机器学习(九)
无监督K-Means聚类
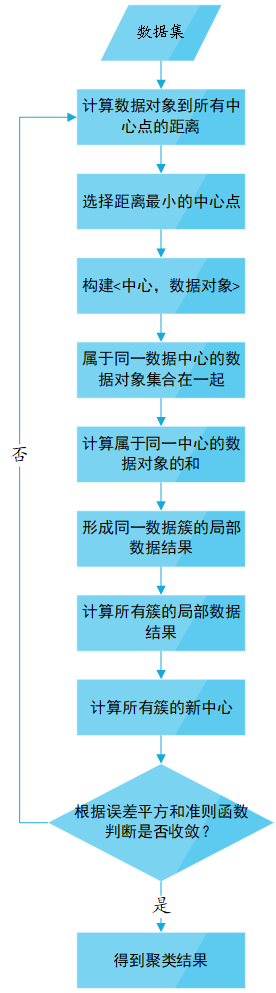
1. K-Means聚类算法流程
误差平方和准则函数:
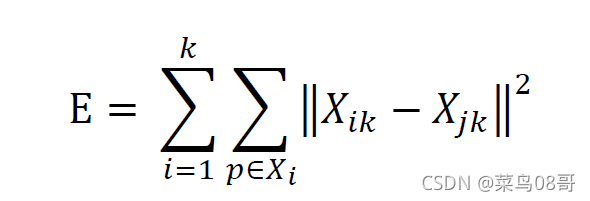
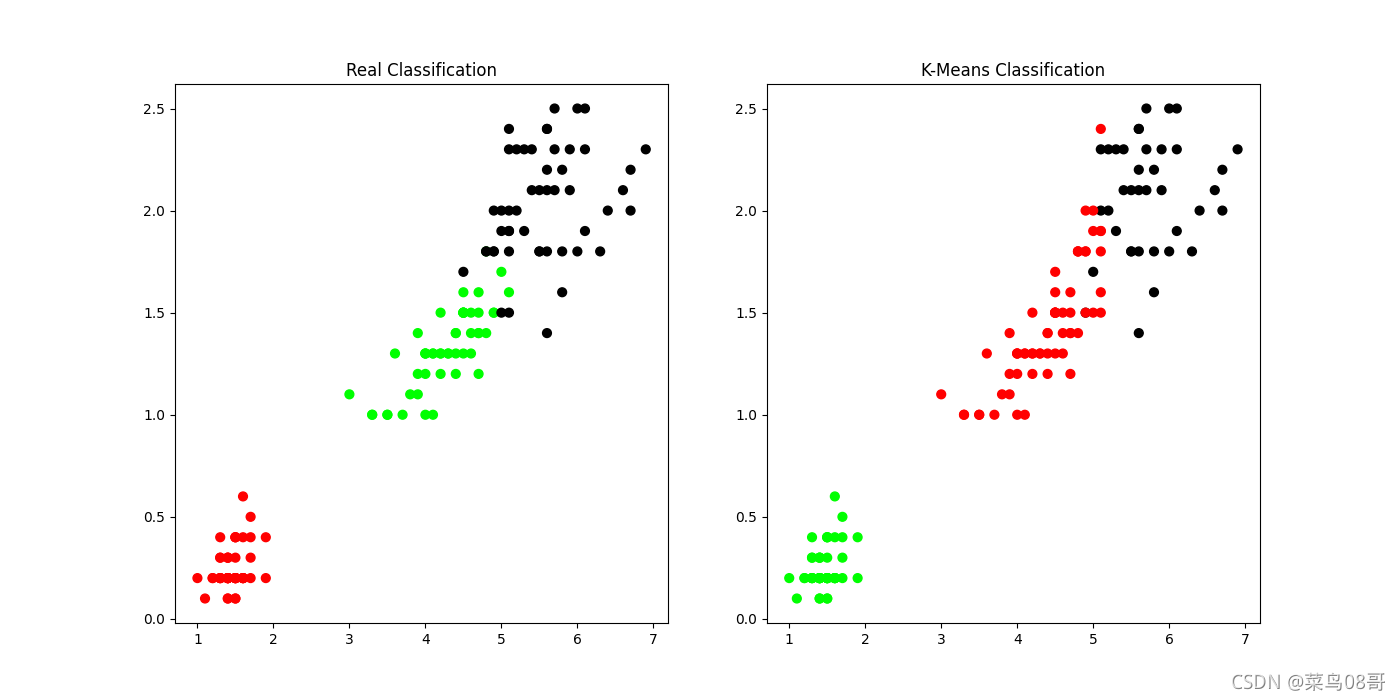
2. K-Means实现鸢尾花聚类
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import datasets
import sklearn.metrics as sm
Iris = datasets.load_iris()
Iris.feature_names
Iris.target
Iris.target_names
x = pd.DataFrame(Iris.data)
x.columns = ['sepal_length','sepal_width','petal_length','petal_width']
y = pd.DataFrame(Iris.target)
y.columns = ['Targets']
# plt.figure(figsize=(14,7))
# colormap = np.array(['red','lime','black'])
# plt.subplot(1,2,1)
# plt.scatter(x.sepal_length,x.sepal_width,c=colormap[y.Targets],s=40)
# plt.title('sepal')
# plt.subplot(1,2,2)
# plt.scatter(x.petal_length,x.petal_width,c=colormap[y.Targets],s=40)
# plt.title('petal')
# plt.show()
model = KMeans(n_clusters=3)
model.fit(x)
predY = np.choose(model.labels_,[2,0,1]).astype(np.int64)
plt.figure(figsize=(14,7))
colormap = np.array(['red','lime','black'])
plt.subplot(1,2,1)
plt.scatter(x.petal_length,x.petal_width,c=colormap[y.Targets],s=40)
plt.title('Real Classification')
plt.subplot(1,2,2)
plt.scatter(x.petal_length,x.petal_width,c=colormap[model.labels_],s=40)
plt.title('K-Means Classification')
plt.show()
print(sm.accuracy_score(y,predY))