������ȡ�����
1. ����֪ʶ
1.1 ���ݷ����Ļ���֪ʶ
���ݷ�����һ������:
��ȷĿ��-���ɼ�����-��������ϴ�����-������ͼ�����ҿ��ӻ�-���ó�����
1.2 ����python��ɫ�ij���
1.3 �ַ�����Ƭ
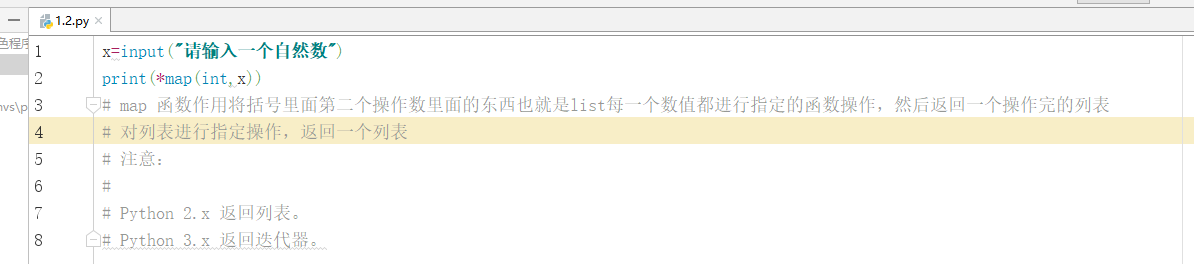
1 ѭ����ӡǶ���б�:movies=[��the holy��,1975,��terry jones��,91,[��graham��,
[��michael��,��john��,��gilliam��,��idle��,��haha��]]],ʵ��������ʽ�����:
The holy
1975
2���ֵ�ֵ����
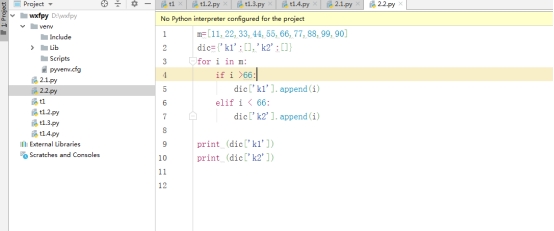
������ֵ����[11,22,33,44,55,66,77,88,99,90],�����д���66��ֵ�������ֵ�ĵ�һ��key��,��С��66��ֵ�������ڶ���key��ֵ�С���:{��k1��:����66������ֵ,��k2��:С��66������ֵ}
2. ���ݲɼ�-����������ʵ��
2.1 ��������·��:
-
������:scrapy ��selenium
-
request��,urlibԭ������
2.2 �������:
-
��������
����������һ�ְ���һ������,�Զ�ץȡ������Ϣ�ij�����߽ű���
���ڻ��������ݵĶ�����,��Դ��������,���ڸ����û�������ץȡ�����ҳ������,�Ѿ���Ϊ����������ȡ����
-
����ı���
ģ�����������ҳ,��ȡ��ҳ��������Ҫ�IJ�������
-
���湤������
- �۲�ҳ������:ʹ��Ctrl+u�鿴��ҳԴ��,ѡ��ijԪ��,�������
- ����Ŀ����ҳ�������Ӧ
- ������Ϣ��ȡ����,ʹ��re(����)��������ҳ������,beautiful soup xpath bs4
- ��ȡ��ҳ���ݲ�����
-
����ͨ����Ҫͨ������,������ʽ:
������Ϣ��ȡ����,ʹ��re(����)��������ҳ������,beautiful soup xpath bs4
2.4 Scrapy ����
2.4.1 Scrapy �������Ҫ�����Լ�����
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-pHCwfals-1634735959385)(C:/Users/Lenovo/AppData/Roaming/Typora/typora-user-images/image-20211019203520100.png)]
- Scrapy Engine(����): ����Spider��ItemPipeline��Downloader��Scheduler�м��ͨѶ,�źš����ݴ��ݵȡ�
- Scheduler(������): ������������淢������Request����,������һ���ķ�ʽ������������,���,��������Ҫʱ,���������档
- Downloader(������):��������Scrapy Engine(����)���͵�����Requests����,�������ȡ����Responses������Scrapy Engine(����),�����潻��Spider������
- Spider(����):������������Responses,���з�����ȡ����,��ȡItem�ֶ���Ҫ������,������Ҫ������URL�ύ������,�ٴν���Scheduler(������)
- Item Pipeline(�ܵ�):��������Spider�л�ȡ����Item,�����н��к��ڴ���(��ϸ���������ˡ��洢��)�ĵط�.
