Lesson 6.��̬����ͼ���ݶ��½�����
??�ڡ�Lesson 5.�����Ż�˼������С���˷����Ľ�β,�����ᵽPyTorch�е�AutoGrad(�Զ���)ģ��,������ʹ�ø�ģ���е�autograd.grad���к�����������,���Ƿ���,autograd.grad�������������к���ijһ��ĵ�����ƫ����������,���ּ�����ʵҲֻ��AutoGradģ���е�һС���ֹ��ܡ����ڿ�,���ǽ���������AutoGradģ���е��������ù���,���ڴ˻����Ͻ�����һ�������Ż��㷨:�ݶ��½��㷨��
import numpy as np
import torch
һ��AutoGrad�Ļ��ݻ����붯̬����ͼ
1.�������������
??����һ���������ᵽ,�°�PyTorch�е������Ѿ���������һ�������������,��������Ҳ��֧�������㡣���ֿ�������ʵ�������������ǿ���ʹ��grad�������������,����Ҫ�������ֿ����Ի������ڿ���������������������С�
- requires_grad����:������
������������
x = torch.tensor(1.,requires_grad = True)
x
����������ϵ
y = x ** 2
- grad_fn����:�洢Tensor�ֺ���
y
���Ƿ���,��ʱ����y������һ��grad_fn����,����ȡֵΪ<PowBackward0>,���ǿ��Բ鿴������
y.grad_fn
grad_fn��ʵ�Ǵ洢��Tensor���ֺ���,����˵grad_fn�洢�˿��������ڽ��м���Ĺ����к�����ϵ,�˴�x��y��ʵ���ǽ����������㡣
��x��Ϊ��ʼ����,��û��grad_fn����
x.grad_fn
����ֵ����Ҫ����,y������x�����������ϵ(y = x**2),����Ҫ����,y��������һ����x��������ó���һ������
y
������һ�������������ɵ�����,Ҳ�ǿ��ֵ�
y.requires_grad
Ҳ���������x,y����ͬ��ӵ��������ȡֵ,����ͬ����,������洢��x��y�ĺ���������Ϣ�������ٳ���Χ��y�����µĺ�����ϵ,z = y + 1
z = y + 1
z
z.requires_grad
z.grad_fn
���ѷ���,zҲͬʱ�洢������������ֵ��z�ǿ���,����z���洢�˺�y�ļ����ϵ(add)���ݴ����ǿ���֪��,��PyTorch���������������,����������ó�ʼ�����ǿ���,���ڼ��������,ÿһ����ԭ��������ó������������ǿ���,���һ��ᱣ���ǰһ���ĺ�����ϵ,��Ҳ������ν�Ļ��ݻ��ơ�������������ݻ���,���Ǿ��ܷdz��������������ÿһ������,���ݴ˻�����������ͼ��
2.��������ͼ
??�������ݻ���,���Ǿ��ܽ������ĸ��Ӽ�����̳���Ϊһ��ͼ(Graph),�����ǰ���Ƕ����x��y��z��������,���ߵļ����ϵ�Ϳ�������ͼ���б�ʾ��
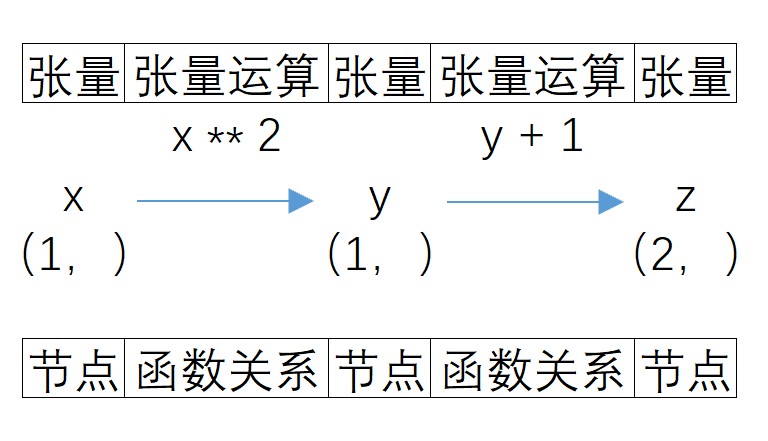
- ����ͼ�Ķ���
??��ͼ�������ڼ�¼�������������ϵ����������ͼ,ͼ�ɽڵ������߹���,���нڵ��ʾ����,�߱�ʾ���������ϵ,�������ʾʵ�����㷽��,��������ͼ������������ͼ��
- �ڵ�����
??����������ͼ��,��Ȼÿ���ڵ㶼��ʾ��������,���ڵ�ͽڵ�֮��ȴ���в�ͬ��������ǰ����,y��z�����˺��������ϵ,��xû��,����ʵ�ʼ����ϵ��,���Dz��ѷ���z�����м�����յ�,���,��Ȼx��y��z���ǽڵ�,��ÿ���ڵ�ȴ����һ�����˴����ǿ��Խ��ڵ��Ϊ����,�ֱ���:
a):Ҷ�ڵ�,Ҳ���dz�ʼ����Ŀ�������,ǰ����x����Ҷ�ڵ�;
b):����ڵ�,Ҳ����������ó�������,ǰ����z��������ڵ�;
c):�м�ڵ�,��һ�ż���ͼ��,����Ҷ�ڵ������ڵ�,���������м�ڵ�,ǰ����y�����м�ڵ㡣
��Ȼ,��һ�ż���ͼ��,�����ж��Ҷ�ڵ���м�ڵ�,������������,ֻ��һ������ڵ�,�����ڶ��������,����Ҳ�����Ὣ�䱣����һ�������С�
3.����ͼ�Ķ�̬��
??ֵ��һ�����,PyTorch�ļ���ͼ�Ƕ�̬����ͼ,����ݿ��������ļ�������Զ�����,���Ұ�����������������ļ��벻�ϸ���,��ʹ��PyTorch�ļ���ͼ��������Ч,���Ҹ������ڹ���,������ȹ���ͼ��ִ�м���IJ��ֿ��(���ϰ汾��TensorFlow),��̬ͼҲ������������������̡�
�����������ݶȼ���
1.�����Ļ�������
