Ϣ��?�㷢������ʲô��ͼ?��������֪�����,�ݹ�ѭ������֪,�ڱ���֮�⡣����,ͨѶ���۾�ֻ�ܷ���,������ǰ�籨��¥�ķ���Ա,��Ǯ����,���Dz����㷢���Ķ��������ݺͺ����
�ݹ���������,�й�����������ʵ���˲�����ν�������־���ȫ�ǡ�����ͨѶ����ÿ���־����ⲿ�����һ��ͼƬ����һ����������,����Ҫ����롣�Ҿ����о���Ȼ���Ե��˺��о��Ӿ�ͳ�ƽ�ģ����,��Ҫ�úÿ����й��ļ���,Ȼ��,���е����鶼����ˡ�ÿ�������־���һ��ͼ,ͼ��ʲô?�����ľ���һ������ͼ��Ƭ��(fragment of parse graph)��?

�������ͼ��һ�����ֵ��ݱ��ϵͼ,��һ����������������������ġ�����ǰ,�ҵ�̨�����,�����Ȿ����,������˼�����ͼ�Ǵ��۾���ʼ��һϵ�����֡����ȴӾ���Ķ�����ʼ,���м���һ���۾�,��Ŀ����,���ִ����۾�����,����վ������������,���ǡ�����(look)��Ȼ���ǻ���,���硰ʡ��,����ϸ��,�������,��һ����С��Ҷ�����۾�����,ָʾ˵�㿴Ҷ������Ķ���,��ʾ��Ҫϸ����Ȼ��ʼ�������ĸ���,����attribute��ʱ����ô����,�������Ǽ�������,��ʾ��������ֹ,��ʾ�˵Ĺ�ϵ,�˵��Դ�״̬,���������������¡�������,һֱ���ݿ�������,���Ӿ���֪��,Ҫ�������幦�ܾ�Ҫ�ݵ�ʯ��ʱ��ȥ,�����Ե�Ҫ�ݵ�������Դ��
��ͼ����һ������:�ա��¡�ɽ��ˮ��ľ;�����㡢���������ɫ��ͼ������ʵ���������ü�����Ӿ�������ͼ���еõ���һЩ����ı���ͼģ��,��ʵ�����·���һЩ������ļ��ġ����������YiHong,˾�����Ȳ�ʿ�����ලѧϰ�����ǵ��㷨�����˴��������ͷ�����Ӻͽš�ˮ����ˮ�ݵȡ�����ġ����ʷ��š������Ӿ��ı���ģ���ǿɽ���explainable��ֱ�۵ġ�����,������ʽģ�͵ĽǶ�����,���Ծ����Ӿ�,�Ӿ��������ԡ�

�����������ʡ���������,����ɶ��˼?��һ����,��ֻ��,һ������,���ϵ���һ������,�ø�����ק���ڶ����ܼ�,ϴ�֡������ǹ��š�������Ԯ����Ԯ��,һֻ�ְ�����һ���˵���������������Ҳ��������,һ���ֳ���һ���ֳ���,ɶ��˼?�Ҹ��㶫��,����ܡ��������������,���������෴�ķ����������������������졣������,���Ѿ���ʾ���˺���֮��Ķ���ϸ�ڡ�

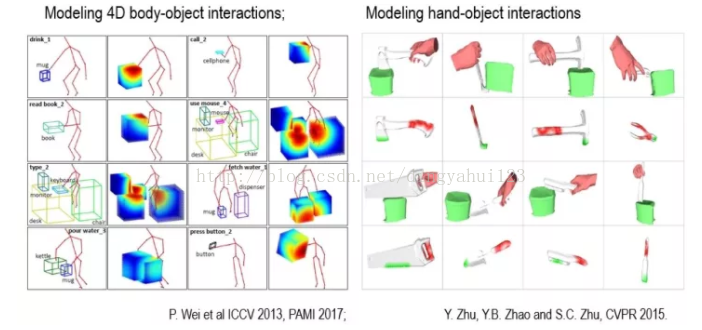
�����ҵ�ʵ������,�����Ҳ���Զ�ѧ��������ġ��Ķ��ʵı���,����ͼ������ѧ��������Щ�����˽����Ķ�������:�������ֻ������֡������˵ȵȡ����ǰ���Щ����ģ�ͷֱ����4DHOI (4D Human-Object Interaction)��4Dhoi(4D hand-object interaction)��4DHHI (4D Human-Human Interaction)��?
�Ҹղ�˵�����ʺͶ���,���кܶ������Ķ���,�ҽ�������ȥ�о�һ��,Ҫ��ģ�͵Ļ����ǹŴ��ļ�����ʵ����һ��ģ��,���ܹ�������������������Ҫ����Ķ��������������,��һ���걸�˵�����ģ�͡�
���پٸ����Ӻͳ��������,���ǹŴ�����ô������������,�dz���Ư��!
������̸��,��ҵ��Ļ����˽�������Ժ�,�Dz��ǻ�Σ����������,���������˺ܶ����ۡ���һ���Ҳμ�һ��DARPA�ڲ�����,���������˸�������������������,���������������ѧ����֪��ѧ���˹����ܵ�ѧ�ơ����Ī��һ�ǡ��ֵ���������,�Ҿ�˵,��ʵ�������,�й��Ŵ��˵��ǻ۾��Ѿ�������ˡ��������µġ��¡�����ô�����?ʲô�е���?���¹淶��ʲô,���Ǹ���ԵĶ���,����ʱ�����Ⱥ���仯���Ҹ���������ʱ��,����������̥������ͬ����,���ڶ������ˡ��й���ǰ��Ů�������ļޡ���������ʮ��ǰ,���ڼ��綼��˵�����Ĺ��:���һ����Ů��·��,����Ӱ��Ͷ��һ����������,���Ǵ�,������·�����ƿ�,�����һ�����淶��?
����������¡����㿴�����˫����,˫������ʵ����������,˫�����ڼ��Ļ�����ʮ��·��(�����ұ��Ǹ�ͼ),ʮ��·�ھ���˵����Ҫ����ѡ��,�Ǹ����ߡ�����ôѡ��?����˵һ�����˵��ڵ���,���Ƿ������Dz�����?�����һ��ѡ��̰��̰�ۡ��ܲ��ܻ��ⶼ�����ĵ�һ��ѡ�����ѡ������������������,���������и����֡�����ô�ж������ĵ�ѡ��������ϵ�����?�����ܰѴ������������г���,һ������Ҳû��������ô������ݰɡ����¡���������һ��ʮ��,ʮ������һ����,��ʵ������,�����۾�,ʮ���۾������㡣������Ⱥ�������еġ�����൱��������������,�����Ŷ�����ͨ��������ѡ������(���Ǹ���һ��ķ��ɹ淶��)������������������������ܹ����ܾ��ǵ���,����������Ǿ��Dz����¡�����,������ѡ���ʱ��,���뿼����Χ�˵Ŀ���,�˼��Դ������ô��,�ž����������������������,���û����һ�ڽ�����֪����,Ҳ��������������ƶϱ��˵�˼��,�Ǿ���֪�������������о������˵�һ������Ҫ��һ��������:����Ҫȥ������������֪���ò���������ô��������һ��(���൱����������simulation):��������������,�˻���ʲô��Ӧ,�����Ӧ�þ���,�����Ӧ���þͲ���,����ôһ�������Բ���Ӧ��䡣������ô֪������ô�����?���������˽���,��ϲ��ʲô�����ʲô��ÿ���˶���һ��,���ڲ�ͬ��Ⱥ������,��Щ����˵,��Щ������˵,������ﶼ֪��,����ǽ���,��û���ⷽ��֪ʶ����ô������?�����һ��Ǿ������ǹŴ����˺����ǻ�,���������ڵ��������̵Ķ�,һ���־Ͱ�һ������˵�úܾ��١��������ڴ��˲�������,��Ϊ�㲻��Ҫ��������,����ý�塢��浽������,ʱʱ�̿������������,��⿴����������,�����ʲô��!ֻҪ���־ͺ��ˡ�����,���ǻص�����ͨѶ����������˶Ի������⡣��ͼ�����������һ����֪ģ�͡�?

������֮������Ҫ��������Դ�minds:��֪���Ķ�������֪���Ķ�������֪����֪���Ķ�������֪����֪���Ķ��������ǹ�֪ͬ���Ķ���������,�Ի���ʱ�������ͼ��ʲô�ȵ�������⡣�����Ҳ�����ô���ˡ�
���,����̸һ��,�������Ӿ���������ϵ������ѧ�д������˵���ϵ������ѧ��ʲô��˼?����˵ͼ��ռ�,���Կռ�,����һ����,ȫ�������ǵ�ÿ����������������һ���Ӽ�,����˵,���е�ͼ����һ������,һ��������ؾ���һ����ά�ռ�,ÿ��ͼ����������ά�ռ��һ���㡣�����Ǹ�����,���е�������������һ����ά�ռ��һ���Ӽ�,��������Ӽ����������Ӽ�Ҫ������ϵ,�����ϵ�����˹�ϵ����������˰��������,��Ӧ�ڴ������ˡ�����,ͷ�Ͳ����ڼ�����ǺϹ��,���ʺܸߡ����ͼ��ռ�Ľṹ��ʵ�����,��������STC-AOG,ʱ����������ͼ����ɵ��������ԡ�,���Ծ���һ��������ľ��ӵ��ܵļ��ϡ�STC-AOG����֪ʶ���������,�����ǿ�������ǰÿһ����������STC-AOG��������ʱ���������ͼSTC-PG��������Ӿ�����,���Կ϶�����,��֪����,����������滮Ҳ�����������һ��ͳһ�ı��
�ڰ˽� ��������:��ȡ����������ļ�ֵ��
������Ҫ���˽���,�����붮�������ֵ�ۡ���ѧ�;���ѧ������һ����������,��Ϊһ�����Ե���(rational agent),������Ϊ�;��߶�������ͼ�ֵ����,�������Լ������������˶�Ӧ���Ƿ����Ե��ˡ��������Ե���,��ͨ���۲�������Ϊ��ѡ��,�Ϳ��Է���������ѧϰ���������ļ�ֵ�ۡ�������ʱ�ų����п��ܹ����װ���Ի����ǵ�����������ֵ�����ǰ�������Ϊһ�����溯��Utility function,��һ������U��ʾ����ͨ������������:(1)Loss��ʧ����,����Reward��������;(2)Cost���Ѻ���������˵,����һ���µõ���������,���Ѷ��ٳɱ������ǿ���������溯����������̬��(fluents)�ռ����档����ÿ���ж�,�ı�ijЩ��̬,�Ӷ���U����Ŀռ���������,Ҳ���ǡ���ֵ�����ɺ���U����̬����F���ֵĻ�,�͵õ�һ������������ϰһ�¸ߵ���ѧ,���Ǽ���һ������ij��ʱ��,���ļ�ֵȡ����ì�ܵġ�����,�������ΪA��B��,B��C��,Ȼ��C��A��,�Ǿ�ѭ����,��ֵ�۾Ͳ���ǡ�����ڳ����о���һ�������С���һ���������������ij�,�ͽ���һ�����س�������ڵļ�ֵ��U����һ�����ܺ�������ν�������ߴ��ߡ�ˮ���ʹ�����˵��������������������ͬ����,������ȫһ�¡������˺�ˮ���ڰ��ո��Ե����ܺ������˶�!��ô�����˵����ܺ�����ʲô��?�����˵ļ�ֵ��ͬ,����ͬһ����,��ֵ��Ҳ�ڸı䡣���IJ�������Щ������ļ�ֵ��,����ָ����һЩ������ġ���ʶ�Եġ����ͬ�ļ�ֵ�ۡ�����˵�ѷ�����ʰ�ɾ���,�������ǵĹ�ʶ��?
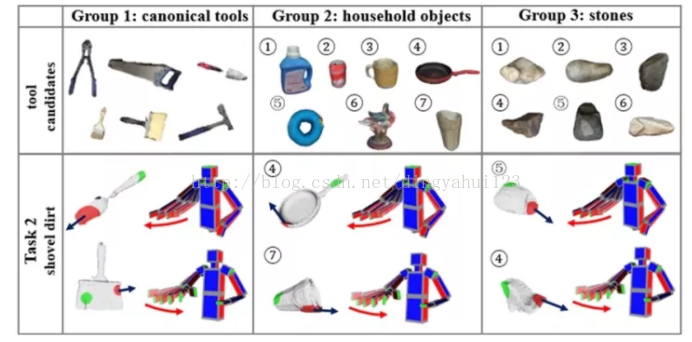
��ͼ��������һ����ʵ�顣�ҰѼ��ֲ�ͬ�����ӡ����ӷ����Ұ칫��(��ͼ)��ʵ����(��ͼ)��Ȼ��,��ͳ��һ��ѧ�������Ժ�,��ϲ�����ĸ�����,ʵ�ڲ��п��������ϡ������ҾͿ��Եõ���Щ���ӵ�����A��B��C��D��E��F��G�Ÿ���,�������ͳ��ͼ���ҹ۲�����Щ�˵�ѡ��,����:Ϊʲô������ӱ��Ǹ����Ӻ�?��ʲô��?����ʵ�ͷ�ӳ���˵��Դ�����һ�������ļ�ֵ��������˵һ��:����ͨ���ճ�����,�̺���̵ĵ�·��ƻ����ز���������?���˾�ռ�����,�Ͳ�ȥ����������ˡ�
Ϊ�˽������,�ҵ�������ʿ�������κ�������ͼ��ѧ�Ľ�����(���ո�ȥUpenn���ݴ�ѧ����������),��ͼ��ѧ����������ģ��ģ���˵ĸ��ֵ�����,Ȼ��������Щ��������Щ�����ϵ�ʱ��,���弸���������ֲ�ͼ������ͼ,���米�����β���ͷ���ܶ�������
��ͼ����ɫ��ֱ��ͼ��ʾ���������岿λ�������ֱ�ͼ���ɴ����ǾͿ��������ÿ��ά�ȵļ�ֵ����������ͼ��������ɫ�������Ǹ��ļ�ֵ����,���˵�����ʹ�ø���λ�������ں��߽ϵ͵�ֵ,���нϸߵġ���ֵ��,Ҳ�������á����������Ȼÿ���˿��ܲ�һ��,�е������۱�����Ӳ������е���ϲ������ɳ������Ҳ��Ϊʲô,�����۲쵽��Щ����,�����Ƶ������ij�ط����������ˡ�?
