Unsupervised domain adaptation (UDA) for person re-ID.
UDA methods have attracted much attention because their capability of saving the cost of manual annotations. There are three main categories of methods.
UDA�������ڽ�ʡ���ֹ���ע�Ļ��Ѷ������������ע,������Ҫ�����ַ���:
The first category of clustering-based methods maintains state-of-the-art performance to date
��һ�༯Ⱥʱ������Ҳ���������ŵ�����
- (Fan et al., 2018) proposed to alternatively assign labels for unlabeled training samples and optimize the network with the generated targets.
ԭ������:https://arxiv.org/pdf/1705.10444.pdf
���Ϊδ��ǵ�ѵ��������������ǩ(fine-tune��clustering����Ĺ���),���������ɵ�Ŀ���Ż����硣
1.���������:
(1)���ޱ�ǩ����(�� �������б�ǩ���ݼ��ޱ�ǩ����)ѵ��ģ�͡�
(2)��K-means��CNN���,������cluster̫��noisy�����⡣
(3)���Բ�ѧϰ�������������ģ��ѵ����
2.ѵ������:
step1: ImageNet��Ԥѵ����ResNet
step2: �ò���ص��б�ǩ���ݶ�������г�ʼ��
step3: ���ޱ�ǩ������ι������,���о��ࡣ(���ൽ����������,��γ�ʼ����������)(���������ʼ���ѡ��Ӧ�ú���Ҫ��)
step4: ѡ������������ļ�����,���롰�ɿ�ѵ��������ѵ�����ı�ǩ��Ϊk-means��k��
step5: �����ɿ�ѵ������������ι�������ٴ�ѵ������Ϊģ�ͻ�Խ��Խ��,���Խӽ��������ĵ�����������epoch����,�����ĵ�����֮һ��(Ϊ��������ֲ�����,�ȴӡ��ɿ��ȡ���ߵ�����ѵ����)
step6: ����3,4,5�����ܶ���ʼ��ֱ��ÿ��ѡ��ĸ����ȶ���
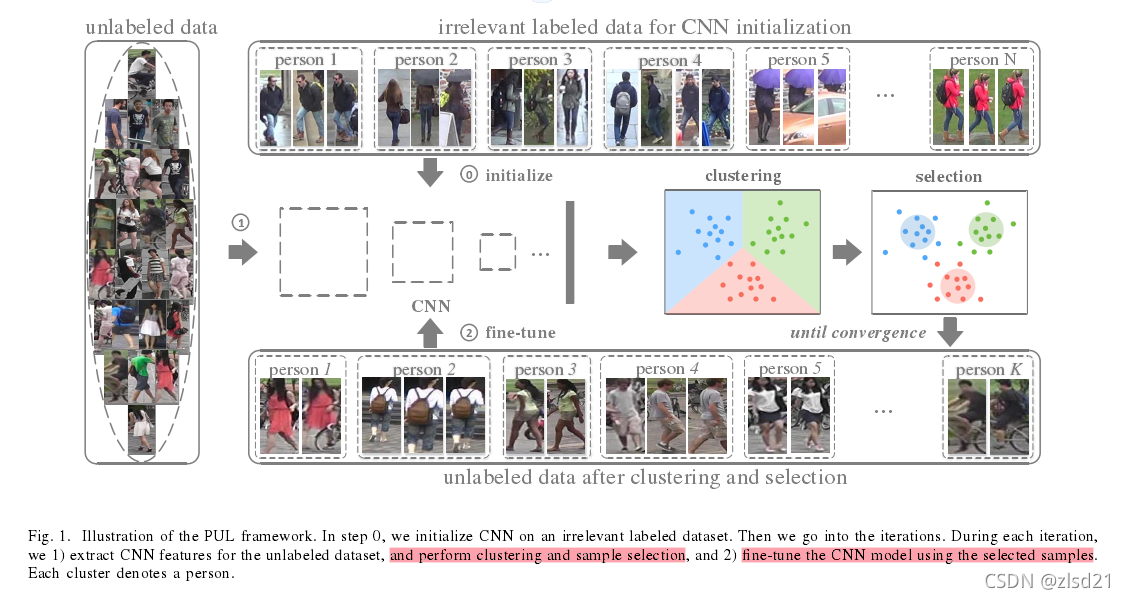
���������һ������self-paced learning(�Բ�ѧϰ)����,�Ҳ���һ��,������ƪ���ͽ�Ϊ����,����Ҳο� https://blog.csdn.net/weixin_37805505/article/details/79144854
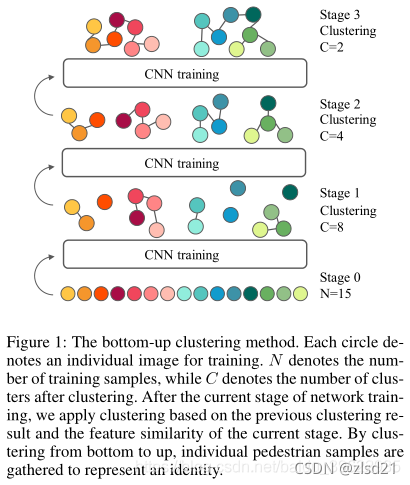
- (Lin et al., 2019) proposed a bottom up clustering framework with a repelled loss.
