����Ŀ¼
ǿ�ҽ������ڶ�����ǰ�ȿ������Ƶ�� ��ζ����ġ����ľ�����
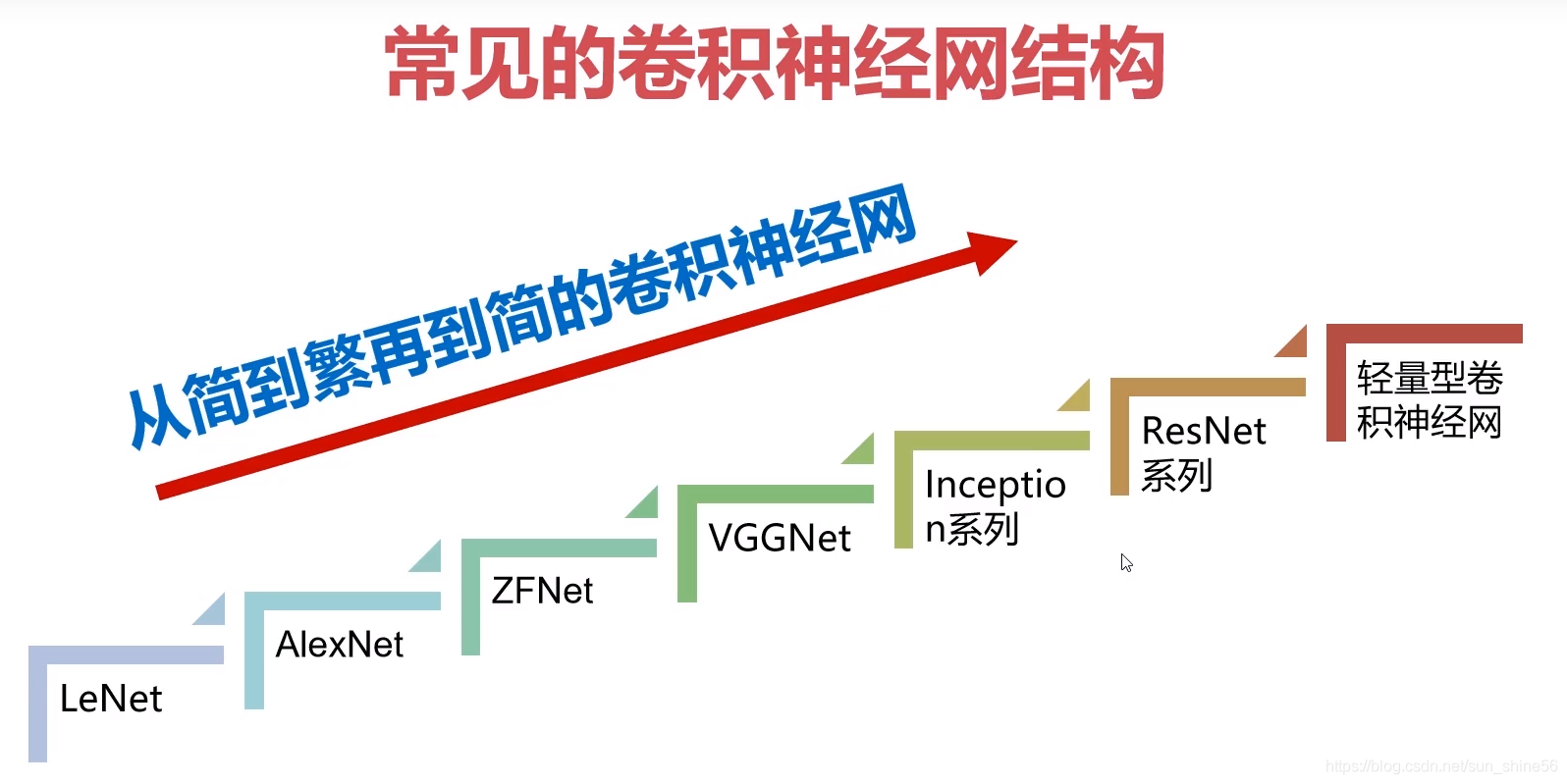
1 �����Ķ�
1.1 ����ժҪ
����ѵ����һ��������Ⱦ�������������120��߷ֱ��ʵ�ͼ��ֵ�1000��ͬ������С������������6000�������650000����Ԫ,����5��������(ijЩ�����������гػ���)��3��ȫ���Ӳ�,�����һ��1000ά��softmax��Ϊ��ѵ���ĸ���,����ʹ���˷DZ�����Ԫ���Ծ������������˷dz���Ч��GPUʵ�֡�Ϊ�˼���ȫ���Ӳ�Ĺ����,���Dz�����һ�������������Ϊdropout��������,���֤���Ƿdz���Ч�ġ�
����,����Ĺ��ܺͽṹ����ȫ�����˽�,�������ǽ���ϸ�ڽ��������̽����
1.2 ���Ĵ��µ�
�� ReLU Nonlinearity ReLU������
����Ԫ���f��ģΪ����x�ĺ����ı���ʽ����f(x) = tanh(x)��f(x) = (1 + e?x)?1�����ǵ��ݶ��½���ѵ��ʱ��,��Щ���͵ķ����Ա��DZ��ͷ�����f(x) = max(0,x)����������Nair��Hinton[20]��˵��,���ǽ����ַ�������Ԫ��Ϊ�������Ե�Ԫ(ReLU)��
�ص�:�ӿ���ѵ�����ٶȡ�
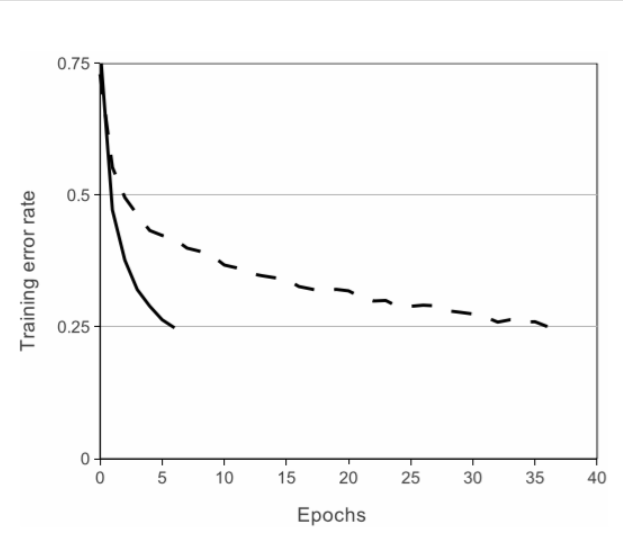 ����ͼ��,����һ���ض����IJ��������,��CIFAR-10���ݼ��ϴﵽ25%��ѵ���������Ҫ�ĵ�����������֤ʵ��һ�㡣���ͼ����,������Dz��ô�ͳ�ı�����Ԫģ��,���ǽ���������˴����������ʵ��ù�����(���߲���Relu��Ϊ�����)
����ͼ��,����һ���ض����IJ��������,��CIFAR-10���ݼ��ϴﵽ25%��ѵ���������Ҫ�ĵ�����������֤ʵ��һ�㡣���ͼ����,������Dz��ô�ͳ�ı�����Ԫģ��,���ǽ���������˴����������ʵ��ù�����(���߲���Relu��Ϊ�����)
