李宏毅机器学习Task05
梯度下降法的困难
本次重点关注神经网络算法中在用梯度下降法寻找最佳的那个
f
?
f^*
f?时,如果梯度为0其实意味着是一个极值点,并不一定是一个最值点,基本的情况可以分为鞍点,和极值点,如图所示(左为鞍点,右边为极小值点)
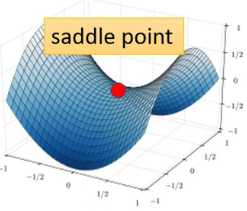
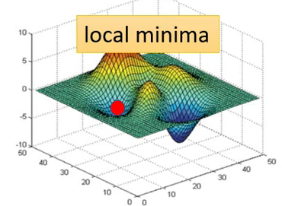
多维情况下的泰勒展开
损失函数在一组向量下的值可以用附近的近似为:
L
(
θ
)
≈
L
(
θ
′
)
+
(
θ
?
θ
′
)
T
g
+
1
2
(
θ
?
θ
′
)
T
H
(
θ
?
θ
′
)
L(\bm\theta)\approx L(\bm\theta')+(\bm\theta-\bm\theta')^T \bm{g}+\frac12(\bm\theta-\bm\theta')^TH(\bm\theta-\bm\theta')
L(θ)≈L(θ′)+(θ?θ′)Tg+21?(θ?θ′)TH(θ?θ′)
-
g 梯度向量,为函数对各参数的一阶偏导向量。
-
H 海森矩阵,里面的内容是损失函数的二阶偏导。
由于我并未接触过海森矩阵,这里补充学习一下。
海森矩阵常用于牛顿法解决优化问题,利用海森矩阵可判定多元函数的极值问题。

-
N元函数的海森矩阵是一个N阶方证。
-
海森矩阵的对角第n行意味是对第n个参数的二阶偏导。
-
海森矩阵的第i行第j列是分别对第i个和第j个参数求偏导的二阶偏导。
是极值,还是鞍点?
一旦梯度下降法不能再更新参数时,梯度向量肯定为0,那么根据前面的泰勒展开,我们可以划为:
L
(
θ
)
≈
L
(
θ
′
)
+
1
2
(
θ
?
θ
′
)
T
H
(
θ
?
θ
′
)
L(\bm\theta)\approx L(\bm\theta')+\frac12(\bm\theta-\bm\theta')^TH(\bm\theta-\bm\theta')
L(θ)≈L(θ′)+21?(θ?θ′)TH(θ?θ′)
为了方便表示我们将
θ
?
θ
′
\bm\theta-\bm\theta'
θ?θ′用
v
v
v来表示,此时将有三种情况:
- 对于所有的 v v v, v T H v > 0 v^THv>0 vTHv>0,此时 L ( θ ) > L ( θ ′ ) L(\bm\theta)>L(\bm\theta') L(θ)>L(θ′),意味着这里为局部最小值。同时,H矩阵所有特征值为正。
- 对于所有的 v v v, v T H v < 0 v^THv<0 vTHv<0,此时 L ( θ ) < L ( θ ′ ) L(\bm\theta)<L(\bm\theta') L(θ)<L(θ′),意味着这里为局部最大值。同时,H矩阵所有特征值为负。
- 当 v T H v v^THv vTHv有时大于0有时小于0时,这里为鞍点。H矩阵特征值征服不统一。
鞍值点的更新
当梯度为0时,如果确保此时遇见的是鞍值点,那么我们并不用担心太多。鞍值点附近的值与鞍值比可大可小。
此时应该求出H矩阵特征值所对应的特征向量,通过验证,下一步的更新可以沿着特征向量的方向更新参数,此时亦可以减小损失函数值。
存在极值点吗?
如果是极值的情况,旁边的值均比当地值大,似乎我们就没有了好的对策。
老师用三体故事中的例子告诉我们低维的一个密不透风的物体,高维情况下也许有空隙;一个二次函数的极值,增加一个维度看很可能就是一个鞍值点。
所幸,深度学习所用的参数一般有成百上千个,所以我们遇到的大多数都是鞍值点,也就有办法解决梯度为0的问题了。
分批运算
我们在用数据训练神经元的时候,并不是将所有的数据一起运算,分批次运算。比如说我们有2000个样本数据,我们可以将 2000 个样本分成大小为 500 的 batch,此时的batch size为500。我们将看完一次所有数据称为一个epoch(期),看完一期之后,一般会SHUFFLE(重新分批)多次运算。
直观来看,批次尺寸越大时,所需要的时间越多,同时每次用梯度下降更新参数的力度会比较大(其实就是更的值会越大),而小的批次尺寸需要的时间更短,同时数据更新参数会显得波动明显。


