学习心得
(1)为了解决神经网络随着层数的增加,参数量巨大的问题,GoogleNet利用1×1卷积核,并且分别通过几个不同的卷积核进行处理,有多个相同的模块用Inception类封装;
(2)另一种网络ResNet是为了解决梯度消失(由于在梯度计算的过程中是用的反向传播,所以需要利用链式法则来进行梯度计算,是一个累乘的过程。若每一个地方梯度都是小于1的,累乘后梯度会趋于0)的问题。
(3)构造网络的超参数和input、output的size需要计算好。为了检验网络是否正确,可以先对net简单测试(输入rand的tensor代入),如注释其他层,看前面层的结果和预期的tensor大小是否吻合,即【增量式开发】。
文章目录
零、简单回顾
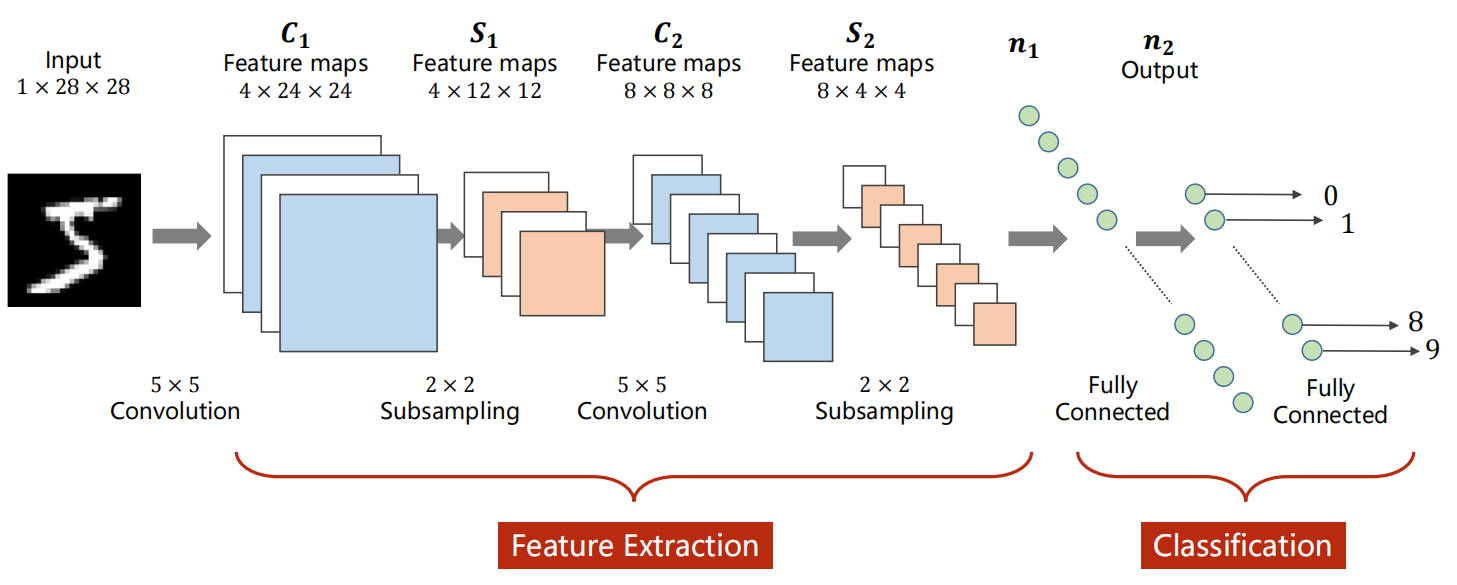
上节课主要讲了CNN的架构(如下图的LetNet5),
- 定义一个卷积层:输入通道数、输出通道数、卷积核的大小(长和宽)。卷积层要求输入输出是四维张量
(B,C,W,H),全连接层的输入与输出都是二维张量(B,Input_feature)。 - 卷积(convolution)后,C(Channels)变,W(width)和H(Height)可变可不变,取决于是否padding。subsampling(或pooling)后,C不变,W和H变。
- 如果要有m个输出channel,就要使用m个卷积核:
1)每个卷积核的通道数要求和输入通道相同;
2)卷积核的组数是和输入的通道数相同;
3)卷积核的大小由自己来定,和图像的大小无关,一般设置为正方形,边长为奇数(其实设置为长方形也是可以的)。
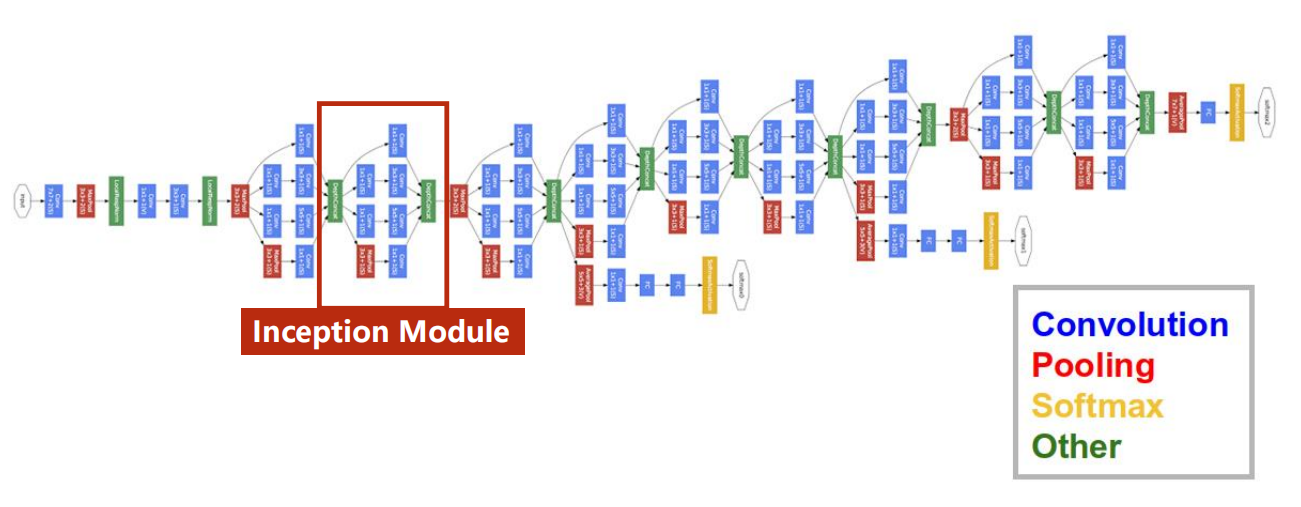
一、GoogleNet
减少代码冗余:函数or类。从下图的GoogleNet可以看出
1.1 Inception模块
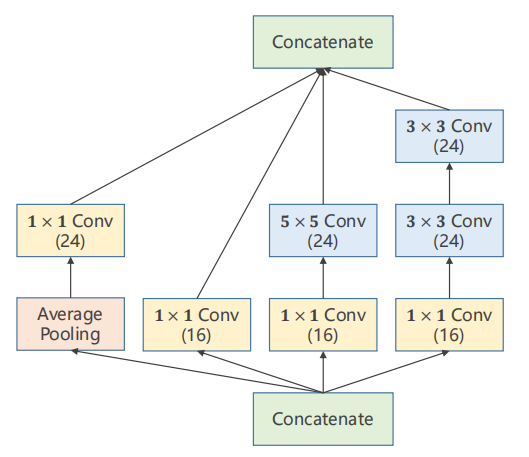
(1)最后要拼接在一起,要求每个的宽度和高度一致。走不通路径出来的,(B,C,W,H)唯一可以不同的是channel。
(2)padding可以维持高度和宽度不变;average pooling也可以通过padding和stride使高度和宽度不变。
1.2 1×1卷积核
1×1卷积核能够改变通道数的数量。1×1卷积核个数取决于input的通道数。如下图记得将三个颜色的矩阵相加。
不论input的通道为多少,如下图最后做完1×1卷积后都是从C×W×H变为1×W×H的feature map。
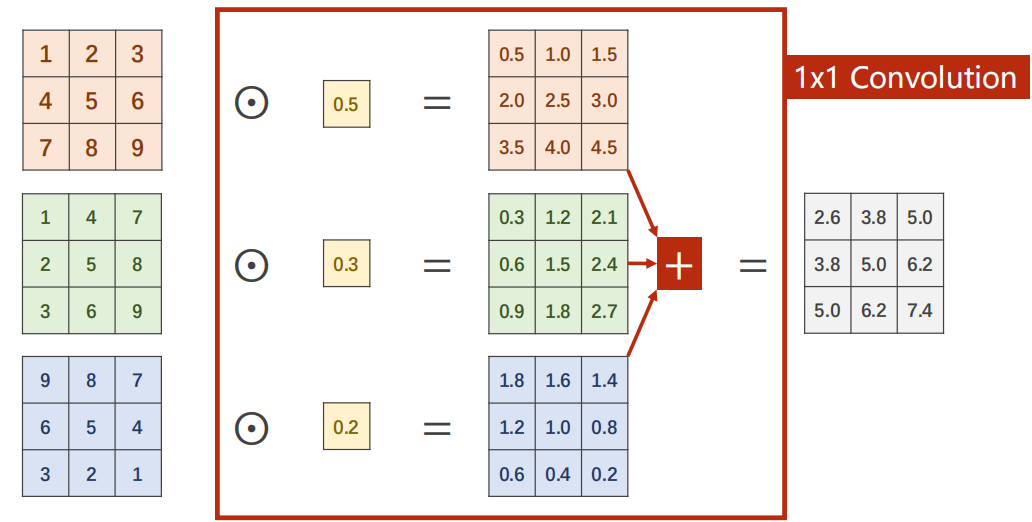
如果需要变为C’×W×H的feature map,那就将C’组【3个1×1组合起来卷积核】,可以回顾上次讲CNN的多通道卷积运算。
1×1卷积核可以跨越不同通道相同位置的元素值(结果的某个位置可以包含input的所有相同位置的信息,即信息融合)。
二、可减少参数量的1×1卷积核
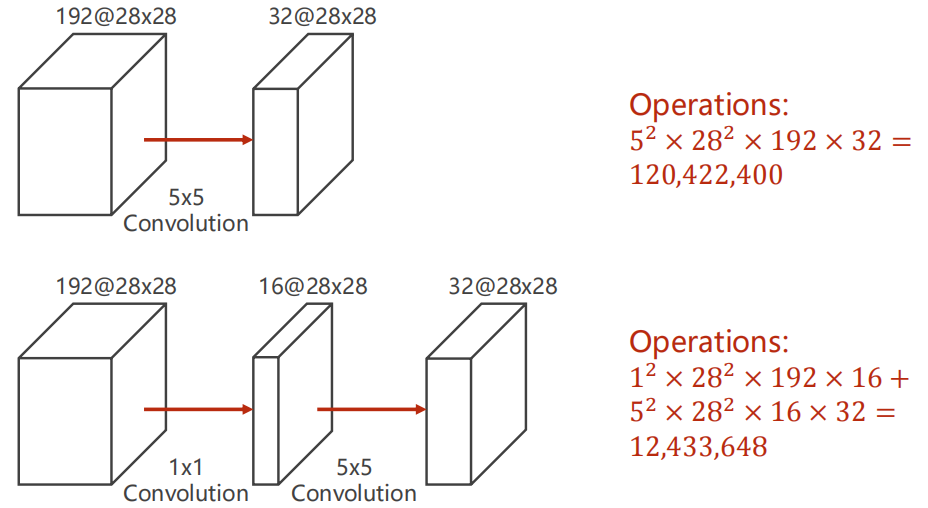
(1)下图首先用5×5卷积:每个通道需要拿25个像素进行运算;假如进行padding,则需要对28×28的每个元素都进行运算;每次卷积要对192个通道上进行,这样的运算进行了32次才能得到output。
(2)为了减少参数量,可以使用1×1卷积直接改变通道数,下图可见参数量是第一种的十分之一。
括号内为output的通道数。
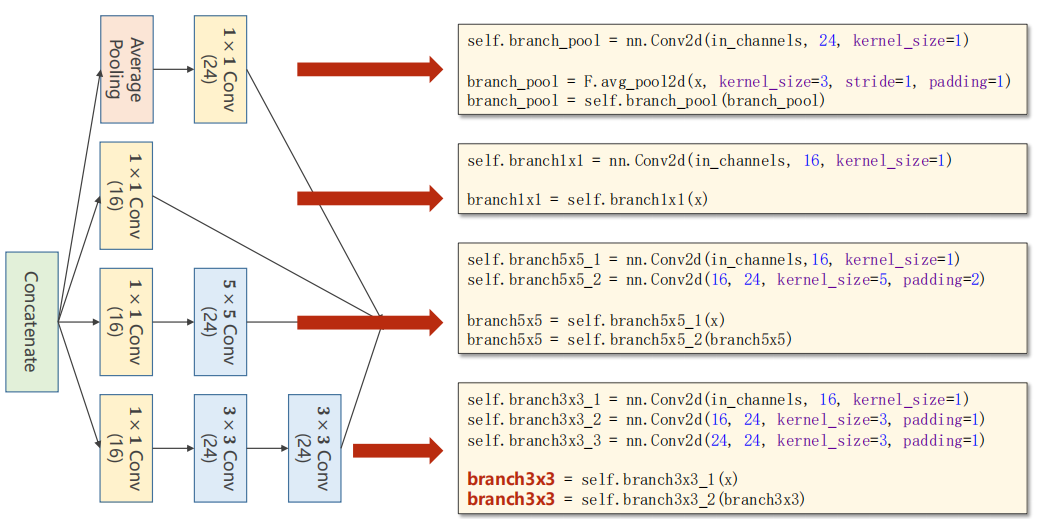
最后拼接所有块,沿着维度=1(因为从0开始计算,维度分别为B,C,W,H)。
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim = 1)

三、GoogleNet代码实践
结合上面的googleNet介绍,详看下面代码注释。
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 21 14:10:19 2021