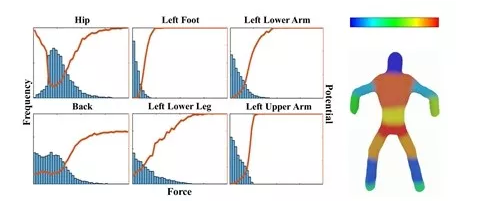
��������,�㲻��Ҫ��:�ⲻ�������������ܺ���,��������,һ����?��,����һ����������Ҳ�������һ���ҽ�Ҫ˵��:�������ţ�ٵ�������ϵҪͳһ����������dz�ʶ,���ǻ����˱��������ܶ������ij�ʶ,TA��Ҫ��������Ϊ������,����Ͳ������ˡ����·�Ҳ��������������һ�����ӡ�������ǰ�������ص����ܺ������ӻ�Ϊһ������ͼ,��ô���һ���·��Ĺ���,������һ����ɽ��·��������·�����ԭ��������,����Ӧ��״̬�ڹȵ�,�������˾͵����ϵ�ɽ���ˡ�ÿһ����������һ������reward���Ҹ�������·��Ĺ���,����ɽ��״����������,������֪�����·��������ı�����ʲô��������µ��·�,��Ҳ����ˡ������˿����ж���ļ�ֵ�ۡ�
������̸�۽϶���ǻ���������,�ر�����Χ��,��ȷ�̼��˹��˵��������������һ���ؼ�����ѧϰ��ֵ����,����ÿһ�����ܵ����,��Ҫ��һ����ȷ�ļ�ֵ�жϡ����,������Ϸ������ǿѧϰҲ�Ƚϻ��ȡ�����Щ�о������ڼķ��ſռ������档��ʵ������������������������ʵ����,ѧϰ�˵ļ�ֵ���������˼�ֵ����,��һ�����˻�����,�����˾��������,�γ�������һ��̸�������淶���������¡���Щ���������淶������Ⱥ�ھ�������֮��,�ܵ��ⲿ�������������������,��ɵ���ʱ��ƽ��̬��ÿ��ƽ��̬��������һ���̶��Ĺ���,Ҫ������ͬ���Ĺ涨����,����һ�ָ��ʵġ���Ϊ�������������ʵ�������˵����,���һ�ָ��ʵ�ʱ��������ͼSTC-AOG�ı����������������,����ijЩ�߽������ĸı�(���µļ�������,���������˹�����)���������߸ı�(��ĸ↑��),�����˾ɵ�ƽ��,��ἱ��仯;Ȼ��,����µ�ƽ��̬����ô���淶��Ӧ������һ��ʱ��������ͼSTC-AOG��������һ��ƽ��̬��STC-AOGģ��ȥ����һ��ƽ��̬����,�ͳ�����ν�ġ�ˮ������������
̸������,����˳��Ա�������ѧϰ������
һ������ѧϰ Inductive learning������ͨ���۲������������,��Щ�������Ƕ�ij��ʱ�ڡ�ij������ij����Ⱥ��ɵ�ƽ��̬�Ĺ۲졣Ҳ����ǰ��̸����ǧ���Ļ����γ��봫�С�����ѧϰ�Ľ������һ��ʱ������ĸ���ģ��,�Ұ�������ΪSTC-AOG��ÿ��ʱ�յĶ�����һ��STC-PG,����ͼ��
��������ѧϰ Deductive learning��������������к���,Ҳ���ǴӼ�ֵ����(�����������)����,ֱ���Ƶ�����Щƽ��̬,���ҿ���,��Ҳ��һ��STC-AOG�����Ҫ����о��Ķ�������̵ġ�����ʽ��ģ�ͺ����⡣����,�����������ɽ,�Ȳ鿴����,֪���Լ��Ķ��顢�������,���������˾��ܲ�����(�����Ը�)��Ȼ��,���Դ���������,��֪����ô�����ˡ��˵�ѧϰ���������ߵĽ�ϡ������ʱ��,����ѧϰ�õö�һЩ,����ѧϰ������һ�ֲ�����嶯,����ѧ��,��Ҳ���ܷ���������ء����ˡ���ʮ������ʱ��,��ֵ�۳�����,��ֵ�۸��ǵĿռ�Ҳ������ȫ��,��ô�����Ͼ�������ѧϰ��AlphaGo����ͨ������ѧϰ,ѧϰ����������;Ȼ��,���������ȫ������ѧϰ�ˡ�AlphaGo����ֿռ�����������Ŀռ临�ӶȻ���û���ȵġ�����,�����ÿ��������ϵ,һ��������ȥ,����ȷ���ġ��˵�ÿ�������Ľ�����кܶȷ������,����Ҫ���ѵöࡣ
�ھŽ� ������ѧ:����������ƽ̨
���ڵ��Ľ�̸���˹������о�����֪����,Ӧ����С���ݡ�������ʽ�������˾�����ôһ��������Ŀ���ƽ̨��������Ҫ�����Ӿ�ʶ�����Խ�������֪����������,��Ҫִ�д������ж�ȥ�ı价�����ҾͲ����ܻ�е������Щ������,�����������ṩ��ͨ�û�����ƽ̨��ǰ����ܹ�,�˺ͻ�����Ҫִ������,������ֽ��һ�����Ķ���,��ÿ����������Ҫ�ı价���е���̬���Ұ���̬����������:?
(1)������̬ (Physical Fluents):����ͼ���,ˢ�ᡢ�տ�ˮ���ϵذ塢�вˡ�?
