��ƪ������MAML�������汾,�����Meta-LSTM��˼��,����һ���µ�Ԫѧϰ�㷨�����������㷨���������ѧϰ�ʺ��Ż���������ȡ�µIJ���,����������SGD����,�������ȡ��Ϊ����Meta-SGD��
�ο��б�:
��Meta-SGD�����Ķ��ʼ�
��MAML��Meta-SGD
Meta-SGD: Learning to Learn Quickly for Few-Shot Learning
1 MAML
1.1 ���
����ɲο��ҵ���һƪMAML���Ľ��
1.2 ����
- �������µ�task�ϴﵽFast Adaptation��
- Ϊ�㷨�ṩһ�����Կ��������ĺ��ʳ�ʼ������,���������Ų���,��һ������Ҫ���⡣���Ų�����Learner��MAML����ij�ʼ����������,�������Ӷ��ﵽ���Ǹ�task��ʹ�� L o s s Loss Loss�ﵽ���Ż��IJ�����
1.3 ȱ��
- �ڸ��µ������,ѧϰ�ʡ�����������������Ƶ�,�������������������Ͻ��Ƶ��ݶ�ֵ��һ��ѧϰ�ʵĴ�С��Ҫ����;��������������Ȼ������ѵ�ѡ��
2 Meta-LSTM
2.1 ���
����ɲο��ҵ�2ƪ���Ľ��:
��L2L by gradient by gradient
��optimization as a model for few-shot learning
 ��������Meta-LSTMѧϰ�������Ż���ȥ�Ż���С����
L
o
s
s
Loss
Loss��ѧϰ���ߡ�
��������Meta-LSTMѧϰ�������Ż���ȥ�Ż���С����
L
o
s
s
Loss
Loss��ѧϰ���ߡ�
2.2 ����
��Ԫѧϰ�㷨ѧ����һ���Ż�����,MAMLѧϰ���˳�ʼ������,Meta-LSTMѧϰ����һ���Ż���ʽ������LSTM��ΪMeta-Learner,Ȼ��Meta-Learner��Ϊģ��,��Adamȥѵ��,Ҳ����˵��Meta-Learner����ģ��ȥѵ������ �� \theta ����Learner�IJ�����ͨ��LSTM������ڻ�ȡ: �� t = �� t ? 1 + g t \theta_t=\theta_{t-1} +g_t ��t?=��t?1?+gt?,�����Meta-LSTM��ѧϰ�����Ż��㷨,�����֮������LSTM����ʾ�����������ʽ�ӡ�
2.3 ȱ��
- ѵ���Ѷȴ�
- �����ٶ�����
3 Meta-SGD
3.1���
- Meta-SGD��MAML��Meta-LSTM�Ľ�ϰ汾,����˵��MAML��������,����MAMLֻ��Ԫѧϰ�����ʼ�������Ļ�����,����ȥԪѧϰ�Ż���ѧϰ�ʺ���������,���������dz��õ�SGD��Adam���Ż��㷨,���Ǵ������ֶ����ѧϰ�ʺ���������Ϊ��(����SGDΪ L o s s Loss Loss���ݶȷ���,������ǵ��Ż����ۻ���֪ʶ,�ݶȷ�����Ȼ�������ŵ���������,������Ȼ�ݶȷ��������ݶȷ��������½����ȵ�,��˭������˵����õ�,��ô����������Ϊȥѡ��һ���Ż�����,�������ü�����Լ�ȥѧϰѡ��һ���Ż��㷨)��
- ��MAMLһ��,Meta-Learner���Կ��ٽ�ѧϰ����һ���Ż�����(ѧϰ��+��������)��Ӧ��Learner��,������˵,ֻ��1��step�����Meta-SGDҲ�߱�
Fast-Adaptation�������� - Meta-SGD��Meta-LSTMһ��,������ѧϰ����һ���Ż���ʽ,����Meta-SGD������ѵ��;����ʵ��������:Meta-LSTM��Ҫ����LSTM,��Meta-SGDֻ��Ҫһ���ɸ��µľ���,����ѵ������Ҳ���졣
3.2 ����˼��
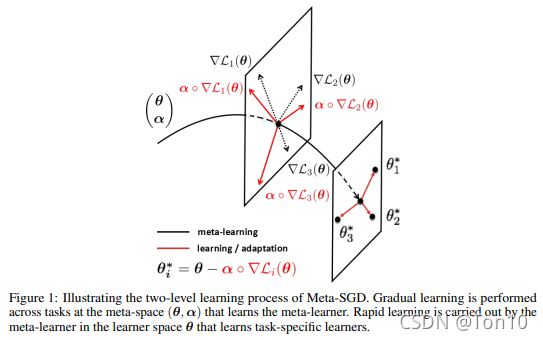
