AI�������֪ʶ
���ѧϰ
����ݶ��½�(SDG)�������ݶ��½�(BDG)
| ���� | �ص� |
|---|---|
| BDG | 1.�����������ݽ����ݶ��½����� 2.�������϶༴�������ϴ�ʱѵ���ٶȺ��� |
| SDG | 1.SDGʹ��һ�����������ݶ��½�����; 2.ѵ���ٶȺܿ�; 3.���ڲ���һ����������,����п��ܵõ��IJ���ȫ�����Ž�; 4.����ʹ��һ�������������µ����ķ���仯�ܴ�,��˲��ܺܿ���������ֲ����Ž� |
Bootstrapping
??һ���ٳ�����ͳ�Ʒ�������������ͳ�������롰�۲�ͳ�������Ĺ�ϵ�֡��۲�ͳ�������롰��ֵ���Ĺ�ϵ��
??�ٳ����Ķ���:
??�ټٶ��۲�ֵ��������
??������һ�ٶ��������ȡ����,���ٳ�����
Attention����
(������д,�ȿ���ƪ����)
����ѧϰ
������
(1)��Ϣ��
??xΪ��ɢ���������,����ʷֲ�Ϊp(x),������Ϣ������:
I
(
x
0
)
=
?
l
o
g
(
p
(
x
0
)
)
I(x_0)=-log(p(x_0))
I(x0?)=?log(p(x0?))
(2)��
??��Ϣ��������:
H
(
x
)
=
?
��
i
=
1
n
p
(
x
i
)
l
o
g
(
p
(
x
i
)
)
H(x)=-\sum_{i=1}^{n}p(x_i)log(p(x_i))
H(x)=?i=1��n?p(xi?)log(p(xi?))
(3)�����(KLɢ��)
??ͬһ���������x,�����������ĸ��ʷֲ�p��q(����ʵֵ�ֲ�������ֵ�ֲ�),������������ߵȼ�ʱ�������Ϣ������
D
K
L
(
P
�O
�O
Q
)
=
��
i
=
1
n
p
(
x
i
)
l
o
g
(
p
(
x
i
)
q
(
x
i
)
)
D_{KL} (P||Q)=\sum_{i=1}^{n}p(x_i)log(\frac{p(x_i)}{q(x_i)} )
DKL?(P�O�OQ)=i=1��n?p(xi?)log(q(xi?)p(xi?)?)
(4)������
D
K
L
(
P
�O
�O
Q
)
=
��
i
=
1
n
p
(
x
i
)
l
o
g
(
p
(
x
i
)
q
(
x
i
)
)
D_{KL} (P||Q)=\sum_{i=1}^{n}p(x_i)log(\frac{p(x_i)}{q(x_i)} )
DKL?(P�O�OQ)=i=1��n?p(xi?)log(q(xi?)p(xi?)?)
=
��
i
=
1
n
p
(
x
i
)
l
o
g
(
p
(
x
i
)
?
��
i
=
1
n
p
(
x
i
)
l
o
g
(
q
(
x
i
)
)
=\sum_{i=1}^{n}p(x_i)log(p(x_i)-\sum_{i=1}^{n}p(x_i)log(q(x_i))
=i=1��n?p(xi?)log(p(xi?)?i=1��n?p(xi?)log(q(xi?))
=
?
H
(
x
)
+
[
?
��
i
=
1
n
p
(
x
i
)
l
o
g
(
q
(
x
i
)
)
]
=-H(x)+[-\sum_{i=1}^{n}p(x_i)log(q(x_i))]
=?H(x)+[?i=1��n?p(xi?)log(q(xi?))]
??����,ǰ��-H(x)Ϊp����,һ��Ϊ��֪����;����Ϊ������,��Ϊ:
H
(
p
,
q
)
=
?
��
i
=
1
n
p
(
x
i
)
l
o
g
(
q
(
x
i
)
)
H(p,q)=-\sum_{i=1}^{n}p(x_i)log(q(x_i))
H(p,q)=?i=1��n?p(xi?)log(q(xi?))
??�ڻ���ѧϰ��,ͨ��ʹ��KLɢ������label��predict֮��ľ���,��-H(y)һ�㲻��,���,���ý����ؿ�����Ϊloss��������ģ�͡���������������Ԥ����������������Ķ�����
Multi-task Learning
������ѧϰ�������ѧϰ������
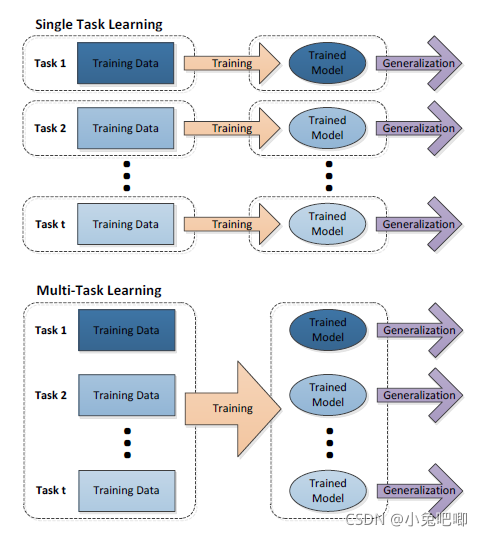
������ѧϰ�Ķ���:
??���ڹ�����ʾ,�Ѷ����ص��������һ��ѧϰ��һ�ֻ���ѧϰ������
ǿ��ѧϰ
SumTree
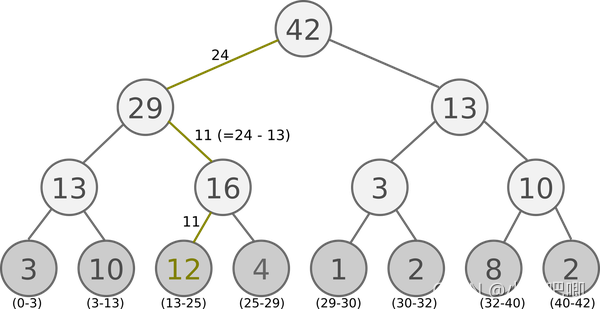
??Sum-Tree���Binary heap,��ÿ�����ڵ������ֵ�����ӽڵ�����ֵ�ĺ͡�Ӧ����DQN with Prioritized Experience Reply�����ȼ�ȡ���С�������������:
??�ٰ�batch_size�ָ�����:
n
=
s
u
m
(
p
)
b
a
t
c
h
s
i
z
e
n=\frac{sum(p)}{batchsize}
n=batchsizesum(p)?
??��ÿ�����������ѡȡһ����ֵ,����ͼ����[13,25)������ѡ��24��
??�۰������й�ʽ��������������������,ֱ���ҵ�����priority�Ͷ�Ӧ�����ݡ