�� Training on Multiple GPUs ��GPUѵ��
��ʵ֤��120��ͼ��������������ѵ�����㹻��,������̫����˲����ڵ���GPU�Ͻ���ѵ����������ǽ�����ֲ�������GPU�ϡ����Dz��õ����з���������ÿ��GPU����һ��ĺ�(����Ԫ),����һ������ļ���:ֻ��ijЩ�ض��IJ��Ͻ���GPUͨ����
����ζ��,����,��3��ĺ˻Ὣ��2������к�ӳ����Ϊ���롣Ȼ��,��4��ĺ�ֻ��λ����ͬGPU�ϵĵ�3��ĺ�ӳ����Ϊ���롣����ģʽ��ѡ����һ��������֤����,�������������ȷ�ص���ͨ������,ֱ�����ļ������ڿɽ��ܵķ�Χ�ڡ�
�� Local Response Normalization �ֲ���Ӧ��һ��
ReLU�����������������,������Ҫͨ�������һ������ֹ���͡��������һЩѵ��������ReLU������������,��ô�Ǹ���Ԫ�Ͻ�����ѧϰ��Ȼ��,������Ȼ���ֽ������ľֲ���Ӧ��һ�������ڷ�����

�����и��Ĺ�ʽʱbatch normalization��ǰ����
��ž���˵relu��Ȼ��normalization������,�����ǻ��Ƕ���������normalization,����Ч�����á�
�� Overlapping Pooling �ص��ػ�
ϰ����,���ڳػ���Ԫ���ɵ������Dz��ص��ġ���CNN�в��õĴ�ͳ�ֲ��ػ�,�ػ������Dz��ص��ġ����粽����2,�ػ�������2,ÿ�γػ��������ص�������������2,�ػ�������3,������ȥ��������ص����ػ�����ʱ��ѵ��������ͨ���۲�����ص��ػ���ģ��,���������ѹ���ϡ�
�� Dropout ʧ�
�����������ļ���,������dropout��,������0.5�ĸ��ʶ�ÿ��������Ԫ�������Ϊ0����Щ��ʧ��ġ�����Ԫ���ٽ���ǰ�����Ҳ����뷴�������ÿ������ʱ,����������һ����ͬ�ļܹ�,�����мܹ�����Ȩ�ء�������������˸��ӵ���Ԫ����Ӧ,��Ϊһ����Ԫ���������ض���������Ԫ�Ĵ��ڡ����,��Ԫ��ǿ��ѧϰ��³��������,���������ͬ��������Ԫ������Ӽ����ʱ�����õġ�
������ǰ����ȫ���Ӳ�ʹ��ʧ����û��ʧ��,���ǵ�������ֳ������Ĺ���ϡ� ʧ�������ʹҪ�������ĵ�����������һ����
1.3 ѧϰϸ��
����ʹ������ݶ��½���ѵ�����ǵ�ģ��,������batch sizeΪ128,����Ϊ0.9,Ȩ��˥��Ϊ0.0005��Ȩ��˥����������һ��������:��������ģ�͵�ѵ����Ȩ��w�ĸ��¹�����:

1.4 ��
�������,��ӭ����ָ��!
| ���� | ���� |
|---|---|
| ReLU | ����ٶ� |
| GPUS | ����ٶ� |
| �ֲ���Ӧ��һ�� | ��С�����,����������� |
| �ص��ػ� | ��С�����,����������� |
| ������ | �������,����������� |
| Ȩ��˥�� | ��С�����,����������� |
2 ������
2.1 Feature map ά�ȼ���
����˵,��cnn��ÿ��������,���ݶ�������ά��ʽ���ڵġ������������������ά�������һ��,����ÿһ���Ϊһ��feature map��


2.2 ����ṹ����
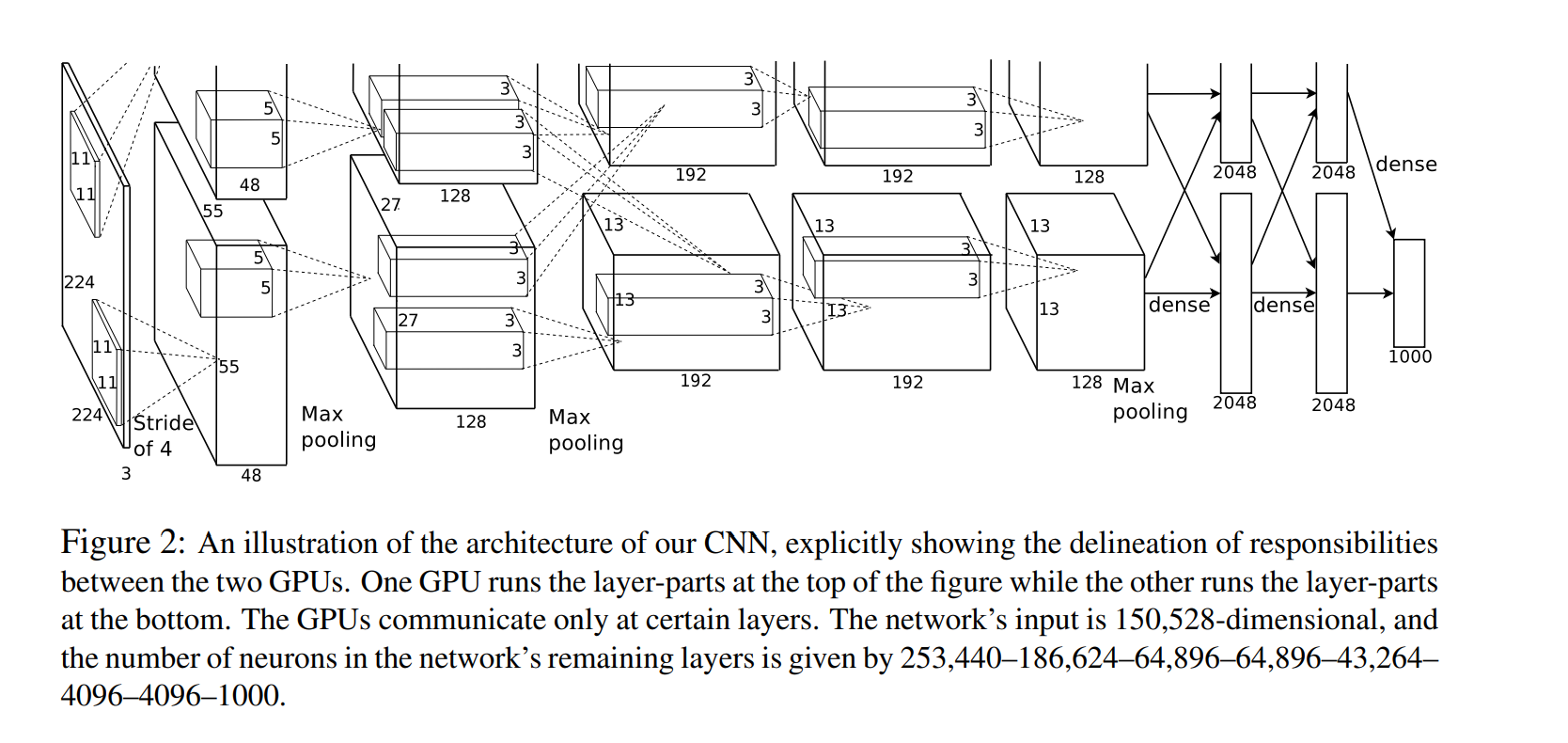
As a fun aside, if you read the actual paper it claims that the input images were 224��224, which is surely incorrect because (224 �C 11)/4 + 1 is quite clearly not an integer. This has confused many people in the history of ConvNets and little is known about what happened. My own best guess is that Alex used zero-padding of 3 extra pixels that he does not mention in the paper.
