�㷨��Դ����Patchmatch
patchmatch�㷨��Ϊ��ͼ��༭�������,ͨ���ҵ����Ե������ƥ���������������߽�����,�Ӷ��ﵽ��Ȼ��Ч�����㷨�Ĺؼ��ǿ���ͨ����������ҵ�һЩ�õIJ���ƥ��,��������ͼ���������,�����ܹ�������ƥ����ٴ�������Χ����
���ֱ�Ӳ���ö�ٵķ�ʽ������������,��Bͼ�Ĵ�СΪM,A��patch��������Ϊm,��ôһ��ƥ��ļ��㸴�Ӷ��� O ( M 2 m ) O(M^2m) O(M2m)
�㷨��������ʵ����:
1.��� O ( M 2 m ) O(M^2m) O(M2m)��ά��,һ���㷨����patch�ռ��Ϊά��(kd-tree,���㸴�Ӷ� O ( m M l o g M ) O(mMlogM) O(mMlogM)?),û�иı�ö�ٵı���,ֻ�Ǽӿ����ٶȡ�����ڴ�,ֱ����2D�ռ���Ѱ���ܵ�ƫ����������ṹ��ֱ��ƥ����Ӹ�Ч��
2.ͼ���������:��ÿ�����ض��������������ͼ���е���Ȼ�ṹ����������ķ�ʽ���������������Ч�ʡ�
3.��������:������������ǰ����,û��patch�����ȷƫ�ƵĿ����Էdz�С��
�㷨���
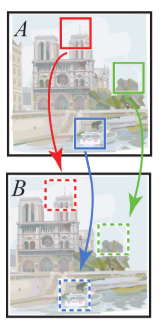
����ɫΪ����ɫ,A����ԭͼ��,���еľ��ο����������patch��,��ɫ����ɫ�ֱ�����patch������һ�����غ�����һ�����ء�Ҫ��patch_A,����Ҫ��Bͼ(Ҳ��ԭͼ)������һ������ʵ�patch��,���յõ�����patch_A��patch_B��ƫ������
PatchMatch �ĺ���˼��������ͼ���������(consistence), һ��ͼ��A��patch_A(��ɫ)������Patch��(��ɫ��ɫ)�������(B�еĺ�ɫ��ɫ��)���п��ܳ�����Patch_A�������(B�е���ɫ��)����,��������ͼ��������Դ������������ķ�Χ,ͨ�������ķ�ʽ��֤��������ܾ���������
�㷨����
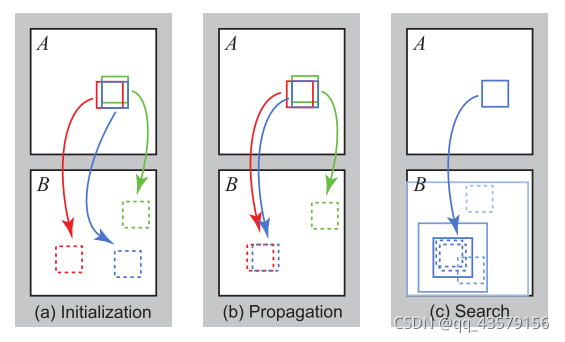
1.��ʼ��
ʹ��coarse-to-fine�����Ż�����,��ʼ����ֵ���Դ���һ�����ϲ����õ�����ʼ�����ƫ��ʹ�õķ����Ƕ����ش�ͼB��Χ�ھ��Ȳ�����
2.����
���������ԭͼA��ǰ���ؿ�patch_A(��ɫ)��Ӧ��B�е�patch_B_1,patch_A�Ϸ�(��ɫ)��Ӧ��B�е�patch_B_2,patch_A���(��ɫ)��Ӧ��B�е�patch_B_3������patch������patch_A���ƶ���ߵ�patch�顣(�������ε�����ż���ε���,�����ζ�Ӧ����,ż���ζ�Ӧ����)
3.����Ŷ�����
Ϊ�˱�������ֲ���ֵ,�ٶ�����������ɼ���patchλ����Ϊ��ѡpatch��,��С�ڵ�ǰpatch,����¡�
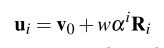
w�Ǵ��ڴ�С,R�Ǿ��ȷֲ�[-1,1]x[-1,1], �� \alpha ��?��ʼֵ��0.5,����i������С, w �� i > = 1 w\alpha^i>=1 w��i>=1
����Ŷ�����ԭͼA��,�Ե�ǰ����Ϊ���ĵ�,��ʼ�뾶����Ϊȫͼ,�ڴ������������Ѱpatch�鲢��patch_Aԭ����Ӧ��B�е�patch��Ա�,������������¶�Ӧ��ϵoffset,Ȼ�����µ�patch_BΪ����,�뾶��Сһ��,��������,ֱ���뾶��СΪ1,������ϡ�
PatchMatch Stereo _BMVC2011, ����:555
һ���㷨:ƽ����������ṹ��������,�Ӳ�Ϊ����(����cost volume)
PatchMatchStereo:Ѱ��ÿ��������ŵĿռ���Ƭ��

��Ҫ�ѵ�: �����п�������������ƽ�����ҵ�һ�����ص����� 3D ƽ��
�������: PatchMatch�㷨 (�ռ䴫��) + ��չ (ͼ����,ʱ�䴫��)
������,����ʹ����������ʹ����� PatchMatch ˼��,����һ��ƽ���ҵ��Լ����ϵ�����ڡ� ��ʹ�ô�����б����������ؾ��ȳ�Ϊ���ܡ�
�㷨ģ��
ģ��ǰ��,ͼ���Ѿ������˼��߽���
��������ͼ��ÿ������p,��Ѱ�Ҷ�Ӧ��ƽ��
f
p
f_p
fp?,һ���ҵ�,����p�����Ӳ�
d
p
d_p
dp??Ϊ:
d
p
=
a
f
p
p
x
+
b
f
p
p
y
+
c
f
p
d_p = a_{f_p}p_x+b_{f_p}p_y+c_{f_p}
dp?=afp??px?+bfp??py?+cfp??
����,
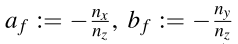
**Ѱ��ƽ��ʹ�ô��ڵ�ƥ�������С��**���� q ? ( a f q x + b f q y + c f ) q-(a_fq_x+b_fq_y+c_f) q?(af?qx?+bf?qy?+cf?)��q����һ��ͼ��ƥ���,���ָ����x�������Ӳ������
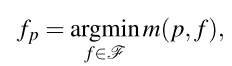
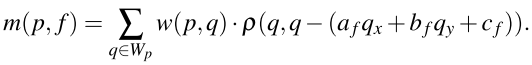
w ( p , q ) w(p,q) w(p,q)ͨ���鿴���ص���ɫ������ p �� q λ��ͬһƽ���ϵĿ�����
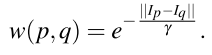
ƥ����ۺ����Ȱ�����ɫ�ְ����ݶȡ�
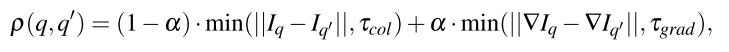
�㷨����
�㷨ǰ���������ʼ��֮��,ÿ������������һ�����ش���һ���ӽ���ȷƽ���ƽ��,֮��Ĵ������������Ӳ�ݵ���������������ء�
������������������������������������������������������������Patchmatch��˼�롣
�ڴ˻�����,�������������µĴ�������:��ͼ������ʱ�䴫���������һ��ƽ��ϸ���IJ���,�Ż�ƽ������Խӽ����ƽ�档
(1)�����ʼ��
��ƽ��������������ʼ��������ѡ������Ӳ� z 0 z_0 z0?(����ֵ,�����ӲΧ��),�õ����ƽ���ϵ�һ����P ( x 0 , y 0 , z 0 ) (x_0,y_0,z_0) (x0?,y0?,z0?)?,ƽ��ķ���������Ϊ���������
(2)����
1.�ռ䴫��
������p�ռ��ھ�q��ƽ�� f q f_q fq?�����p�Ƿ����� m ( p , f p ) m(p,f_p) m(p,fp?)��ֵ,����� m ( p , f q ) < m ( p , f p ) m(p,f_q)<m(p,f_p) m(p,fq?)<m(p,fp?),��ô f p : = f q f_p:=f_q fp?:=fq??��
ż���ε�������������ھ�,�����ε��������Һ����ھӡ�
2.��ͼ����
���������Ӳ�ͼ֮���ǿ�����,����ƥ����ƽ���Ƿ�����mֵ,����� m ( p , f p �� ) < m ( p , f p ) m(p,f_{p'})<m(p,f_p) m(p,fp��?)<m(p,fp?),��ô f p : = f p �� f_p:=f_{p'} fp?:=fp��?