(2)�����̬ (Social Fluents): ����ͼ�ұ�,�ԡ��ȡ� �𡢲��,�Ǹı��Լ��ڲ�����״̬������������˵Ĺ�ϵ��

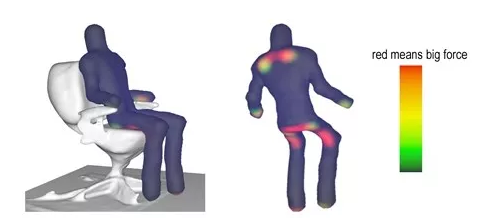
���������ؽ�����ά������(��̸�Ӿ���ʱ���ᵽ��,����ʵ��һ���������������ĵ������ɵĹ���),���ʹ��Ź�����������۹������������������ͼ��ʾ,�ĸ��ط�����վ,�ĸ��ط�������,�ĸ��ط����Ե�ˮ�ȵȡ�����ͼ�����ĵط���ʾ����ִ��ij����������Щͼ�ڻ����˹滮���ֽ���Affordance Map����˼��:����������Ը����ṩʲô??

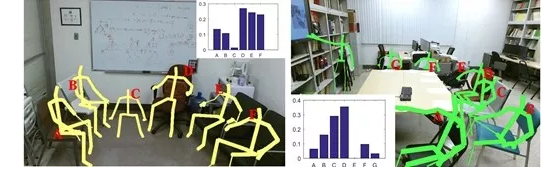
������Щ������������ĵ�ͼ,�����˾Ϳ���������Ĺ滮������滮��������һ����λ��ı���������ж��ַ���,�һ��ǰ���ͳһ����һ��STC-PG���������,��ʵ�൱����,��Ϊ��һ����,һ��Ҫ���Ͽ����³�����ģ�͡���Ϊ��ǰ����ܹ�,�Ի�����ά��״�ļ��㾫���Ǹ���������Ҫ��������,Ҳ����Task-Centered�Ӿ������������ƻ��Ĺ��̻�Ҫ������������ǵ������б��˵ķ�Ӧ�����ǵĶ���Խ��,����Խ����,���¾͵��塢��ççײײ����һ��ʼ�������Ǹ������˾���,��Щ��֪�滮��������ʵ��������һȺ�ں�̨ң�ص��ˡ�����,�Ҿͼ��ܼ�����ʵ���ҵõ��ij�����ʾ���,��̨û��ң�ص��ˡ���ʵ�����õ���һ��ͨ�õ�Baxter������,����һ�������ƶ��ĵ���������ץ��(grippers),����һЩ������������ͷ�ȡ�����ץ���Dz�ͬ��,����������,������������˼����,�����۲����Ϻ�ȶ���,��������ǯ��Ҳ�Dz�ͬ��,һ���������顢һ���Ǿ��״�ġ�
��ͼ��һ����ʿ��������̻��˻����˼����罻����,�������֡����ֿ���ƽ��,��ʵ�dz�������߹�ȥ��һ�������ֵĹ�����,����ʵ��Ҫ����ж϶Է�����ͼ;����,��������ξ��档����������������ý�嶼��������

���������ͼ�ǻ��������һ���ۺϵ�������������������ȥ����,�ƶ�����Ҫ����,����ȥ���š����,����������������ø��������,˫�ֱ�ռ��,������Ҫ������ͨ���Ի�,��֪���Է�Ҫ�ѵ���ŵ���������,��������ȥ���˿��������(����ͼ)���������������,����һ��������ץ���ֹ�,ҡ��ҡ,���������������ƶ������Ҫ��ˮ,�����ֹ��ǿյ�(���ɼ�����̬)��������֪���п����ڱ���,������Ϳ��������ÿ���,Ȼ��ݸ��ˡ�

��Ȼ,�����������,Ҫ�ܹ������Ĺ�����������һ�������Ļ�,�Ǿͻ����ܽӽ�����ǰ���ᵽ�Ŀɾ�����ѻ�ˡ����ǻ���Ŭ����!
��ʮ�� ����ѧϰ:ѧϰ�ļ��͡�ͣ�����⡱
ǰ��̸���������,���ڸ��������ϵġ���������,��Domains������Ŭ������Щ�������һ���������˼��,Ѱ��һ��ͳһ�ı������㷨�������Ҫ���ܵĻ���ѧϰ,���о��������������(Methods),�о����ȥ��ϡ���ȡ�������Щ֪ʶ������ȷ�,�����������������ֶ���,����ѧϰ���о�����,ϣ��ȥ����Щ���Ӵ���ȥ�����ѧϰ����һ�ѱȽϺ��õĴ��ӡ���Ȼ,��������������Ҳ�����˺ܶസ�ӡ�ֻ��������⼸�����ѧϰ��Ѵ��ӱȽ����С����Ϲ��ڻ���ѧϰ�����ۺܶ�,����������һ����������,����̽��:ѧϰ�ļ����롰ͣ�����⡱��
��Ҷ�֪��,�������ѧ������һ��������ͼ��ͣ��Halting����,�����ж�ͼ����ڼ���������Ƿ��ͣ���ˡ������һ��ѧϰ��ͣ������:ѧϰӦ����һ������������ͨѶ�Ĺ���,������������ǻ������ǵ���֪���ܵġ���ô,��ʲô������,ѧϰ���̻���ֹ��?��ѧϰ������ֹ��,ϵͳҲ�ʹﵽ�˼��ޡ�����,�е�������;�����ѧϰ�ˡ�
����,����ʲô��ѧϰ?
��ǰ������Ļ���ѧϰ,��ʵ��һ��������Ķ���,������������ѧϰ���̡�����ͼ�� ���Ͱ�������:?
(1)�㶨��һ����ʧ����loss function ����u,����һ��С����,��������ʶ��,���˾ͽ���1,���˾���-1��?
(2)��ѡ��һ��ģ��,����һ��10-���������,�����м��ڸ�����theta,��Ҫͨ����������ϡ�?
(3)���õ���������,����������˸������˱�ע������,Ȼ��Ϳ�ʼ��ϲ����ˡ�?
�������û�����,û�л������ж�,�Ǵ���ġ�������ͳ��ѧϰ��Ŀǰ��Щ���Ӿ�ʶ�������ʶ������һ�ࡣ?

��ʵ������ѧϰ��һ�������Ĺ��̡� ���������ѧ���ĶԻ�,���ǽ�ѧ��Ҳ������һ�����̡� ѧ����������ʦ,��ʦ��ѧ��,��ͬ˼��,��һ��ƽ�Ƚ���,������ͨ�������⺣����Ѽʽ��ѵ����̹��˵,����Ȼ�ǽ���,���ھͳ������ҵIJ�ʿ������ѧ����֪ʶ�����ѧϰ�����ǽ�������֪����֮�ϵ�(�����ڽ����Ĺ���)���Ұ����ֹ����ѧϰ����ͨѶѧϰCommunicative Learning,����ͼ��?