@author: 86493
"""
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
# 准备数据
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081))])
train_dataset = datasets.MNIST(root = '../dataset/mnist/',
train = True,
download = True,
transform = transform)
train_loader = DataLoader(train_dataset,
shuffle = True,
batch_size = batch_size)
test_dataset = datasets.MNIST(root = '../dataset/mnist/',
train = False,
download = True,
transform = transform)
test_loader = DataLoader(test_dataset,
shuffle = False,
batch_size = batch_size)
class InceptionA(nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels,
16,
kernel_size = 1)
self.branch5x5_1 = nn.Conv2d(in_channels,
16,
kernel_size = 1)
# 为了保证高和宽不变,设置padding
self.branch5x5_2 = nn.Conv2d(16,
24,
kernel_size = 3,
padding = 1)
self.branch3x3_1 = nn.Conv2d(in_channels,
16,
kernel_size = 1)
self.branch3x3_2 = nn.Conv2d(16,
24,
kernel_size = 3,
padding = 1)
self.branch3x3_3 = nn.Conv2d(24,
24,
kernel_size = 3,
padding = 1)
self.branch_pool = nn.Conv2d(in_channels,
24,
kernel_size = 1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
# 为了保证高和宽不变,设置padding,下面这个没有要学习的参数
branch_pool = F.avg_pool2d(x,
kernel_size = 3,
stride = 1,
padding = 1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim = 1)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size = 5)
# 88=24×3+16
self.conv2 = nn.Conv2d(88, 20, kernel_size = 5)
self.incep1 = InceptionA(in_channels = 10)
self.incep2 = InceptionA(in_channels = 20)
self.mp = nn.MaxPool2d(2)
# self.fc = nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
# 下面这句的output=88
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
# 下面这句的output=88
x = self.incep2(x)
# 做全连接,结果是通过flatten得到1408个元素
x = x.view(in_size, -1)
print("x.shape:", x.shape)
# x = self.fc(x)
return x
# CNN网络
class Net1(nn.Module):
def __init__(self):
super(Net1, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size = 5)
self.conv2 = nn.Conv2d(10, 20, kernel_size = 5)
self.pooling = nn.MaxPool2d(2)
self.fc = nn.Linear(320, 10)
def forward(self, x):
# Flatten data from (n, 1, 28, 28)to(n, 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
# flatten
x = x.view(batch_size, -1)
# print("x.shape", x.shape)
x = self.fc(x)
return x
model = Net()
"""
X = torch.rand(4, 1, 28, 28)
model(X) # 打印x.shape: torch.Size([4, 1408])
"""
# print(model)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 有多个显卡时则可以填其他cuda号
model.to(device)
# 把模型的参数等放到显卡中
# 设计损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),
lr = 0.01,
momentum = 0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# 1.准备数据
inputs, target = data
# 迁移到GPU,注意迁移的device要和模型的device在同一块显卡
inputs, target = inputs.to(device), target.to(device)
# 2.前向传递
outputs = model(inputs)
loss = criterion(outputs, target)
# 3.反向传播
optimizer.zero_grad()
loss.backward()
# 4.更新参数
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss:%.3f'%
(epoch + 1,
batch_idx + 1,
running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
# 求出每一行(样本)的最大值的下标,dim = 1即行的维度
# 返回最大值和最大值所在的下标
_, predicted = torch.max(outputs.data, dim = 1)
# label矩阵为N × 1
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set :%d %% ' % (100 * correct / total))
return correct / total
if __name__ == '__main__':
epoch_list = []
acc_list = []
for epoch in range(10):
train(epoch)
acc = test()
epoch_list.append(epoch)
acc_list.append(acc)
plt.plot(epoch_list, acc_list)
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.show()
结果为99%的准确率,比上次的CNN高了1%。

[1, 300] loss:0.952
[1, 600] loss:0.216
[1, 900] loss:0.150
accuracy on test set :96 %
[2, 300] loss:0.112
[2, 600] loss:0.097
[2, 900] loss:0.085
accuracy on test set :97 %
[3, 300] loss:0.078
[3, 600] loss:0.072
[3, 900] loss:0.063
accuracy on test set :98 %
[4, 300] loss:0.059
[4, 600] loss:0.057
[4, 900] loss:0.062
accuracy on test set :98 %
[5, 300] loss:0.049
[5, 600] loss:0.052
[5, 900] loss:0.053
accuracy on test set :98 %
[6, 300] loss:0.048
[6, 600] loss:0.044
[6, 900] loss:0.045
accuracy on test set :98 %
[7, 300] loss:0.040
[7, 600] loss:0.047
[7, 900] loss:0.038
accuracy on test set :98 %
[8, 300] loss:0.035
[8, 600] loss:0.037
[8, 900] loss:0.041
accuracy on test set :98 %
[9, 300] loss:0.033
[9, 600] loss:0.038
[9, 900] loss:0.035
accuracy on test set :98 %
[10, 300] loss:0.031
[10, 600] loss:0.031
[10, 900] loss:0.036
accuracy on test set :99 %
如果打印model也能看到对应的结构:
Net(
(conv1): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(88, 20, kernel_size=(5, 5), stride=(1, 1))
(incep1): InceptionA(
(branch1x1): Conv2d(10, 16, kernel_size=(1, 1), stride=(1, 1))
(branch5x5_1): Conv2d(10, 16, kernel_size=(1, 1), stride=(1, 1))
(branch5x5_2): Conv2d(16, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(branch3x3_1): Conv2d(10, 16, kernel_size=(1, 1), stride=(1, 1))
(branch3x3_2): Conv2d(16, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(branch3x3_3): Conv2d(24, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(branch_pool): Conv2d(10, 24, kernel_size=(1, 1), stride=(1, 1))
)
(incep2): InceptionA(
(branch1x1): Conv2d(20, 16, kernel_size=(1, 1), stride=(1, 1))
(branch5x5_1): Conv2d(20, 16, kernel_size=(1, 1), stride=(1, 1))