??�ڡ�Lesson 5.����,������ʹ��autograd.grad���к���ijһ��ĵ���ֵ�ü���,��ʵ,����ʹ�ú�������,���ǻ�����һ�ַ���,Ҳ�ܽ��е�������:��������Ȼ,��ʱ��������������Ҳ��������һ�ֽ��:�����ݶȽ����
ע:�˴�������ʱ��������������������ֵ���ݶ�ֵ��������,Ŀǰλ������������ͬ,���������ݶ��½�ʱ�ٽ������֡�
����,����ijһ�����������ĵ���ֵ(�ݶ�ֵ),�洢��grad�����С�
x.grad
�����,x.grad�����ǿ�ֵ,���᷵���κν��,������Ȼ�Ѿ�������x��y��z����֮��ĺ�����ϵ,xҲ�о���ȡֵ,��Ҫ����x�㵼��,����Ҫ���о����������,Ҳ����ִ����ν�ķ�������ν����,���ǿ��Լ�����Ϊ,�ڴ�ǰ��¼�ĺ�����ϵ������,����������ϵ,�������Ҷ�ڵ�ĵ���ֵ���ڱ�Ҫʱ��,��Ҳ�ǽ�ʡ������Դ�ʹ洢�ռ�ı�Ҫ�涨��
z
z.grad_fn
ִ�з���
z.backward()
����������,���ɲ鿴Ҷ�ڵ�ĵ���ֵ
x
��z=y+1=x**2+1������ϵ������,xȡֵΪ1ʱ�ĵ���ֵ
x.grad
ע��,��Ĭ�������,��һ�ż���ͼ��ִ�з���,ֻ�ܼ���һ��,�ٴε���backward����������
z.backward()
��Ȼ,��y��Ҳ��ִ�з���
x = torch.tensor(1.,requires_grad = True)
y = x ** 2
z = y + 1
y.backward()
x.grad
�ڶ���ִ��ʱҲ�ᱨ��
y.backward()
z.backward()
���ۺ�ʱ,����ֻ�ܼ���Ҷ�ڵ�ĵ���ֵ
y.grad
����,���Ǿ��˽��˷����Ļ��������ʹ�÷���:
- �����ı���:������ϵ�ķ���(���Ƿ�����);
- ������ִ������:ӵ�к�����ϵ�Ŀ�������(����ͼ�г���Ҷ�ڵ�������ڵ�);
- �����ĺ�������:����Ҷ�ڵ�ĵ���/��/�ݶ�������;
2.��������ע������
- �м�ڵ㷴��������ڵ㷴������
??�����м�ڵ�Ҳ�ɽ��з���,���ܶ�ʱ�����ڴ��ڸ��Ϻ�����ϵ,�м�ڵ㷴���ļ�����������ڵ㷴��������������ͬ��
x = torch.tensor(1.,requires_grad = True)
y = x ** 2
z = y ** 2
z.backward()
x.grad
x = torch.tensor(1.,requires_grad = True)
y = x ** 2
z = y ** 2
y.backward()
x.grad
- �м�ڵ���ݶȱ���
??Ĭ�������,�ڷ���������,�м�ڵ㲢���ᱣ���ݶ�
x = torch.tensor(1.,requires_grad = True)
y = x ** 2
z = y ** 2
z.backward()
y.grad
x.grad
���뱣���м�ڵ���ݶ�,���ǿ���ʹ��retain_grad()����
x = torch.tensor(1.,requires_grad = True)
y = x ** 2
y.retain_grad()
z = y ** 2
z.backward()
y
y.grad
x.grad
3.��ֹ����ͼ��
??��Ĭ�������,ֻҪ��ʼ�����ǿ�������,ϵͳ�ͻ��Զ������������,�������ڼ���ͼ��ϵ��,����Ҳ��ͨ��grad_fn���鿴��¼�ĺ�����ϵ,��������������,���Dz���ϣ���������Ӵ��������������������¼,��ʱ�Ϳ���ʹ��һЩ��������ֹ�������㱻��¼��
- with torch.no_grad():��ֹ����ͼ��¼
??����,����ϣ��x��y�ĺ�����ϵ����¼,��y�ĺ����������㲻����¼,����ʹ��with torch.no_grad()����֯����y�����㲻����¼��
x = torch.tensor(1.,requires_grad = True)
y = x ** 2
with torch.no_grad():
z = y ** 2
with�൱����һ�������Ĺ�����,with torch.no_grad()�ڲ����붼�����Ρ��˼���ͼ���ټ�¼
z
z.requires_grad
y
- .detach()����:����һ�����ɵ�����ͬ����
��ijЩ�����,����Ҳ���Դ���һ�����ɵ�����ͬ���������������,�Ӷ���ϼ���ͼ����
x = torch.tensor(1.,requires_grad = True)
y = x ** 2
y1 = y.detach()
z = y1 ** 2
y
y1
z
4.ʶ��Ҷ�ڵ�
??����Ҷ�ڵ��Ϊ����,�����Ҫʶ����һ������ͼ��ij�����Ƿ���Ҷ�ڵ�,����ʹ��is_leaf���Բ鿴��Ӧ�����Ƿ���Ҷ�ڵ㡣
x.is_leaf
y.is_leaf
��is_leaf����Ҳ���������ĵط�,�����κ�һ���´���������,�����Ƿ�ɵ����Ƿ�������ͼ,���ǿ�����Ҷ�ڵ�,��Щ�ڵ����������Ҷ�ڵ�,ֻ��һ��requires_grad���Ե�����
torch.tensor([1]).is_leaf
����detach������,Ҳ������Ҷ�ڵ�
y1
y1.is_leaf
�����ݶ��½�����˼��
??����AutoGradģ���и�����������֧��,������,���Ǿ��ܳ����ֶ�������һ���Ż��㷨:�ݶ��½��㷨��
1.��С���˷��ľ������Ż�
??�ڡ�Lesson 5.����,���dz���ʹ����С���˷��������Իع��Ŀ�꺯��,��˳���������ȫ�����Ž⡣�������Ͻ���˵,�����е��Ż��㷨����С���˷���Ȼ��Ч���ҽ����ȷ,��Ҳ�в������ĵط�,���ľ�������С���˷���ʹ��������Ϊ����,Ҫ�����������Ľ���˻�������������Ⱦ���,���ܽ�����⡣����ʵ�������,�ܶ����ݵ�����������������������,��ʱ����ʹ����С���˷�������⡣
��С���˷����:
w ^ T = ( X T X ) ? 1 X T y \hat w ^T = (X^TX)^{-1}X^Ty w^T=(XTX)?1XTy
??����С���˷�ʧЧ�����ʱ,��ʵ����Ҳ�ʹ���ԭĿ�꺯��û�����Ž�����ŽⲻΨһ��������������,�кܶ��н������,����,���ǿ�����ԭ�����м���һ���Ŷ��� �� I \lambda I ��I,�ĺ����ʽ����:
w ^ T ? = ( X T X + �� I ) ? 1 X T y \hat w ^{T*} = (X^TX + \lambda I)^{-1}X^Ty w^T?=(XTX+��I)?1XTy
����, �� \lambda �����Ŷ���ϵ��, I I I�ǵ�Ԫ�����ɾ������ʿ�֪,���뵥λ�����, ( X T X + �� I ) (X^TX + \lambda I) (XTX+��I)����һ������,����ֱ����� w ^ T ? \hat w^{T*} w^T?,��Ҳ������ع��һ��������
??��Ȼ,��ʽ�ĺ���õĽ���Ͳ�����ȫ����Сֵ,����һ���ӽ���Сֵ�ĵ㡣��������Ŀ�꺯������Ҳ����������Сֵ����Ψһ��Сֵ,���Ż��Ĺ���������ƫ��Ҳ�ǿ��Խ��ܵġ���Ȼ,���������ѧϰ��������,���ǻᷢ��,��Сֵ����Ψһ���ڲ���Ŀ�꺯���ij�̬�����ڴ����,�ܶ���ݵ�ʽ�α�õ��ľ�ȷ�����������Ż�����(����С����)��������,��ʱ������ҪѰ��һ�ָ���ͨ�õ�,�ܹ���Ч�����ٱƽ�Ŀ�꺯���Ż�Ŀ������Ż��������ڻ���ѧϰ����,��ͨ�õ����Ŀ�꺯�������Ż����������������ݶ��½��㷨��
??ֵ��һ�����,����ͨ��ָ���ݶ��½��㷨,������ijһ���㷨,����ijһ�������ݶ��½��������ۻ���չ�����㷨��,�����ݶ��½��㷨������ݶ��½��㷨��С�����ݶ��½��㷨�ȵȡ�������,���Ǿʹ�����ݶ��½�����,�����ݶ��½��ĺ���˼���һ��ʹ�÷�����
2.�ݶ��½�����˼��
??�ݶ��½��Ļ���˼����ʵ��������,����ľ���ϣ���ܹ�ͨ����ѧ�����ϵĵ�������,��һ����������,һ�����ƽ����Ž⡣
����,�ڴ�ǰ�������Իع鷽�̵Ĺ�����,�������鿴SSE����ά����ͼ������:
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
x = np.arange(-1,3,0.05)
y = np.arange(-1,3,0.05)
a, b = np.meshgrid(x, y)
SSE = (2 - a - b) ** 2 + (4 - 3 * a - b) ** 2
fig = plt.figure()
ax = plt.axes(projection=��3d��)
ax.plot_surface(a, b, SSE, cmap=��rainbow��)
ax.contour(a, b, SSE, zdir=��z��, offset=0, cmap=��rainbow��) #����z����ͶӰ,Ͷ��x-yƽ��
plt.show()
���ݶ��½�,��Ϊ���Ż��㷨,����Ŀ��Ҳ���ҵ����߱ƽ���Сֵ��,�������������:
- ��Ŀ�꺯��������ҵ�һ����ʼ��;
- ͨ����������,һ�����ƽ���Сֵ��;
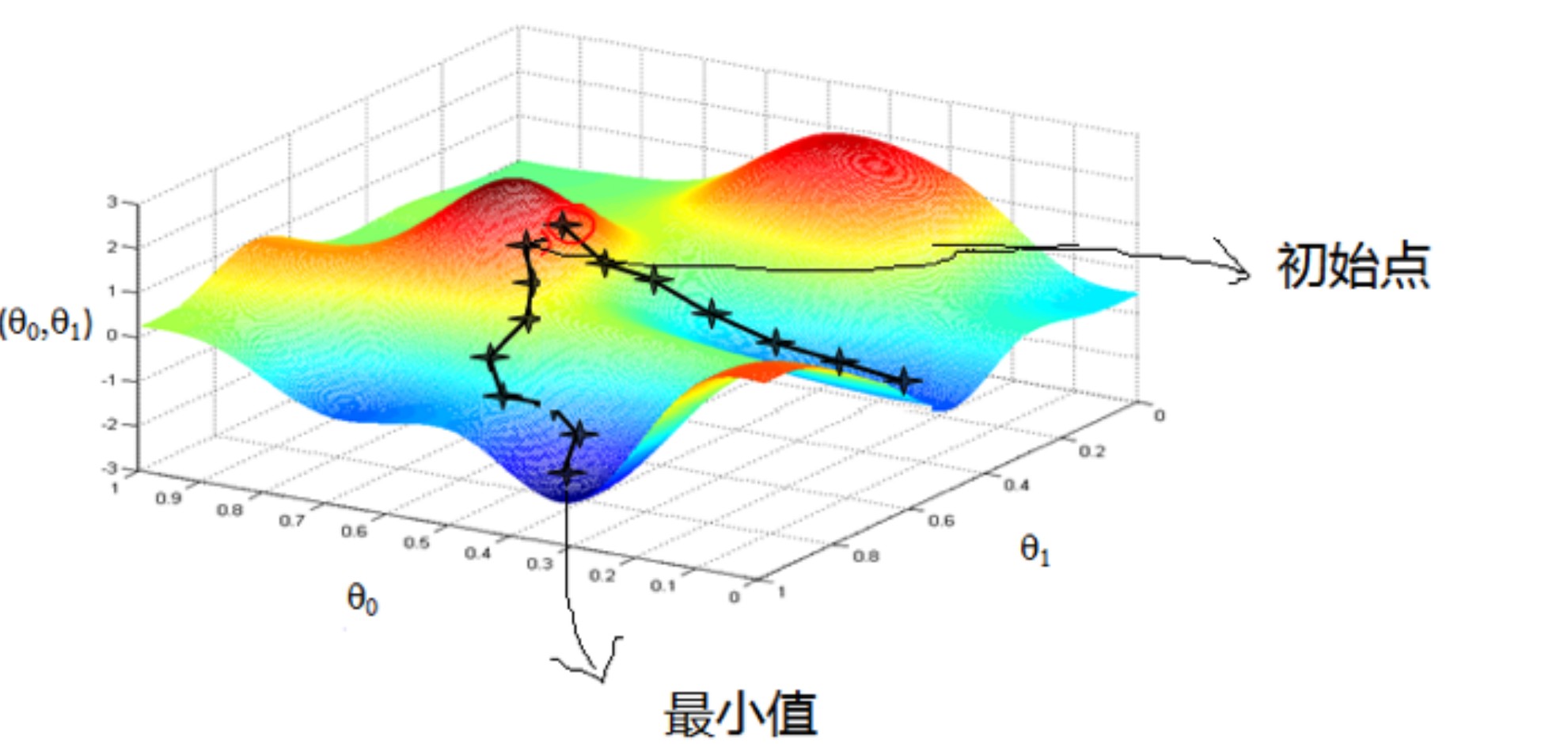
��ѧ�����ϵĵ�������,ָ������һ�μ���Ľ����Ϊ��һ������ij�ʼ������������
3.�ݶ��½��ķ����벽��
??��Ȼ,�ݶ��½��Ļ���˼�������,��ʵ������ȴ��������(��Ҳ�Ǵ��������ѧϰ�㷨�ij�̬)����ʵ������Ŀ�꺯���½��Ĺ�����,���Ǻ�����Ҫ�����������,��һ�����ĸ�������,�����ÿһ���߶�Զ�������������Իع��Ŀ�꺯��Ϊ��,����ά�ռ���,Ŀ�꺯���ϵ�ÿ���������϶����������ƶ��ķ���,ÿ���ƶ���Զ����������Ҳû�����Ե�Լ��,����Щ�����ݶ��½��㷨������Ҫ���������,Ҳ������ν�ķ���Ͳ�����
����,�ǹ��ڷ�������ۡ�
���ڷ��������,��ʵ�ݶ��½��Dz�����һ�־ֲ������Ƶ�ȫ�����ŵ�˼·,����������ϣ���ܹ��ҵ���Ŀ�꺯���仯���ķ�����Ϊ�ƶ��ķ���,���������,�����ݶȡ�
3.1 �������ݶ�
??���Ƕ�֪��,������ijһ��ĵ���ֵ�ļ��κ�����Ǻ����ڸõ������ߵ�б�ʡ�����y=x**2��,x��1��ĵ������Ǻ�����1������ߵ�б�ʡ�
x = np.arange(-10,10,0.1)
y = x ** 2 # y = 2x
z = 2 * x - 1 # ��(1,1)������߷���
plt.plot(x, y, ��-��)
plt.plot(x, z, ��r-��)
plt.plot(1, 1, ��bo��)
plt.show()
������һ������,������������,xȡֵΪ1��ʱ��,���������ߵ�б��Ϊ2,���������Ǹ�1�����һ������С������,1ֻ�������������ƶ�(����Ȼ��������)����Ȼ,�õ㵼��ֵ������һ�����;��Ǹõ���ݶ�,�ݶȵ�ֵ(grad)�͵�����ͬ,���ݶȵĸ��������Ϊ�������������,ֻ�����ݶȸ����ط���ĸ���,Ҳ���Ǵ��ݶȵĽǶȽ������ֵ,�ʹ����ŵ�ǰ�����Ŀ���ʹ��yֵ���������ƶ�����
�ݶ�:�ݶȱ�����һ�����������ʸ��,����ijһ�����ڸõ㴦�����ݶȷ���仯ʱ,�仯�����Ȼ,�ݶȵ��������������ֵ�������ķ���,�ݶȵĸ������ʾ�����������ķ���
x = torch.tensor(1., requires_grad = True)
y = x ** 2
y.backward()
x.grad
������ʱ�����Ա�������һά�ռ�,ֻ������x��仯(�����ƶ�,ֻ����������),�ݶȸ����ķ���ֻ�ܽ��Ϊ����2,Ҳ����������仯ʱ,y���������(ȷʵ���,ͬʱҲ�Զ���)��
3.2 �ݶ��뷽��
??Ϊ�˸��õĽ���ݶ��뷽��֮��Ĺ�ϵ,�����ԡ�Lesson 5.���м����Իع���ʧ����Ϊ�������в鿴��������Ŀ�꺯������ͼ������:
fig = plt.figure()
ax = plt.axes(projection=��3d��)
ax.plot_surface(a, b, SSE, cmap=��rainbow��)
ax.contour(a, b, SSE, zdir=��z��, offset=0, cmap=��rainbow��) #����z����ͶӰ,Ͷ��x-yƽ��
plt.show()
��ʱa��b����ʵ������ȡֵ��������߳�ʼֵΪ0,Ҳ���dz�ʼ�����Ϊԭ�㡣����(0,0)��,���ݶȼ�������
a = torch.tensor(0., requires_grad = True)
a
b = torch.tensor(0., requires_grad = True)
b
s0 = torch.pow((2 - a - b), 2) + torch.pow((4 - 3 * a - b), 2)
s0
s0.backward()
a.grad, b.grad
Ҳ����ԭ���(-28,-12)�����֮������ֱ�ߵķ���,�����ܹ�ʹ��sse�仯���ķ���,���ҳ���(-28,-12)�������ʹ��sse�������ķ���,������������sse�������ķ���
ͨ������ֱ��,ȷ��ԭ����ƶ�����
x = np.arange(-30,30,0.1)
y = (12/28) * x
plt.plot(x, y, ��-��)
plt.plot(0, 0, ��ro��)
plt.plot(-28, -12, ��ro��)
**Point:**�����й��ڷ������������
- ����û�д�С,��Ȼ���Ǹ��Զ����Ĺ۵�,�����ǵ�����˵����(-28,-12)�����ƶ�,ֻ��˵����ֱ���ƶ�,����һ���ƶ���(-28,-12)��;
- ��������ݶ�,��ʱ�ڷ����仯��ֵ��ע�����,һ���㷢���ƶ�,�ݶȾͻ���֮�����仯,Ҳ����˵,������������sse�仯���ķ����ƶ�,һ�������ŷ����ƶ���һС��,�������Ͳ��������ŷ����ˡ�
��Ȼ,���ݶ�ֵ�ķ���仯��ʹ��sse��С����췽��,���dz����ƶ���һС������һ���ƶ���(28,12)��û�������,�ݶȸ�������ֵ�ľ���ֵ����Ҳû�о�������������ѧ���塣����a��b��ȡֵҪ����(28,12)�ȱ����仯,������Dz����������·��������ƶ�:
[ 0 0 ] + 0.01 ? [ 28 12 ] = [ 0.28 0.12 ] \left [\begin{array}{cccc} 0 \\ 0 \\ \end{array}\right] + 0.01 * \left [\begin{array}{cccc} 28 \\ 12 \\ \end{array}\right] = \left [\begin{array}{cccc} 0.28 \\ 0.12 \\ \end{array}\right] [00?]+0.01?[2812?]=[0.280.12?]
s0
a = torch.tensor(0.28, requires_grad = True)
a
b = torch.tensor(0.12, requires_grad = True)
b
s1 = (2 - a - b) ** 2 + (4 - 3 * a - b) ** 2
s1
ȷʵ�����½�,��������µĵ���ݶ�
s1.backward()
a.grad, b.grad
���ѿ���,�����Ѿ������仯����ʵ�����ƶ�����С��һ��,ֻҪ�ƶ�,�������Ҫ���¼��㡣���ÿ������ݶ��ṩ���ƶ���������Ž�,���ƶ��,��ʵ��û��ͳһ�Ĺ涨������,���ǽ�����0.01����ѧϰ��,��ѧϰ�ʳ����ݶ�,����ԭ���ƶ��ġ����ȡ���
��Ȼ,���ƶ���(0.28,0.12)֮��,��û��ȡ��ȫ�����Ž�,��˻���Ҫ�����ƶ�,��Ȼ���ǻ����Լ�������0.01���ѧϰ�ʼ����ƶ�,��ʱ,�µ��ݶ�Ϊ(-21.44,-9.28),����
[ 0.28 0.12 ] + 0.01 ? [ 21.44 9.28 ] = [ 0.4944 0.2128 ] \left [\begin{array}{cccc} 0.28 \\ 0.12 \\ \end{array}\right] + 0.01 * \left [\begin{array}{cccc} 21.44 \\ 9.28 \\ \end{array}\right] = \left [\begin{array}{cccc} 0.4944 \\ 0.2128 \\ \end{array}\right] [0.280.12?]+0.01?[21.449.28?]=[0.49440.2128?]
������,���ǿ��Լ��������µ�(0.94,0.148)�������ݶ�,Ȼ���������ѧϰ��0.01�����ƶ�,���ƶ����ɴ�֮��,�ͽ��õ��dz��ӽ���(1,1)�Ľ����
�ġ��ݶ��½�����ѧ��ʾ
1.�ݶ��½��Ĵ�����ʾ
??����������������,���ǿ���ͨ���������㷽ʽ�ܽ��ݶ��½������һ�����
���Ԫ���Իع鷽��Ϊ
��
w ^ = ( w 1 , w 2 , . . . , w d , b ) \hat w = (w_1,w_2,...,w_d,b) w^=(w1?,w2?,...,wd?,b)
x ^ = ( x 1 , x 2 , . . . , x d , 1 ) \hat x = (x_1,x_2,...,x_d,1) x^=(x1?,x2?,...,xd?,1)
���ڼӿ���������ٶȵ�Ŀ��,�����ڶ����ݶ��½�����ʧ����Lʱ,��ԭSSE�����Ͻ��б�������,�µ���ʧ���� L ( w 1 , w 2 , . . . , w d , b ) = 1 2 m S S E L(w_1,w_2,...,w_d,b) = \frac{1}{2m}SSE L(w1?,w2?,...,wd?,b)=2m1?SSE,����,mΪ����������
��ʧ������:
L ( w 1 , w 2 , . . . , w d , b ) = 1 2 m �� j = 0 m ( f ( x 1 ( j ) , x 2 ( j ) , . . . 1 ) ? y j ) 2 L(w_1,w_2,...,w_d,b) = \frac{1}{2m}\sum_{j=0}^{m}(f(x_1^{(j)}, x_2^{(j)}, ...1) - y_j)^2 L(w1?,w2?,...,wd?,b)=2m1?j=0��m?(f(x1(j)?,x2(j)?,...1)?yj?)2
����,���ݴ�ǰ��������,�ڿ�ʼ�ݶ��½�������֮ǰ,����������Ҫ����һ������ij�ʼȡֵ ( w 1 , w 2 . . . , w d , b ) (w_1, w_2..., w_d, b) (w1?,w2?...,wd?,b),�Լ�ѧϰ�� �� \alpha ��,Ȼ��ִ�е�������,����ÿһ�ֵ���������Ҫִ����������
Step 1.�����ݶȱ���ʽ
��������һ������ w i w_i wi?,���ݶȼ������ʽ����:
? ? w i L ( w 1 , w 2 . . . , w d , b ) \frac{\partial}{\partial w_i}L(w_1, w_2..., w_d, b) ?wi???L(w1?,w2?...,wd?,b)
Step 2.��ѧϰ�ʳ�����ʧ�����ݶ�,�õ������ƶ�����
�� ? ? w i L ( w 1 , w 2 . . . , w d , b ) \alpha \frac{\partial}{\partial w_i}L(w_1, w_2..., w_d, b) ��?wi???L(w1?,w2?...,wd?,b)
Step 3.��ԭ������Step 2�м���õ��ľ���,�������еIJ���w
w i = w i ? �� ? ? w i L ( w 1 , w 2 . . . , w d , b ) w_i = w_i - \alpha \frac{\partial}{\partial w_i}L(w_1, w_2..., w_d, b) wi?=wi??��?wi???L(w1?,w2?...,wd?,b)
���������в���,�������һ�ֵĵ���,�������������µ�һ�� w i w_i wi?������һ�ֵ�����
��һ�ּ�������Ϊ��һ�ּ���ij�ʼֵ,������ν�ĵ�����
����ʱֹͣ����,һ����˵���������,��һ�����õ�������,�������������ֹͣ����;�������������������,����ij���ε���������,ÿ�� w i w_i wi?���µ���ֵ��С��ij��Ԥ���ֵ,��ֹͣ������
2.�ٴ����ⲽ��
�����ݶ��½������Դ�����ʾ����,���ǿ���ͨ��ij��ʵ����ǿ�����ⲽ����һ���
�����ݼ���ʾ����:
| x | y |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
����,����ʹ�� y = w x y = wx y=wx�������,��SSEΪ:
KaTeX parse error: No such environment: align at position 8: \begin{?a?l?i?g?n?}? SSE & = (2-1*w��
��ʱ,SSE����һ������w��һԪ��������ʹ����С���˷��������ʱ,SSE������ʧ����,����SSE����w��Ϊ0�ĵ������Сֵ��,�����:
w = 2 w=2 w=2
������ʹ���ݶ��½����ʱ:
�����ݶȱ�ʾ����,��ijЩ��������ǿ��Զ��������ֵ����һ���̶��ϵġ����š�,��ʱ���ǹ涨��Ч�ݶ���ԭ�ݶȵ�1/28,����
g r a d = w ? 2 grad = w-2 grad=w?2
�貽��$\alpha= 0.5 , �� ʼ ֵ �� ȡ Ϊ 0.5,��ʼֵ��ȡΪ 0.5,��ʼֵ��ȡΪw_0=0$,�������������:
��һ�ֵ���:
g r a d ( w 0 ) = g r a d ( 0 ) = ? 2 , w 0 = 0 , w 1 = w 0 ? �� ? g r a d ( w 0 ) = 0 ? 1 2 ( ? 2 ) = 1 grad(w_0)=grad(0)=-2,w_0=0,w_1=w_0-\alpha*grad(w_0)=0-\frac{1}{2}(-2)=1 grad(w0?)=grad(0)=?2,w0?=0,w1?=w0??��?grad(w0?)=0?21?(?2)=1
�ڶ��ֵ���:
g r a d ( w 1 ) = g r a d ( 1 ) = ? 1 , w 1 = 1 , w 2 = w 1 ? �� ? g r a d ( w 1 ) = 1 ? 1 2 ( ? 1 ) = 3 2 grad(w_1)=grad(1)=-1,w_1=1,w_2=w_1-\alpha*grad(w_1)=1-\frac{1}{2}(-1)=\frac{3}{2} grad(w1?)=grad(1)=?1,w1?=1,w2?=w1??��?grad(w1?)=1?21?(?1)=23?
�����ֵ���:
g r a d ( w 2 ) = g r a d ( 3 2 ) = ? 1 2 , w 2 = 3 2 , w 3 = w 2 ? �� ? g r a d ( w 2 ) = 3 2 ? 1 2 ( ? 1 2 ) = 7 4 grad(w_2)=grad(\frac{3}{2})=-\frac{1}{2},w_2=\frac{3}{2},w_3=w_2-\alpha*grad(w_2)=\frac{3}{2}-\frac{1}{2}(-\frac{1}{2})=\frac{7}{4} grad(w2?)=grad(23?)=?21?,w2?=23?,w3?=w2??��?grad(w2?)=23??21?(?21?)=47?
�����ֵ���:
g r a d ( w 3 ) = g r a d ( 7 4 ) = ? 1 4 , w 3 = 7 4 , w 4 = w 3 ? �� ? g r a d ( w 3 ) = 7 4 ? 1 2 ( ? 1 4 ) = 15 8 grad(w_3)=grad(\frac{7}{4})=-\frac{1}{4},w_3=\frac{7}{4},w_4=w_3-\alpha*grad(w_3)=\frac{7}{4}-\frac{1}{2}(-\frac{1}{4})=\frac{15}{8} grad(w3?)=grad(47?)=?41?,w3?=47?,w4?=w3??��?grad(w3?)=47??21?(?41?)=815?
��������:
w 5 = 15 8 + 1 16 = 31 16 ; w 6 = 31 16 + 1 32 = 63 32 ; w 7 = 63 32 + 1 64 = 127 64 ; . . . w_5 = \frac{15}{8}+\frac{1}{16} = \frac{31}{16}; w_6 = \frac{31}{16}+\frac{1}{32} = \frac{63}{32}; w_7 = \frac{63}{32}+\frac{1}{64} = \frac{127}{64}; ... w5?=815?+161?=1631?;w6?=1631?+321?=3263?;w7?=3263?+641?=64127?;...
w n = 2 n ? 1 2 n ? 1 = 2 ? 1 2 n ? 1 w_n=\frac{2^n-1}{2^{n-1}} = 2-\frac{1}{2^{n-1}} wn?=2n?12n?1?=2?2n?11?
lim ? n �� �� ( w n ) = lim ? n �� �� ( 2 ? 1 2 n ? 1 ) = 2 \lim_{n��\infty} (w_n) = \lim_{n��\infty} (2-\frac{1}{2^{n-1}}) = 2 n����lim?(wn?)=n����lim?(2?2n?11?)=2
���Dz��ѷ���,�����ʧ����������,����ȫ����Сֵ����,�����Ա�ʾ��ǰ�����Сֵ��֮�����ı�����ϵ�����ܵ���˵,���ڲ���������,���������³�������:
- ����̫��:�Ἣ���Ӱ�����������ʱ��,�������Ч�ʻ�dz���;
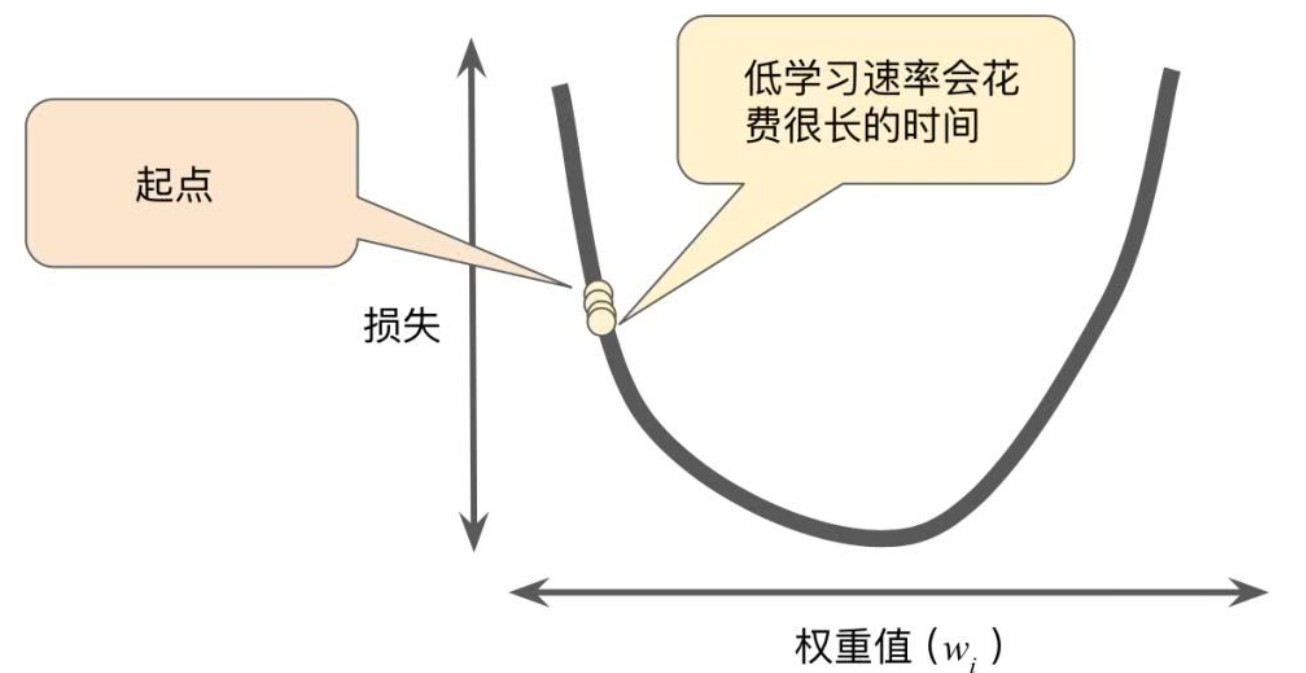
- ����̫��:�����������Ž�,���½����
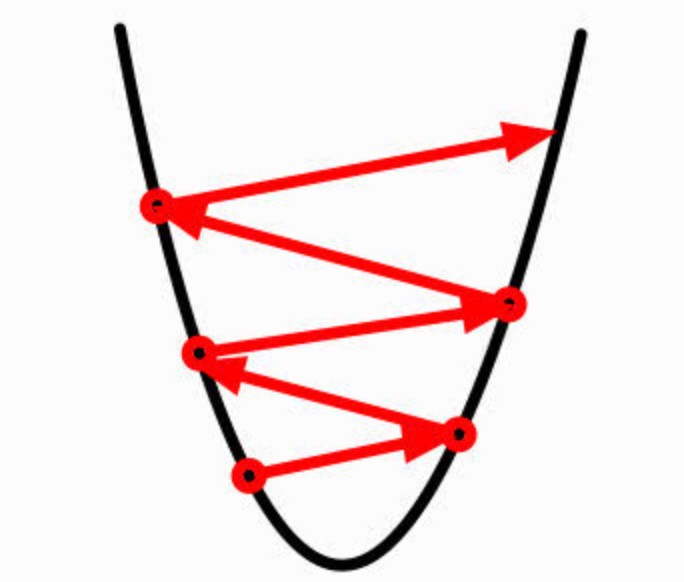
���ڲ���������,��ʵ����Ļ��ʵ��ʹ��������,��ʵ����ʧ�����������,������ǻ��ں���ʹ���ݶ��½����Ŀ�꺯��ʱ����ʵ�����,���ⲽ����ʵ�ʵ������ԡ�
3.�ݶ��½��ľ����ʾ
??����С���˷�һ��,������ʾ��ʽ�������������������,��ʵ�ʱ��ʵ���ݶ��½��Ĺ�����,���ǻ��Ǹ�������ʹ�þ�������ʾ�ݶ��½�������̡�
��
w ^ = ( w 1 , w 2 , . . . , w d , b ) \hat w = (w_1,w_2,...,w_d,b) w^=(w1?,w2?,...,wd?,b)
x ^ = ( x 1 , x 2 , . . . , x d , 1 ) \hat x = (x_1,x_2,...,x_d,1) x^=(x1?,x2?,...,xd?,1)
- w ^ \hat w w^:����ϵ������ɵ�����,�������ǽ��Ա���ϵ���ͽؾ�ŵ���һ��������,�˴� w ^ \hat w w^���൱��ǰ���е�a��b��ɵ�����(a,b);
- x ^ \hat x x^:�����Ա�����1��ͬ��ɵ�����;
���,���̿ɱ�ʾΪ
f ( x ) = w ^ ? x ^ T f(x) = \hat w * \hat x^T f(x)=w^?x^T
����,���ǽ������Ա�����ֵ����һ��������,���Һʹ�ǰA��������,Ϊ�˲��ؾ�,����һ��ȫΪ1�����ھ����ĩβ,���ܹ���m��ȡֵ,��
X = [ x 11 x 12 . . . x 1 d 1 x 21 x 22 . . . x 2 d 1 . . . . . . . . . . . . 1 x m 1 x 12 . . . x m d 1 ] X = \left [\begin{array}{cccc} x_{11} &x_{12} &... &x_{1d} &1 \\ x_{21} &x_{22} &... &x_{2d} &1 \\ ... &... &... &... &1 \\ x_{m1} &x_{12} &... &x_{md} &1 \\ \end{array}\right] X=?????x11?x21?...xm1??x12?x22?...x12??............?x1d?x2d?...xmd??1111??????
