һ��ժҪ
��Ҫ����ѵ��ʱ��,�ֲ�ʽͬ��SGD(Distributed synchronous SGD )ͨ����SGD minibatches���ֵ�һ�����еĽ�������,Ϊ��������ṩ��һ��DZ�ڵĽ��������Ȼ��,Ϊ��ʹ�÷�����Ч,ÿ���������Ĺ������ر���ܴ�,����ζ��SGD minibatch��С�������������ڱ�����,���ǵľ������,��ImageNet���ݼ���,���minibatches�ᵼ���Ż���ȱ��,���������Щ����ʱ,����ѵ����������ֳ��ܺõķ�����������˵,��ʹ�øߴ�8192��ͼ���minibatchѵ��ʱ,����û����ʾ�����ȵ���ʧ��Ϊ��ʵ����һ���,���Dz�����һ���������������Ź���(linear scaling rule),������ѧϰ������Ϊminibatch ��С�ĺ���(for adjusting learning rates as a function of minibatch size ),��������һ���µ���������,�˷���ѵ�����ڵ��Ż���ս��
��������
��������ݼ���������ģ�������������л�ó�����ߵ�ȷ��,�������Ԥѵ����������ģ�ͺ����ݹ�ģ������,ѵ��ʱ��Ҳ�����ӡ����ģ���ѧϰ��DZ���;�����,�����˿����µļ���������ѵ��ʱ��ɿ��Ե����������Ŀ������ʾ���зֲ�ʽͬ������ݶ��½�(distributed synchronous SGD)�Ĵ��ģѵ���Ŀ����ԡ�
�������е�minibatch sizes���ǽ�ѧϰ������Ϊminibatch size�����Ժ���,����ѵ����ǰ������Ӧ��һ���������Ρ����������ij��������ֲ��䡣ʹ�����ּķ���,����ģ�͵�ȷ�Զ���minibatch size�Dz���ġ����ǵļ���ʹѵ��ʱ�����Լ���,Ч��Ϊ90%,ʹ�����ܹ���256��GPU��1Сʱ��ѵ��һ����ȷ��8k minibatch ResNet-50 ģ��
Ϊ�˽������쳣���minibatch,����ʹ����һ���ĺ������������Գ߶ȹ���������ѧϰ�ʡ�Ϊ�˳ɹ���Ӧ����һ����,���������һ���µ���������,����ѵ����ʼʱʹ�ýϵ͵�ѧϰ�ʵIJ���,�Կ˷������Ż������ѡ���Ҫ����,���ǵķ��������������֤���(the baseline validation error)��ƥ��,���һ��ܲ�����С��minibatch��������ƥ���ѵ���������(closely match the small minibatch baseline)�������һЩ�о���ͬ����,���ǵ��ۺ�ʵ�����,�Ż������Ǵ���minibatch����Ҫ����,�����Ƿ����Բ����,���ǻ�֤�����������Ź���(linear scaling rule)�����������ƹ㵽�����ӵ�����,����Ŀ�����ʵ���ָ�,�������������Mask R-CNN֤������һ�㡣����ע�,����ǰ�Ĺ����л�û�����һ������㷺�Ĵ���minibatch��ǿ��ͳɹ���ָ�����롣
��Ȼ�����ṩ�IJ��Ժܼ�,�����ɹ���Ӧ�Á`�����ѧϰ����ʵ����ȷ��,ͨ��������������ʵ��ϸ�ڡ�SGDʵ���е�ϸ�����ܻᵼ�����Է��ֵĴ���Ϊ���ṩ���а�����ָ��,���������˳���������Ϳ��Գ�����Щ��������ʵ��ϸ�ڡ�
���ǵIJ������������п��,��ʵ����Ч������������Ҫǿ���ͨ���㷨������ʹ�ÿ�Դ��Caffe2���ѧϰ��ܺ�Big Basin GPU������,��ʹ�ñ�����̫������(������ר�ŵ�����ӿ�)����Ч�IJ�����
��������������ʵ�ʽ�չ��һϵ�������ж����а������ڹ�ҵ����,���ǵ�ϵͳ�ͷ��˴ӻ�������ģ��������ѵ���Ӿ�ģ�͵�DZ��,ʹÿ��ʹ����ʮ����ͼ���ѵ����Ϊ���ܡ�ͬ����Ҫ����,��һ���о�����,���Ƿ��������Լӵ�GPU����GPUʵ�ֵ�Ǩ���㷨,������Ҫ����������,�����ǵ�ʵ���н�Faster R-CNN��ResNets��1��Ǩ�Ƶ�8��gpu��
2��Large Minibatch SGD
����ͨ����С��������ʽ����ʧL,���о��ලѧϰ:
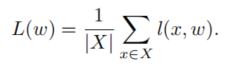
?����w��һ�������Ȩֵ,X��һ����ǵ�ѵ����,l(x,w)�Ǵ�����x�����ǩy���������ʧ��ͨ��,l��һ��������ʧ(���罻����)��һ��������ʧ���ܺ͡�Minibatch SGD��ִ�����¸���:

����B�Ǵ�X�ܲ�����minibatch,n=|B|��minibatch�Ĵ�С,����ѧϰ��,t�ǵ���������ע��,��ʵ��������ʹ�ö���SGD(momentum SGD);���ǻص�֮ǰ���ڶ��������ۡ�
2.1��Minibatch��ѧϰ��
���ǵ�Ŀ����ֻ�ô���minibatch����С��Minibatch,ͬʱ����ѵ���ͷ�����ȷ�ԡ����ڷֲ�ʽѧϰ���ر���Ȥ,��Ϊ��������������ʹ�ü����ݽṹ��������չ�����������,��������ÿ���������Ĺ�������,Ҳ������ģ�͵�ȷ�ԡ��������ǽ���ȫ���ʵ������չʾ��,���Ƿ���һ�µ�ѧϰ�ʳ߶ȹ�����ڹ㷺��minibatch size�Ǿ��˰���Ч��:
Linear Scaling Rule:��minibatch size����k��ʱ,ѧϰ��Ҳ����k����
�������еij�����(Ȩ��˥����)���DZ��ֲ���ġ����Գ߶ȹ�������������ƥ��ʹ��small minibatch �� big minibatch֮��� ȷ��,����ͬ����Ҫ����,�ںܴ�̶���ƥ�����ǵ�ѵ������,����������������֮ǰ���ٵ��ԺͱȽ�ʵ�顣
����:���Ƕ����Գ߶ȹ����Լ�Ϊʲô������Ч�����˷���ʽ�����ۡ