(branch5x5_2): Conv2d(16, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(branch3x3_1): Conv2d(20, 16, kernel_size=(1, 1), stride=(1, 1))
(branch3x3_2): Conv2d(16, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(branch3x3_3): Conv2d(24, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(branch_pool): Conv2d(20, 24, kernel_size=(1, 1), stride=(1, 1))
)
(mp): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
四、残差网络代码实践
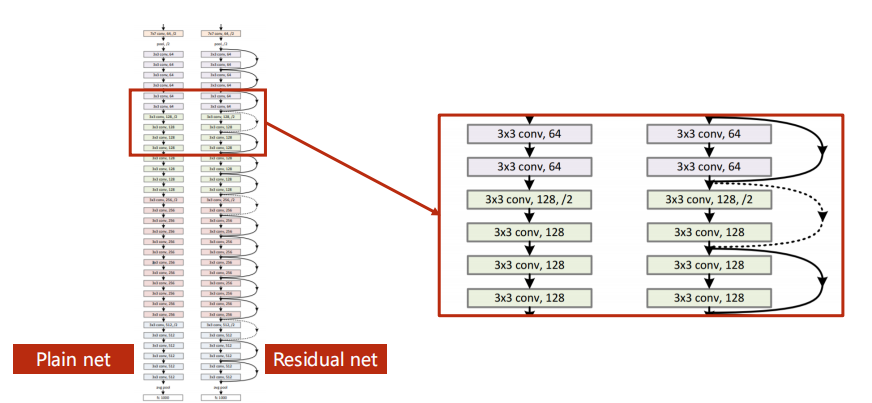
(1)residual block要求输入和输出的tensor维度相同。
(2)有的跳连接在上图汇总是虚线的,表示不一定做跳连接(因为维度不匹配的原因,无法跳跃后相加),所以需要做单独处理――如不做跳连接,或者在跳连接中做一个池化层,注意池化不改变通道数(上面栗子的正路是做一个卷积,起到/2效果)。

(3)构造网络的超参数和input、output的size需要计算好。为了检验网络是否正确,可以先对net简单测试(输入rand的tensor代入),如注释其他层,看前面层的结果和预期的tensor大小是否吻合,即【增量式开发】。
(4)卷积层中做的事,res是层间做的事。
代码如下,ResidualBlock和Net两个类变了,其余和之前没变。
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels,
channels,
kernel_size = 3,
padding = 1)
self.conv2 = nn.Conv2d(channels,
channels,
kernel_size = 3,
padding = 1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
# x+y后再relu激活
return F.relu(x + y)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size = 5)
self.conv2 = nn.Conv2d(16, 32, kernel_size = 5)
self.mp = nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
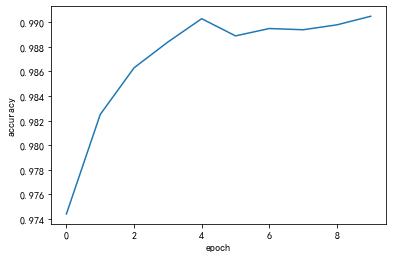
[1, 300] loss:0.524
[1, 600] loss:0.168
[1, 900] loss:0.119
accuracy on test set :97 %
[2, 300] loss:0.094
[2, 600] loss:0.079
[2, 900] loss:0.072
accuracy on test set :98 %
[3, 300] loss:0.064
[3, 600] loss:0.059
[3, 900] loss:0.055
accuracy on test set :98 %
[4, 300] loss:0.049
[4, 600] loss:0.047
[4, 900] loss:0.046
accuracy on test set :98 %
[5, 300] loss:0.042
[5, 600] loss:0.038
[5, 900] loss:0.038