from CS231n blog
��������ļ��㹫ʽ,�������Ը���feature map�ߴ��������:
ֵ��ע�����:���ڱ��˵ĵ���ֻ��һ��GPU,�������еľ���������һ��GPU��ʵ�ֵġ�
�ҿ��˺ܶ������������,Ŀǰ��Ҳ��̫֪��˭˵������ȷ��,������������ݺʹ��벿�ֽ����ο���ͬʱ,��Ҳ������������ģ�����ѧϰ�ο���
- ������1�õ���feature map: (227 - 11 + 2 �� 0) �� 4 + 1 = 55
- �ص��ػ���õ���feature map:(55 - 3) �� 2 + 1 = 27
- ������2�õ���feature map: (27 - 5 + 2 �� 2) �� 1 + 1 = 27
- �ص��ػ���õ���feature map:(27 - 3) �� 2 + 1 = 13
- ������3�õ���feature map: (13 - 3 + 2 �� 1) �� 1 + 1 = 13
- ������4�õ���feature map: (13 - 3 + 2 �� 1) �� 1 + 1 = 13
- ������5�õ���feature map: (13 - 3 + 2 �� 1) �� 1 + 1 = 13
- �ص��ػ���õ���feature map:(13 - 3) �� 2 + 1 = 6
- Flattenչ��:6 �� 6 �� 128 �� 2 = 9216
- ȫ���Ӳ�1:9216 -> 4096
- ������:p = 0.5
- ȫ���Ӳ�2:4096 -> 4096
- ������:p = 0.5
- ȫ���Ӳ�3:4096 -> 1000
3 ��Ԫ�����Ͳ�������
3.1 ���㷽��
��Ԫ������ = feature map��С(�߿�) * feature map����(ά��)
������IJ��� = �����˴�С x �����˵�����+ ƫ������(�������ĺ�����)
ȫ���Ӳ�IJ������� = ��һ��ڵ�����(pooling֮���) x ��һ��ڵ����� + ƫ������(����һ��Ľڵ�����)
�ο��Ķ�:AlexNet�еIJ������� ��Ȩɾ!