4. ����ͼ��ʾ,����MAML-SGD�ĺ���˼�������,էһ����MAML�����еĺ�����,�����������:��һ��������ƽ���ں�ɫ����MAML��,��ͬtask�ϵ���������,��ɫ��������Meta-SGD�ڲ�ͬtask�ϵ���������,���Կ�������Meta-SGD������һ��ѧϰ�ʾ���
��
\alpha
��,�������ͺ�ɫ�ݶȾ���Ĵ�С��һ����,�м��
��
\circ
����ʾ��Ԫ�����,���ַ�ʽʹ�ò�����һ���µ���������
5.
��
��
?
L
(
��
)
\alpha\circ\nabla\mathcal{L}(\theta)
����?L(��)�ij��Ⱦ��Ǹ��µIJ���,���һ������(����)������������ ����,
��
��
?
L
(
��
)
\alpha\circ\nabla\mathcal{L}(\theta)
����?L(��)�����ĸ��·����
?
L
(
��
)
\nabla\mathcal{L}(\theta)
?L(��)�����Dz�һ����,��Ϊ
��
\alpha
���Ǹ���ѧϰ�ľ���(����)��
����,
��
��
?
L
(
��
)
\alpha\circ\nabla\mathcal{L}(\theta)
����?L(��)�����ĸ��·����
?
L
(
��
)
\nabla\mathcal{L}(\theta)
?L(��)�����Dz�һ����,��Ϊ
��
\alpha
���Ǹ���ѧϰ�ľ���(����)��
- �м�ĺ�ɫ���ߴ�����Meta-Learner�IJ���,��MAML��ͬ����,Meta-SGD��2������ ( �� �� ) \begin{pmatrix}\theta\\\alpha\end{pmatrix} (����?)��
- �ڶ���������ƽ�����MAML����ѭ��,�õ�Learner�IJ��� �� i ? \theta_i^* ��i??,���¹�ʽΪ: �� i ? = �� ? �� �� ? L i ( �� ) L i ( �� ) = 1 �O T �O �� ( x , y ) �� T l ( f �� ( x ) , y ) (2) \theta_i^* = \theta - \alpha\circ\nabla\mathcal{L}_i(\theta)\\\mathcal{L}_i(\theta) = \frac{1}{|\mathcal{T}|}\sum_{(x,y)\in\mathcal{T}}l(f_\theta(x), y)\tag{2} ��i??