但是实际上在有着GPU加速图形运算后,小的batch size在GPU的一定能力内,与大的batch size所花费的时间差距并不大。
图中详细比较了大的batch size 和小的batch size的优劣。

总的来看,越小的batch size在完成一整个epoch(一期)时,速度不占优,但是他在最终的
f
?
f^*
f?的选择以及去用测试集数据检验时,效果会优于大的batch size。
实际问题中, batch size是一个需要综合决定的一个参数。
标准化法
有的时候会有很多使得梯度变化比较小的地方,像一条汹涌河流里面的浪的情况,这会让梯度下降变得很慢,老师介绍了一种比较常见的经典标准化的方法:batch normalization批次标准化的方法。
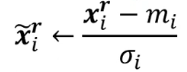
即对每一层的数据做如上处理,m代表均值,
σ
\sigma
σ代表偏差,当然,这种方法要求批次里面数据的值要大,否则的话太偶然,情况没用。
需要注意的是,在输入的数据标准化之后,经过第一层神经网络之后的输出,我们依然需要进行标准化。

还有需要注意的点就是,在给数据标准化的时候,这一部分已经需要考虑成网络结构的一部分,而不是独立的部分,计算均值和偏差以及之前的部分,构成了一个巨大的神经网络。
我们一般在利用均值方差之后,还会再做一次变换:
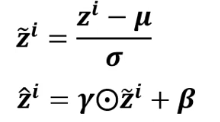
很多时候我们不可能等到数据满了一批的尺寸大小时再计算均值偏差,会考虑加上参数p来计算,pytorch种p的值默认为0.1。
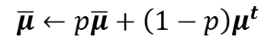
批标准化的优点及原因
批标准化的作者实验出了批标准化的方法有助于加快速度,同时竟然可以让原本不能运作的sigmoid激励函数运作起来,他认为批标化能够起作用的原因是在与解决了内部参数影响的原因,但是这种说法被之后的一篇论文所否定。目前人们也并没有给出更合理的解释,它的发现与盘尼西林一样具有一种偶然性,确实给出了一种方法能够有助于寻找最优解的过程。
再谈梯度下降
前文我们主要关注关键点(极值或鞍值),但是实际上在找最优时最大的阻碍并不是遇见了关键点,个人觉得通过计算机这种通过很多的运算来碰巧走到那个点上,遇见梯度为0的情况其实很少,其实在梯度不为0的时候我们可能就见到了损失函数无法降低的情况了,所以实际上,学习率的设定其实还是要重要一些。
自适应学习率
在之前的Task3中我其实已经学习过,具体的方法就是每个参数的学习率都把它除上之前微分的均方根。如图片所示
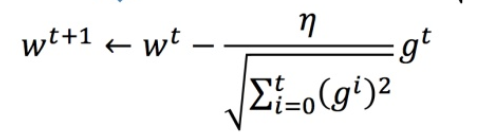
详细内容见Task3的记录。
RMSProp
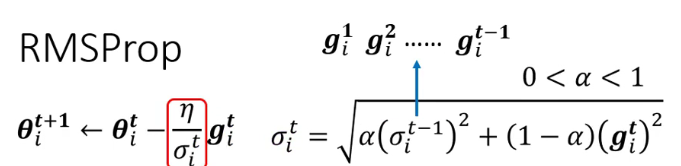
此项技术与之前方法的区别在于它给了一个权重,权重可以反映出之前梯度对本次参数更新的重要性,相比最初的算法要更明确。
动量法
动量法模拟物理上真实的小球遇到极值点和鞍值点的情况,由于小球有惯性,小球会冲过上述情况的两个点。于是我们在更新参数的时候不仅考虑梯度的方向也考虑上次移动的方向,这两个方向合成的结果来寻找损失函数的下一个低点,这个方法在考虑更新方向的时候,考虑的不仅仅是这一次的方向,而是所有梯度方向的总和。
Adam法
这个方法实际上就是将RMSProp法和动量法结合,将RMSProp中的梯度改为动量法的动量,然后更新参数,本方法是目前深度学习中运用的最多的方法。
Transformer法
本方法并没有什么确切的模型,老师的评价类似于是黑科技,总体上看,它的学习率是先增长后降低的形式。很多时候就是要用Transformer法来解决,但是为什么要这样,人们其实也并没有什么很好的解释。