在自然语言处理中,处理句法结构树是比较常见的处理问题,如何对句法结构树进行遍历,以及如何抽取出其中的层次关系,是值得去深究的。
本文将从Stanfordcorenlp的句法结构树和nltk中的Tree的数据结构入手,进行对句法结构树的层次遍历,抽取出句子中所包含的句法的层次结构。
首先需要安装Stanfordcorenlp(请自行CSDN),然后安装nltk(pip一下就可以用其中的Tree模块了)
例句:公安部治安局局长刘绍武介绍,这次销毁的非法枪支来源于三个方面。
句法结构树可以通过nltk中draw()画出来如下图:
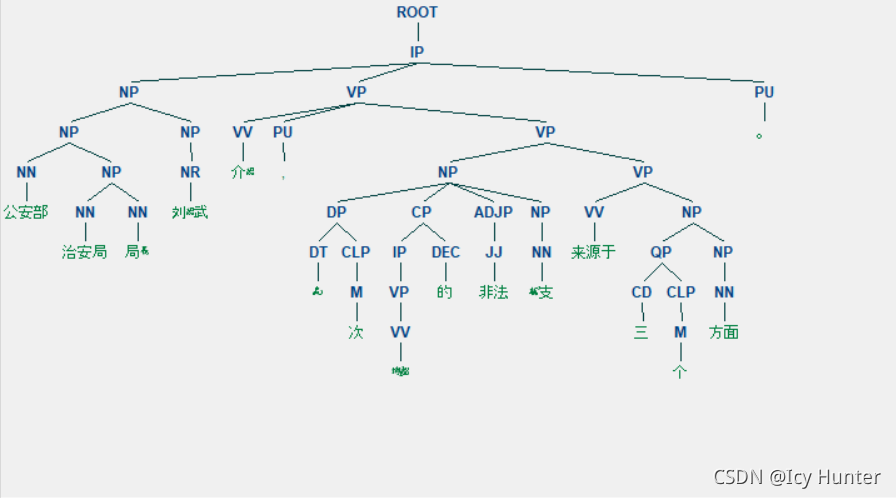
(字体有些变形)
通过递归来进行对句法结构的遍历,代码简洁,运行结果如下:
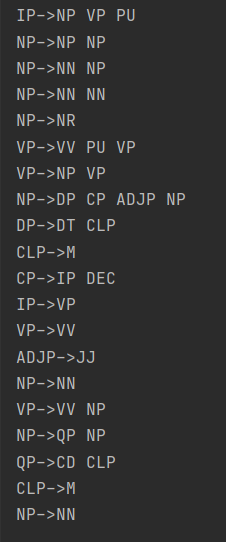
对照上面的结构树可见 “->”代表的是层次关系,“->”前是上一层的叶节点(这一层的根节点),‘->’后是这一层的叶节点,然后同层的叶节点以空格连接,从而反应出句法结构的层次关系。
代码如下:
from stanfordcorenlp import StanfordCoreNLP
from nltk import Tree
cen = []
def cenxun(tree):
c = [] # 每一层结果的储存
if type(tree[0]) == str: # 如果遇到字符,即到达了叶子节点,便返回
return
else:
root = [] # 储存子树,即遍历下一层时,每个子树的开始都是作为根
r = tree.label() # 取出当前节点的句法英文标注
for i in range(len(tree)): # 遍历这棵树的子树,root中储存子树,c中保留每棵子树根节点的标注
root.append(tree[i]) # 即这棵树的叶节点的标注,作为一层的信息
c.append(tree[i].label())
c = " ".join(c) # 每层的叶子节点用空格连接
c = r + "->" + c # 根节点用->连接每层的叶节点
cen.append(c) # 将每次遍历的结果存cen中
for rt in root: # 遍历得到的子树,将每个子树作为新的一棵树进行遍历
cenxun(rt) # 递归调用就可以
return
def main():
lang = "zh"
nlp = StanfordCoreNLP(r'E:\stanford-corenlp-4.2.2', lang=lang)
try:
sentence = "公安部治安局局长刘绍武介绍,这次销毁的非法枪支来源于三个方面。"
parse = nlp.parse(sentence)
t = Tree.fromstring(parse)
cenxun(t[0])
t.draw() # 展示句法结构树
except:
print("meet error")
nlp.close()
print("\n".join(cen))
if __name__ == '__main__':
main()
``