�����һ�־����ų���ʧ���Զ����µľ�����
����˼��:���ߵķ������ǵ���������ʶ�������������������ʵ:��ͬ�˼��diversity��ͬһ���˼��similarity�����ߵ��㷨�ʼ��ÿ������Ϊ������һ��,�����ÿ���diversity,Ȼ���İ����Ƶ���ϲ�Ϊͬһ��,������ÿ���similarity���������Ե����ϵľ��������������һ����������������ƽ��ÿ��cluster��������,����,���ߵ�ģ����diversity��similarity֮��ﵽ�˺ܺõ�ƽ�⡣
3. (Yang et al., 2019) introduced to assign hard pseudo labels for both global and local features. However, the training of the neural network was substantially hindered by the noise of the hard pseudo labels generated by clustering algorithms, which was mostly ignored by existing methods.
�������Ϊȫ�ֺ;ֲ����������Ӳα��ǩ,Ȼ��,���еľ����㷨������Ӳα��ǩ������,�����谭���������ѵ����
����˼��:�������ݿ�֮��,ͼ�������졣�����ͼ����зָ�,��ôÿһ��֮��ķ����������Сһ�㡣����,Ҳ��ѧ����³���Ը�ǿ��������
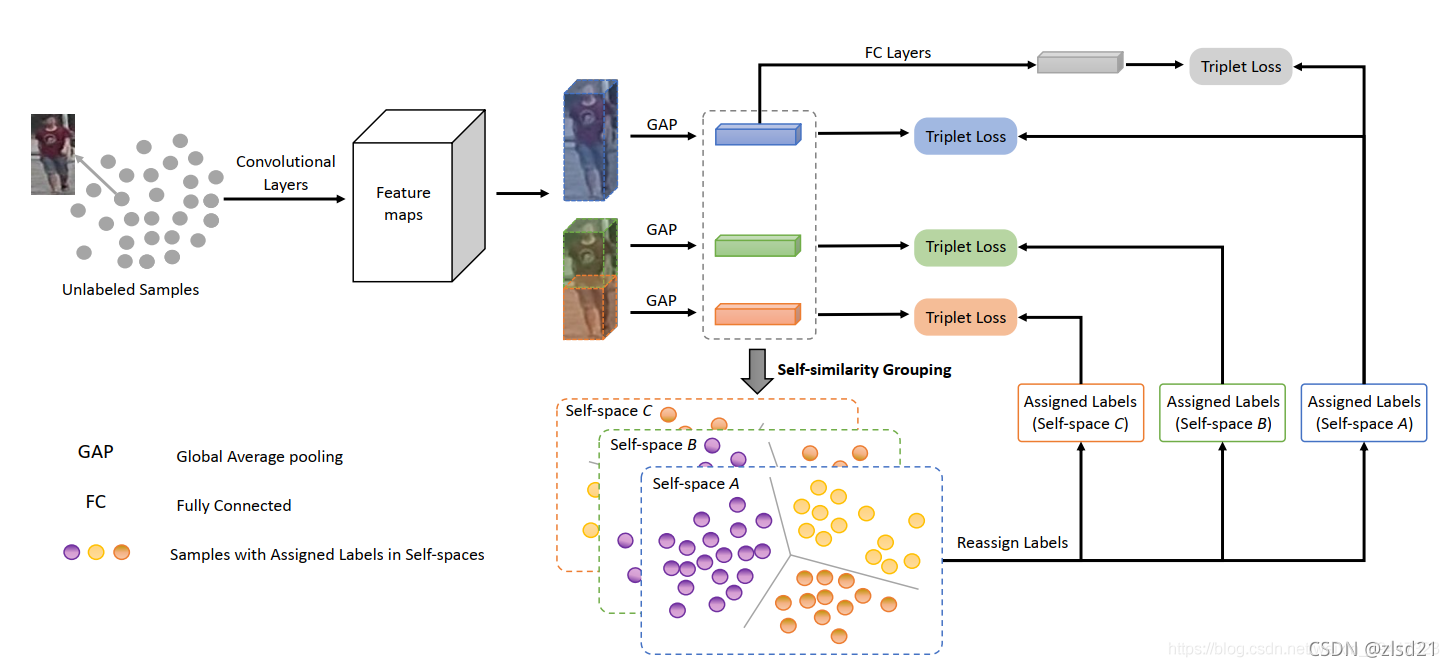
��ɫ����ɫ����ɫ�ֱ����������ͼ��,�ϰ�ͼ����°�ͼ�ֱ���ȡ�����Ե�������������ɫ���ǽ�����������һ��
����ɫ����ɫ����ɫ�������������ֱ���о���,ÿһ�����������ͻ���˶�Ӧ�ı�ǩ����ɫ�ı�ǩֱ�Ӻ���ɫ�ı���һ�¡�����,һ���˵��ϰ������°�����ȫ����Ӧ�ı�ǩ�����Dz�һ���ġ�����뿪ͷ��˼�����Ӧ,ѧϰ�Ĺ����в������������ͼ��ı�ǩ,����������ԡ�
���˱�ǩ֮��,��ÿһ�����������ֱ�ʹ��������Ԫ����ʧ��ģ�ͽ���ѵ����
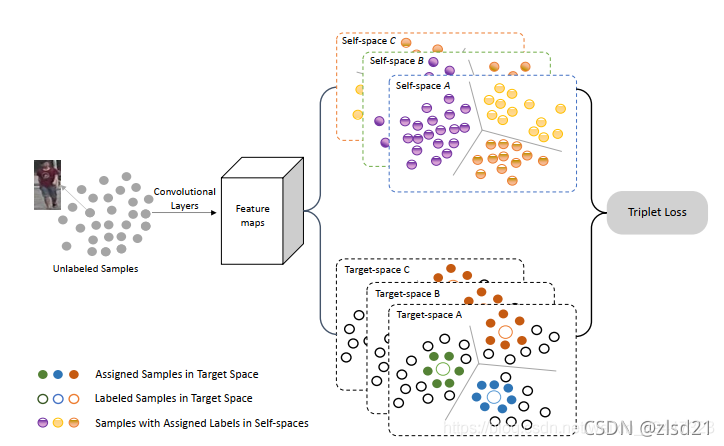
������ͼ��������������������,�ܹ���Ϊ��N�ࡣ��ÿһ���������ѡһ��ͼ��,��N��,�ֱ���ȡ��ͼ���ȫ�֡��ϰ벿�֡��°벿�ֵ���������,��Ϊ�ֵ䡣�ڲ����Ĺ�����,�Ա��ɵ���ͼ����ȡ������������,ÿһ��ֱ�������ᵽ��N��ͼ���Ӧ�������������Ƚ�,������С��,�ͺ��䱣����ͬ�ı�ǩ���ڴ˻�����,�ٽ���������Ԫ����ʧ��
ԭ������:https://blog.csdn.net/weixin_39417323/article/details/103474275
The second category of methods learns domain-invariant features from style-transferred source-domain images.
�ڶ������Ǵ�style-transferred��Դͼ��ѧϰ������
5. SPGAN (Deng et al., 2018) and PTGAN (Wei et al., 2018) transformed source-domain images to match the image styles of the target domain while maintaining the original person identities. The style-transferred images and their identity labels were then used to fine-tune the model.
