本项目将使用Pytorch,实现一个简单的的音频信号分类器,可应用于机械信号分类识别,鸟叫声信号识别等应用场景。
项目使用librosa进行音频信号处理,backbone使用mobilenet_v2,在Urbansound8K数据上,最终收敛的准确率在训练集99%,测试集82%,如果想进一步提高识别准确率可以使用更重的backbone和更多的数据增强方法。
完整的项目代码:https://download.csdn.net/download/guyuealian/30306697
尊重原创,转载请注明出处:https://panjinquan.blog.csdn.net/article/details/120601437
目录
1. 项目结构
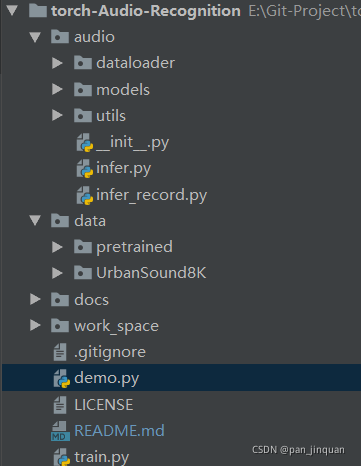
2. 环境配置
使用pip命令安装libsora和pyaudio,pydub等库
pip install librosa
pip install pyaudio
pip install pydub
3.数据处理
(1)数据集Urbansound8K?
?Urbansound8K是目前应用较为广泛的用于自动城市环境声分类研究的公共数据集,
包含10个分类:空调声、汽车鸣笛声、儿童玩耍声、狗叫声、钻孔声、引擎空转声、枪声、手提钻、警笛声和街道音乐声。
数据集下载:https://zenodo.org/record/1203745/files/UrbanSound8K.tar.gz
(2)自定义数据集
可以自己录制音频信号,制作自己的数据集,参考[audio/dataloader/record_audio.py]
每个文件夹存放一个类别的音频数据,每条音频数据长度在3秒左右,建议每类的音频数据均衡
生产train和test数据列表:参考[audio/dataloader/create_data.py]
(3)音频特征提取:?
音频信号是一维的语音信号,不能直接用于模型训练,需要使用librosa将音频转为梅尔频谱(Mel Spectrogram)。
librosa提供python接口,在音频、乐音信号的分析中经常用到
wav, sr = librosa.load(data_path, sr=16000)
# 使用librosa获得音频的梅尔频谱
spec_image = librosa.feature.melspectrogram(y=wav, sr=sr, hop_length=256)
关于librosa的使用方法,请参考:
4.训练Pipeline
(1)构建训练和测试数据
def build_dataset(self, cfg):
"""构建训练数据和测试数据"""
input_shape = eval(cfg.input_shape)
# 获取数据
train_dataset = AudioDataset(cfg.train_data, data_dir=cfg.data_dir, mode='train', spec_len=input_shape[3])
train_loader = DataLoader(dataset=train_dataset, batch_size=cfg.batch_size, shuffle=True,
num_workers=cfg.num_workers)
test_dataset = AudioDataset(cfg.test_data, data_dir=cfg.data_dir, mode='test', spec_len=input_shape[3])
test_loader = DataLoader(dataset=test_dataset, batch_size=cfg.batch_size, shuffle=False,
num_workers=cfg.num_workers)
print("train nums:{}".format(len(train_dataset)))
print("test nums:{}".format(len(test_dataset)))
return train_loader, test_loader由于librosa.load加载音频数据特别慢,建议使用cache先进行缓存,方便加速
def load_audio(audio_file, cache=False):
"""
加载并预处理音频
:param audio_file:
:param cache: librosa.load加载音频数据特别慢,建议使用进行缓存进行加速
:return:
"""
# 读取音频数据
cache_path = audio_file + ".pk"
# t = librosa.get_duration(filename=audio_file)
if cache and os.path.exists(cache_path):
tmp = open(cache_path, 'rb')
wav, sr = pickle.load(tmp)
else:
wav, sr = librosa.load(audio_file, sr=16000)
if cache:
f = open(cache_path, 'wb')
pickle.dump([wav, sr], f)
f.close()
# Compute a mel-scaled spectrogram: 梅尔频谱图
spec_image = librosa.feature.melspectrogram(y=wav, sr=sr, hop_length=256)
return spec_image(2)构建backbone模型
backbone是一个基于CNN+FC的网络结构,与图像CNN分类模型不同的是,图像CNN分类模型的输入维度(batch,3,H,W)输入数据depth=3,而音频信号的梅尔频谱图是深度为depth=1,可以认为是灰度图,输入维度(batch,1,H,W),因此实际使用中,只需要将传统的CNN图像分类的backbone的第一层卷积层的in_channels=1即可。需要注意的是,由于维度不一致,导致不能使用imagenet的pretrained模型。
当然可以将梅尔频谱图(灰度图)是转为3通道RGB图,这样就跟普通的RGB图像没有什么区别了,也可以imagenet的pretrained模型,如
# 将梅尔频谱图(灰度图)是转为为3通道RGB图 spec_image = cv2.cvtColor(spec_image, cv2.COLOR_GRAY2RGB)
def build_model(self, cfg):
if cfg.net_type == "mbv2":