��Ӧ��ǰ���е�A����,A�������ӵ��һ���Ա���������ȡֵ��X������yΪ�Ա�����ȡֵ,����
y = [ y 1 y 2 . . . y m ] y = \left [\begin{array}{cccc} y_1 \\ y_2 \\ . \\ . \\ . \\ y_m \\ \end{array}\right] y=?????????y1?y2?...ym???????????
��ʱ,SSE�ɱ�ʾΪ:
S S E = �O �O y ? X w ^ T �O �O 2 2 = ( y ? X w ^ T ) T ( y ? X w ^ T ) = E ( w ^ ) SSE = ||y - X\hat w^T||_2^2 = (y - X\hat w^T)^T(y - X\hat w^T) = E(\hat w) SSE=�O�Oy?Xw^T�O�O22?=(y?Xw^T)T(y?Xw^T)=E(w^)
�ݶ��½���ʧ����Ϊ:
L ( w ^ ) = 1 2 m S S E = 1 2 m ( y ? X w ^ T ) T ( y ? X w ^ T ) L(\hat w) = \frac{1}{2m} SSE =\frac{1}{2m} (y - X\hat w^T)^T(y - X\hat w^T) L(w^)=2m1?SSE=2m1?(y?Xw^T)T(y?Xw^T)
ͬ��,������Ҫ���ó�ʼ������ ( w 1 , w 2 . . . , w d , b ) (w_1, w_2..., w_d, b) (w1?,w2?...,wd?,b),�Լ�ѧϰ�� �� \alpha ��,Ȼ�ɿ�ʼִ�е�������,ͬ��,ÿһ�ֵ�����Ҫ����������:
Step 1.�����ݶȱ���ʽ
���ڲ������� w ^ \hat w w^,���ݶȼ������ʽ����:
? ? w ^ L ( w ^ ) = 1 m X T ( X w ^ T ? Y ) \frac{\partial}{\partial \hat w}L(\hat w) = \frac{1}{m}X^T(X\hat w ^T - Y) ?w^??L(w^)=m1?XT(Xw^T?Y)
Step 2.��ѧϰ�ʳ�����ʧ�����ݶ�,�õ������ƶ�����
�� ? ? w ^ L ( w ^ ) \alpha \frac{\partial}{\partial \hat w}L(\hat w) ��?w^??L(w^)
Step 3.��ԭ������Step 2�м���õ��ľ���,�������еIJ���w
w ^ = w ^ ? �� ? ? w ^ L ( w ^ ) = w ^ ? �� m X T ( X w ^ T ? Y ) \hat w = \hat w - \alpha \frac{\partial}{\partial \hat w}L(\hat w) = \hat w - \frac{\alpha}{m}X^T(X\hat w ^T - Y) w^=w^?��?w^??L(w^)=w^?m��?XT(Xw^T?Y)
���������в���,�������һ�ֵĵ���,�������������µ� w ^ \hat w w^������һ�ֵ�����
�塢�ֶ�ʵ���ݶ��½�
??������,����ʹ�����������ʾ���ݶ��½���ʽ,Χ�ƴ�ǰ�ļ����Իع��Ŀ�꺯��,���ô�ǰ���ܵ�AutoGradģ���е��ݶȼ��㹦��,�������ֶ�����ݶ��½���
��ת��Ϊ�����ʾ�Ĺ�����,������
X = [ 1 1 3 1 ] X = \left [\begin{array}{cccc} 1 &1 \\ 3 &1 \\ \end{array}\right] X=[13?11?]
y = [ 2 4 ] y = \left [\begin{array}{cccc} 2 \\ 4 \\ \end{array}\right] y=[24?]
w ^ = [ a b ] \hat w = \left [\begin{array}{cccc} a \\ b \\ \end{array}\right] w^=[ab?]
- �ֶ�����ʵ��һ�ֵ���
���ó�ʼ����
weights = torch.zeros(2, 1, requires_grad = True)
weights
��������
X = torch.tensor([[1.,1],[3, 1]], requires_grad = True)
X
y = torch.tensor([2.,4], requires_grad = True).reshape(2,1)
y
����
eps = torch.tensor(0.01, requires_grad = True)
eps
�ݶȼ��㹫ʽ
grad = torch.mm(X.t(), (torch.mm(X, weights) - y))/2
grad
ע��Աȴ������̼�����,��ʼ�ݶ�Ϊ(-28,-12),�˴����4,Ҳ����2m,m������������
weights = weights - eps * grad
weights
- ����3��
for k in range(3):
grad = torch.mm(X.t(), (torch.mm(X, weights) - y))/2
weights = weights - eps * grad
weights
- ��������������
def gradDescent(X, y, eps = torch.tensor(0.01, requires_grad = True), numIt = 1000):
m, n = X.shape
weights = torch.zeros(n, 1, requires_grad = True)
for k in range(numIt):
grad = torch.mm(X.t(), (torch.mm(X, weights) - y))/2
weights = weights - eps * grad
return weights
X = torch.tensor([[1.,1],[3, 1]], requires_grad = True)
X
y = torch.tensor([2.,4], requires_grad = True).reshape(2,1)
y
gradDescent(X, y)
weights = gradDescent(X, y, numIt = 10000)
weights
S S E = ( y ? X w ^ T ) T ( y ? X w ^ T ) SSE =(y - X\hat w^T)^T(y - X\hat w^T) SSE=(y?Xw^T)T(y?Xw^T)
torch.mm((torch.mm(X,weights)-y).t(), torch.mm(X,weights)-y)