ת��Դ��ͼ����ƥ��Ŀ�����ͼ����ʽ,ͬʱ����ԭʼ���˵����ݡ�Ȼ��ʹ����ʽת����ͼ�������ݱ�ǩ��ģ�ͽ�������
����˼��:
1.���domain gap ����
���ķ��������һ����learning via translation��framework,ʹ��GAN��source domain��ͼƬת����target domain��,��ʹ����Щtranslated imagesѵ��ReID model����������ͼFigure2��
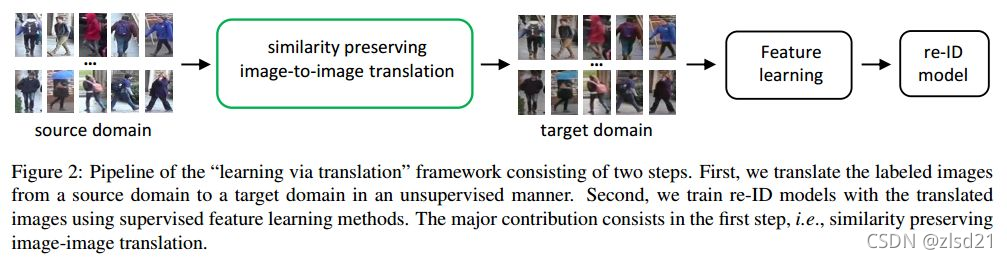
2.���unsupervised image-image translation������,source-domain labels ��Ϣ�ᶪʧ
(1)����ÿ��ͼƬ,ID��Ϣ����ʶ������Ҫ����,��Ҫ���� --> self-similarity���ɼ���ͼFigure1,ת��ǰ���ͼƬҪ�������ơ�
(2)source �� target domain�а�������Ա��û��overlap��,���,ת���õ���ͼƬӦ��Ҫ��target domain���κ�һ��ͼƬ�������ƨC> domain-dissimilarity��
���,�������Similarity Preserving GAN (SPGAN)��ʵ����������motivation��

6. HHL (Zhong et al., 2018) learned camera-invariant features with
camera style transferred images. However, the retrieval performances of these methods deeply relied on the image generation quality, and they did not explore the complex relations between different samples in the target domain.
HHL (Zhong et al., 2018)ѧϰ�������������������ת�Ƶ�ͼ��Ȼ��,��Щ�����ļ������ܴܺ�̶���������ͼ����������,û��̽��Ŀ�����в�ͬ����֮��ĸ��ӹ�ϵ��
������һ��Hetero(����)-Homogeneous(ͬ��) Learning (HHL) ѧϰ����,������������:���������,��һ��ͼ��Ǩ�Ƶ����������ID����;Դ���Ŀ����ID���ص�,���Դ���Ŀ�����ѡһ��ͼ�����pair�ض��Ǹ��ԡ�ǰ����Ŀ�������,Ϊͬ��;��������Դ���Ŀ�������,Ϊ���ʡ�
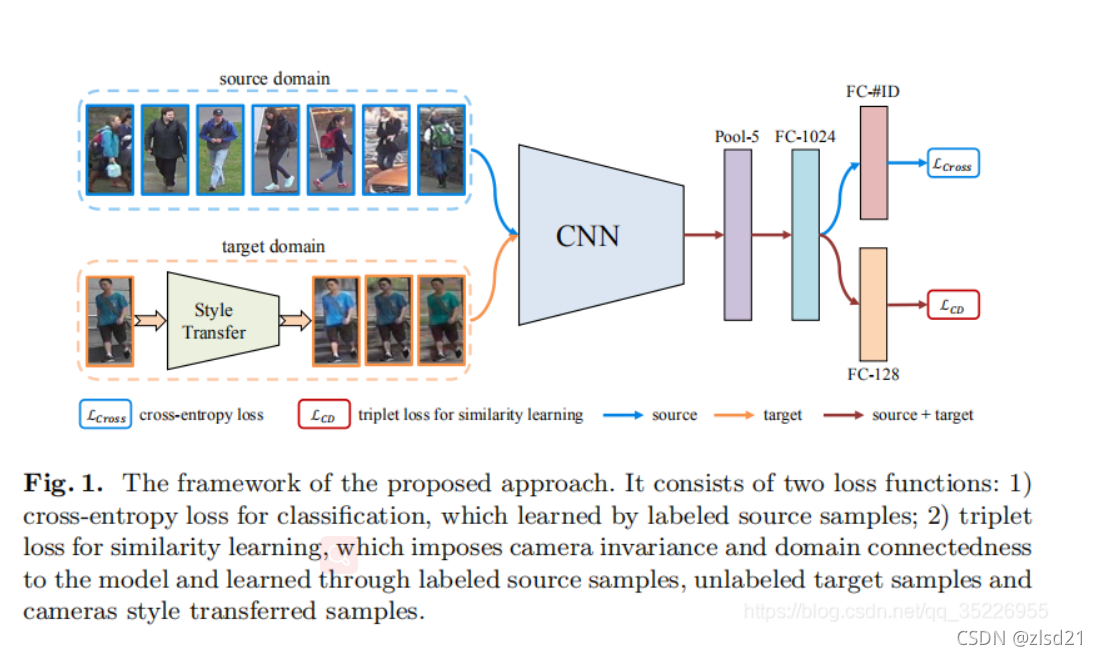
����˼·:����source domain��target domain���л��ѵ��,��domain adaption
a) Target domain����camStyle���и�������ͷ��������ǿ
b) Source��target����ResNet50��baseline
c) ���������branches:
һ����cross-entropy loss for classification
һ����triplet loss for similarity learning:source��anchor image,����source label������������,Ȼ����ѡ��target image�γɸ������ԡ�
���µ�Hetero-Homogeneous Learning
��ѵ����,ÿ��batch������labeled source images,unlabeled real target images�Լ���Ӧ��camStyle���ɵ�fake target images������,ǰ������ѧϰ����domain֮��Ĺ�ϵ,������ѧϰ����target domain�е�camera invariances��
The third category of methods attempts on optimizing the neural networks with soft labels for target-domain samples by computing the similarities with reference images or features.
�����������ͨ��������ο�ͼ������������������Ż�Ŀ��������������ǩ������**
(��ʼ���soft labels��˼��)
7. ENC (Zhong et al., 2019) assigned soft labels by saving averaged features with an exemplar memory module.
�Դ洢���ķ�ʽ����ƽ�������Ӷ��������ǩ(��ƪ�����һᵥ��дһƪ�ܽ�)
��������:Exemplar Memory for Domain Adaptive Person Re-identification