3.ʱ�䴫��
ǰ��֡����ͬ���괦���ܻ�������Ƶ�ƽ�档ͬ��,��� m ( p , f p �� ) < m ( p , f p ) m(p,f_{p'})<m(p,f_p) m(p,fp��?)<m(p,fp?),��ô f p : = f p �� f_p:=f_{p'} fp?:=fp��?
4.ƽ���Ż�
�Ż�ƽ������Խ�һ����Сmֵ��
Gipuma_ICCV2015
��Ҫ����:
1.����Ч��:��PatchMatch���,�����һ���µ���ɢ����,���ʺ��ڶ��GPU,���ٶȸ��졣
2.���ȷ�Ժ�³����:��PatchMatch Stereo��˫Ŀ��չ���˶���ͼƥ��,PatchMatchStereo����ֱ�Ӽ����������ķ���ƽ��,�����˶Լ�У����
�������������Ȼ��Ҫ�ο�ͼ����ȷ������IJ���,����������ȼ���ÿ��ͼ�����ͼ,Ȼ���������ںϡ������������ȼ��㷽�澡���������˹���һ����,������ͼ���ںϽ���Ҫ�����IJ������輴�ɡ�
�㷨����Ĵ�������:��������ģʽ�����ػ���Ϊ��ɫ��ͺ�ɫ��,��ͬʱ���θ������к�ɫ�ͺ�ɫ,�������ڵ��ѡ��ʽת����,ʹ����20���ֲ����ڵ����ڴ�����

��������:(a)�����к�ɫ���ز��и�����Ⱥͷ���,ʹ�ú�ɫ������Ϊ��ѡ,��֮��Ȼ�� (b) ���Ծֲ������ƽ��(���)��Ϊ���¸�������(��ɫ)�ĺ�ѡ�ߡ� ? �ٶ����õ��ķ���,��ʹ��ͼ�����ڲ������ⲿ���ء�
��ƥ����ۼ��㷽��,����ʹ��RGB������������С,��˴��ۼ���任Ϊ�˻ҶȲ���,ͬʱΪ�˽�һ���ӿ�����ٶ�,��ȡ��Sparse Census Transform��˼��,Census Transform����������ʾ:

����ͼ��չ:
�����Ӳ��Ǽ���У����ͼ�������е�,����ڶ���ͼ��˵�dz�����Ȼ,��������ŷ�ϳ����ռ���ʹ��patch���в�����
�ŵ�:
1.�����˼���У��
2.���Բ���3D�����ռ��ڵ��ܼ����淨��,�����ڸĽ������ĵ����ںϡ�
3.�������ݴ���ֱ�ӴӶ���ͼ�ۺ϶�����
������ʽ:
������һ��
X
=
[
X
,
Y
,
Z
]
T
X=[X,Y,Z]^T
X=[X,Y,Z]T,������
n
T
X
=
?
d
n^TX=-d
nTX=?d,����
Z
=
?
d
c
[
x
?
u
,
��
(
y
?
v
)
,
c
]
?
n
,
K
=
[
c
0
u
0
c
/
��
v
0
0
1
]
Z=\frac{-dc}{[x-u,\alpha (y-v),c] \cdot n}, K=\begin{bmatrix} c&0&u\\0&c/\alpha&v\\0&0&1 \end{bmatrix}
Z=[x?u,��(y?v),c]?n?dc?,K=???c00?0c/��0?uv1????
ͬʱ,ƽ�浥Ӧ�����Ƶ�����:
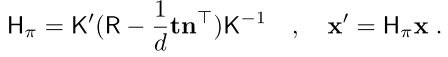
�����Ƶ�:https://blog.csdn.net/qq_25638133/article/details/88353125
�㷨���µ�:
1.��ʼ��:Ϊ�˲����ɼ������ھ��ȷֲ������������,��������:
q
1
,
q
2
q_1,q_2
q1?,q2?���Ծ��ȷֲ�
(
?
1
,
1
)
(-1,1)
(?1,1)�ڵ��������,����
S
=
q
1
2
+
q
2
2
<
1
S=q_1^2+q_2^2<1
S=q12?+q22?<1,��ô��������ʾΪ
n
=
[
1
?
2
S
,
2
q
1
1
?
S
,
2
q
2
1
?
S
]
T
n=[1-2S,2q_1\sqrt{1-S},2q_2\sqrt{1-S}]^T
n=[1?2S,2q1?1?S?,2q2?1?S?]T
�������ܲ������ȷֲ��������ϵĵ�λ������ ������������ϵ�ͶӰ
[
u
,
v
,
c
]
T
n
>
0
[u,v,c]^Tn>0
[u,v,c]Tn>0 ,������ n ��ת��
ͬʱ,������Ϊ��ȷֱ����Ǹ������Ե�:��������Ȼ����ͼ��ռ��в�����,��˲����ľ������ӲΧ�ڽ��ƺ㶨,����������dzɷ��ȵġ��������ӿ��ܵ��ӲΧ���ȵij�ȡ������������ת��Ϊ���ֵ��(�����ṩ���ܼ��IJ������,ͼ���в�����ܻ��������;Զ���IJ�����ȸ���ϡ��,��Ϊ���Ӳ��첢����)������ͬ����ԭ��,ƽ��ϸ������������������ҲӦ������ȳ����ȡ�
2.����ͼ���۾ۺ�:
(1)������ͼѡȡ,ѡ��۲�Ƕ� �� m i n < �� < �� m a x \alpha_{min}<\alpha<\alpha_{max} ��min?<��<��max?, �� \alpha ��̫С,���ǻ�����̫С,��Ȳ�ȷ��������; �� \alpha ��? ̫��,?���ڽϴ����Ť��,���ɿ��Ƚ���ۡ�
(2)���۾ۺ�:���ֻ�ǼľۺϵĻ�,��ʹ����ȷ�ؽ���patch,��������ڵ�����Ҳʹ��cost����,�Ӷ�����������ģ����Ϊ�˽���������,Kang��Handling occlusions in dense multi-view stereo�����˵�����,�������ٴ���һ���ͼ������ؽ�patch�����ǿɼ���,ֻѡȡN��cost�е���õ�50%��
���İѹ̶���50%��ɲ���K,Kȷ����Ҫ���ǵ�cost��Ŀ��K��ѡ��ȡ���ڲ�ͬ������:�ϸߵ�Kֵ���������ಢ����ȷ��,��Ҳ���ڰ�����ƥ��ķ���,����Ӱ��³���ԡ����ݾ�����˵,���ڱȽ�ϡ������ݼ�������Խϵ͵�Kֵ���ֻ����,��������K=3
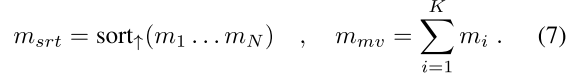
ACMH_Arxiv2018
������PatchMatchStereo֮��,���÷ǶԳ����̴�������,���Ը��ݵ�ǰ�ھӼ�������Ŷ�����Ӧ��ʹ��Ч�����һ����չ;Ϊ�˸��þۺ����Զ��ͼ����Ӿ���Ϣ,Ϊÿ�������ṩ�˶����������ͼѡ��,�����˻��ڶ����������ijɱ��������Ƚ��ƶϳ����ʵľۺ��Ӽ����С�
DeepPruner_ICCV2019
Ŀ��:�����ӿ��㷨����ʱ��,�Ա�ʵ��ʵʱ����������������������������������������������������������KITTI��Scene-Flow 62ms
����:������һ�����ֵ�PatchMatchģ��,���������������������ý���������cost volume���㡣�������ֱ�ʾ��ѧϰÿ������Ҫ���ķ�Χ,ͨ����С�����ռ䲢��Ч����������Ϣ,�ܹ���Ч�ؼ������Ȼ����ijɱ�����

����һ������ͼ��,����������ȡ��ȶ�߶������� Ȼ���������ÿ� PatchMatch ������ÿ�����ص�һС�����Ӳ�,���������ŷ�ΧԤ������һ������ռ䡣 ���������Ӳ�������Χ�ڲ������������� [8, 15] ��ͬ,����ֻ����С��������Χ�ھۺϳɱ��� ���,���������������������Ż����������
�㷨���
patchmatch�����Ӳ�ͼ+���ŷ�Χ������С�ӲΧ+3D costvolume����
-
������ȡ
����һ��ͼ�� { x 0 , x 1 } \{x_0,x_1\} {x0?,x1?},���һ���ƥ�����õ�������� { f 0 , f 1 } \{f_0,f_1\} {f0?,f1?}?