=��?����?Li?(��)Li?(��)=�OT�O1?(x,y)��T��?l(f��?(x),y)(2)
3.3 ѵ������
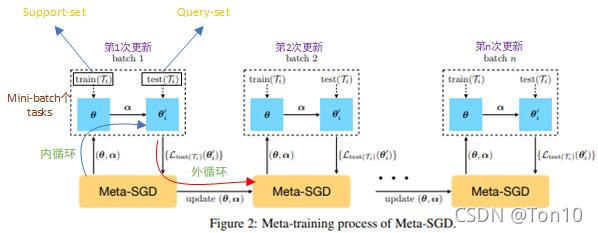
����ѵ������������ʾ:
- ��MAML����,Meta-SGDҲ��2���ѭ��,��һ����Ǻ���˼������,��Meta-Learner����������Ӧ��Learner��;�ڶ�����Meta-Learner�����ĸ��¡�
- ��һ��ѭ�������Լ��趨�Ĺ̶�ѧϰ��,������ѧϰ�ʾ��� �� \alpha ������,��Size�Ͳ�����Sizeһ��,ʹ�ð�Ԫ����һ�������ʧ����Support-set�ϵ���ʧ��
- �ڶ���ѭ������Ҫ��������IJ��� �� \theta ������,��Ҫȥ����ѧϰ�ʾ��� �� \alpha ��,���߸��·�ʽһ���������Ҹ����ڸ��ֵ�ʱ��ʹ�õ���FOMAML����������ʧ����Query-set�ϵ���ʧ��
- ����ÿһ����������ͬ��������ʵ��������ʱ��,��һ��task������ڸ���֮��,Ȼ����Query-set�ϼ��� L o s s Loss Loss���ݶ�;Ȼ��Եڶ���taskҲ�������IJ�����mini-batch��tasks����֮��,��ȡmini-batch�� L o s s Loss Loss�ݶȵ�ƽ��ֵ���ڸ��� ( �� �� ) \begin{pmatrix}\theta\\\alpha\end{pmatrix} (����?)����һ�ָ��½�����,���µ�Meta-Learner����ȥ���ڶ���,�����Ρ���n�θ��¡�
3.4 ���


��3.3��ѵ������������α�������������ʾ,��ʵ��MAML��α�������ơ���һ��ͼƬ��Meta-SGD�ڼලѧϰ�ϵ�Ӧ��;�ڶ���ͼƬ��Meta-SGD��RL�ϵ�Ӧ�á�����������Ҫ����
L
o
s
s
Loss
Loss�Ĺ��ɡ�task�Ĺ��ɲ�һ��,�����ͬС�졣����Ҫע���һ����,�����Ǽලѧϰ����RL,��ѭ����
L
o
s
s
Loss
Lossһ����Learner����
��
��
\theta'
������Query-set�ϵ���ʧ��
3.5 ʵ����
3.5.1 �ع�
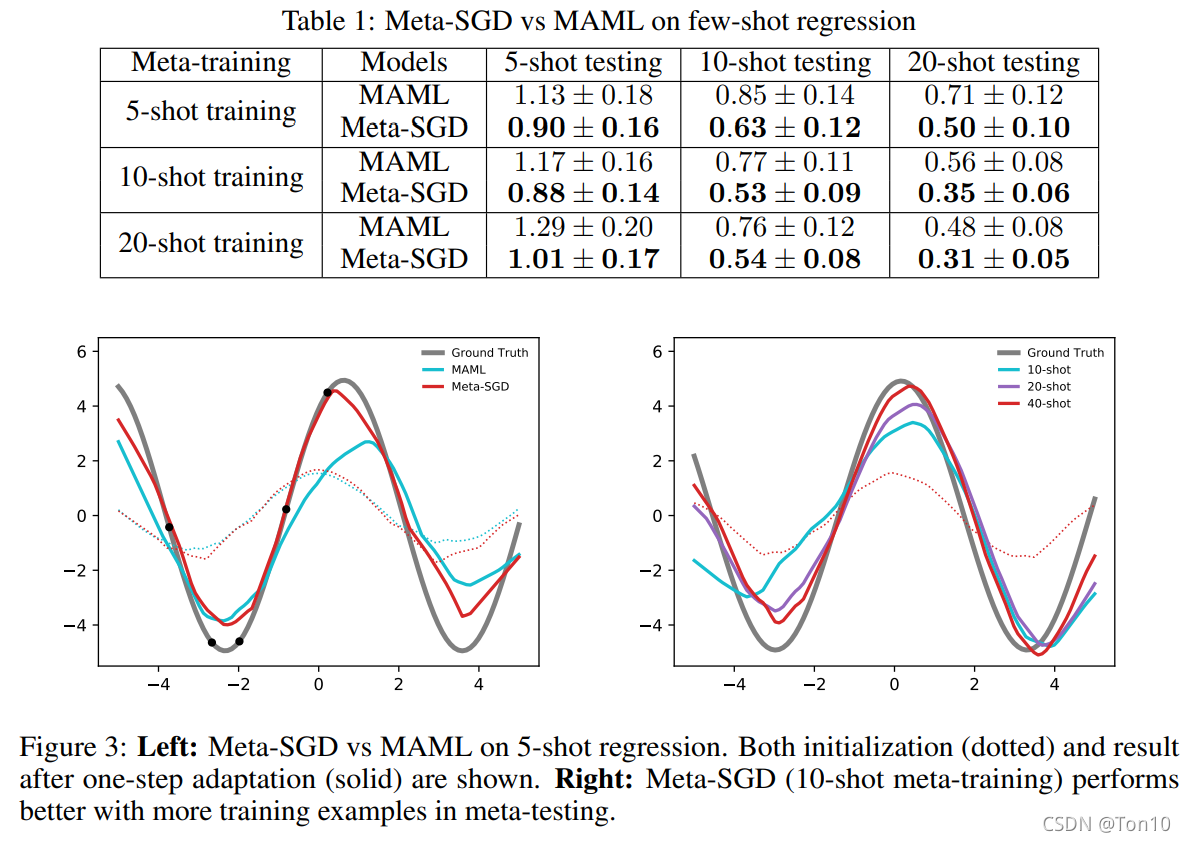
3.5.2 ����
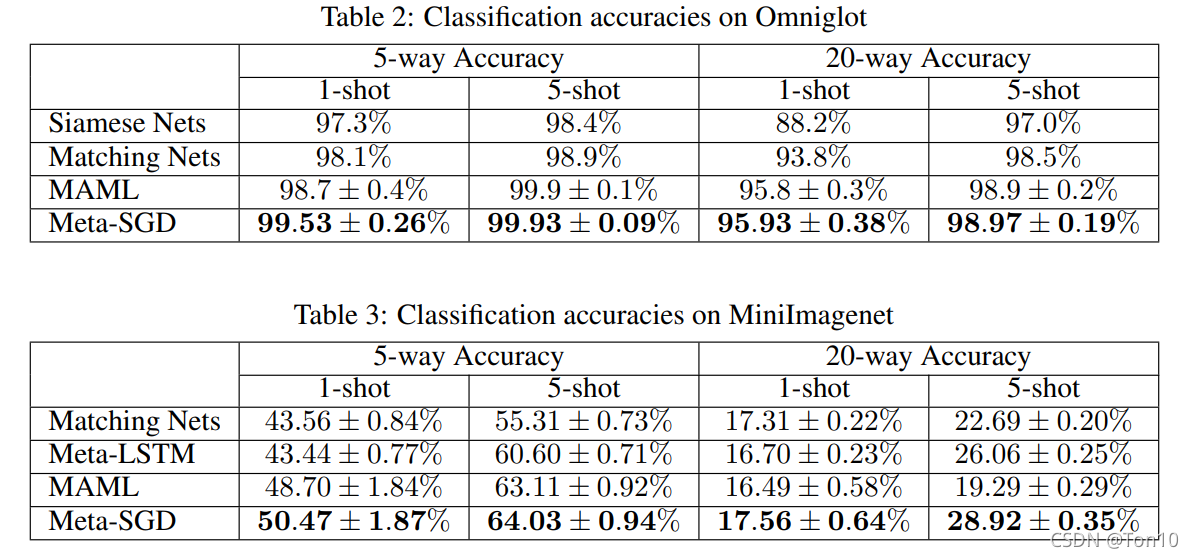
3.5.3 ǿ��ѧϰ
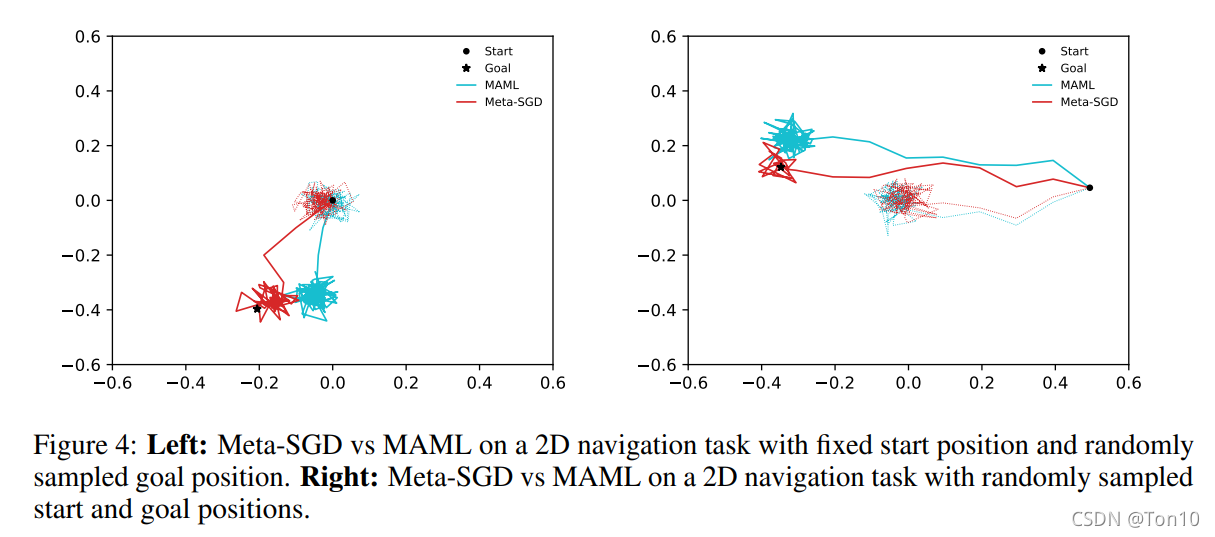
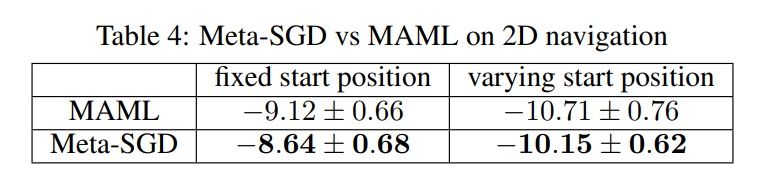
3.5.4 ʵ��С��
- �ܵ���˵,�������öԱ�ʵ����ͻ��Meta-SGD�ڼලѧϰ��ǿ��ѧϰ�϶���MAML��Meta-LSTM����Խ�ԡ�
- ֤����Meta-SGD�ڷ��ࡢ�ع顢RL�µĿ����Ըߡ�
4 �ܽ�
- MAML-SGD = MAML + MAML-LSTM��
- ����ķ�ʽ������Meta-SGD������MAML�Ļ�����,������һ����ѧϰ��ѧϰ�� �� \alpha ������(����),���ѧϰ�ʾ�������ѭ���к�ԭMAML���ݶȰ�Ԫ��������ı���·���;����ѭ���к�Meta-Learner����һ����¡�
- Meta-SGD���ŵ����ڼȿ���ѧϰ����ij�ʼ������,ΪLearner�ṩ����������ٶ�;��ζ���ÿһ��,������������ѧϰ�ʺ�task��ѧϰ�ʡ���������������˵Meta-SGDӵ��MAML��һ���ŵ㡣
- Meta-SGD�����Ż���ʽѵ���������ӿ�����ʵ�ַ��㡣
- Meta-SGD���÷�Χ��:���ࡢ�ع顢ǿ��ѧϰ��