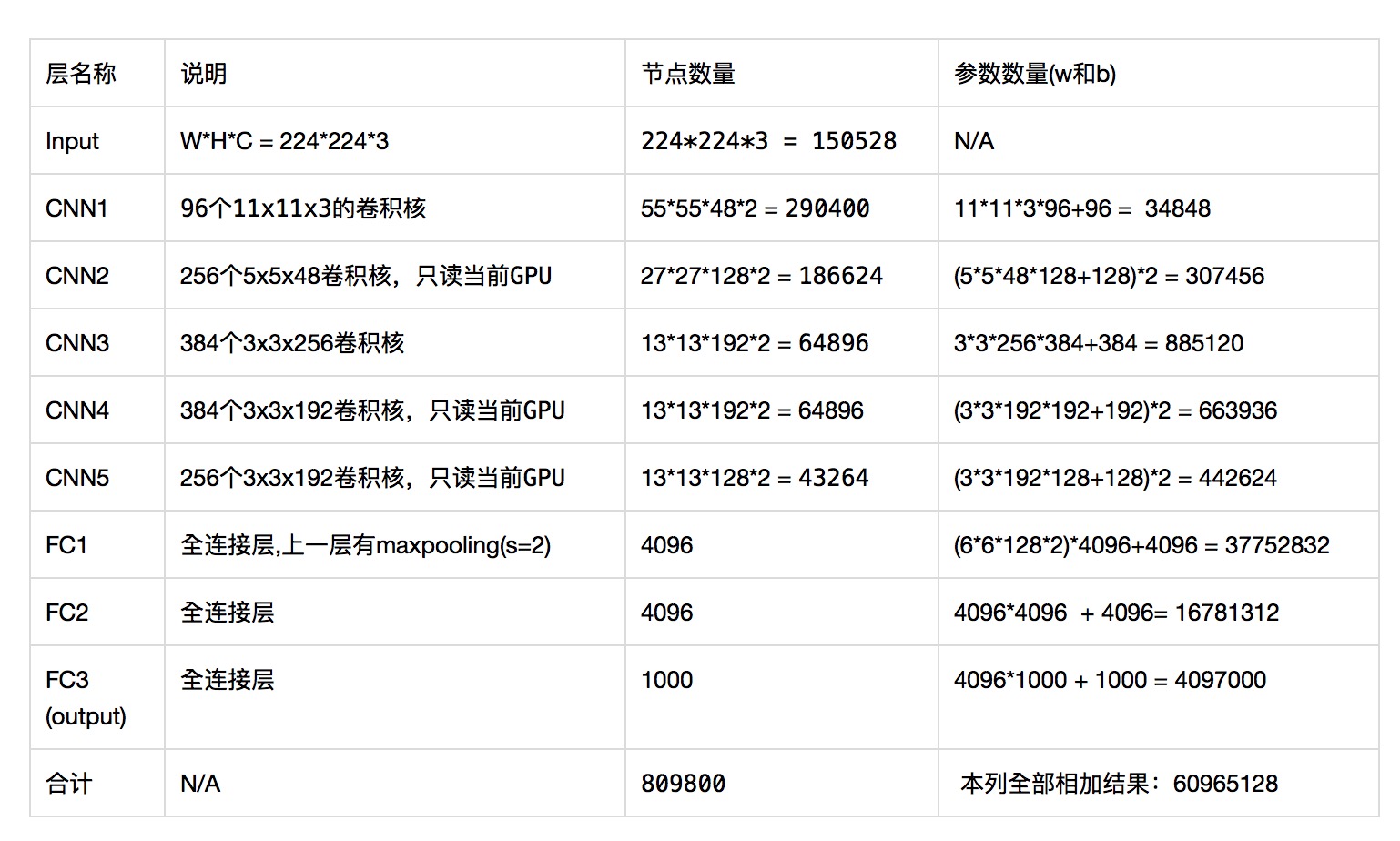
����������һ�¸���IJ������:
- �����:ͼƬ��С:����ͨ��(RGB)����ΪW * H * C = 224 x 224 x 3, ��150528���ء�
- ��1������, ������,ʹ��96�� 11 x 11 x 3�ľ�����,�ڵ�����Ϊ: 55(W) x 55(H) x 48(C ) x 2 = 290400�������������Ϊ: (11 * 11 * 3 * 96) + 96 = 34848
ע��,��������������GPU����,����GPU��48,������һ��������96�������ˡ���ij����������,�����ж��������:��һ����Ҫ���ٸ�feature map,�������Ҫ���ٸ������ˡ�
- ��2������, ������,ʹ��256�� 5 x 5 x 48�ľ�����,�ڵ�����Ϊ: 27(W) x 27(H) x 128(C ) x 2 = 186624�������������Ϊ: (5 * 5 * 48 * 128+128) * 2 = 307456�����"*2"����Ϊ�������ȷֲ�������GPU��,�ȼ��㵥��GPU�ϵIJ���,�ٳ���GPU����2����5 * 5 * 48 * 256 + 256 = 307456��
- ��3������, ������,ʹ��384�� 3 x 3 x 192�ľ�����,�ڵ�����Ϊ: 13(W) x 13(H) x 192(C ) x 2 = 64896�������������Ϊ: 3 * 3* 256 * 384 + 384 = 885120��
- ��4������, ������,ʹ��384�� 3 x 3 x 128�ľ�����,�ڵ�����Ϊ: 13(W) x 13(H) x 192(C ) x 2 = 64896�������������Ϊ: 3 * 3* 192 * 384 + 384 = 663936��
- ��5������, ������,ʹ��256�� 3 x 3 x 192�ľ�����,�ڵ�����Ϊ: 13(W) x 13(H) x 128(C ) x 2 = 43264�������������Ϊ: 3 * 3* 192 * 256 + 256 = 442624��
- ��6������,ȫ���Ӳ�,�ڵ�����Ϊ: 4096����������Ϊ:(6 * 6 * 128 * 2) * 4096 + 4096 = 37752832,
��ν6,�����ھ������ػ���,������13 * 13ת��Ϊ��6 *6�� (13 - 3)/ 2 + 1 = 6
- ��7������,ȫ���Ӳ�,�ڵ�����Ϊ: 4096����������Ϊ: 4096 * 4096 + 4096 = 16781312��
- ��8������,ȫ���Ӳ�,Ҳ��1000-way��softmax�����,�ڵ�����Ϊ: 1000����������Ϊ: 4096 * 1000 + 1000 = 4097000��
���Կ��������������ԶԶ����֮ǰ���о�����IJ�������֮�͡�Ҳ����˵AlexNet�IJ�����λ�ں����ȫ���Ӳ㡣
3.2 ��
�ܽ�: ��������ڵ�Ͳ����ļ���,���Լ�����Ϊ:�����Ŀ���ijһ����,�ҵ���Ӧ�����������㡣�ڵ������������feature map�ijߴ�(�����߿���ͨ����),��������Ϊ �����ľ����˴�С������������+��������������һ��ڵ�����(pooling֮���) x ��һ��ڵ����� + ƫ������(����һ��Ľڵ�����)��
������ⲿ�ֲ�����Ŀ���˽����,��QQ1257663033��
���,Ϊ�˷���鿴,����Ϊ��������,�������һ�и�����AlexNet�IJ���������
4 ����
4.1 �����ܹ�
ʹ��pytorch�AlexNet��ѵ�����������ݼ�
��Щ���ͺ���Ƶ�IJ�����Դ���Լ��Ĵ���,�������ĵ������,��Ϊ�����õ�������227 * 227,���ԶԳػ������Ĵ�С���˸ı䡣�����ں���Ҳ���������ֽ������յ�Ч��ͼ�����ֲ����
net:
import torch
from torch import nn
import torch.nn.functional as F
class MyAlexNet(nn.Module):
def __init__(self):
super(MyAlexNet, self).__init__()
self.c1 = nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=0)
self.ReLU = nn.ReLU()
self.s1 = nn.MaxPool2d(kernel_size=3, stride=2)
self.c2 = nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2)
self.s2 = nn.MaxPool2d(kernel_size=3, stride=2)
self.c3 = nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1)
self.c4 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1)
self.c5 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1)
self.s5 = nn.MaxPool2d(kernel_size=3, stride=2)
self.flatten = nn.Flatten()
self.f6 = nn.Linear(9216, 4096) # 256 * 6 * 6 = 9216
self.f7 = nn.Linear(4096, 4096)
self.f8 = nn.Linear(4096, 1000)
self.f9 = nn.Linear(1000, 10)
def forward(self, x):
x = self.ReLU(self.c1(x))
x = self.s1(x)
x = self.ReLU(self.c2(x))
x = self.s2(x)
x = self.ReLU(self.c3(x))
x = self.ReLU(self.c4(x))
x = self.ReLU(self.c5(x))
x = self.s5(x)
x = self.flatten(x)
x = self.f6(x)
x = F.dropout(x, p=0.5)
x = self.f7(x)
x = F.dropout(x, p=0.5)
x = self.f8(x)
x = F.dropout(x, p=0.5)
x = self.f9(x)
x = F.dropout(x, p=0.5)
return x
if __name__ == "__main__":
x = torch.rand([1, 3, 227, 227])
model = MyAlexNet()
print(model)
y = model(x)
4.2 API�ܹ�
���Ե���fashion_mnist���ݼ���
net:
import torch
from torch import nn
MyAlexNet = nn.Sequential(
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
nn.Linear(9216, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 1000),
nn.Dropout(p=0.5),
nn.Linear(1000, 10))
X = torch.randn(1, 1, 227, 227)
for layer in MyAlexNet:
X = layer(X)
print(layer.__class__.__name__, 'Output shape:\t', X.shape)
train_d2l:
import torch
from d2l import torch as d2l
from NetAPI import MyAlexNet
import matplotlib.pyplot as plt
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=227)
lr, num_epochs = 0.01, 10
d2l.train_ch6(MyAlexNet, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
���Խ��:
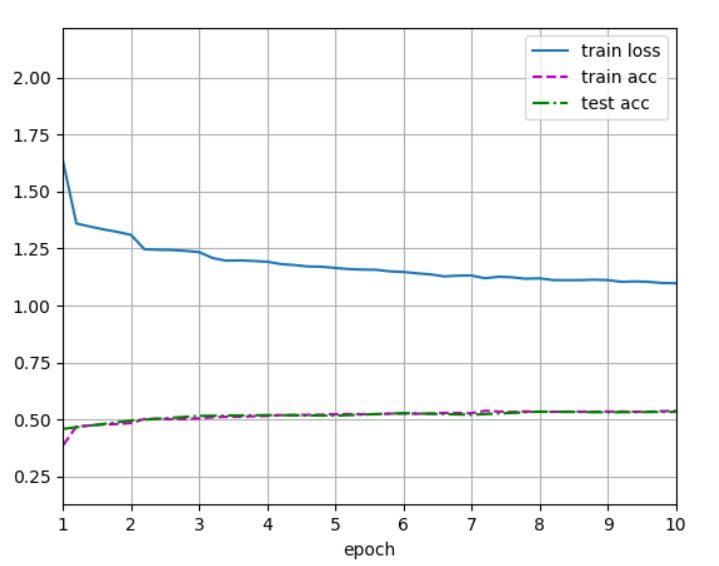
���˻�����������ͼ��Ϊ224 * 224������:
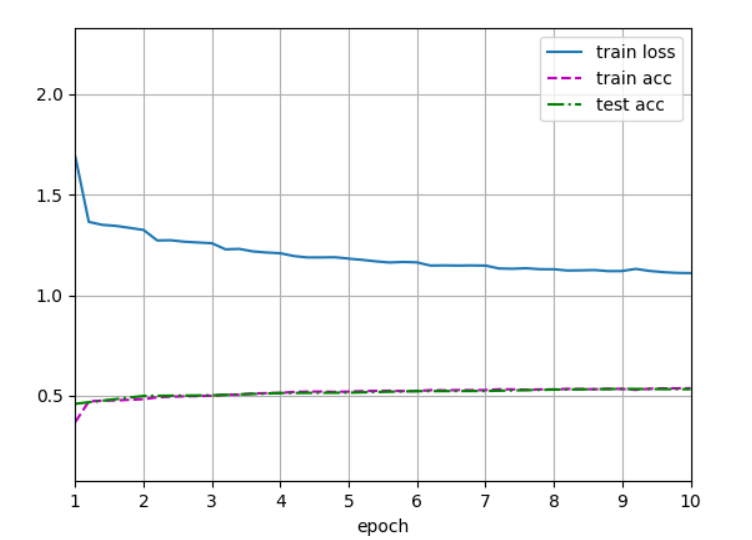
���Կ������ߵ�ѵ������������,��������,����Ҳû�б�Ҫȥ��������ͼ����224 * 224����227 * 227����
4.3 Pytroch�ٷ��ܹ�
from torchvision.models.alexnet import alexnet
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
5 �ܽ�
δ�������:��θı����ݼ���ͼƬ�ߴ�����Ӧ����Ĭ������ߴ�?