model = mobilenet_v2.mobilenet_v2(num_classes=cfg.num_classes)
elif cfg.net_type == "resnet34":
model = resnet.resnet34(num_classes=args.num_classes)
elif cfg.net_type == "resnet18":
model = resnet.resnet18(num_classes=args.num_classes)
else:
raise Exception("Error:{}".format(cfg.net_type))
model.to(self.device)
return model(3)训练参数配置
相关的命令行参数,可参考:
def get_parser():
data_dir = "/media/pan/新加卷/dataset/UrbanSound8K"
# data_dir = "E:/dataset/UrbanSound8K"
train_data = 'data/UrbanSound8K/train.txt'
test_data = 'data/UrbanSound8K/test.txt'
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument('--batch_size', type=int, default=32, help='训练的批量大小')
parser.add_argument('--num_workers', type=int, default=4, help='读取数据的线程数量')
parser.add_argument('--num_epoch', type=int, default=100, help='训练的轮数')
parser.add_argument('--num_classes', type=int, default=10, help='分类的类别数量')
parser.add_argument('--learning_rate', type=float, default=1e-3, help='初始学习率的大小')
parser.add_argument('--input_shape', type=str, default='(None, 1, 128, 128)', help='数据输入的形状')
parser.add_argument('--gpu_id', type=int, default=0, help='GPU ID')
parser.add_argument('--net_type', type=str, default="mbv2", help='backbone')
parser.add_argument('--data_dir', type=str, default=data_dir, help='数据路径')
parser.add_argument('--train_data', type=str, default=train_data, help='训练数据的数据列表路径')
parser.add_argument('--test_data', type=str, default=test_data, help='测试数据的数据列表路径')
parser.add_argument('--work_dir', type=str, default='work_space/', help='模型保存的路径')
return parser
配置好数据路径,其他参数默认设置,即可以开始训练了:
python train.py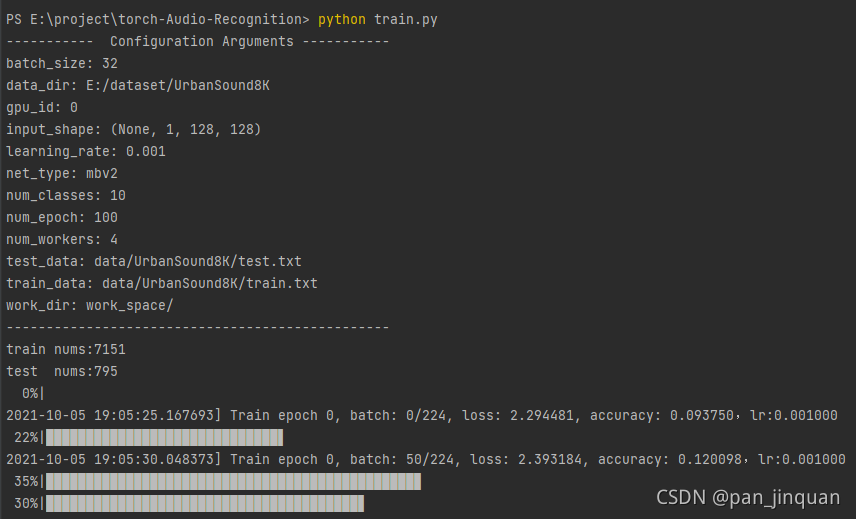
训练完成,使用mobilenet_v2,最终训练集准确率99%左右,测试集81%左右,看起来有点过拟合了。
如果想进一步提高识别准确率可以使用更重的backbone,如resnet34,采用更多的数据增强方法,提高模型的泛发性。
 |  |
完整的训练代码train.py:
# -*-coding: utf-8 -*-
"""
@Author : panjq
@E-mail : pan_jinquan@163.com
@Date : 2021-07-28 09:09:32
"""
import argparse
import os
import numpy as np
import torch
import tensorboardX as tensorboard
from datetime import datetime
from tqdm import tqdm
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import StepLR, MultiStepLR
from audio.dataloader.audio_dataset import AudioDataset
from audio.utils.utility import print_arguments
from audio.utils import file_utils
from audio.models import mobilenet_v2, resnet
class Train(object):
"""Training Pipeline"""
def __init__(self, cfg):
self.device = "cuda:{}".format(cfg.gpu_id) if torch.cuda.is_available() else "cpu"
self.num_epoch = cfg.num_epoch
self.net_type = cfg.net_type
self.work_dir = os.path.join(cfg.work_dir, self.net_type)
self.model_dir = os.path.join(self.work_dir, "model")
self.log_dir = os.path.join(self.work_dir, "log")
file_utils.create_dir(self.model_dir)
file_utils.create_dir(self.log_dir)
self.tensorboard = tensorboard.SummaryWriter(self.log_dir)
self.train_loader, self.test_loader = self.build_dataset(cfg)
# 获取模型
self.model = self.build_model(cfg)
# 获取优化方法
self.optimizer = torch.optim.Adam(params=self.model.parameters(),
lr=cfg.learning_rate,
weight_decay=5e-4)
# 获取学习率衰减函数
self.scheduler = MultiStepLR(self.optimizer, milestones=[50, 80], gamma=0.1)
# 获取损失函数
self.losses = torch.nn.CrossEntropyLoss()
def build_dataset(self, cfg):
"""构建训练数据和测试数据"""
input_shape = eval(cfg.input_shape)
# 获取数据
train_dataset = AudioDataset(cfg.train_data, data_dir=cfg.data_dir, mode='train', spec_len=input_shape[3])
train_loader = DataLoader(dataset=train_dataset, batch_size=cfg.batch_size, shuffle=True,
num_workers=cfg.num_workers)
test_dataset = AudioDataset(cfg.test_data, data_dir=cfg.data_dir, mode='test', spec_len=input_shape[3])
test_loader = DataLoader(dataset=test_dataset, batch_size=cfg.batch_size, shuffle=False,
num_workers=cfg.num_workers)
print("train nums:{}".format(len(train_dataset)))
print("test nums:{}".format(len(test_dataset)))
return train_loader, test_loader
def build_model(self, cfg):
"""构建模型"""
if cfg.net_type == "mbv2":
model = mobilenet_v2.mobilenet_v2(num_classes=cfg.num_classes)
elif cfg.net_type == "resnet34":
model = resnet.resnet34(num_classes=args.num_classes)
elif cfg.net_type == "resnet18":
model = resnet.resnet18(num_classes=args.num_classes)
else:
raise Exception("Error:{}".format(cfg.net_type))
model.to(self.device)
return model
def epoch_test(self, epoch):
"""模型测试"""
loss_sum = []
accuracies = []
self.model.eval()
with torch.no_grad():
for step, (inputs, labels) in enumerate(tqdm(self.test_loader)):
inputs = inputs.to(self.device)
labels = labels.to(self.device).long()
output = self.model(inputs)
# 计算损失值
loss = self.losses(output, labels)
# 计算准确率
output = torch.nn.functional.softmax(output, dim=1)
output = output.data.cpu().numpy()
output = np.argmax(output, axis=1)
labels = labels.data.cpu().numpy()
acc = np.mean((output == labels).astype(int))
accuracies.append(acc)
loss_sum.append(loss)
acc = sum(accuracies) / len(accuracies)
loss = sum(loss_sum) / len(loss_sum)
print("Test epoch:{:3.3f},Acc:{:3.3f},loss:{:3.3f}".format(epoch, acc, loss))
print('=' * 70)
return acc, loss
def epoch_train(self, epoch):
"""模型训练"""
loss_sum = []
accuracies = []
self.model.train()
for step, (inputs, labels) in enumerate(tqdm(self.train_loader)):
inputs = inputs.to(self.device)
labels = labels.to(self.device).long()
output = self.model(inputs)
# 计算损失值
loss = self.losses(output, labels)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 计算准确率
output = torch.nn.functional.softmax(output, dim=1)
output = output.data.cpu().numpy()
output = np.argmax(output, axis=1)
labels = labels.data.cpu().numpy()
acc = np.mean((output == labels).astype(int))
accuracies.append(acc)
loss_sum.append(loss)
if step % 50 == 0:
lr = self.optimizer.state_dict()['param_groups'][0]['lr']
print('[%s] Train epoch %d, batch: %d/%d, loss: %f, accuracy: %f,lr:%f' % (