- Downloader Middlewares(�����м��):�����Զ�����չ���ع��ܵ����(������cokies��)��
- Spider Middlewares(Spider�м��):�����Զ���չ�Ͳ��������Spider�м�ͨ�ŵĹ������(�������Spider��Responses;�ʹ�Spider��ȥ��Requests)
2.4.2 Scrapy �����������
- ����ӵ�������ȡ��һ������(URL)���ڽ�������ץȡ
- �����URL��װ��һ������(Request)����������
- ����������Դ��������,����װ��Ӧ���(Response)
- �������Response
- ������ʵ��(Item),��ʵ��ܵ����н�һ���Ĵ���
- ��������������(URL),���URL�����������ȴ�ץȡ
2.4.3 �봫ͳ��request����Ա�
- scrapy�Ƿ�װ�����Ŀ��,��������������,������,��־���쳣����,���ڶ��߳�, twisted�ķ�ʽ����,���ڹ̶�������վ����ȡ����,������,���Ƕ��ڶ���վ��ȡ 100����վ,�������ֲ�ʽ��������,�������,�����������չ��
- request ��һ��HTTP��, ��ֻ������,��������,����HTTP����,����һ��ǿ��Ŀ�,����,����ȫ���Լ�����,����Ը���,�߲�����ֲ�ʽ����Ҳ�dz����,���ڹ��ܿ��Ը���ʵ��
2.4.4 scrapy�������������
-
�ֶ�����scrapy��Ŀ�� p (mkdir p)
-
����������,���뵽����Ŀ�� cd ��p����

-
scrapy startproject ��Ŀ����
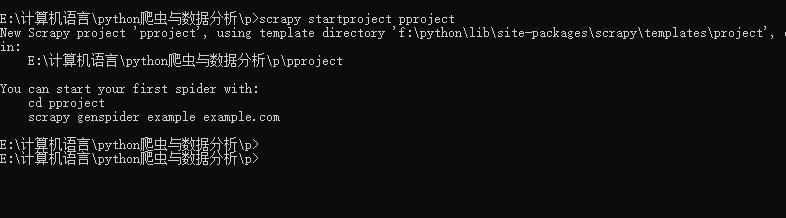

cd E:/p/��Ŀ���ƽ��뵽����Ŀ�к�,Ȼ��ִ�� scrapy genspider XXX XXX

-
������Ϣ,����itempiplines�ȵ�����
��������������ļ�settings.py���ֵ�����,����item������
-
�������
�����ǵ�ptest�����д������
2.5 Selenium ������
2.5.1 ����
��ȡ��̬ҳ��,����webӦ�ò��ԵĹ���,selenium����ֱ�������������,����ģ���˵IJ���,������ЧӦ�Է�������
2.5.2 ��װ������
- pip install
- ��anaconda����
- pycharm ֱ�����ؿ�
2.5.3 ��λԪ�ط�ʽ
�кܶ���Ԫ�ض�λ�ķ���,�������id��name��xpath��css selector�ȷ�ʽ����λ
-
���ص���Ԫ��:
- find_element_by_id()
- find_element_by_name()
- find_element_by_xpath()
- find_element_by_link_text()