��������https://arxiv.org/abs/1904.01990
����:https://github.com/zhunzhong07/ECN
8. MAR (Yu et al., 2019) conducted multiple soft-label learning by
comparing with a set of reference persons. However, the reference images and features might not be representative enough to generate accurate labels for achieving advanced performances.
���ж������ǩѧϰ��һ������˱Ƚϡ�Ȼ��,�ο�ͼ�����������û���㹻�Ĵ����������ɾ�ȷ�ı�ǩ��ʵ�ָ����ܡ�(��ƪ�����һᵥ��дһƪ�ܽ�)
��������:Unsupervised Person Re-identification by Soft Multilabel Learning
ԭ������:https://arxiv.org/abs/1903.06325
Generic domain adaptation methods for close-set recognition.
Generic domain adaptation methods learn features that can minimize the differences between data distributions of source and target
domains.
- Adversarial learning based methods (Zhang et al., 2018a; Tzeng et al., 2017; Ghifary et al., 2016; Bousmalis et al., 2016; Tzeng et al., 2015) adopted a domain classifier to dispel the discriminative domain information from the learned features in order to reduce the domain gap.
- There also exist methods (Tzeng et al., 2014; Long et al., 2015; Yan et al., 2017; Saito et al., 2018; Ghifary et al., 2016) that minimize the Maximum Mean Discrepancy (MMD) loss between source- and target-domain distributions. However, these methods assume that the classes on different domains are shared, which is not suitable for unsupervised domain adaptation on person re-ID.
Teacher-student models
Teacher-student models have been widely studied in semi-supervised learning methods and knowledge/model distillation methods. The key idea of teacher-student models is to create consistent training supervisions for labeled/unlabeled data via different models�� predictions.
- Temporal ensembling (Laine & Aila, 2016) maintained an exponential moving average prediction for each sample as the supervisions of the unlabeled samples, while the mean-teacher model (Tarvainen & Valpola,2017) averaged model weights at different training iterations to create the supervisions for unlabeled samples.
- Deep mutual learning (Zhang et al., 2018b) adopted a pool of student models instead of the teacher models by training them with supervisions from each other. However, existing methods with teacher-student mechanisms are mostly designed for close-set recognition problems, where both labeled and unlabeled data share the same set of class labels and could not be directly utilized on unsupervised domain adaptation tasks of person re-ID.