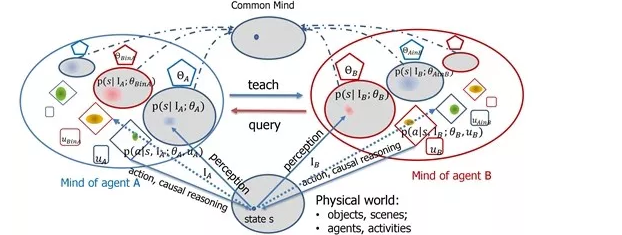
���ͼ������������A��B�Ľ���,һ������ʦ,һ����ѧ��,��ȫ�ǶԵȵĽṹ,�����˽���ѧ��һ��ƽ�ȵĻ������̡�ÿ����Բ����һ���Դ�mind,�������������:֪ʶtheta�����ߺ���pi����ֵ����mu������µ��Ǹ���Բ������������,Ҳ���ǡ��ϵۡ��Դ�����֪���Ķ����������м���Ǹ���Բ����˫����ɵĹ�ʶ��
���ͨѶѧϰ�Ĺ�������,�Ͱ����˴�����ѧϰģʽ,������������ѧϰģʽ(ÿ��ѧϰģʽ��ʵ��Ӧ��ͼ�е�ij����������ͷ),�����滹�кܶ�ģʽ���Կ���������?
(1)����ͳ��ѧϰpassive statistical learning:����ո�̸���ġ���ǰ�����е�ѧϰģʽ,�ô��������ģ�͡�?
(2)����ѧϰactive learning:ѧ����������ʦ����Ҫ����,����ڻ���ѧϰ����Ҳ���й���?
(3)�㷨��ѧalgorithmic teaching:��ʦ��������ѧ���Ľ�չ������,Ȼ��,�������������ѧ�����dzɱ��Ƚϸߵġ�����������ʦ�Ľ�ѧ��ʽ��?
(4) ��ʾѧϰlearning from demonstration:���ǻ�����ѧ�����泣�õ�,�����ְ��ֽл�������������һ��������ģ��ѧϰimmitation learning��?
(5)��֪���ѧϰperceptual causality:�����ҷ�����һ��,����ͨ���۲������Ϊ�����,������Ҫȥ��ʵ����֤,ѧϰ���������ģ��,����������֪��ʮ���ձ顣?
(6)���ѧϰcausal learning:ͨ������ʵ��, ������������, ���õ����ɿ������ģ��, ��ѧʵ������������һ�ࡣ?
(7)��ǿѧϰreinforcement learning:����ȥѧϰ���ߺ������ֵ������һ�ַ�����
���ڵ�һ��̸����,���ѧϰֻ���������ѧϰ���������С��һ����,��ѧϰ�����˹���������һ����������,�����ѧϰ��ͬ���˹�����,������������졢�Թܿ�����
���,ѧϰ�ļ�����ʲô?ͣ��������ʲô?
���ڱ�����ͳ��ѧϰ,�������кܶ���������������ߴ����ʵ����ޡ���������˵��ѧϰ�ļ���ԶԶ��Խ����Щ���塣����ָ��������ѧϰ�����ܷ�����?��������?ѧϰ��ͣ������,�������ѧϰ������ô��ֹ�����⡣����Щ����,�Һ���Ӣ������дһ���������¡�
����ѧϰ��̸���Ĺ���,��ʵ����ij����Ϣ����Щ��Բ֮�������Ĺ��̡���ôӰ��������������ؾͺܶ�,���оټ������¡�
(1)����ѧ�Ķ���:��ʦҪȥ��ѧ��һ��֪ʶ�����ߡ���ֵ,����������ȷ���Լ�֪������ѧ����֪������¡�ͬ��,ѧ��ȥ����ʦ,��Ҳ������ʶ���Լ���֪��,�������ʦ֪������ô,һ���ؼ���,˫�����Լ��ͶԷ���һ��ȷ�Ĺ��ơ�
(2)����ѧ�ķ���:�����ʦȷ֪��ѧ���Ľ���,�Ϳ���ȷ���ṩ��֪ʶ,�����ظ�������algorithmic learning �� perceptual causality��������ԡ�
(3)��������:���ȥ����һ������������?�ܶද��,��Щ��������ô�̶��̲��ᡣ
(4)��ֵ����:������ijЩ֪ʶ������Ȥ,�ǿ϶�����ѧ����ֵ���������,�Ǹ�����������,����̸�������ѧϰ�ˡ�������Ⱥ�����е��˾ʹ�����,��Ⱥ��,��Ϊ�����㲻һ��,��������һ��ȥ,���ͬһ��Ⱥ����������һ��ȥ��,������ǿ������ij�̶ֳ�����������ķ��ѡ�
���ѧϰ�������趨������ͬ,����ѧϰ�϶�����������ͬһ���ط����й�14����,��14�ڸ���ͬ����ģ��,��14�����м�,�ֲ�����һЩ��ʶ,Ҳ���ǹ�����ģ�͡���˵��ͣ������,���������̬����������ɵĸ���ƽ��̬��
��ʮһ�� �ܽ�:���ܿ�ѧ �� ţ��������������ϵ��ͳһ
����,��ժҪ�������˹����������������һЩǰ������,ϣ��������ҿ���һ�����µ�����������,��������,������һ����ͬ����֪��������������ͳһ�������кܶ༤�����ĵ�ǰ�ؿ���,�ȴ�������ȥ̽������ô�˹����������������߽С�ս�����ۡ�,��δӵ�ǰ�ֺ��Ĺ���ʵ��,��Ϊһ�ų���Ŀ�ѧ��ϵ��?���˹�����Artificial Intelligence��� ���ܿ�ѧScience of Intelligence,���߽� Intelligence Science,���ͳһ�Ŀ�ѧ��ϵӦ����ʲô?
ʲô�п�ѧ?����ѧ������Ϊֹ��չ��Ϊ���Ƶ�һ�ſ�ѧ,���ǿ��Խ������ѧ��չ����ʷ�����Լ��ر�ϲ������ѧ,1986�걨���пƴ��ʱ��,����д��־Ը���ǽ�������(4ϵ)������־Ը�Ժ�,�Ҿͻ�����ȥ�ˡ��Ҹ�統ʱ������ĸɲ�,��ȥ���в鿴�ҵ�־Ը,һ������������,ֻ�½��������ҹ���,�����Ҹı����������ʱ���Ƕ�û���������,��Ҳû��������,�������������ײ����������˵�רҵ,�������������������ѧ֮����
�ȵ���ѧ,�ϡ���ѧ���ۡ��Ŀ�,�̲��ǵ�ʱ����У����д��,������Ͳ���������,��Ҷ�֪��,���ǿƴ���һ������������ļ��䡣������ĵ�һҳ,�Ҿͱ����۵��������ˡ�������һ����ͼ,�����ص����仰,�������¡�

(1)����ѧ�ķ�չ����һ�������������ͳһ����ʷ����һ�δ��ͳһ����ţ�ٵľ�����ѧ, ͨ��������������������˶������Ŀ��Ƹ��ӵ������˶�����һ��ͳһ�Ľ��͡��γ�һ����ѧ����ϵ,�Ӵ�Ҳ�ᶨ�˴�ҵ�����:?
��������������������������������?
����ѧ�����ξ���Ѱ��֧����Ȼ���������ͳһ����������ȫ��һ������,��������,��Ϊ��Ŭ��!��ţ������,300������,����ѧ�һ��ڷܶ�,������һ�����������ģ�͡����������ѧ,��̾����,�˹����ܵ��о�,��ĿǰΪֹ,���ٹ�ע�����ѧ�����⡣�����Ĺ���ѧԺҲ�����������,���æ�Ž�һЩ���ܡ����һЩС����,���Ӿ��ܹ��ú����80�����Щ֪�����ڹ���������������ô����,������������ͳһ�Ľ���,�������ǡ�a bag of tricks��һ����Ĺ�ơ���һЩ������������ˮ�����ڡ��Ĺ��̷�������ˡ��Ȼ�Ƿ�dz�Ͷ��ӵġ�
�ҵIJ�ʿ��ʦMumford1980����Ӵ���ѧת��ѧϰ���о��˹�����,����������Ϊ���ܹ���һ����ѧ��ϵ(mathematics of intelligence)������������������ת���Ǽ��䲻����(���кܶ����˵�ͷ��,�����ƶ��Ƚ�����˰�ɪ��Ž���������ѧ��Э����ϯ���������ҿ�ѧѫ��), ���ҵ�Ŀǰ��û�м����ڶ�����ôת�͵Ĵ�ҡ� 1991���Ҷ����ѧ,�����о���Ժ�ĸ��˳���(Statement of Purpose)�о����¶��������Ҫ̽������һ��ͳһ��ܡ���ʱҲû�л�����,��Ҳû����˵��Mumford���ǵõ�ʱ�ƴ�����ϵ�ո����˵�һ̨�����ӡ��,�����ʽ��ӡ�������������������롱���̸��ܻ�����ʦ��,����һ��Ҫ���Ұ�����ҳֽ�ĸ��˳����ú��Ű桢��ӡ����!���,��ѧУ���ܾ����ҵ�����,���ҵ�ʦ����¼ȡ���������ʿ��ͬһ��, �ƴ�����ϵһ��ʦ����Ӣ�걻¼ȡ������ͳ��ѧ����,���Ǿͳ������ѡ�����������ͳ�Ƶ�����ʮ�����,��ȥ25������һֱ��һ����������ڻ�ͷ��,������������!
(2)����ѧ���������־�ų����о�֮��,�������������ܿ�ѧҪ�о��Ķ������ܿ�ѧҪ�о�����һ�������������ϵĸ���ϵͳ��������Ϊһ������,�ͱ����ڸ�������Ȼ�����Ⱥ�������ú���Ϊ�����С��Ҹ���������Щ��Ϊ�������Ȼ��ͳһ����������á�����Ԫ������������ʵ��Щ��������Ǹ������Ӿ�������˵һ��Ҳ��İ�������ǵ�ģ��������ģ������ȫ��ͨ��,������һ�����ʷֲ�,������ˡ����ܺ�����,�����˸��֡�����á�, Ȼ������˸��֡������롰��������Щ���������ǰ��û�����������о���,������˹̹���ġ���������һ��������,һ����ѧѧ�ɳ������������ѡ��������ڿ�����,��ǰ���Ѿ�������һЩ����: �Һ��ҡ������ӡ����·������ǿ��Դ������������������õ���,���ڽ����˵ĸ�����Ϊ�����,��������ѧ��л������������á��������ͳ����������˵������, �滹����2017�������֪ѧ���һ�������㽨ģ������ �����Ժ��д���½����ⷽ��Ĺ��������ܿ�ѧ�ĸ���֮������:
(1)����ѧ��Ե���һ���۵�����,�����������ӳ�䵽ÿ��������, �γ�һ����������ںϵ�����,Ҳ����ÿ�������е�ģ��(����ͳ���б�Ҷ˹ѧ�ɹ۵�)�����ģ���ֱ�ӳ�䵽�����Դ�֮�С�ÿ����Mind����������ϰٸ����˵�ģ�͵Ĺ��ơ� ����Щģ���������˵��˶�����Ϊ��
(2)����ѧ���Ѹ��������������о�,������һ��ͼ��Ͱ���������ģʽ, �˵�һ��������������˺ܸ��ӵ������,���Ѹ��뿪������,��ǰ�Դ����ݼ�Ϊ���ݵġ����ѧϰ��ѧ�ɡ���ˢ���ɡ��dz�����,��Ҫ��һ��С���ⵥ���ó����о�,�������Ǹ������ݼ��������ֲ���ʲô���˵ġ������͵���������,���Ǿ͡�ǿ�Ҿܾ���,Ҫ���㵽�������ݼ����ܽ����������ȱ����ѧ��˼ά���������غ�����!�ص�ǰ����ѻ������,���ڵ��Ľ����۵�,�����о�������������ϵͳ����������ǰ��:
һ���������������������������ֵ������������������ġ����衱,�������Ϊ���DZ���������������,�����ɼ�ֵ��������,�������ǽ������е�phenotype landscape,ͨ��˵���ǽ������������档����Ľ�����������������������,��û�и�����ѧ������������ҷ���,����ͻ����ʵ������������������ġ���ʱ��߶��ϵļ�ֵ�����е��ж�action����ǰ���Ǹ����·��ļ�ֵ��������ͼ,���Ǵ�����ѧ�����ġ�
�������������۵���ʵ������������������Ȼ�߶��µ������������������,Ҳ����ţ����ѧ�Ķ�����
˵����,�˹�����Ҫ������ܿ�ѧ,�������ϱؽ��Ǵ������ţ��������������ϵ��ͳһ��

2016���ҵ�ţ���ѧ����Ŀ������,˳��ι����ص�Westminster Abbey ����á� ���Ҿ��ȵ���:ţ��(1642-1727)������(1809-1882)���˵�ĹѨ���Ҳ��2-3��Զ��վ���Ǹ��ص�,�ҵ�ʱʮ�ָп��� �������˿���˵�dz��ı���������۵ġ���ΰ��Ŀ�ѧ����,��������ΰ���������ϵ��˼���ͳһ,��Ҫ�ȶ����?��ƪ���ĵijɸ�����������,���������ƴ�ʫ���������ġ���ʡ�,����˵�����е�һ�־���,���ҹ���:?