- find_element_by_partial_link_text()
- find_element_by_tag_name()
- find_element_by_class_name()
- find_element_by_css_selector()
-
�����б�:
-
find_elements_by_name()
-
find_elements_by_xpath()
-
find_elements_by_link_text()
-
find_elements_by_partial_link_text()
-
find_elements_by_tag_name()
-
find_elements_by_class_name()
-
find_elements_by_css_selector()
��Ϊid��Ψһ�������Ҿ��ò��ܷ����б�
-
3 . ���ݿ��������ѯ
3.1 Mysql���ݿ�
3.1.1��װ������
- ��װmysql
- ����ٰ�װһ��mysql�û�ͼ�λ������������navicate
- ���û�������
- ����pymysql��
3.1.2 python����mysql���ݿ�
��������:
- �½����ݿ�
- �½���
- �������ݿ�
- ��ǰ���ݿ��еı���������
3.2 MongoDB ���ݿ�
3.2.1��װ������
- ��װMongoDB
- ����ٰ�װһ��MongoDB�û�ͼ�λ������������navicate
- ���û�������
- ����pymongo��
3.2.2 python����mysql���ݿ�
��������:
- �½�����
- �½����ݿ�
- �������ݼ�
- ��ǰ���ݼ��²�������
4. ���ݷ���
4.1 numpy
4.1.1 ����Ĵ���
import numpy as np
np.ones(5)
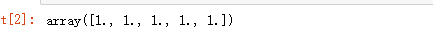
A=np.array([[1,2],[3,4]])

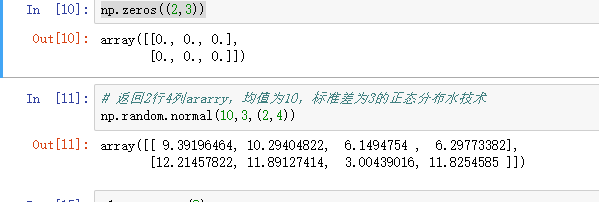
np.zeros((2,3))
4.1.2 ����ı���
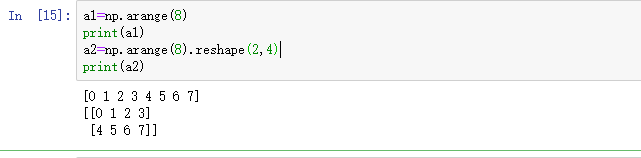
a2=np.arange(8).reshape(2,4)
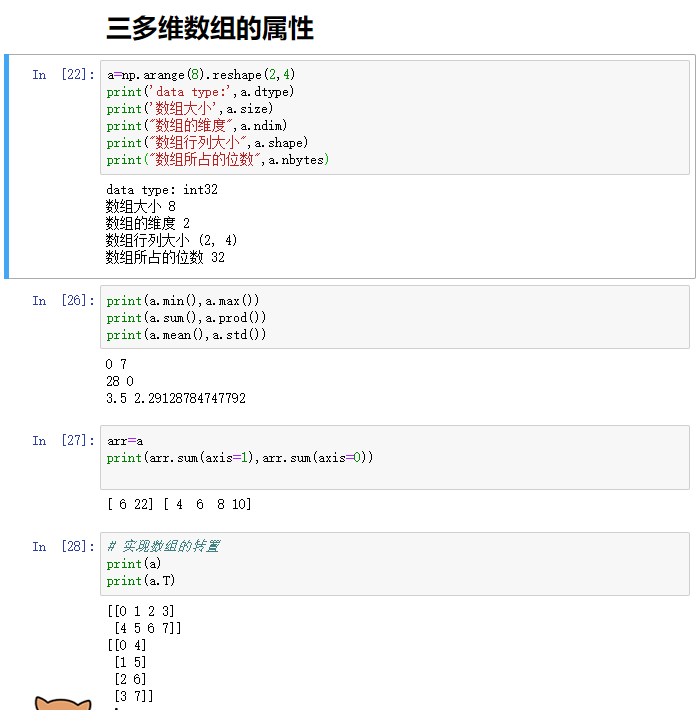
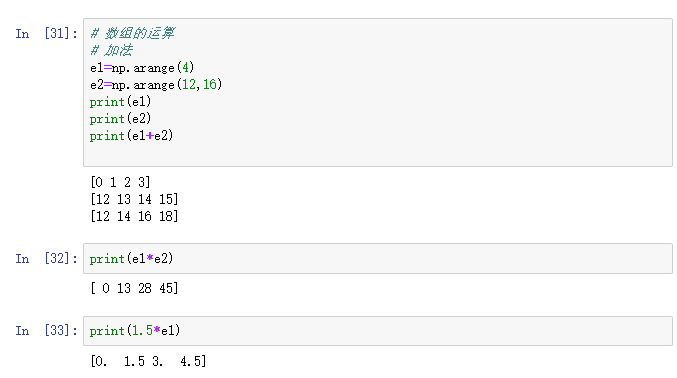
4.1.3 ����ļ���
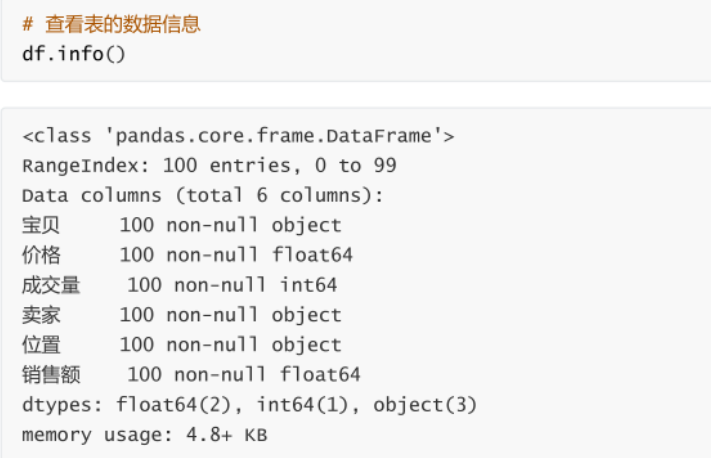
4.2 pandas
4.2.1 ���ݶ�д��ѡ������������
-
��csv�ж�ȡ����
import pandas as pddf =pd.read_csv("./���ݰ��ͰͰ�.csv")��ʵ�����Զ�ȡhtml��txt
������:
df=pd.read_csv("./shujv.cvs",delimiter=",",encoding="utf-8",header=0)#delimiter����ô���ķ�ʽ���ָ�;���뷽ʽutf-8;����0��Ϊͷ�� -