datetime.now(), epoch, step, len(self.train_loader), sum(loss_sum) / len(loss_sum),
sum(accuracies) / len(accuracies), lr))
acc = sum(accuracies) / len(accuracies)
loss = sum(loss_sum) / len(loss_sum)
print("Train epoch:{:3.3f},Acc:{:3.3f},loss:{:3.3f}".format(epoch, acc, loss))
print('=' * 70)
return acc, loss
def run(self):
# 开始训练
for epoch in range(self.num_epoch):
train_acc, train_loss = self.epoch_train(epoch)
test_acc, test_loss = self.epoch_test(epoch)
self.tensorboard.add_scalar("train_acc", train_acc, epoch)
self.tensorboard.add_scalar("train_loss", train_loss, epoch)
self.tensorboard.add_scalar("test_acc", test_acc, epoch)
self.tensorboard.add_scalar("test_loss", test_loss, epoch)
self.scheduler.step()
self.save_model(epoch, test_acc)
def save_model(self, epoch, acc):
"""保持模型"""
model_path = os.path.join(self.model_dir, 'model_{:0=3d}_{:.3f}.pth'.format(epoch, acc))
if not os.path.exists(os.path.dirname(model_path)):
os.makedirs(os.path.dirname(model_path))
torch.jit.save(torch.jit.script(self.model), model_path)
def get_parser():
data_dir = "/media/pan/新加卷/dataset/UrbanSound8K"
# data_dir = "E:/dataset/UrbanSound8K"
train_data = 'data/UrbanSound8K/train.txt'
test_data = 'data/UrbanSound8K/test.txt'
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument('--batch_size', type=int, default=32, help='训练的批量大小')
parser.add_argument('--num_workers', type=int, default=4, help='读取数据的线程数量')
parser.add_argument('--num_epoch', type=int, default=100, help='训练的轮数')
parser.add_argument('--num_classes', type=int, default=10, help='分类的类别数量')
parser.add_argument('--learning_rate', type=float, default=1e-3, help='初始学习率的大小')
parser.add_argument('--input_shape', type=str, default='(None, 1, 128, 128)', help='数据输入的形状')
parser.add_argument('--gpu_id', type=int, default=0, help='GPU ID')
parser.add_argument('--net_type', type=str, default="mbv2", help='backbone')
parser.add_argument('--data_dir', type=str, default=data_dir, help='数据路径')
parser.add_argument('--train_data', type=str, default=train_data, help='训练数据的数据列表路径')
parser.add_argument('--test_data', type=str, default=test_data, help='测试数据的数据列表路径')
parser.add_argument('--work_dir', type=str, default='work_space/', help='模型保存的路径')
return parser
if __name__ == '__main__':
parser = get_parser()
args = parser.parse_args()
print_arguments(args)
t = Train(args)
t.run()
5.预测demo.py
# -*-coding: utf-8 -*-
"""
@Author : panjq
@E-mail : pan_jinquan@163.com
@Date : 2021-07-28 09:09:32
"""
import os
import cv2
import argparse
import librosa
import torch
import numpy as np
from audio.dataloader.audio_dataset import load_audio, normalization
from audio.dataloader.record_audio import record_audio
from audio.utils import file_utils, image_utils
class Predictor(object):
def __init__(self, cfg):
# self.device = "cuda:{}".format(cfg.gpu_id) if torch.cuda.is_available() else "cpu"
self.device = "cpu"
self.input_shape = eval(cfg.input_shape)
self.spec_len = self.input_shape[3]
self.model = self.build_model(cfg.model_file)
def build_model(self, model_file):
# 加载模型
model = torch.jit.load(model_file, map_location="cpu")
model.to(self.device)
model.eval()
return model
def inference(self, input_tensors):
with torch.no_grad():
input_tensors = input_tensors.to(self.device)
output = self.model(input_tensors)
return output
def pre_process(self, spec_image):
"""音频数据预处理"""
if spec_image.shape[1] > self.spec_len:
input = spec_image[:, 0:self.spec_len]
else:
input = np.zeros(shape=(self.spec_len, self.spec_len), dtype=np.float32)
input[:, 0:spec_image.shape[1]] = spec_image
input = normalization(input)
input = input[np.newaxis, np.newaxis, :]
input_tensors = np.concatenate([input])
input_tensors = torch.tensor(input_tensors, dtype=torch.float32)
return input_tensors
def post_process(self, output):
"""输出结果后处理"""
scores = torch.nn.functional.softmax(output, dim=1)
scores = scores.data.cpu().numpy()
# 显示图片并输出结果最大的label
label = np.argmax(scores, axis=1)
score = scores[:, label]
return label, score
def detect(self, audio_file):
"""
:param audio_file: 音频文件
:return: label:预测音频的label
score: 预测音频的置信度
"""
spec_image = load_audio(audio_file)
input_tensors = self.pre_process(spec_image)
# 执行预测
output = self.inference(input_tensors)
label, score = self.post_process(output)
return label, score
def detect_file_dir(self, file_dir):
"""
:param file_dir: 音频文件目录
:return:
"""
file_list = file_utils.get_files_lists(file_dir, postfix=["*.wav"])
for file in file_list:
print(file)
label, score = self.detect(file)
print(label, score)
def detect_record_audio(self, audio_dir):
"""
:param audio_dir: 录制音频并进行识别
:return:
"""
time = file_utils.get_time()
file = os.path.join(audio_dir, time + ".wav")
record_audio(file)
label, score = self.detect(file)
print(file)
print(label, score)
def get_parser():
model_file = 'data/pretrained/model_060_0.827.pth'
file_dir = 'data/audio'
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument('--num_classes', type=int, default=10, help='分类的类别数量')
parser.add_argument('--input_shape', type=str, default='(None, 1, 128, 128)', help='数据输入的形状')
parser.add_argument('--net_type', type=str, default="mbv2", help='backbone')
parser.add_argument('--gpu_id', type=int, default=0, help='GPU ID')
parser.add_argument('--model_file', type=str, default=model_file, help='模型文件')
parser.add_argument('--file_dir', type=str, default=file_dir, help='音频文件的目录')
return parser
if __name__ == '__main__':
parser = get_parser()
args = parser.parse_args()
p = Predictor(args)
p.detect_file_dir(file_dir=args.file_dir)
# audio_dir = 'data/record_audio'
# p.detect_record_audio(audio_dir=audio_dir)
完整的项目代码:https://download.csdn.net/download/guyuealian/30306697
更多AI博客,请参考:
人体关键点检测需要用到人体检测,请查看鄙人另一篇博客:2D Pose人体关键点实时检测(Python/Android /C++ Demo)_pan_jinquan的博客-CSDN博客