���Թŷ��ﱯ����,��������ʤ������?
���һ��������,����ʫ�鵽��������
��¼
�п�Ժ�Զ����о����ٰ�ġ��˹�����ǰ�ؽ�ϰ�ࡪ�˻�����������Ļ�����¼(��������)��
ʱ��:2017��9��24������
������: ���̺���ڽ��ܴ�(��л����֮��,�ڴ�ʡ��)��
�� ������:?
��л̷��ţ��ʦ��ι��պ����̺���ʦ��ʢ�����롣������������,�dz�������˼,��������Ϣʱ�䡣��֪�����ƽʱ����æ,���Ǽ���������һ��,�dz������ס�����,�Ҹ����Ǵ���һ��ɻ�,��Ϊ����������
����Ľ����Ǹ���������,����ʦҪ��̸�˻�����������ʲô���˻�����,��Ҫ�����Щ����?�Ҿͻ���һ��ʱ��������һ���Ƚϳ��Ľ���,����ҽ����˹����ܵķ�չ,���˻���������ϵ�ṹ���������dz���,�����о������ո���,�����Ҫ�Ѻܶ��������һ�����ܿ������µ��������Ҹ������һ��˼·,�������˼��,�Ҳ�����ֱ�Ӹ���һ������������Ļ��Ͱ���������˼���Ŀռ��Ȩ����
2017������ڡ��Ӿ�������������һƪ̸��ѧ��������������,������ѧ�ʵ�һ�����뾳����ǡ�������¡�,Ҳ����ҹ���˾���ʱ��,��ȥ��ѧǰ��̽������������Ľ���,ϣ���Ѵ�Ҵ�����ôһ���տ��ĵط�,ȥ����һ����
���������ʻ���:
����һ:����ʦ,������ôͨ��ѧϰ��������������ʶ���ղ�����ʾ���Ǹ�������,�ſ��и�����Ҫ����,Ta��ô֪���Լ����˰�·���ó���?
��:������ʶ�������dz���Ҫ�����ȼ�Ҫ����һ�±���,�ٻش�������⡣
������ʶ(self-awareness,consciousness)������ѧ��������ܴ�,��������֪ѧ��һ�Ȳ��������ȥ̸�������,���������˶����ò����о����ѡ��˹�������������������̸,����,������ء�������ʶ��������:
(1)��֪���顣���ǻ�Ǯȥ����Ӱ������ɽ��������,��ʵ��ľ���һ�����顣����������һ�ֱȽϵͲ�ε�������ʶ,�γ�һ�ֱ���(�����������潲���Ľ���ͼ)�� �º���Ҳ���Ի�ζ��
(2)�˶����顣������Ȼ�о���,���dz����赸��Ա,��Ҳ�û�п����Լ�����Ϊ����������, ���Ƕ��Լ�����̬�Ͷ���������֪�ġ�����ʱ��֪�����ǵ���̬����ά����������,����ѧʵ��,�����һȺ��(��Ϥ�Ͳ���Ϥ�Ķ���)�Ķ�����̬�ü����ؽڵ����˶���,��¼����,Ȼ��,�Ͱ���Щ��Ÿ��㿴,��ֻ��������˶�,������������Ϣ�����ϳ��ĸ��������Լ��ı��ʸ����ϳ�����,���Ҷ��ӽDz���ô���С�����,����ͨ����֪���˶��ڹ�ͬ����һ�����ҵ���άģ�͡��������ǻ�ͨ��,���������ھ�����Ԫ(mirror neurons)�������ڲ������һ���ؼ�ת�����ơ����������ⷽ��ͱȽ�����ʵ��,�����Լ�����άģ��,�ؽ��д�����,����Visualodometry, ����ʱ�����Լ��ڳ����е���άλ�ú���̬����һ�㲻�ѡ�
(3)��֪֮�����й��и�����������˹�����֪֮���������仰˵,һ���˺�������֪֮�������Լ���������ʶ,��Ҫ�ָ��۵͡������۸��ֵ͡�����������ʶ��Ҫ��ʱ���µġ�����,�Ⱦƺ��ܿ���,�ƹⰵ��ʱ���ҵ�����ʶ�������Ͳ���ôǿ,��������Լ������仯��һ���жϡ�����ÿ���������ܶ���һ����ʵ,����൱�����ˡ�����,�����˽����ձ��������ֳ���,�˷�����ʱ���������˵ĸ���������ͻȻ,��һ����·��ͨ��,һ���ؽ��˶�������,һ���ڴ汻�ƻ��ˡ��������Լ�֪��,�������µ����Լ�������滮��Ŀǰ�˹�����Ҫ������һ��,�dz��ѡ��ղ�˵���˽�����������֪��������,�Ǿ���һ��Э�������Ĺ滮����滮����������Ҫ֪���Է���ʲô����������,���������־���ʵ�Ƿdz����ӵĻ������̡�Ϊ�˴�����Ŀ��,��Ҫ��������ģ��simulate��
���ʶ�:лл�����,�о����������Ķ�������ǰ����û�������Ķ���������һ��������������������������ʶ������,����˵�Ľ�������Ҫȥ����Է��Ǹ��˵��뷨,������Ϣ����ô����ȡ��?Ҳ��ͨ��ѧϰ����?
��:���۲���ʵ�����㿴����������۲쵽,����ܹ�ѧ��ÿ���˶���һ���ļ�ֵ����,����˽����Χ��ͬ��,�������ǹ���һ���칫��,���߹۲����ͥ�������,����������ʱ��Խ��,���Խ��Խ���֪������ô�����⡢��ô����,Ȼ��������ڽ����Ĺ�����Խ��ԽĬ���ˡ����˹۲�,����ʵ��,����ȥ��̽������Է�������֮��,�ս��ᳳ��,֮��Խ��Խ���ˡ���г��,��ֵ���ںϴ��������ˡ������ܹ����������ˡ�ʵ��������,�Ǿͷֵ�����,�������ְ����������������������˵�ġ�ѧϰ��ͣ�����⡱�����֮�䲻Ҫ���������ѧϰ��,Ҫô������ᡢ���ղ���;Ҫô������š���ͬİ·��
������:��Ҳ��ͨ�����Լ��۲쵽,�����潨��һ��ͼ��?һ������ͼ(parse graph)��?
��:���ҿ����������ġ������ұ�������Դ�����ĺܶ�ṹ�����ع�����,���������ǽ���ͼ,���������������Ԫ����洢�������ͼ,���Dz���������Կ϶������Ƶı���,���Դ���������ı����,�ҾͿ���װ��������ĶԸ�������ķ�Ӧ����ѧ���Ҵ�����ʱ��,���Դ�����ͬʱҪװ�¼�ʮ���ϰٺ��˵�ģ�ͺ�֪ʶ����,��Щ��֪��ʲô��ʲôʱ��֪���ġ����ĿƵ���һ��۲�Ƚ����������������ⷽ�������϶�Ҳ�ر�ǿ��
������:�����ǸսӴ�����ѧϰ,����û��ʲô�Ƽ���,��Ϊ���ڴ�Ҷ�����ѵ���������,��û��һ���Ƽ���,���Ǹ���ģ�ͻ���ʲô����,һ����ѧ���ۻ���һ����ѧ���ߡ�
��:�ҵ��뷨��������,�����ô�Ҷ���˼��,��������ѧ,̽��������δ֪������˵��ҹ���˾���ʱ����̽������,�����ľ���������,����Ȼ�Ϳ���һЩ���˺��ԵĶ�������Ҫ�����Ƽ�ij�����ߡ����롢�ؼ�,�������á��ҽ��콲�Ķ�����������Դ��ijһ�����ۡ�����,���ڻ��ͨ��Ľ����
�ҷ������ѧ����,����ѧ�о����ǹ�ȥ���ֵ��������ſ���Ϸ,�������־��������ꡣ����ǰҲ̸����һ����·�Ƶ�������,��ѧ�о�������һ����ڵ�ҹ����Կ��,���ϲ������·�Ƶ�����,���Ǻܿ���Կ�ײ����Ǹ��Ƶ��¡�
������:����ʦ��,�dz����������������,�����һ������ܼ���˵�Ǽ���ʱ��,������һ���س�����ʲôʱ���ܵ�?���س���ʱ��,��ѧ����һ������Ϊ,���ܻᱻ�����س��������������������Ǹ�������ʲô��
��:�ʵúܺá�ʲôʱ���ﵽͳһ?��������й�������˵��,���е�����
һ��˵����������ɽ������������ԶԶ����ǰ���Ǹ�ɽ�쵽��,�����ǰ��,������������������,�м���ܻ��м�������סȥ·���������Ƕ����������Ʋ��㡣
�ڶ���˵���ǡ�Զ�����,������ǰ���� �ܲ��ܵ���,����������ߵ��˵��ǻۺ��ж���ʲôʱ��ͳһ��˭��ͳһ,������������Լ�Ŭ���ˡ������ս��ʱ��,˼���������,���Ӱټ�ȫ����������,����һ��˼�뼤����ײ��ʱ�����ҽ��콲����Щ������ʵ�������Դ����漤�ҵ���ײ,�һ���Щ�����벻ͨ��
��������̸�������Ϳ��,������������ж���������?�ҵĹ۲���:����,Ҳ��һֻ�־Ϳ������ù�����
��ĵڶ�������,���Ҫͳһ,������������ѧ������ʲô?����Ҫ����ͳһ��֪ʶ����:���ʺ���Ҫ�ں�,�����ѧϰҲҪ�ںϡ����ǿ�������ѧ�����ͳһ��,�����������ģ��(�Ĵ�������������)������Ǣ,Ȼ�����������˵������Ҫ���������:
һ��ʲô�ط���ʲôģ��? �ԱȾ�����ѧ�����ѧ����ѧ��ͳ�����������������ȶ����Լ��������ɺ�ʹ�÷�Χ���������Ҳ����,����ģ�������ǵķ�Χ�ͻ���,�������dz�����˵��,����˹ģ���������ڸ�����,ϡ��ģ���ڵ�����,���ͼ���������������һ������ҵ�ʵ����,������û���������о���
������Щģ��֮�����ת��? ǰ���ҽ���һ������,��д��һƪ������ʽ(�����Ʒ�)����ʽ(ϡ��)ģ�͵�ͳһ����ɵ���Ϣ�߶ȵ�����,Ͷ��CVPR����,���,���������ǡ�(5)ǿ�Ҿܾ�;(5)ǿ�Ҿܾ�;(4)�ܾ�������Ҹ�����û���������,�۾����Ͱ͵ؿ������ݼ������������˶��١�ˢ�����CVPR���е���Ҫ��ʽ����ijЩ������,ˢ�����Ψһ��ʽ������ǰ�������������,����һ��,��ʵӦ�ö�������Ҷ���Щ�Ѵ��ڴ�������ȥ��ѧ���������,��ǰ������,�������ر�м�Ta�ǡ��������Լ���ѧ�����и���ʱ��ȥʵ�����ǵ�˼·�����Ƕ�һ��ӿ������̤���ҿ�����,�Ҷ��㲻���������о�ϲ���徲,��ȥ������,��ȥ��������������Щָ�ꡣ
���̺�����ܽ�(����):��������ڵı���,��ҿ��Ըо������㡣
һ���ݺ����ء��������ᡣ���ۡ����������˹�������������ܶ���̵���Ŀ,�ںܶ�������ݺύ�����,�����÷dz��������������,�շ����硣�dz����������������ı��档
������������������㡣�����������ȥ˼������,���ȥ������,����о�һЩ�������ʵĶ��������������ѧϰ������ǿ��֮��,�кܶʿ������һЩ�о��߹�����������,˼�������������ˡ���ʵ�о���������ô��,��һ��Ҫ̧��ͷ������,�����ǿա�
��л
��л���о�Ժ�����������ա�������Ȳ�ʿ2016��9���ڱ�����֯�����ֻᡣ2017��6������Ÿ�������ա��ւ��Ƚ�����������������Ĵ�ѧ�����ı��档������ʿ��2017��7������ͼ��֯�ı̻���̳��2017��9����̷��ţ���ڹ����¡����̺�������п�Ժ�Զ������ٰ���˹������˻�������ϰ�ࡢ��ָ���ټ�Ա�ͱ�����ʿ��������ͬѧ��������������ij��塣����û�����ǵ����ġ��ߴ١�������Э��,��ƪ���ı����Dz����ܲ����ġ������еIJ���ͼƬ��VCLA@UCLAʵ���������Ρ�κƽ�����������Э��������
��л�пƴ���ҫ�ӽ��ڡ���־��ͬѧ�����ҵ��DZ���صġ���ѧ���ۡ�����ɨ��档�����۱�ժ¼�����С��ҵ�˼���ܵ��Ȿ������ɡ�
��л���Ӿ����������ںű༭�����ٻ������ա���۫���ܲ���ͬ�ʵ�Э����
��л������һ����������ἰ�о��ij���֧�֡�
����:�������ڴ���ѧ���۵������,������κ���֯����,����Ժ����������Ľ��������˹۵㡢����������������
ȫ����