accuracy on test set :99 %
[6, 300] loss:0.031
[6, 600] loss:0.036
[6, 900] loss:0.035
accuracy on test set :98 %
[7, 300] loss:0.031
[7, 600] loss:0.030
[7, 900] loss:0.031
accuracy on test set :98 %
[8, 300] loss:0.029
[8, 600] loss:0.026
[8, 900] loss:0.026
accuracy on test set :98 %
[9, 300] loss:0.024
[9, 600] loss:0.022
[9, 900] loss:0.023
accuracy on test set :98 %
[10, 300] loss:0.020
[10, 600] loss:0.021
[10, 900] loss:0.022
accuracy on test set :99 %
网络的结果也可以print出来:
Net(
(conv1): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1))
(mp): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(rblock1): ResidualBlock(
(conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(rblock2): ResidualBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(fc): Linear(in_features=512, out_features=10, bias=True)
)
更多阅读何恺明大神的论文:
He K, Zhang X, Ren S, et al. Identity Mappings in Deep Residual Networks[C]
Huang G, Liu Z, Laurens V D M, et al. Densely Connected Convolutional Networks[J]. 2016:2261-2269.
五、PyTorch学习路线
(1)理论,看花书《深度学习》
(2 )通读一遍PyTorch官方文档
(3)复现经典工作(读代码和写代码交叉进行),注意去github下别人论文代码跑通没啥用,要自己复现,不会的再去看别人的代码
(4)扩充视野。基于上面前三个能力,因为复现是一开始很花时间的,现在看别人论文应该脑海有直觉代码大概咋写,看到不会的模块再去看别人代码,吸取精华,把小模块吸收为自己的内容。
Reference
(1)PyTorch 深度学习实践 第10讲,刘二系列
(2)b站视频:https://www.bilibili.com/video/BV1Y7411d7Ys?p=10
(3)官方文档:https://pytorch.org/docs/stable/_modules/torch/nn/modules/conv.html#Conv2d
(4)吴恩达网易云课程:https://study.163.com/my#/smarts
(5)刘洪普老师博客:https://liuii.github.io/
(6)某同学的笔记
(7)pytorch官方文档:https://pytorch.org/docs/stable/index.html
(8)Deep-Learning-with-PyTorch中文版:https://tangshusen.me/Deep-Learning-with-PyTorch-Chinese/#/
(9)神经网络模型(Backbone)
(10)详解残差网络:https://zhuanlan.zhihu.com/p/42706477