ͨ��SPP������ȡ������
-
��patchmatch��֦ģ��
һ����������:
���Ӳ�����:����ÿ������,��Ԥ��/Ԥ���������ռ��ϵľ��ȷֲ��������k���Ӳ�ֵ��
������:����Ԥ�ȶ�����˲�ģʽ,�������ؼ�����������
������:����ÿ������i,ͨ�������ڻ������ѡ����j��ƥ�����,ÿ�����ص����k���Ӳ�ֵ������һ����ʹ��
s i , j = < f 0 ( i ) , f 1 ( i + d i , j ) > s_{i,j}=<f_0(i),f_1(i+d_{i,j})> si,j?=<f0?(i),f1?(i+di,j?)>
������Ƽܹ��ڵײ���һ�����Ӳ�����,Ȼ��ѭ������������������,��������ʱ��argmax���Ӳ���,��˰����滻Ϊsoft�汾:
d i ^ = �� j s i , j ? d i , j �� j s i , j \hat{d_i}=\frac{\sum_js_{i,j}\cdot d_{i,j}}{\sum_js_{i,j}} di?^?=��j?si,j?��j?si,j??di,j??

����ͼ�������˿���֦��ģ�������,��ʵ����,���Dz�����ÿ�����Ӷ�פ�����������Ӳ�ռ���,���ǽ������ռ仮��Ϊ k �����,��ǿ�Ƶ� i ������λ�ڵ� i ������С� �Ᵽ֤�����ӵĶ�����,������������Ժ�����ȷ��
���ŷ�ΧԤ��:
���������ض���,��ʼ�������ռ�ʱ��ͬ��,���Ƕ���ÿһ�����ض���,�����ܵ��Ӳ�ֵͨ���ں�С��һ����Χ�ڡ�ʹ�ô�PatchMatch�ι��Ƶ�С�Ӳ��Ӽ�,�������㹻����Ϣ��������ʵ�Ӳ����ڵķ�Χ��
����:ʹ�����ŷ�ΧԤ���������ÿ�����ص������ռ䡣��������encoder-decoder�ṹ,�������Կ�PatchMatch��ϡ���Ӳ���ơ���ͼ��Ť������ͼ(����ϡ���Ӳ����Ť��)��Ϊ����,��Ϊÿ������i������ŷ�Χ R i = [ l i , u i ] R_i=[l_i,u_i] Ri?=[li?,ui?]?.
