论文链接:BERTese: Learning to Speak to BERT - ACL Anthology
代码开源:暂无
1. 概要
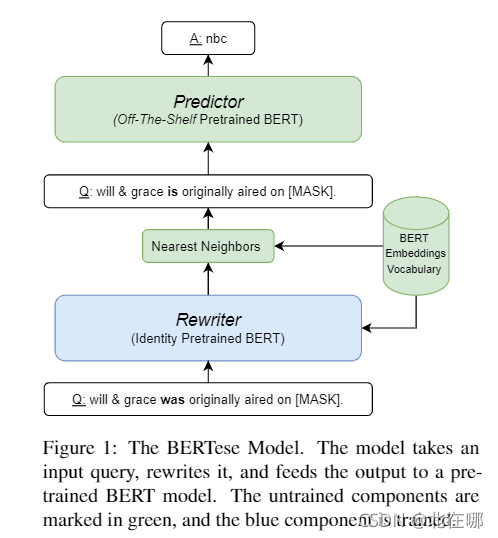
????????这篇论文和How Can We Know What Language Models Know?研究的问题一样,旨在找到更好的提示,从而提高从预训练模型中提取世界性知识的准确率。主要思想是训练一个模型,对原有的提示进行重写,然后再输入预训练模型中进行预测,大体框架如下:
2. 核心算法?
????????论文将重构提示的模型称为rewriter,需要测试的预训练模型称为predictor,已有的提示需要经过rewriter处理后再送入predictor中预测。为了保证rewriter生成的token合法以及有且只有一个[MASK],论文设计了两种loss函数:Valid Token Loss 和 Single [MASK] Loss。
Valid Token Loss:
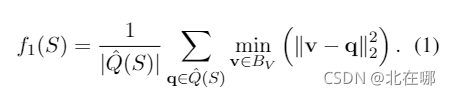
????????其中表示输入rewriter前的句子embedding,
则表示?rewriter输出的句子embedding,
是
中的token embedding,
是BERT词表中的词向量集合,
是属于
的词向量。该损失函数的目的是使rewriter输出的token embedding与它在BERT词向量中的最近邻更相似,从而使其更“合法”。
Single [MASK] Loss:
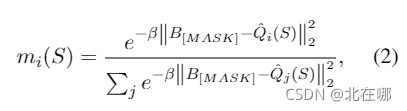
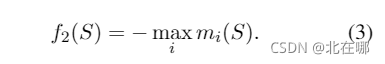
????????其中,?,
表示BERT的[MASK]词向量,
表示rewriter输出的第
个token embedding,
是可学习参数。论文将式(2)称为softmin函数,根据与[MASK]词向量的L2距离为各个toke分配概率,距离越小,token是[MASK]的概率越高。
? ? ? ? 上述两个loss只是辅助作用,最终损失需要在predictor输出后计算(计算与真实标签的交叉熵损失)。需要注意的一点是,rewriter将自己的输出送入predictor之前,需要将词向量映射为自然语言,具体做法是将[mask]概率最大的位置的token映射为[mask],其他位置的token embedding则根据它们在BERT词向量中的最近邻映射为相应的token。注意到此处有连续转离散即量化的操作,这样就无法通过梯度反向传播来更新参数,论文中采用了straight-through estimator(STE)来解决这个问题,即前向传播时,只计算选定的[mask]位置处的交叉熵损失,而反向传播时则利用以下式子进行求导,其中是真实标签,
是第
个位置输出的概率分布:?
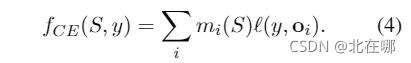
最终损失可表示为(?
是超参数):
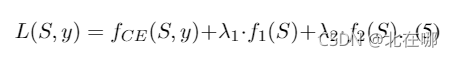
3. 实验结果
与微调BERT和LPAQA对比,可超越不使用集成的LPAQA4个百分点:

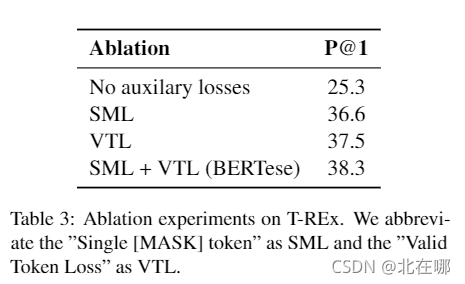
?消融实验表明,两个辅助函数可以起到很好的作用: