参考论文:
[1] Wang Y , Fang W , Ding Y , et al. Computation offloading optimization for UAV-assisted mobile edge computing: a deep deterministic policy gradient approach[J]. Wireless Networks, 2021:1-16.doi:https://doi.org/10.1007/s11276-021-02632-z
代码:
fangvv/UAV-DDPG
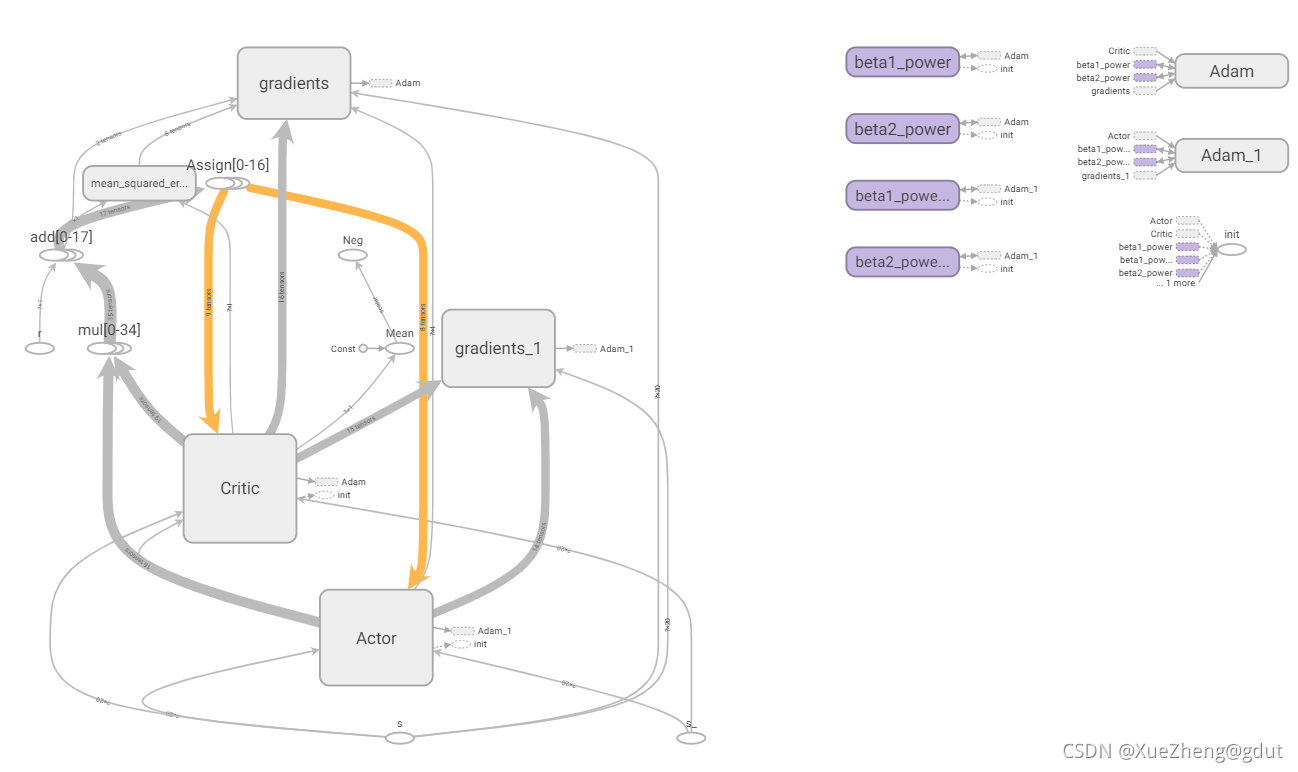
结合论文以及开源代码对DDPG算法进行一个详细讲解,这里运行好代码(这里代码也是根据网上改的,DDPG算法已经是固定的了,创新只能在建模方面创新,环境类需要自己写,DDPG算法直接套用即可),使用tensorboard将张量流图导出,这是一个非常好的可视化工具,帮助理清代码,该代码的tensorboard图如下,下面都会基于该图进行详细讲解。(需要具备强化学习理论知识以及对tensorflow、python有一定了解,上一篇博客有免费强化学习系统学习路线,学习后再来看此博客会比较友好)
贡献
考虑时隙无人机辅助MEC系统中时变信道状态,联合优化用户调度、无人机移动和资源分配,将非凸计算卸载问题制定为马尔科夫决策过程(MDP)问题,最小化初始时延。
考虑MDP模型,系统状态的复杂度非常高,计算卸载的决策需要支持连续动作空间,采用DDPG算法求解该问题,使用Actor网络做出动作,使用Critic网络近似动作价值函数Q给动作打分,获得最优策略。
DDPG框架

代码详解
定义DDPG类,初始化,Session 是 Tensorflow 为了控制,和输出文件的执行的语句,运行 session.run() 可以获得你要得知的运算结果, 或者是你所要运算的部分,后面会使用 session.run() 进行变量初始化操作。placeholder 是 Tensorflow 中的占位符,暂时储存变量,可以理解为一个空壳,传入值才进行计算,未传入则空壳不执行任何计算。
def __init__(self, a_dim, s_dim, a_bound):
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32) # memory里存放当前和下一个state,动作和奖励
self.pointer = 0
self.sess = tf.Session()
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
self.S = tf.placeholder(tf.float32, [None, s_dim], 's') # 输入
self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
self.R = tf.placeholder(tf.float32, [None, 1], 'r')
tf.variable_scope 个人理解,主要是为了共享变量,取不同的名字就可以共享相同的变量了,DDPG一共是四个神经网络,Actor中两个神经网络的结构是相同的,Critic中两个神经网络的结构也是相同的,只是参数不同而已,分别写出一个神经网络的结构后,这些变量可以通过命名不同来实现共享。下面的代码可以看出,Actor有两个网络,一个是主网络eval,一个是目标网络target,eval网络直接输出动作a,target网络输出动作a_,都是使用函数_build_a建立的,通过命名不同实现变量共享。同理Critic网络也是,分别是eval和target网络,输出是两个Q值,q,q_,从tensorboard可以看到actor和critic下分别是两个网络。下面进一步看如何建立actor网络和critic网络。trainable=True或者False主要是用来指定是否将神经网络中的变量添加到tensorboard图集中。
with tf.variable_scope('Actor'):
self.a = self._build_a(self.S, scope='eval', trainable=True)
a_ = self._build_a(self.S_, scope='target', trainable=False)
with tf.variable_scope('Critic'):
# assign self.a = a in memory when calculating q for td_error,
# otherwise the self.a is from Actor when updating Actor
q = self._build_c(self.S, self.a, scope='eval', trainable=True)
q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
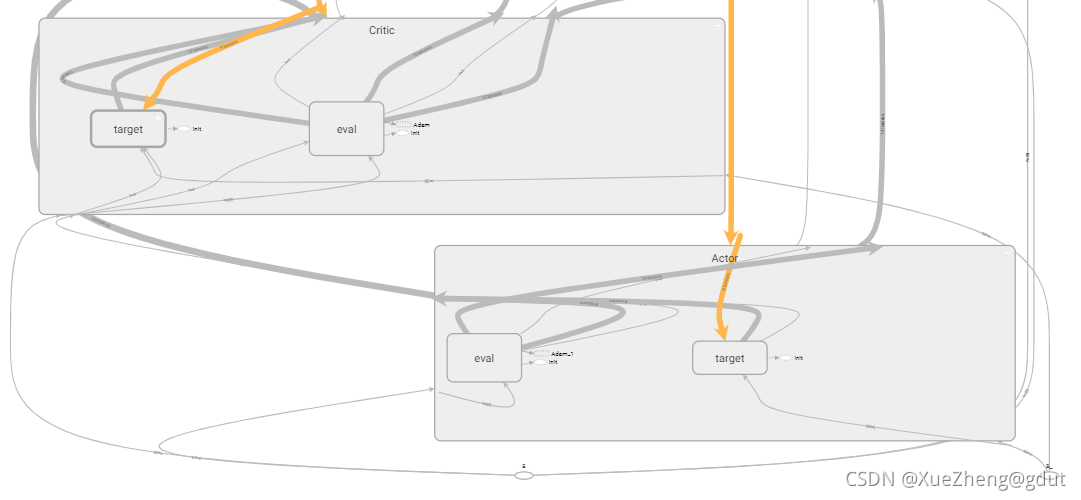
Actor
Actor网络主要输入状态s后,直接输出动作a。tf.layers.dense( input, units=k )会在内部自动生成一个权矩阵kernel和偏移项bias,各变量具体尺寸如下:对于尺寸为[m, n]的二维张量input, tf.layers.dense()会生成:尺寸为[n, k]的权矩阵kernel,和尺寸为[m, k]的偏移项bias。内部的计算过程为y = input * kernel + bias,输出值y的维度为[m, k]。
利用tensorflow封装的全连接层函数,输入状态,第一层神经元400(命名l1),第二层300(命名l2),第三层10(命名l3),输出层4(a_dim=4命名a)。actor的两个结构相同的网络就建好了,tensorboard如图所示。
def _build_a(self, s, scope, trainable):
with tf.variable_scope(scope):
net = tf.layers.dense(s, 400, activation=tf.nn.relu6, name='l1', trainable=trainable)
net = tf.layers.dense(net, 300, activation=tf.nn.relu6, name='l2', trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu, name='l3', trainable=trainable)
a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
return tf.multiply(a, self.a_bound[1], name='scaled_a')
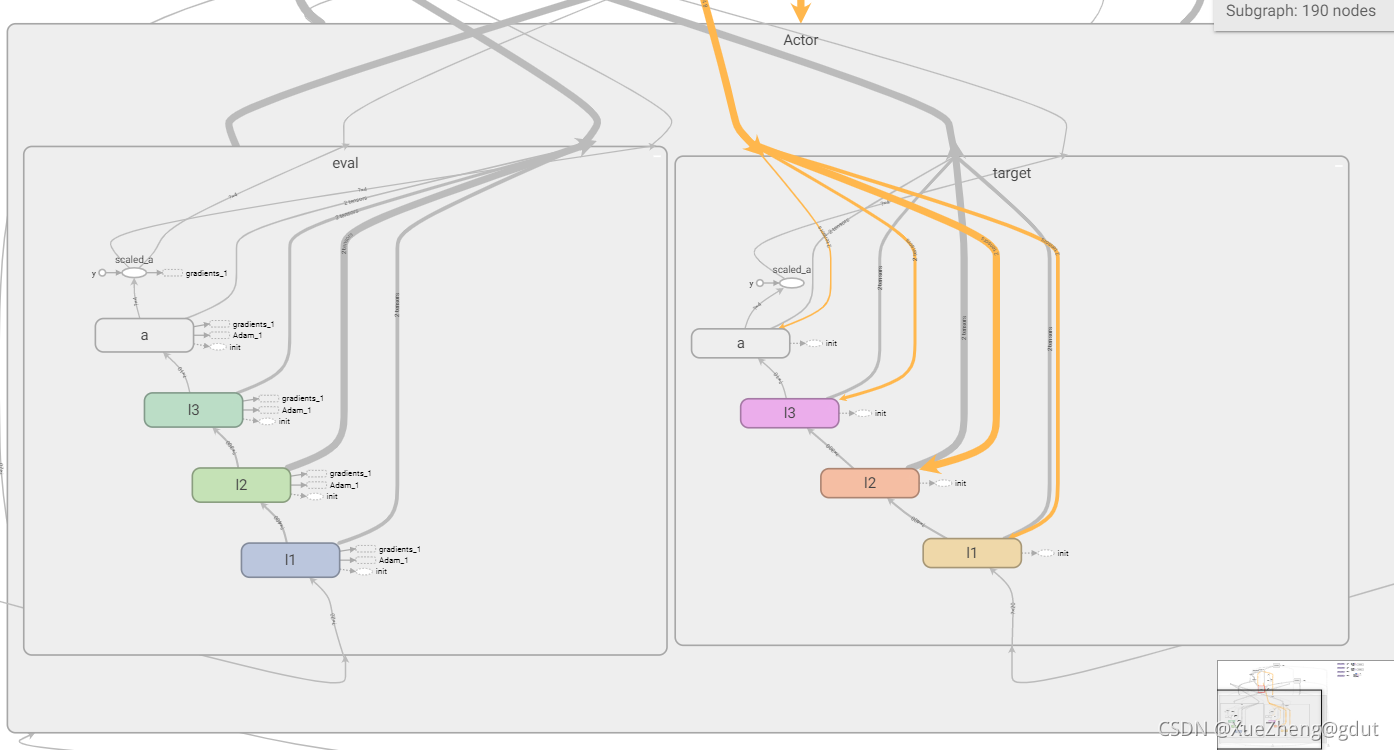
Critic
下面是Critic网络,对动作a进行打分,输出Q值。这里和上面建立神经网络的方式有一点不一样,因为Q函数需要输入状态s和动作a,所以s对应一个权重,a对应一个权重,整体还有一个偏置,然后经过一个激活函数就相当于一层神经网络了,w1_s和w1_a和b1都是神经网络的参数,是需要保存并更新的,所以设置为trainable,这样输入到的第一层神经元为400,第二层为300(命名l2),第三层为10(命名为l3),输出为对动作的打分,标量。神经网络原理,线性求和后通过激活函数(非线性函数)。Critic的两个结构相同的网络就建好了,tensorboard如图所示。
def _build_c(self, s, a, scope, trainable):
with tf.variable_scope(scope):
n_l1 = 400
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
net = tf.nn.relu6(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
net = tf.layers.dense(net, 300, activation=tf.nn.relu6, name='l2', trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu, name='l3', trainable=trainable)
return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
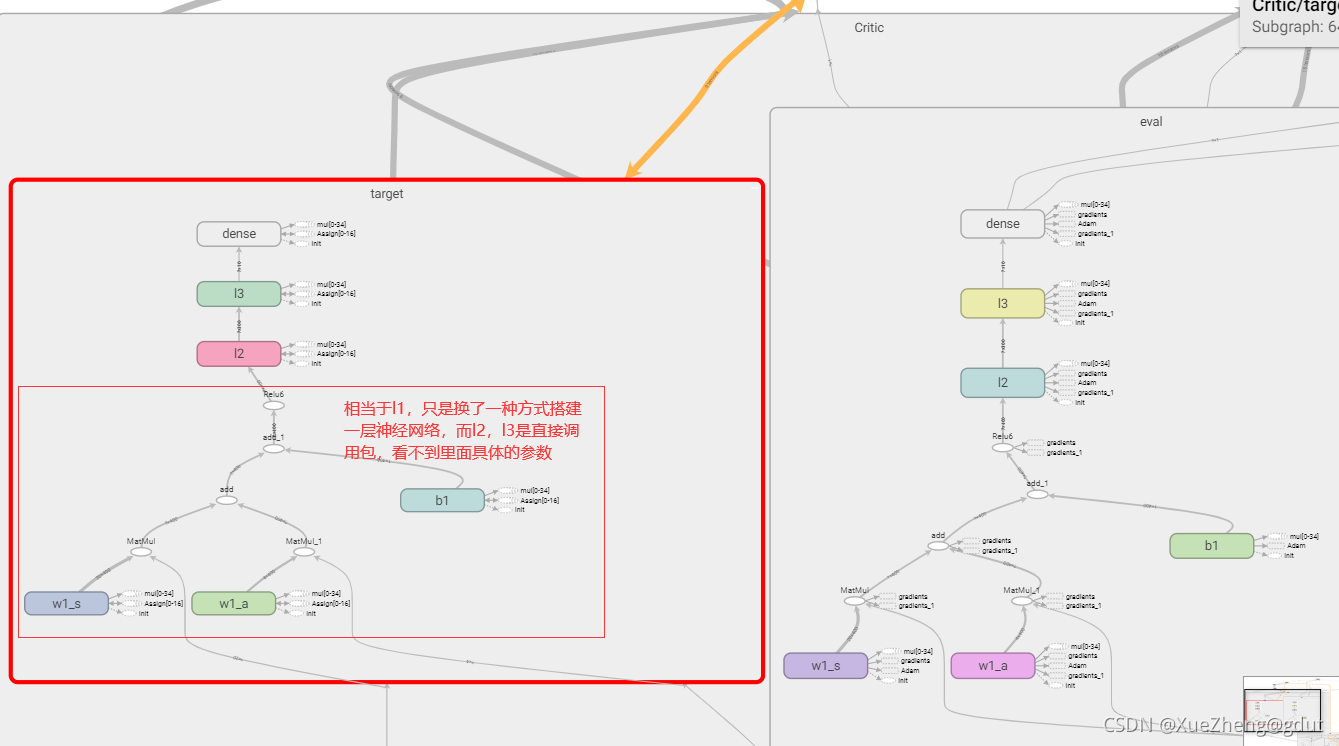
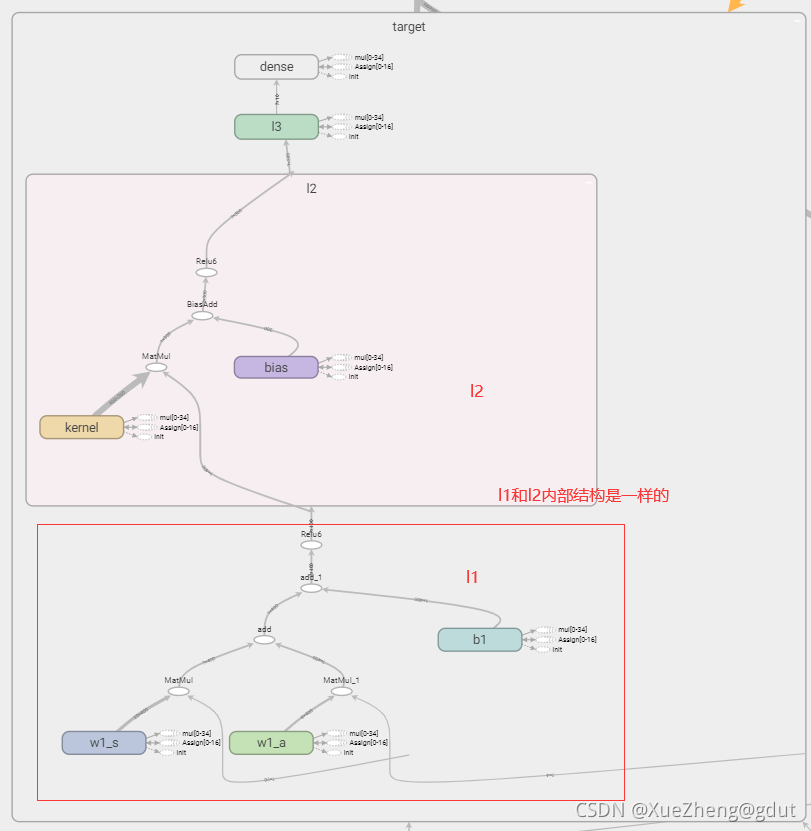

至此,四个神经网络结构就搭建好了。
神经网络重要的参数就是每层的权重和偏置,我们没有用非常原始的方式搭建神经网络,直接调用tf.layers.dense进行搭建,每层具体的参数是不清楚的,但tensorflow提供了非常方便的tf.get_collection,从一个集合中取出全部变量,是一个列表,一共有四个网络,这样可以提取出四个网络的所有参数,用来进行更新。
# networks parameters
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
经验回放池
由于神经网络输入时往往不是一个一个的输入,而是以小批量的形式输入,需要先收集一定的经验放在经验回放池,每次小批量取出用来给神经网络进行训练,训练到一定次数停止训练。将s, a, r, s_称为一条经验,存放到经验池,直至达到最大容量。
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
# transition = np.hstack((s, [a], [r], s_))
index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
self.memory[index, :] = transition
self.pointer += 1
神经网络参数更新
Actor和Critic中的两个主网络Actor_eval和Critic_eval分别通过TDerror和策略梯度进行更新。

计算TDerror,用来更新Critic_eval的网络参数,而Actor_eval的网络参数通过Q函数对actor_eval参数求导,这里实际上是Q对a求导然后对mu求导。{\theta^Q}
就是这里的ce_params,而{\theta^\mu}是ae_params。q_target 对应y_i。
q_target = self.R + GAMMA * q_
# in the feed_dic for the td_error, the self.a should change to actions in memory
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
一共是四个神经网络,主网络的参数由上面更新,而两个目标网络也需要更新,采用软更新(滑动平均)的方式,每次更新一点点,为什么要在Actor和Critic中分别使用两个神经网络主要是为了避免高估问题,因此参数需要设置的不一样,硬更新的方式是把主网络的参数延迟一段时间复制到目标网络,而软更新相当于每次只更新一点点。其公式和对应代码如下图。
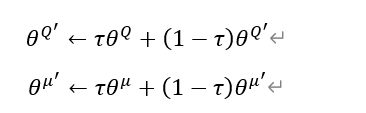
# target net replacement
self.soft_replace = [tf.assign(t, (1 - TAU) * t + TAU * e)
for t, e in zip(self.at_params + self.ct_params, self.ae_params + self.ce_params)]
这里的公式一下子可以更新两个目标网络的参数?为什么这里self.at_params + self.ct_params这里是+?说实话不是十分理解,这样就可以既更新at_params,又更新ct_params?有知道的可以详细讲解一下?不过搜索到这个,似乎这样写才是对的。这个也是直接用的莫烦的代码。
存经验
到这里,DDPG的整个框架基本搭建好了,剩下的就是往经验池存入数据,存满后就可以开始训练搭建好的神经网络了。存取经验(s,a,r,s_),随机选择一个状态s,这时候需要经过神经网络输出动作,所以设定了choose_action函数,这里调用神经网络输出动作a,这个动作往往会加噪声代表进行探索,然后环境根据动作a反馈奖励r并更新下一个状态s_,这样就得到一条经验。存的时候会判断是否存满等,或者对输出动作有一定要求等,见下面代码。这时候不能对神经网络进行训练。
def choose_action(self, s):
temp = self.sess.run(self.a, {self.S: s[np.newaxis, :]})
return temp[0]
# Add exploration noise
a = ddpg.choose_action(s_normal.state_normal(s))
a = np.clip(np.random.normal(a, var), *a_bound) # 高斯噪声add randomness to action selection for exploration
s_, r, is_terminal, step_redo, offloading_ratio_change, reset_dist = env.step(a)
if step_redo:
continue
if reset_dist:
a[2] = -1
if offloading_ratio_change:
a[3] = -1
ddpg.store_transition(s_normal.state_normal(s), a, r, s_normal.state_normal(s_)) # 训练奖励缩小10倍
训练
这里判断经验池满后,开始对神经网络训练,更新参数,这里直接调用learn函数,就可以开始训练过程,更新参数等。
if ddpg.pointer > MEMORY_CAPACITY:
# var = max([var * 0.9997, VAR_MIN]) # decay the action randomness
ddpg.learn()
搭建好流图后,使用sess.run运行,先进行软更新(目标网络参数更新),从经验池随机取出BATCH_SIZE条经验,使用sess.run对主网络参数进行更新(atrain,ctrain)。
def learn(self):
self.sess.run(self.soft_replace)
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
bt = self.memory[indices, :]
bs = bt[:, :self.s_dim]
ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
br = bt[:, -self.s_dim - 1: -self.s_dim]
bs_ = bt[:, -self.s_dim:]
self.sess.run(self.atrain, {self.S: bs})
self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
if ddpg.pointer > MEMORY_CAPACITY:
# var = max([var * 0.9997, VAR_MIN]) # decay the action randomness
ddpg.learn()
s = s_
ep_reward += r
到这里DDPG类的代码就讲解完了,这里将DDPG类的代码完整放出来。
############################### DDPG ####################################
class DDPG(object):
def __init__(self, a_dim, s_dim, a_bound):
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32) # memory里存放当前和下一个state,动作和奖励
self.pointer = 0
self.sess = tf.Session()
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
self.S = tf.placeholder(tf.float32, [None, s_dim], 's') # 输入
self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
self.R = tf.placeholder(tf.float32, [None, 1], 'r')
with tf.variable_scope('Actor'):
self.a = self._build_a(self.S, scope='eval', trainable=True)
a_ = self._build_a(self.S_, scope='target', trainable=False)
with tf.variable_scope('Critic'):
# assign self.a = a in memory when calculating q for td_error,
# otherwise the self.a is from Actor when updating Actor
q = self._build_c(self.S, self.a, scope='eval', trainable=True)
q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
# target net replacement
self.soft_replace = [tf.assign(t, (1 - TAU) * t + TAU * e)
for t, e in zip(self.at_params + self.ct_params, self.ae_params + self.ce_params)]
q_target = self.R + GAMMA * q_
# in the feed_dic for the td_error, the self.a should change to actions in memory
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
self.sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", self.sess.graph)
def choose_action(self, s):
temp = self.sess.run(self.a, {self.S: s[np.newaxis, :]})
return temp[0]
def learn(self):
self.sess.run(self.soft_replace)
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
bt = self.memory[indices, :]
bs = bt[:, :self.s_dim]
ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
br = bt[:, -self.s_dim - 1: -self.s_dim]
bs_ = bt[:, -self.s_dim:]
self.sess.run(self.atrain, {self.S: bs})
self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
# transition = np.hstack((s, [a], [r], s_))
index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
self.memory[index, :] = transition
self.pointer += 1
def _build_a(self, s, scope, trainable):
with tf.variable_scope(scope):
net = tf.layers.dense(s, 400, activation=tf.nn.relu6, name='l1', trainable=trainable)
net = tf.layers.dense(net, 300, activation=tf.nn.relu6, name='l2', trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu, name='l3', trainable=trainable)
a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
return tf.multiply(a, self.a_bound[1], name='scaled_a')
def _build_c(self, s, a, scope, trainable):
with tf.variable_scope(scope):
n_l1 = 400
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
net = tf.nn.relu6(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
net = tf.layers.dense(net, 300, activation=tf.nn.relu6, name='l2', trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu, name='l3', trainable=trainable)
return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
除了下面几句没讲到,初始化所有变量,和出tensorboard图。
self.sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", self.sess.graph)
训练代码:
############################### training ####################################
np.random.seed(1)
tf.set_random_seed(1)
env = UAVEnv()
MAX_EP_STEPS = env.slot_num
s_dim = env.state_dim
a_dim = env.action_dim
a_bound = env.action_bound # [-1,1]
ddpg = DDPG(a_dim, s_dim, a_bound)
# var = 1 # control exploration
var = 0.01 # control exploration
t1 = time.time()
ep_reward_list = []
s_normal = StateNormalization()
for i in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
j = 0
while j < MAX_EP_STEPS:
# Add exploration noise
a = ddpg.choose_action(s_normal.state_normal(s))
a = np.clip(np.random.normal(a, var), *a_bound) # 高斯噪声add randomness to action selection for exploration
s_, r, is_terminal, step_redo, offloading_ratio_change, reset_dist = env.step(a)
if step_redo:
continue
if reset_dist:
a[2] = -1
if offloading_ratio_change:
a[3] = -1
ddpg.store_transition(s_normal.state_normal(s), a, r, s_normal.state_normal(s_)) # 训练奖励缩小10倍
if ddpg.pointer > MEMORY_CAPACITY:
# var = max([var * 0.9997, VAR_MIN]) # decay the action randomness
ddpg.learn()
s = s_
ep_reward += r
if j == MAX_EP_STEPS - 1 or is_terminal:
print('Episode:', i, ' Steps: %2d' % j, ' Reward: %7.2f' % ep_reward, 'Explore: %.3f' % var)
ep_reward_list = np.append(ep_reward_list, ep_reward)
# file_name = 'output_ddpg_' + str(self.bandwidth_nums) + 'MHz.txt'
file_name = 'output.txt'
with open(file_name, 'a') as file_obj:
file_obj.write("\n======== This episode is done ========") # 本episode结束
break
j = j + 1
# # Evaluate episode
# if (i + 1) % 50 == 0:
# eval_policy(ddpg, env)
print('Running time: ', time.time() - t1)
plt.plot(ep_reward_list)
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.show()