�ڶ���PatchMatch:
����ط��ϸ���˵��û����Patch match ������,ֻ�Ǹ���֮ǰ����������ŷ�Χ������,Ϊÿһ��pixel,���������о��ȵ�ȡ��ѡ��(uniform sampler)��
��������Ϊ,��һ��patch match �ĵ�,�ܶ�����ŷ�Χ֮��,��Щ������������Ӳ���ʵ�ο����岻����ô�����ŷ�Χ֮�ڵĵ��Ƚ���,�����ع�ĵ�ͺ����ˡ��������ʱ����Ҫ�����ŷ�Χ��,���²���,���ͨ��soft argmin���ع��Ӳ
-
���۾ۺϺ��Ż�
���۾ۺ�:
right_feature_map, left_feature_map = self.spatial_transformer(left_input,right_input, disparity_samples)
disparity_samples = disparity_samples.unsqueeze(1).float()
cost_volume = torch.cat((left_feature_map, right_feature_map, disparity_samples), dim=1)
ֱ�Ӱ�����ͼ���Ӳ�����concatenate��һ����Ϊcostvolume, B �� R �� H �� W B\times R \times H \times W B��R��H��W,����RΪ�Ӳ�������Ŀ
�Ż�:
ͨ��FCN����Ч��,��������˵ͼ�������Ϣ�Լ�С��������߽߱紦���Ӳ�ͼ������
Planar Prior Assisted PatchMatch Multi-View Stereo _AAAI2020
����ƽ��ģ�ͺ�PatchMatch,�����һ��ƽ�����鸨����PatchMatch-MVS,���ø���ͼģ�Ͱ�ƽ��ģ��Ƕ�뵽PatchMatchMVS�С�
1.ƽ��������Ϣ:
��ͳ��PatchMatch����ͼ���巽����,�����ڱ�Ե�ͽ�����б�������ϡ����ŵĶ�Ӧ��ϵ,������Щ��Ӧ��ϵ������3Dģ�͵�mesh��ʾ�еĶ����غ�,����ζ����Щϡ����ŵĶ�Ӧ��ϵ��������������3Dģ�͵ĹǼܡ�����>����Щ��Ӧ��ϵ�������ǻ��Ӷ��õ�ƽ��ģ�͡�
2.ƽ�����鸨���Ķ���ͼ�ۺ�ƥ�����
���ø���ͼģ��ͬʱģ����һ���Ժ�ƽ�������,ƽ�����������Ԥ����ȵķ�Χ,���һ���Է�Ӧ���������������ȱ仯��
3.����ɿ���ƽ�������Ӱ��
ǿ��ִ�ж���ͼ����һ���Ծ����������ȹ��ơ�
�㷨���
�㷨����:
I = { I m �O m = 1... N } I = \{ I_m|m=1...N\} I={Im?�Om=1...N}?, ���ȡΪ�ο�ͼ I r e f I_{ref} Iref??,��ô��Ӧ��Դͼ�� I s r c = { I j �O ( I j �� I ) �� ( I j =? I r e f ) } I_{src}=\{I_j|(I_j\in I)\cap (I_j\not= I_{ref})\} Isrc?={Ij?�O(Ij?��I)��(Ij?��?=Iref?)}
�ο�ͼ�� I r e f I_{ref} Iref?��ϡ����Ŷ�Ӧ��ϵ��
�㷨����:
1.�ɴ�ͳ��PatchMatchMVS��������ֵ����ϡ���Ӧ,������Щ��Ӧ��ϵ�������ǻ��Ӷ��õ�ƽ��ģ�͡�
2.ͨ����������ͼģ��ͬ������ǰ��õ�ƽ��ģ�ͺ��һ����,ͨ�������µ�ƥ�������ɶԵ����������������ȹ��ơ�
 (��e�ɿ���,�����ƽ�������������������ѹ��Ƽ���һ�¡�)
(��e�ɿ���,�����ƽ�������������������ѹ��Ƽ���һ�¡�)
1.ƽ��ģ����
ϡ���ؽ������Ȼ��ʧ�˵������������ȹ��ƽ��,���ǿ��Ա�������������������3Dģ�͡�������ȶ�ϡ���ؽ�������������ܷ�,����Ӧ���ɲ�ͬ��С�������λ�Ԫ,����������������������λ�Ԫ��Խ�С,��˿��Ա�����ƽ������Ľṹ;�����ڵ���������,�����λ�Ԫ�ᾡ���ܴ������ÿ��ŵ�ϡ���ؽ���ϵ����Ԫ����Ⱥͷ�������ɶ����������������õ���
2.ƽ������Эͬ
ƽ������������������������������αӰ,�ر����ڱ߽紦����
(����)
PatchMatchNet

�㷨����
1.��ʼ���;ֲ��Ŷ�
�ڵ�һ����,����Ԥ�������ȷ�Χ [ d m i n , d m a x ] [d_{min},d_{max}] [dmin?,dmax?],������ȷ�Χ�ڶ�ÿ�����ص� D f D_f Df?��ȼ�����в���,��Ӧͼ��ռ��еľ��Ȳ�����Ϊ�˾���ȷ�����ȸ�����ȷ�Χ,��(��)��Χ����Ϊ D f D_f Df??������,��ȷ��ÿ�����䶼��һ�����踲�ǡ�
�����������������������������������������������ڸõ��Ӧ�ļ����Ͻ��о��Ȳ���
�ڽ������ĵ�k����ִ�оֲ��Ŷ�,�ڹ�һ���ķ���ȷ�Χ R k R_k Rk?��ÿ�����ز��� N k N_k Nk?������,����$ R_k ? �� �� �� �� �� �� �� �� �� �� �� С �� ?�����Ž����Ӷ���С�� ?����������������������С�� R_k $?���м�ֵ����һ�θõ�����ֵ�ϲ����������PatchMatch�ṩ�˸���ļ��衣Χ����ǰ���ƽ��в���Ҳ����ϸ���ֲ���������д���ľ�����
2.����Ӧ����
���ͼ�Ŀռ�һ���Խ�������ͬһ���������������֮�䡣��˴�ͬһ�������ռ���ȼ���������PatchMatch�������������ṩ��ȷ�����ͼ��ͨ��λ�ƹ��Ƶķ�ʽ������ K p K_p Kp?����ȴ�ѡֵ��
�ۺ�12����,��������ȴ�ѡֵΪΪ D f + K p D_f+K_p Df?+Kp?��
3.��ӳ��
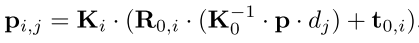
4.ƥ����ۼ���
��������ͼ��source Images��Ϣ�����Ӧ����ȼ������ϵ�reference Image �С�
��������������������������������������������ͨ����������Լ���ÿ������ijɱ�,�ڴ˻�����ͨ����ͼȨ�ؼ��Ծۺϡ�
F 0 ( p ) , F i ( p i , j ) �� R c F_0(p),F_i(p_{i,j}) \in R^c F0?(p),Fi?(pi,j?)��Rc�ֱ�����˲ο�����ͼ��Դ����ͼ�ϵĵ�p,������ͨ��ƽ������ΪG��,��ô��G��������� S i ( p , j ) g �� R S_i(p,j)^g \in R Si?(p,j)g��R�Ķ���ʽ����
S i ( p , j ) g = G / C < F 0 ( p ) , F i ( p i , j ) g > S_i(p,j)^g = G/C<F_0(p),F_i(p_{i,j})^g> Si?(p,j)g=G/C<F0?(p),Fi?(pi,j?)g> , ����<>�����ڻ�,��� S i �� R W ? H ? D ? G S_i \in R^{W*H*D*G} Si?��RW?H?D?G
�ڻ�ȡ���������֮��,��Ҫ����õ����ؼ���ͼȨ�� ( w i ( p ) ) i = 1 N ? 1 (w_i(p))_{i=1}^{N-1} (wi?(p))i=1N?1?��
�������� w i ( p ) w_i(p) wi?(p)����ʾ����p��Դͼ���еĿɼ���,Ȩ�ؼ���һ�β��ұ��̶ֹ�,�ڸ���ϸ�Ľ��ϲ�������������ͼȨ��������1x1x1�ں˺�sigmoid������
3D���������,�����ʼ���ƶ� S i S_i Si?,���0��1�����ֺ���ȼ���Ӷ����� P i �� R W ? H ? D P_i \in R^{W*H*D} Pi?��RW?H?D��
w i ( p ) = m a x ( P i ( p , j ) �O j = 0 , 1 , . . . , D ? 1 ) w_i(p)=max(P_i(p,j)|j=0,1,...,D-1) wi?(p)=max(Pi?(p,j)�Oj=0,1,...,D?1)
���� P i ( p , j ) P_i(p, j) Pi?(p,j) ֱ�۵ر�ʾ p ���� j ����ȼ��������Ƿ�Χ�Ŀɼ������Ŷ�
����ÿ�������Եļ��㹫ʽ������ʾ��
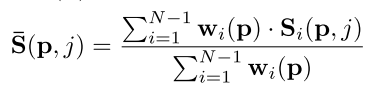
5.����Ӧ�ռ���۾ۺ�
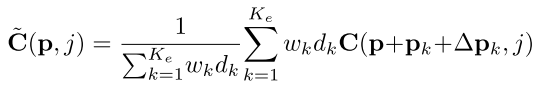
p k p_k pk?������p��Χ�����ڵ�, �� p k \Delta p_k ��pk?����������2D CNN�����ο�����ͼ F 0 F_0 F0?�ڸõ�ѧ����ƫ��