��csv�������
df.to_csv("./ababab.csv",columns=["��ؐ","�۸�"],index=False,header=True)��Ҫ����,����ͷ�����е���
-
����ѡȡ
-
�е�ѡȡ
rows =df[0:3]ѡ���0�е���2������
r=df.head()ѡȡǰ����
-
�е�ѡȡ
cols =df[['����','�۸�']] -
��
ȡ0��3�еı����ͼ۸�
df.loc[0:3,['����','�۸�']] -
�����кͿ�
�����е����д���һ������
df['���۶�']=df['�۸�']*df['�ɽ���']df.head()#�鿴һ��ǰ�������� -
��������������
df1=[(df["�۸�"]<100)&(df["�ɽ���"]>1000)]ɸѡ��,�۸�С��100,�ɽ�������1000������
-
-
��������
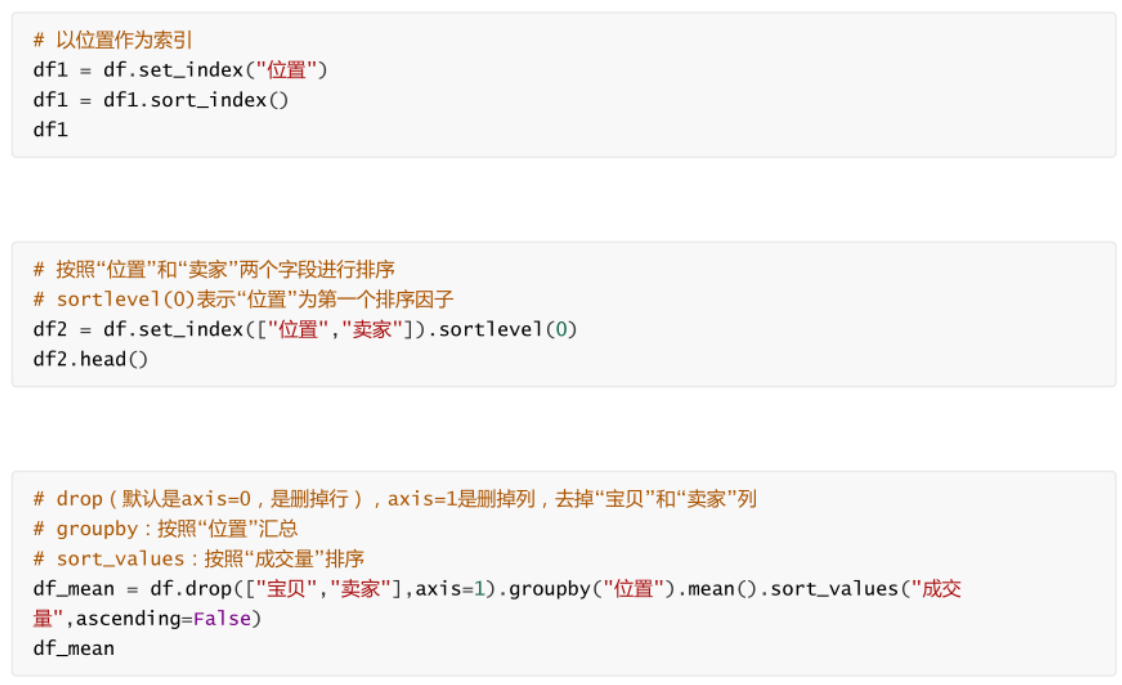

-
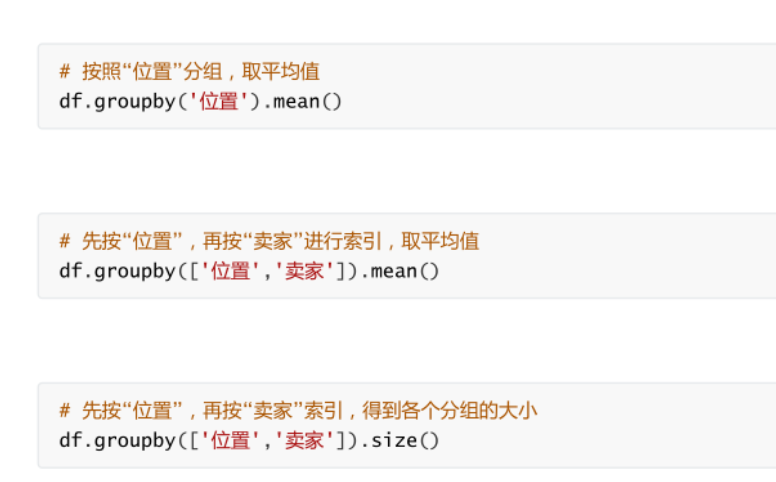
��������

4.2.2 ���ݷ��顢�ָ�ϲ��ͱ���
-
����
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-EzhROGsp-1634735959479)(C:/Users/Lenovo/AppData/Roaming/Typora/typora-user-images/image-20211019232946860.png)]

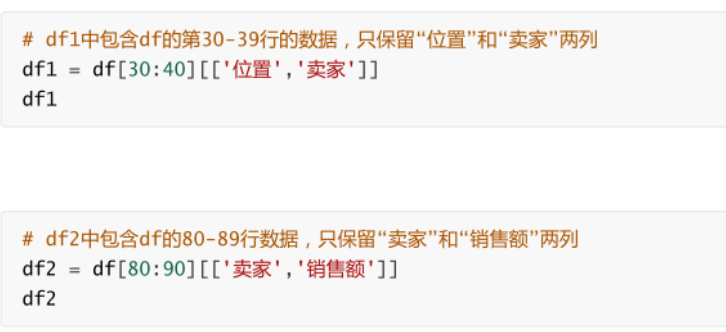
-
�ָ�
ǰ�պ�
-
�ϲ�
-
dataframe�ϲ�
pd.merge(df1,df2,how='left',on="����")#������pd.merge(df1,df2,how='outer',on="����")#������pd.merge(df1,df2,how='right',on="����")#����ָ��on�Ǹ��о�Ĭ����ͬ��ѡ��������ͬ��һ��
-
�����ϲ�
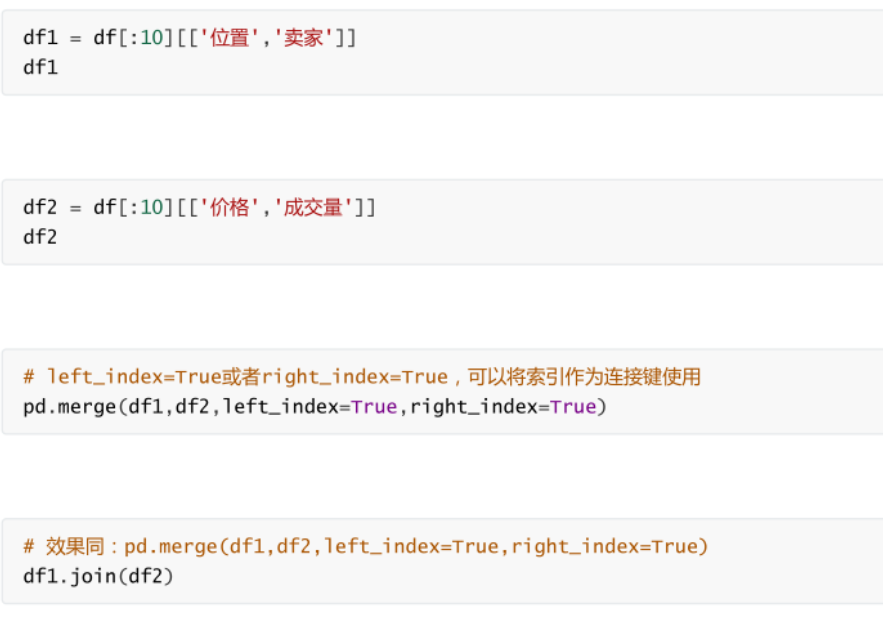
-
��������
��axis=1��ƴ��,axisΪ0���ǰ���,Ĭ�Ͼ����С�
pd.contact([col1,col2,col3],axis=1)
-
-
����
-
���ܲ�λ�


-
�����ӱ�:
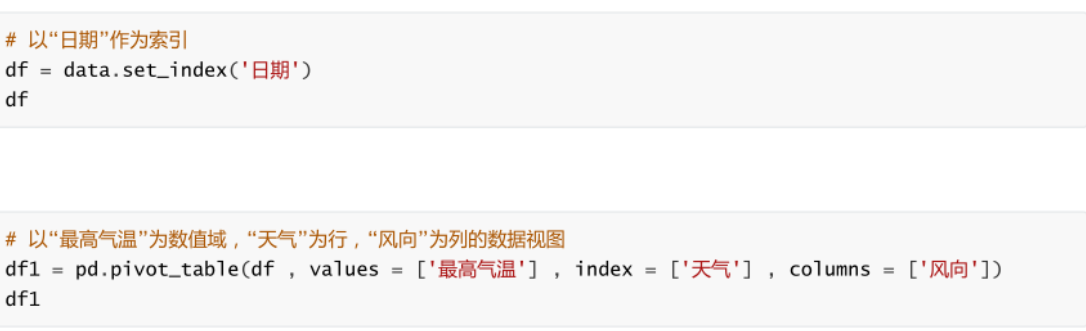
-
-
4.2.3 ȱʧֵ


5. ���ݿ��ӻ�
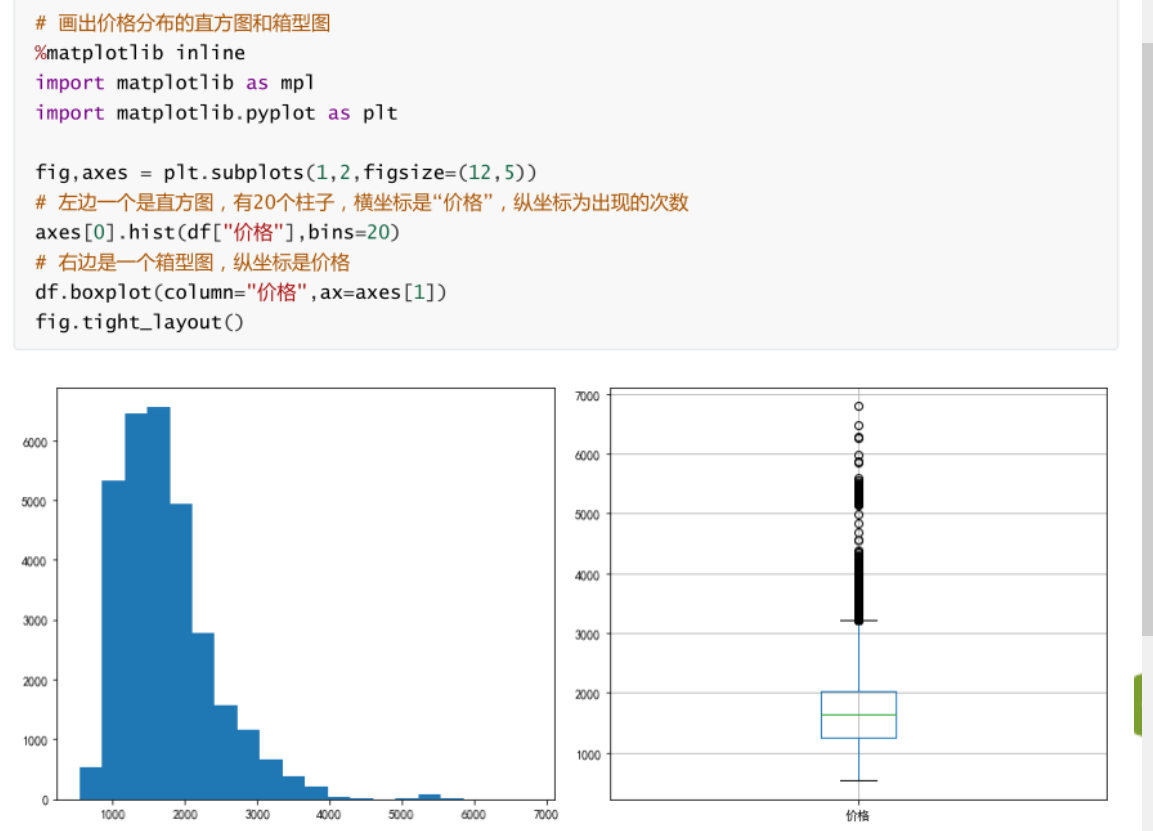
5.1 matplotlib��ͼ����:
-
��ʼ��,����,����,�趨����
import matplotlibimport matplotlit.pylot -
����һ������(�涨������С,����ϵ)
fig,axes =plt.subplots(1,2,figsize=(12,5)) -
��ͼ(��״)
axes[0].hit(df,bins=20) -
�Զ�������ʽ
fig.tight_layout()
5.2 ����